Erkunden der Optimierung von Basismodellen in Azure Machine Learning
Zum Optimieren eines Basismodells aus dem Modellkatalog in Azure Machine Learning können Sie die Benutzeroberfläche verwenden, die in Studio, im Python SDK oder in der Azure CLI bereitgestellt wird.
Aufbereiten Ihrer Daten und Computeressourcen
Bevor Sie ein Basismodell optimieren können, um die Modellleistung zu verbessern, müssen Sie Ihre Trainingsdaten aufbereiten und einen GPU-Computecluster erstellen.
Tipp
Wenn Sie einen GPU-Computecluster in Azure Machine Learning erstellen, wird ein GPU-optimierter virtueller Computer für Sie erstellt. Weitere Informationen finden Sie unter Für GPU optimierte VM-Größen in Azure.
Die Trainingsdaten können im JSON-Zeilen-, CSV- oder TSV-Format vorliegen. Die Anforderungen Ihrer Daten variieren je nach Aufgabe, für die Sie Ihr Modell optimieren möchten.
| Aufgabe | Datasetanforderungen |
|---|---|
| Textklassifizierung | Zwei Spalten: Sentence (Zeichenfolge) und Label (Integer/Zeichenfolge) |
| Tokenklassifizierung | Zwei Spalten: Token (Zeichenfolge) und Tag (Zeichenfolge) |
| Fragen und Antworten | Fünf Spalten: Question (Zeichenfolge), Context (Zeichenfolge), Answers (Zeichenfolge), Answers_start (int) und Answers_text (Zeichenfolge) |
| Zusammenfassung | Zwei Spalten: Document (Zeichenfolge) und Summary (Zeichenfolge) |
| Sprachübersetzung | Zwei Spalten: Source_language (Zeichenfolge) und Target_language (Zeichenfolge) |
Hinweis
Ihr Dataset muss über die erforderlichen Anforderungen verfügen. Sie können jedoch verschiedene Spaltennamen verwenden und die Spalte der entsprechenden Anforderung zuordnen.
Wenn Sie Ihr Dataset und Ihren Computecluster vorbereitet haben, können Sie einen Optimierungsauftrag in Azure Machine Learning konfigurieren.
Auswählen eines Basismodells
Wenn Sie in Azure Machine Learning Studio zum Modellkatalog navigieren, können Sie alle Basismodelle untersuchen.
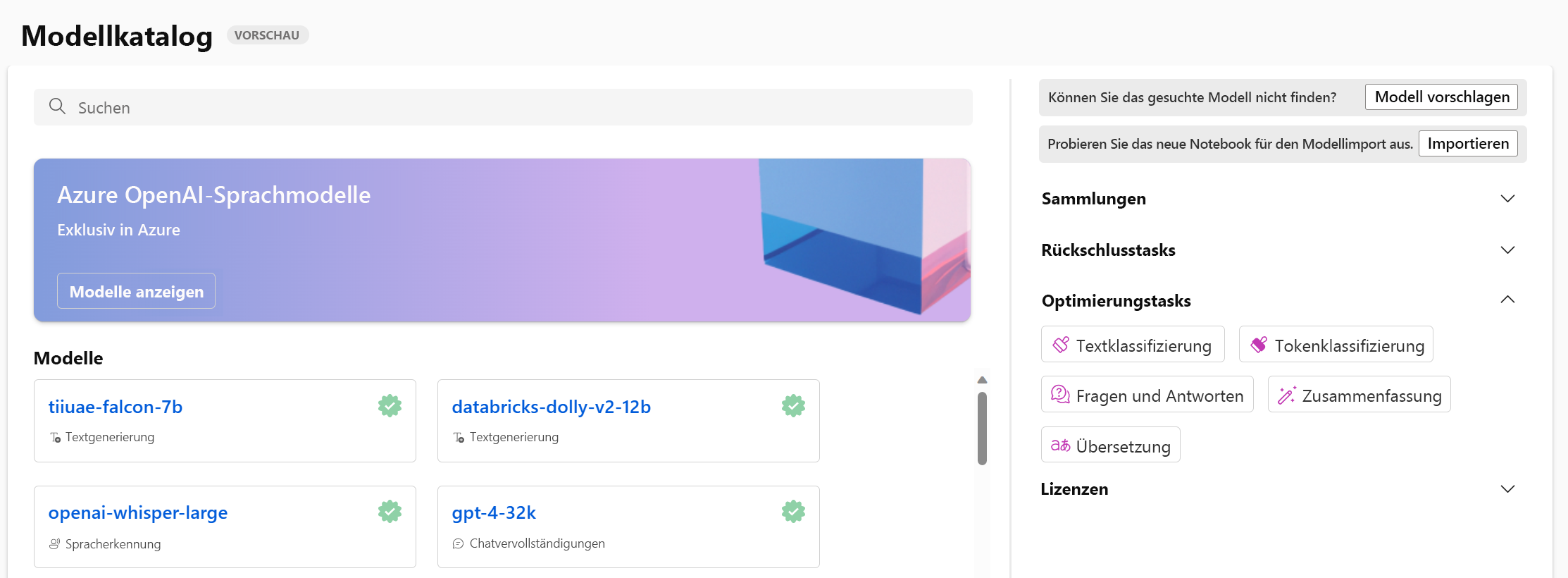
Sie können die verfügbaren Modelle basierend auf der Aufgabe filtern, für die Sie ein Modell optimieren möchten. Pro Aufgabe stehen Ihnen mehrere Optionen für Basismodelle zur Auswahl. Bei der Entscheidung zwischen Basismodellen für eine Aufgabe können Sie die Beschreibung des Modells und die Karte des referenzierten Modells überprüfen.
Dies sind einige Aspekte, die Sie bei der Entscheidung für ein Basismodell vor der Optimierung berücksichtigen sollten:
- Modellfunktionen: Bewerten Sie die Funktionen des Basismodells und seine Eignung für die Aufgabe. Beispielsweise ist ein Modell wie BERT besser darin, kurze Texte zu verstehen.
- Vorabtrainingsdaten: Betrachten Sie das Dataset, das zum Vorbereiten des Basismodells verwendet wird. GPT-2 wird beispielsweise mit ungefilterten Inhalten aus dem Internet trainiert, was zu Verzerrungen führen kann.
- Einschränkungen und Verzerrungen: Beachten Sie alle Einschränkungen oder Verzerrungen, die im Basismodell vorhanden sein können.
- Sprachunterstützung: Überprüfen Sie, welche Modelle die spezifische Sprachunterstützung oder mehrsprachige Funktionen bieten, die Sie für Ihren Anwendungsfall benötigen.
Tipp
Obwohl Azure Machine Learning Studio Beschreibungen für jedes Basismodell im Modellkatalog bereitstellt, können Sie weitere Informationen über jedes Modell auch über die jeweilige Modellkarte finden. Die Modellkarten sind in der Übersicht der einzelnen Modelle aufgeführt und auf der Website von Hugging Face zu finden.
Konfigurieren eines Optimierungsauftrags
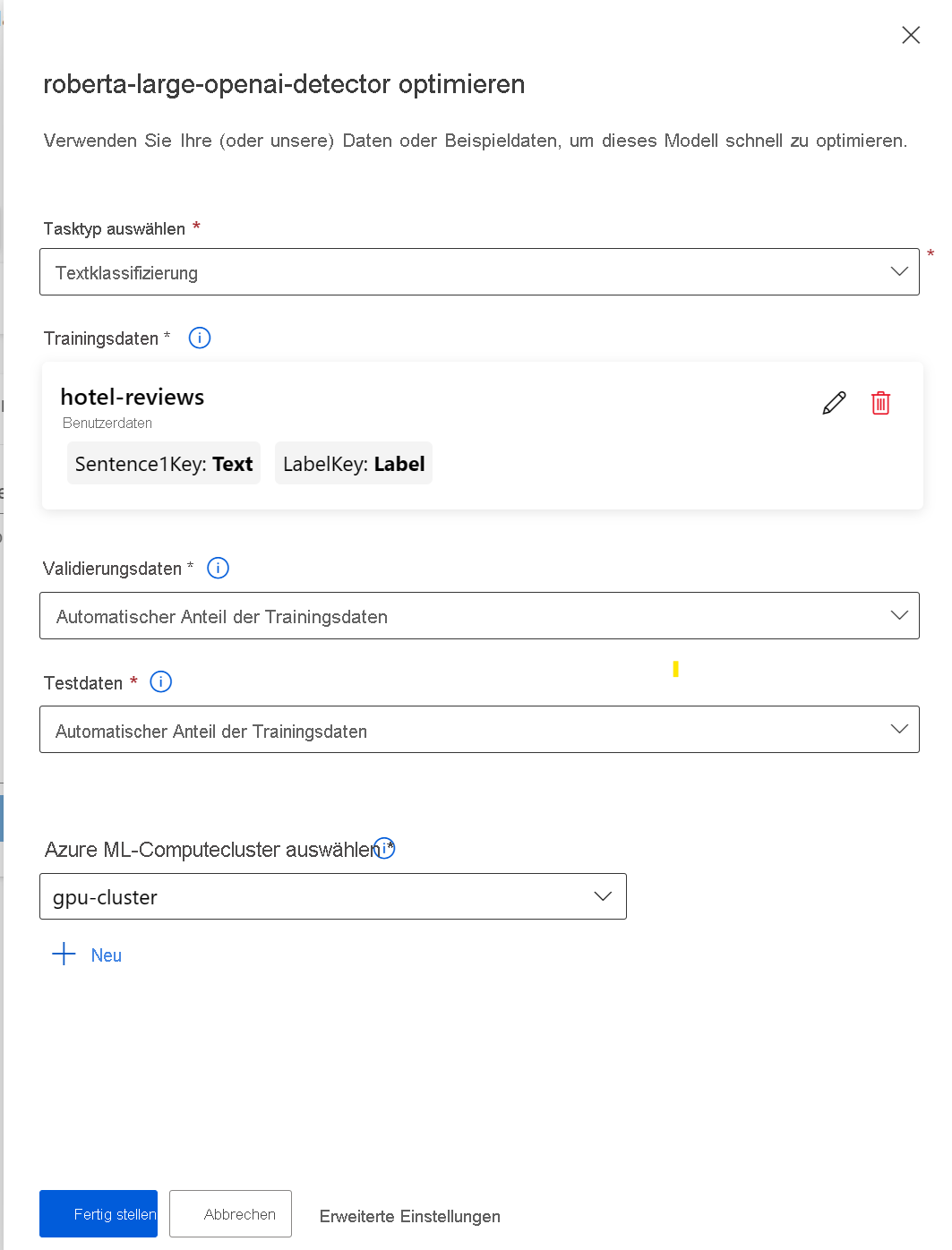
Führen Sie die folgenden Schritte aus, um einen Optimierungsauftrag mithilfe von Azure Machine Learning Studio zu konfigurieren:
- Wählen Sie ein Basismodell aus.
- Wählen Sie Optimieren aus, um ein Popupfenster zu öffnen, auf dem Sie den Auftrag konfigurieren können.
- Wählen Sie den Aufgabentyp aus.
- Wählen Sie die Trainingsdaten aus, und ordnen Sie die Spalten in Ihren Trainingsdaten den Datasetanforderungen zu.
- Lassen Sie Azure Machine Learning die Trainingsdaten entweder automatisch aufteilen, um ein Validierungs- und Testdataset zu erstellen, oder stellen Sie ein eigenes bereit.
- Wählen Sie einen GPU-Computecluster aus, der von Azure Machine Learning verwaltet wird.
- Wählen Sie „Fertig stellen“ aus, um den Optimierungsauftrag zu übermitteln.
Tipp
Optional können Sie in den erweiterten Einstellungen Einstellungen wie den Namen des Optimierungsauftrags und Aufgabenparameter (z. B. die Lernrate) ändern.
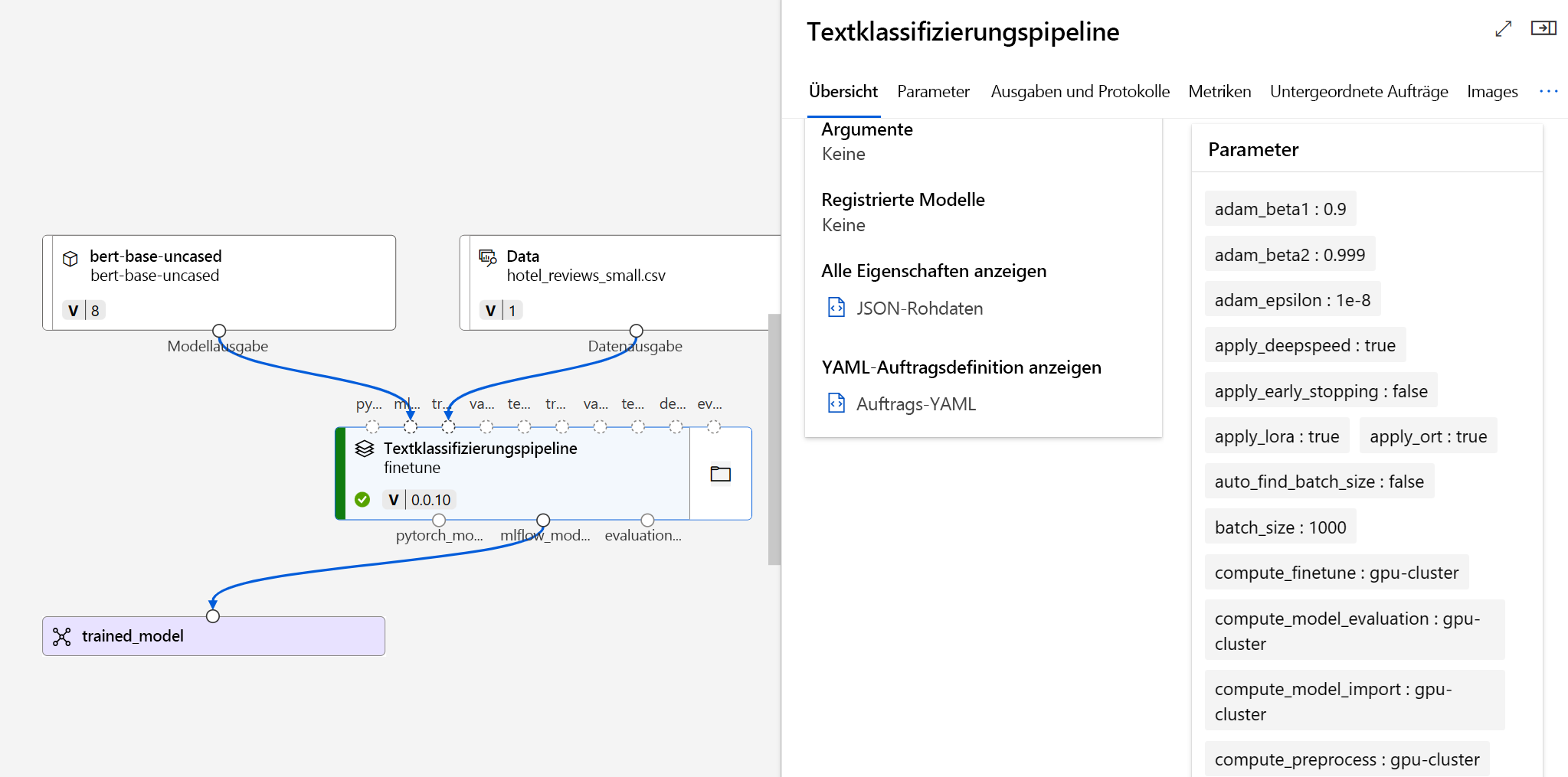
Nachdem Sie den Optimierungsauftrag übermittelt haben, wird ein Pipelineauftrag erstellt, um Ihr Modell zu trainieren. Sie können alle Eingaben überprüfen und das Modell aus den Auftragsausgaben zusammenstellen.