Beschreiben der Data Warehousing-Architektur
Die Architektur groß dimensionierter Datenanalysen kann variieren, ebenso wie die spezifischen Technologien, die zu ihrer Implementierung eingesetzt werden. Im Allgemeinen sind jedoch die folgenden Elemente enthalten:
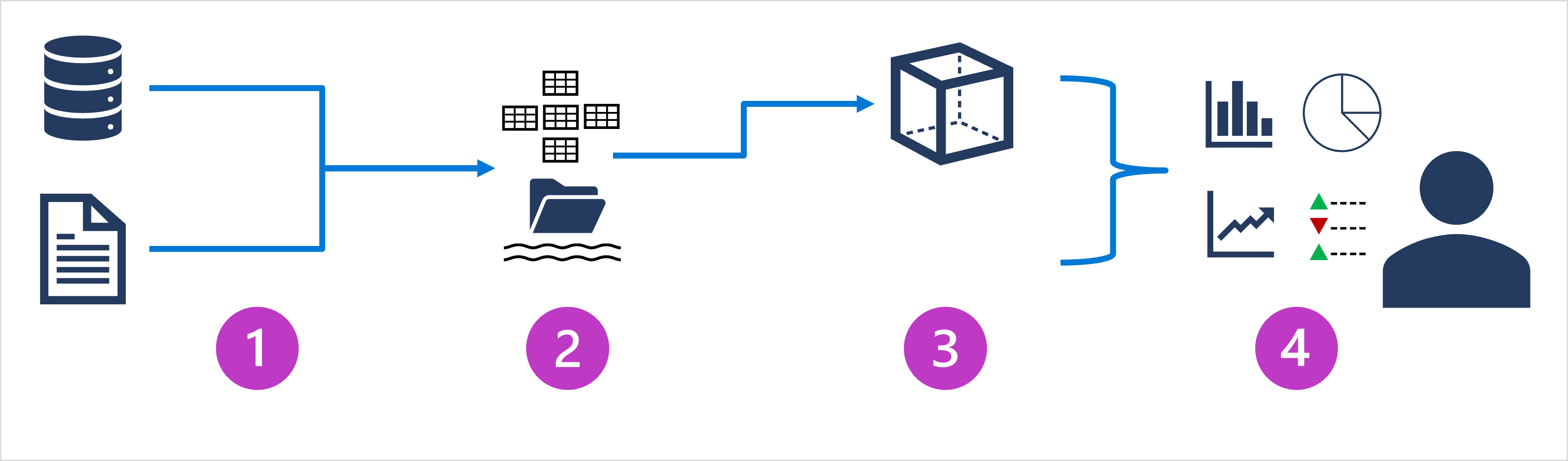
- Datenerfassung und -verarbeitung: Daten aus Transaktionsdatenspeichern, Transaktionsdatendateien, entsprechenden Echtzeitdatenströmen und anderen Quellen werden in einen Data Lake oder in ein relationales Data Warehouse geladen. Der Ladevorgang umfasst in der Regel einen ETL-Prozess (Extrahieren, Transformieren und Laden) oder einen ELT-Prozess (Extrahieren, Laden und Transformieren), bei dem die Daten bereinigt, gefiltert und für die Analyse neu strukturiert werden. Bei einem ETL-Prozess werden die Daten vor dem Laden in einen Analysespeicher transformiert, während sie bei einem ELT-Prozess zuerst in den Speicher kopiert und dann transformiert werden. In beiden Fällen ist die resultierende Datenstruktur für Analyseabfragen optimiert. Die Datenverarbeitung wird häufig von verteilten Systemen ausgeführt, die große Datenmengen mithilfe von Clustern mit mehreren Knoten parallel verarbeiten können. Die Datenerfassung umfasst sowohl die Batchverarbeitung statischer Daten als auch die Echtzeitverarbeitung von Streamingdaten.
- Analysedatenspeicher: Zu Datenspeichern für umfangreiche Analysen gehören relationale Data Warehouses, dateisystembasierte Data Lakes sowie Hybridarchitekturen, die Features von Data Warehouses und Data Lakes vereinen (und gelegentlich als Data Lakehouses oder Lake-Datenbanken bezeichnet werden). Diese werden später ausführlicher behandelt.
- Modell für analytische Daten: Data Analysts und wissenschaftliche Fachkräfte für Daten können zwar direkt mit den Daten im Analysedatenspeicher arbeiten, für gewöhnlich wird jedoch mindestens ein Datenmodell erstellt, mit dem die Daten vorab aggregiert werden, um die Erstellung von Berichten, Dashboards und interaktiven Visualisierungen zu erleichtern. Häufig werden diese Datenmodelle als Cubes beschrieben, in denen numerische Datenwerte über mindestens eine Dimension aggregiert werden (z. B. um den Gesamtumsatz nach Produkt und Region zu bestimmen). Zur Unterstützung von Drillup-/Drilldownanalysen kapselt das Modell die Beziehungen zwischen Datenwerten und dimensionalen Entitäten.
- Datenvisualisierung: Data Analysts verwenden Daten, die aus Analysemodellen und direkt aus Analysespeichern stammen, um Berichte, Dashboards und andere Visualisierungen zu erstellen. Darüber hinaus können Benutzer in einer Organisation, die möglicherweise keine Technologiefachkräfte sind, Self-Service-Datenanalysen durchführen und entsprechende Berichte erstellen. Die Visualisierungen aus den Daten zeigen Trends, Vergleiche und Key Performance Indicators (KPIs) für ein Unternehmen oder eine andere Organisation und können in Form von gedruckten Berichten, Graphen und Diagrammen in Dokumenten oder PowerPoint-Präsentationen, webbasierten Dashboards und interaktiven Umgebungen vorliegen, in denen Benutzer*innen Daten visuell untersuchen können.