Erstellen einer KQL-Abfrage
Da Sie nun wissen, wie Abfragesprachen funktionieren und wo KQL eingesetzt werden kann, lassen Sie uns nun untersuchen, wie eine KQL-Abfrage aufgebaut ist.
KQL-Abfragestruktur
Eine KQL-Abfrage ist eine schreibgeschützte Anforderung zur Verarbeitung von Daten und zur Rückgabe der Ergebnisse. Die Anforderung wird in Klartext mit einem Datenflussmodell formuliert, das leicht zu lesen, zu erstellen und zu automatisieren ist.
Unterschiedliche Abfragesprachen verfügen häufig über unterschiedliche Strukturen. Die Organisation von KQL basiert auf der Art und Weise, wie Daten verarbeitet werden. Jede KQL-Abfrage beginnt mit der Datenquelle. Die Daten werden dann durch Durchlaufen von Bedingungen verarbeitet, sortiert und mit einem Filter weiter reduziert.
Datenverarbeitung
Stellen Sie sich vor, die Daten durchlaufen einen Datenverarbeitungstrichter. Die tabellarische Eingabe ist der Anfang des Datentrichters. Diese Daten werden in die nächste Zeile geleitet und mit einem Operator gefiltert oder manipuliert. Die verbleibenden Daten werden in die nachfolgende Zeile eingefügt, und so weiter, bis die endgültige Abfrageausgabe erreicht ist. Diese Abfrageausgabe wird in einem tabellarischen Format zurückgegeben.
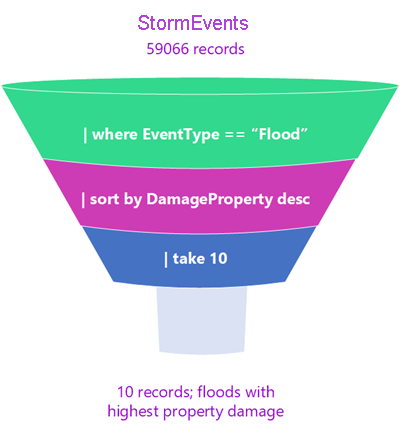
An der Form des Filters können Sie erkennen, dass die Daten „oben“ im Trichter zu Beginn größer sind als die Daten am Ende. Schritte, die die größten Datenmengen entfernen, werden normalerweise am Anfang der Abfrage verwendet. Auf diese Weise müssen die folgenden Vorgänge eine geringere Datenmenge verarbeiten und das Abfrageergebnis wird schnell zurückgegeben. Einer der Vorteile von KQL ist tatsächlich seine Fähigkeit, große Mengen unterschiedlichster Daten schnell zu verarbeiten.