Verbessern der Leistung eines Sprachmodells
Nachdem Sie ein Modell auf einem Endpunkt bereitgestellt haben, können Sie mit dem Modell interagieren, um sein Verhalten zu untersuchen. Wenn Sie das Modell an Ihren Anwendungsfall anpassen möchten, gibt es mehrere Optimierungsstrategien, die Sie zum Verbessern der Leistung des Modells anwenden können. Im Folgenden erkunden wir die verschiedenen Strategien.
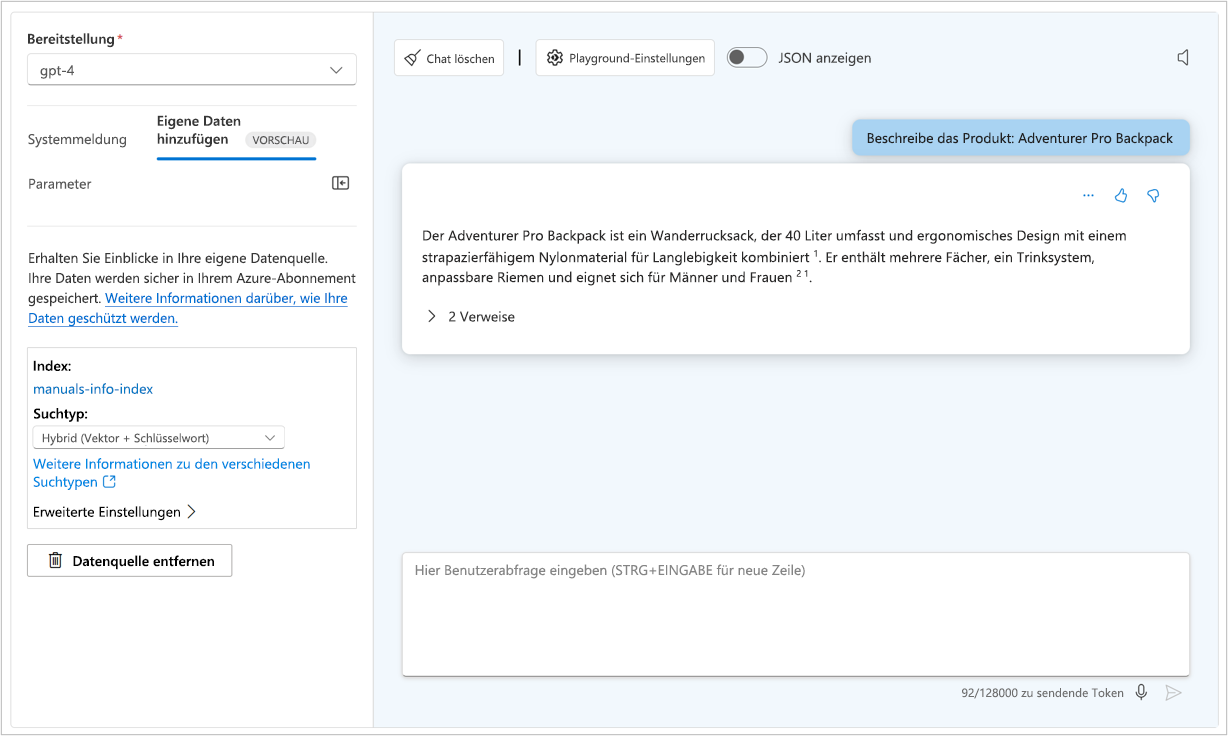
Chatten mit einem Modell im Playground
Sie können Ihre bevorzugte Programmiersprache verwenden, um einen API-Aufruf an den Endpunkt Ihres Modells durchzuführen, oder direkt im Playground des Azure KI Foundry-Portals mit dem Modell chatten. Der Chat-Playground ist eine schnelle und einfache Möglichkeit, um Experimente durchzuführen und die Modellleistung zu verbessern.
Die Qualität der Fragen, die Sie an das Sprachmodell senden, hat direkten Einfluss auf die Qualität der Antworten, die Sie erhalten. Sie können die Frage bzw. den Prompt sorgfältig konstruieren, um bessere und interessantere Antworten zu erhalten. Der Prozess des Entwerfens und Optimierens von Prompts zum Verbessern der Leistung des Modells wird auch als Pompt Engineering bezeichnet. Wenn Endbenutzer relevante, spezifische, eindeutige und gut strukturierte Prompts bereitstellen, kann das Modell den Kontext besser verstehen und genauere Antworten generieren.
Anwenden von Prompt Engineering
Wenn Sie im Playground mit dem Modell chatten, können Sie mehrere Prompt Engineering-Techniken anwenden, um zu untersuchen, ob diese die Ausgabe des Modells verbessern.
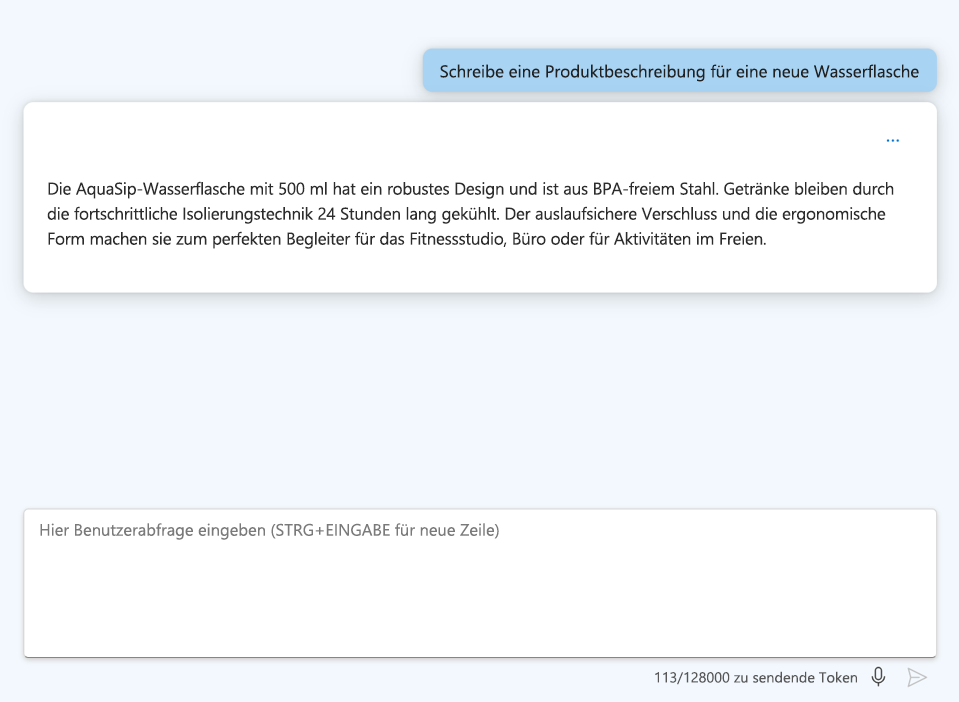
Sehen wir uns einige der Techniken an, die Endbenutzer zum Anwenden von Prompt Engineering verwenden können:
- Stellen Sie klare Anweisungen bereit: Seien Sie spezifisch bezüglich der gewünschten Ausgabe.
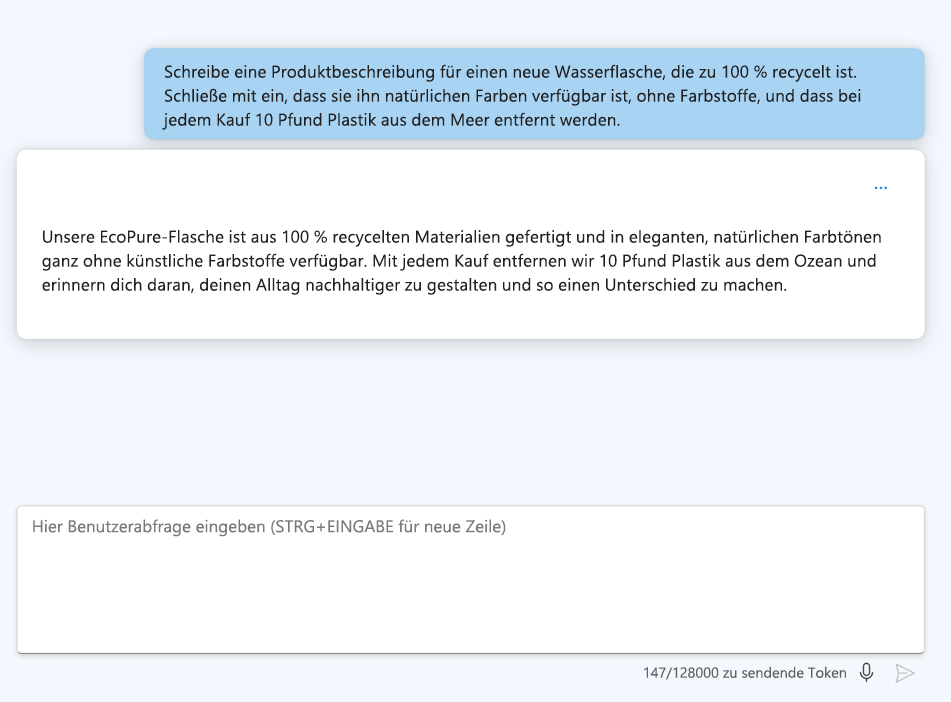
- Formatieren Sie Ihre Anweisungen: Verwenden Sie Überschriften und Abgrenzungszeichen, damit die Frage einfacher zu lesen ist.
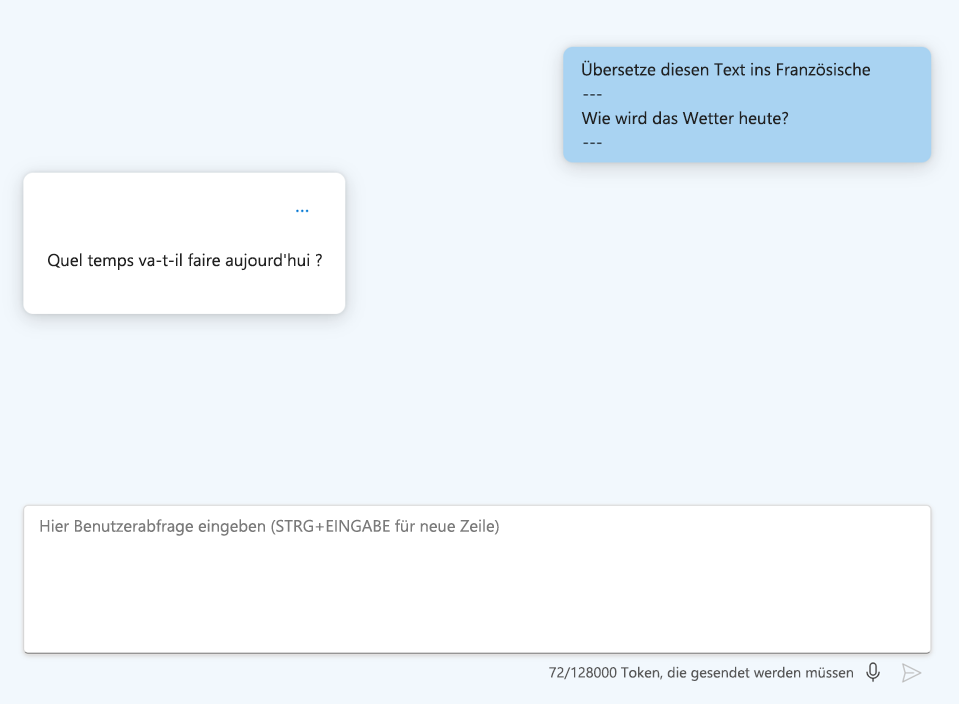
- Verwenden Sie Cues: Geben Sie Schlüsselwörter oder Indikatoren an, mit denen die Antwort des Modells beginnen soll, z. B. eine bestimmte Programmiersprache.
Aktualisieren der Systemnachricht
Im Chat-Playground können Sie den JSON-Code Ihrer aktuellen Unterhaltung anzeigen, indem Sie JSON anzeigen auswählen:
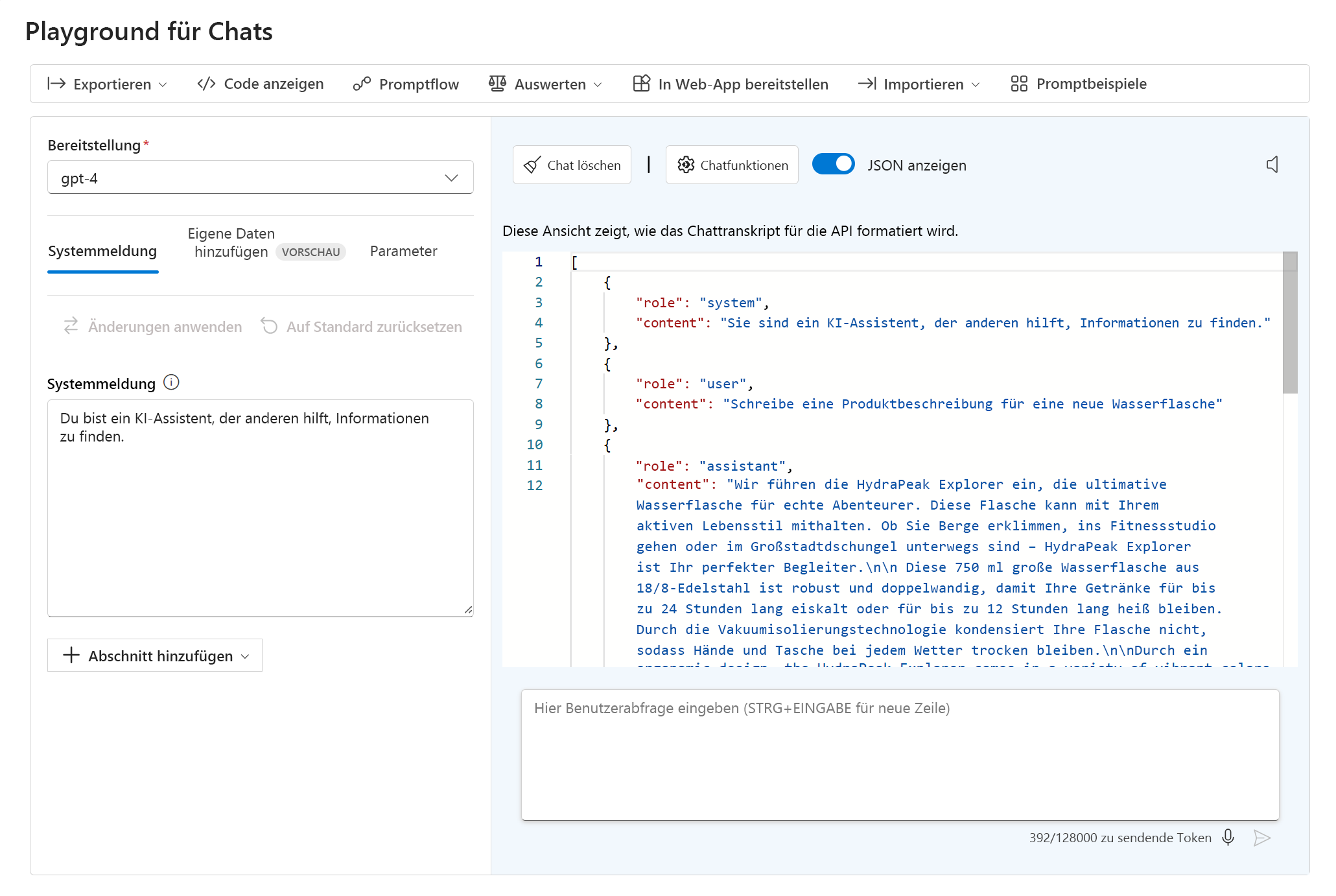
Bei dem angezeigten JSON-Code handelt es sich um die Eingabedaten für Ihren Modellendpunkt, die beim Senden jeder neuen Nachricht übermittelt werden. Die Systemmeldung ist immer Teil der Eingabedaten. Die Systemmeldung ist für Endbenutzer nicht sichtbar. Ihnen als Entwickler ermöglicht sie es jedoch, das Verhalten des Modells anzupassen, indem Sie Anweisungen für das Verhalten des Modells bereitstellen.
Entwickler können durch Aktualisieren der Systemmeldung z. B. folgende gängige Prompt Engineering-Techniken anwenden:
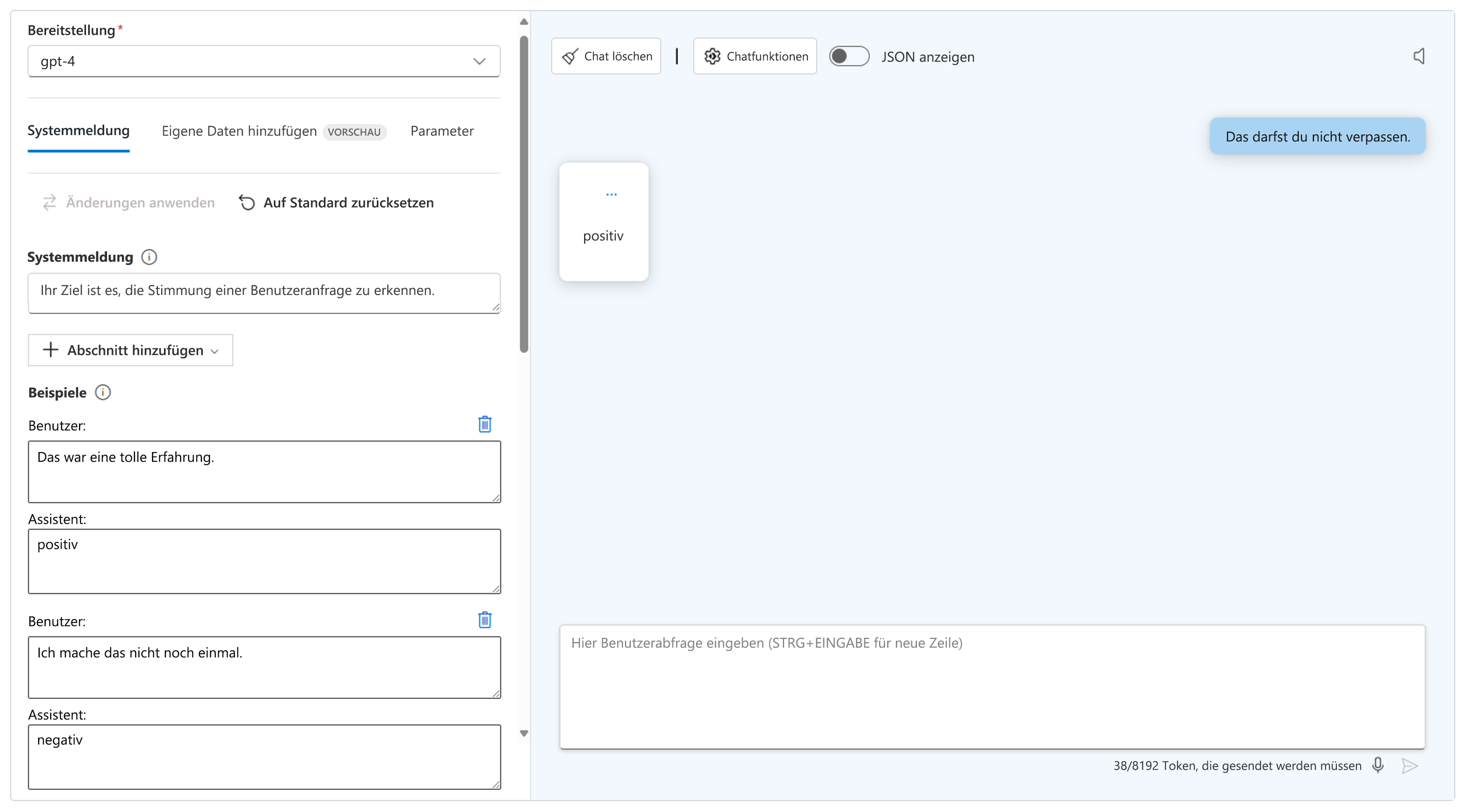
- Verwenden Sie One-Shot- oder Few-Shot-Prompts: Stellen Sie ein oder mehrere Beispiele bereit, damit das Modell ein gewünschtes Muster identifizieren kann. Sie können der Systemmeldung einen Abschnitt mit einem oder mehreren Beispielen hinzufügen.
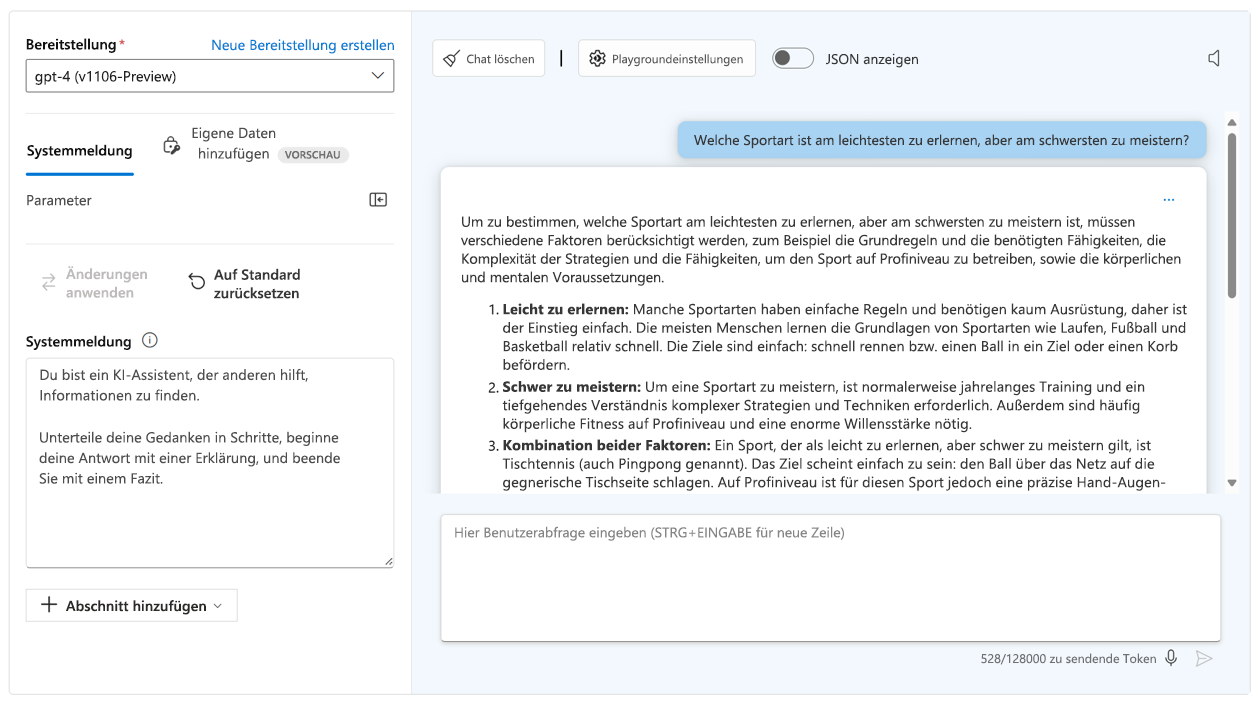
- Verwenden Sie eine Gedankenkette: Leiten Sie das Modell Schritt für Schritt zum Denken an, indem Sie es anweisen, die Aufgabe zu durchdenken.
- Fügen Sie Kontext hinzu: Verbessern Sie die Genauigkeit des Modells, indem Sie relevante Kontext- oder Hintergrundinformationen für die Aufgabe bereitstellen. Sie können kontextbezogene Daten durch Groundingdaten im Benutzerprompt oder durch Verbinden einer eigenen Datenquelle bereitstellen.
Anwendung von Strategien zur Modelloptimierung
Als Entwickler können Sie auch andere Optimierungsstrategien zum Verbessern der Leistung des Modells anwenden, ohne den Endbenutzer zum Schreiben spezifischer Prompts auffordern zu müssen. Abgesehen vom Prompt Engineering hängt die von Ihnen gewählte Strategie von Ihren Anforderungen ab:
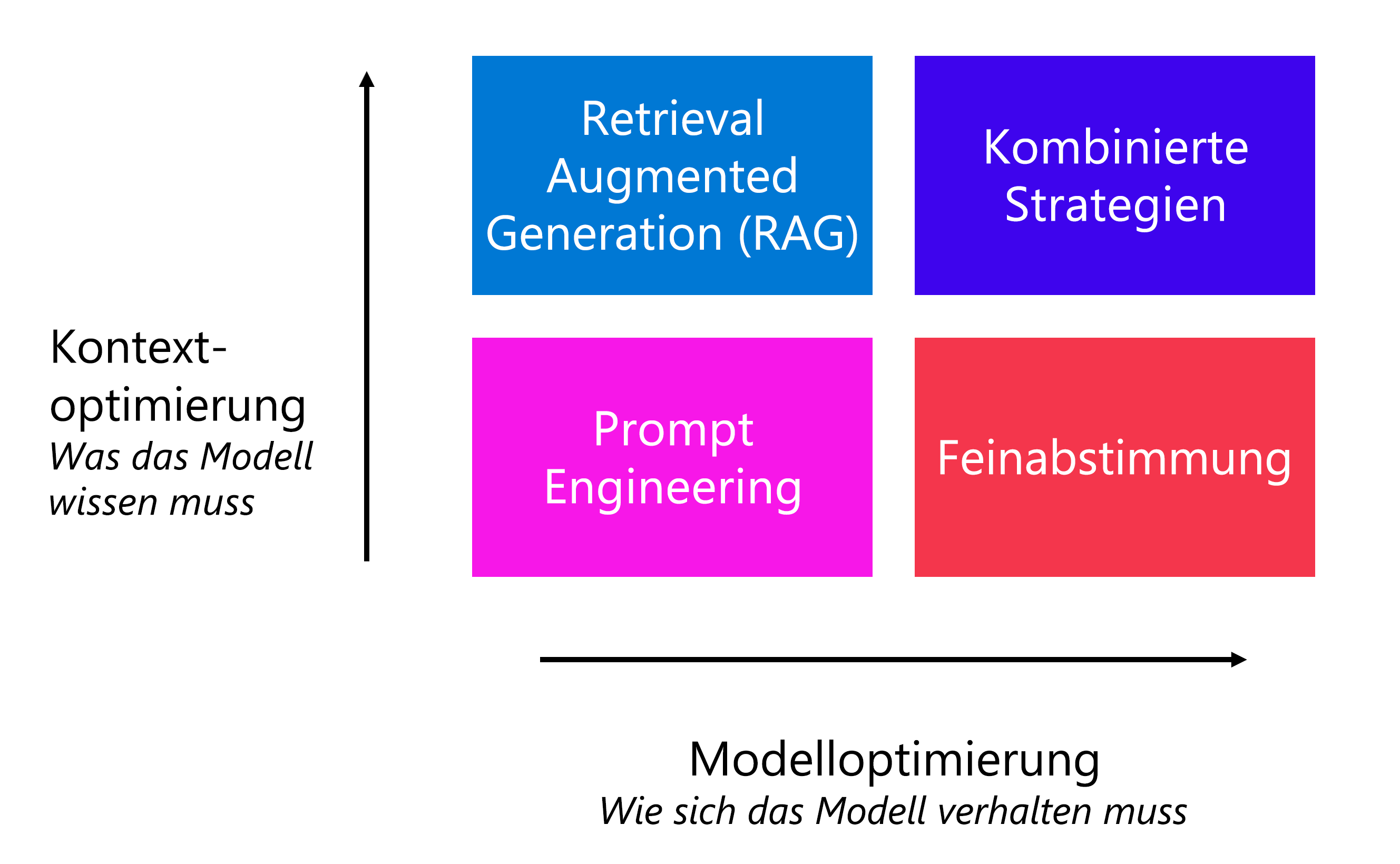
- Optimieren nach Kontext: Verwenden Sie diesen Ansatz, wenn das Modell kein kontextbezogenes Wissen umfasst und Sie die Genauigkeit der Antworten maximieren möchten.
- Optimieren des Modells: Verwenden Sie diesen Ansatz, wenn Sie das Format, den Stil oder die Sprache der Antwort durch Maximieren der Konsistenz des Verhaltens verbessern möchten.
Um den Kontext zu optimieren, können Sie ein Retrieval Augmented Generation (RAG)-Muster anwenden. Wenn Sie RAG verwenden, führen Sie zunächst ein Grounding Ihrer Daten durch, indem Sie vor dem Generieren einer Antwort zunächst den Kontext aus einer Datenquelle abrufen. Sie möchten zum Beispiel, dass Ihre Kundinnen und Kunden Fragen zu den Hotels stellen können, die Sie in Ihrem Reisebuchungskatalog anbieten.
Wenn das Modell in einem bestimmten Stil oder Format antworten soll, können Sie entsprechende Richtlinien in der Systemmeldung hinzufügen. Wenn Sie feststellen, dass das Verhalten eines Modells nicht konsistent ist, können Sie durch Feinabstimmen eines Modells ein konsistentes Verhalten erzwingen. Durch die Optimierung bzw. Feinabstimmung trainieren Sie ein Basissprachmodell mit einem Dataset, bevor Sie es in Ihre Anwendung integrieren.
Sie können auch eine Kombination von Optimierungsstrategien wie RAG und ein optimiertes Modell verwenden, um Ihre Sprachanwendung zu verbessern.