Grundlagen zu Datenerfassungspipelines
Nachdem Sie nun ein wenig mehr über die Architektur einer großen Data Warehousing-Lösung und einige der verteilten Verarbeitungstechnologien kennengelernt haben, die zum Verarbeiten großer Datenmengen verwendet werden können, ist es an der Zeit, sich damit zu beschäftigen, wie Daten aus mindestens einer Quelle in einem Speicher für analytische Daten erfasst werden.
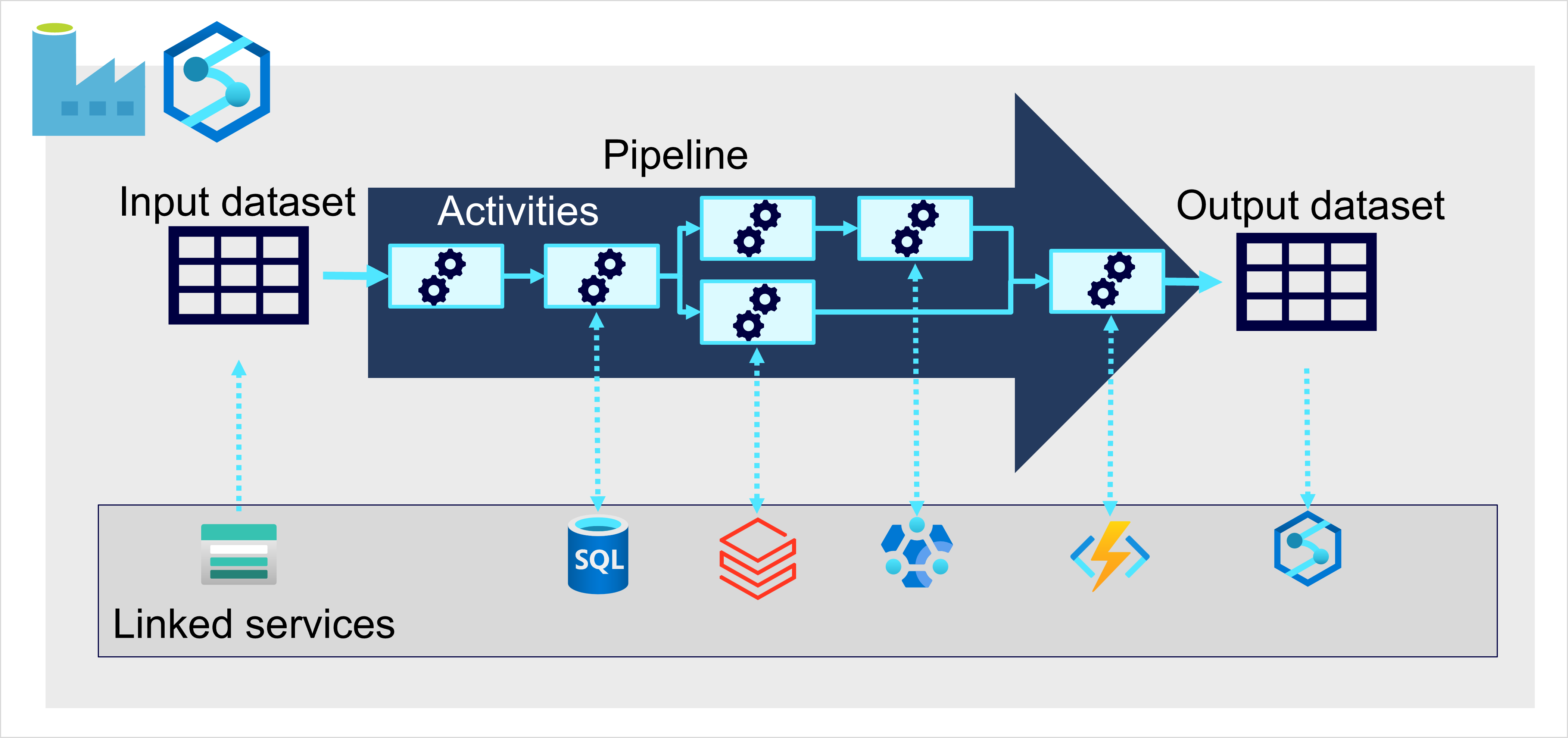
In Azure lässt sich eine umfangreiche Datenerfassung am besten durch das Erstellen von Pipelines implementieren, die ETL-Prozesse orchestrieren. Sie können Pipelines mit Azure Data Factory erstellen und ausführen. Alternativ können Sie die Pipelinefunktion in Microsoft Fabric verwenden, wenn Sie alle Komponenten der Data Warehousing-Lösung in einem einheitlichen Arbeitsbereich verwalten möchten.
In beiden Fällen bestehen Pipelines aus einer oder mehreren Aktivitäten, durch die Daten verarbeitet werden. Ein Eingabedataset stellt die Quelldaten zur Verfügung, und Aktivitäten können als Datenfluss definiert werden, der die Daten inkrementell bearbeitet, bis ein Ausgabedataset erstellt wird. Pipelines verwenden verknüpfte Dienste, um Daten zu laden und aufzubereiten. Dies ermöglicht Ihnen, die für jeden Schritt des Workflows geeignete Technologie zu verwenden. Beispielsweise können Sie einen verknüpften Azure Blob Store-Dienst verwenden, um das Eingabedataset zu erfassen, und dann Dienste wie Azure SQL-Datenbank nutzen, um eine gespeicherte Prozedur auszuführen, die nach verwandten Datenwerten sucht, bevor Sie eine Datenverarbeitungsaufgabe in Azure Databricks ausführen oder eine benutzerdefinierte Logik mithilfe einer Azure-Funktion anwenden. Schließlich können Sie das Ausgabedataset in einem verknüpften Dienst wie Microsoft Fabric speichern. Pipelines kann auch integrierte Aktivitäten einschließen, die keinen verknüpften Dienst erfordern.