Azure Cosmos DB-APIs
Azure Cosmos DB ist eine vollständig verwaltete und serverlose verteilte Datenbank von Microsoft für Anwendungen jeder Größe oder Skalierung, die sowohl relationale als auch nicht relationale Workloads unterstützt. Entwickler können Anwendungen in kurzer Zeit unter Verwendung der bevorzugten Open Source-Datenbank-Engines, z. B. PostgreSQL, MongoDB und Apache Cassandra, erstellen und migrieren. Wenn Sie eine neue Cosmos DB-Instanz bereitstellen, wählen Sie die Datenbank-Engine aus, die Sie verwenden möchten. Die Wahl der Engine hängt von verschiedenen Faktoren ab, etwa vom Typ der zu speichernden Daten, von der Notwendigkeit, vorhandene Anwendungen unterstützen zu müssen, sowie von den Kenntnissen der Entwickler, die mit dem Datenspeicher arbeiten.
Azure Cosmos DB for NoSQL
Azure Cosmos DB for NoSQL ist der native nicht-relationale Dienst von Microsoft für die Arbeit mit dem Dokumentdatenmodell. Damit werden Daten im JSON-Dokumentformat verwaltet. Und obwohl es sich um eine NoSQL-Datenspeicherlösung handelt, wird für die Arbeit mit den Daten die SQL-Syntax verwendet.
Eine SQL-Abfrage für eine Azure Cosmos DB-Datenbank mit Kundendaten könnte in etwa wie folgt aussehen:
SELECT *
FROM customers c
WHERE c.id = "joe@litware.com"
Das Ergebnis dieser Abfrage besteht aus mindestens einem JSON-Dokument, wie hier gezeigt:
{
"id": "joe@litware.com",
"name": "Joe Jones",
"address": {
"street": "1 Main St.",
"city": "Seattle"
}
}
Azure Cosmos DB for MongoDB
MongoDB ist eine beliebte Open-Source-Datenbank, in der Daten im BSON-Format (Binary JSON) gespeichert werden. Mit Azure Cosmos DB for MongoDB können Entwickler MongoDB-Clientbibliotheken und -Code für die Arbeit mit Daten in Azure Cosmos DB verwenden.
MongoDB Query Language (MQL) verwendet eine kompakte, objektorientierte Syntax, bei der Entwickler*innen Objekte zum Aufrufen von Methoden verwenden. Bei der folgenden Abfrage wird beispielsweise die find-Methode zum Abfragen der products-Sammlung im db-Objekt verwendet:
db.products.find({id: 123})
Das Ergebnis dieser Abfrage besteht aus JSON-Dokumenten wie das folgende:
{
"id": 123,
"name": "Hammer",
"price": 2.99
}
Azure Cosmos DB for PostgreSQL
Azure Cosmos DB for PostgreSQL ist die verteilte PostgreSQL-Option in Azure. Azure Cosmos DB for PostgreSQL ist eine native, global verteilte relationale PostgreSQL-Datenbank verteilt, die Daten automatisch horizontal partitioniert, um hoch skalierbare Apps erstellen zu können. Sie können Apps in einer Einzelknotenservergruppe genauso wie sonst mit PostgreSQL erstellen. Wenn die Skalierbarkeits- und Leistungsanforderungen Ihrer App zunehmen, können Sie eine nahtlose Skalierung auf mehrere Knoten vornehmen, indem Sie Ihre Tabellen transparent verteilen. PostgreSQL ist ein relationales Datenbankverwaltungssystem (RDBMS), in dem Sie relationale Datentabellen definieren. Sie können beispielsweise eine Tabelle mit Produkten wie folgt definieren:
| ProductID | ProductName | Preis |
|---|---|---|
| 123 | Hammer | 2,99 |
| 162 | Screwdriver | 3.49 |
Anschließend können Sie diese Tabelle wie folgt mithilfe von SQL abfragen, um den Namen und den Preis eines bestimmten Produkts abzurufen:
SELECT ProductName, Price
FROM Products
WHERE ProductID = 123;
Die Ergebnisse dieser Abfrage enthalten für das Produkt 123 eine Zeile wie:
| ProductName | Preis |
|---|---|
| Hammer | 2,99 |
Azure Cosmos DB for Table
Azure Cosmos DB for Table wird verwendet, um mit Daten in Schlüssel-Wert-Tabellen zu arbeiten (ähnlich wie bei Azure Table Storage). Im Vergleich zu Azure Table Storage ist jedoch eine höhere Skalierbarkeit und Leistung möglich. Sie können beispielsweise eine Tabelle mit dem Namen Customers wie folgt definieren:
| PartitionKey | RowKey | Name | |
|---|---|---|---|
| 1 | 123 | Joe Jones | joe@litware.com |
| 1 | 124 | Samir Nadoy | samir@northwind.com |
Anschließend können Sie die Table-API mit einem sprachspezifischen SDK verwenden, um Aufrufe an einen Dienstendpunkt zum Abrufen von Daten aus der Tabelle durchzuführen. Die folgende Anforderung gibt beispielsweise die Zeile zurück, die den Datensatz für Samir Nadoy in der vorherigen Tabelle enthält:
https://endpoint/Customers(PartitionKey='1',RowKey='124')
Azure Cosmos DB for Apache Cassandra
Azure Cosmos DB for Apache Cassandra ist mit Apache Cassandra kompatibel. Hierbei handelt es sich um eine beliebte Open-Source-Datenbank, die eine Speicherstruktur der Spaltenfamilie verwendet. Spaltenfamilien sind Tabellen, die denen in einer relationalen Datenbank ähneln, bei denen es jedoch nicht zwingend erforderlich ist, dass jede Zeile dieselben Spalten aufweist.
Sie können beispielsweise eine Tabelle mit dem Namen Employees wie die folgende erstellen:
| ID | Name | Manager |
|---|---|---|
| 1 | Sue Smith | |
| 2 | Ben Chan | Sue Smith |
Cassandra unterstützt eine Syntax, die auf SQL basiert, sodass eine Clientanwendung den Datensatz für Ben Chan wie folgt abrufen kann:
SELECT * FROM Employees WHERE ID = 2
Azure Cosmos DB for Apache Gremlin
Azure Cosmos DB for Apache Gremlin wird mit Daten in einer Graphstruktur verwendet, in der Entitäten als Scheitelpunkte definiert werden, die Knoten im verbundenen Graphen bilden. Knoten werden wie folgt durch Edges verbunden, die Beziehungen darstellen:
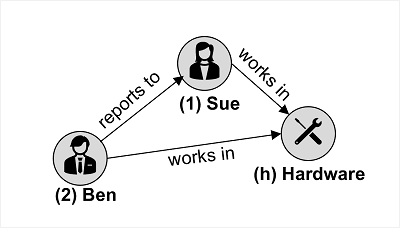
Das Beispiel in der Abbildung zeigt zwei Arten von Vertices (Mitarbeiter und Abteilung) und Edges, die diese miteinander verbinden (Mitarbeiter „Ben“ ist der Mitarbeiterin „Sue“ unterstellt, und beide arbeiten in der Abteilung „Hardware“).
Die Gremlin-Syntax enthält Funktionen zur Verwendung bei Vertices und Edges, mit denen Sie Daten im Graphen einfügen, aktualisieren, löschen und abfragen können. Sie können beispielsweise den folgenden Code verwenden, um eine neue Mitarbeiterin mit dem Namen Alice hinzuzufügen, die der Mitarbeiterin mit der ID 1 (Sue) unterstellt ist.
g.addV('employee').property('id', '3').property('firstName', 'Alice')
g.V('3').addE('reports to').to(g.V('1'))
Mit der folgenden Abfrage werden alle employee-Vertices in der Reihenfolge der ID zurückgegeben.
g.V().hasLabel('employee').order().by('id')