Bewerten der Modell-Leistung
Die Bewertung der Leistung Ihres Modells in verschiedenen Phasen ist entscheidend, um die Effektivität und Zuverlässigkeit zu gewährleisten. Bevor Sie sich mit den verschiedenen Optionen befassen, die Sie zum Bewerten Ihres Modells haben, sollten Sie die Aspekte Ihrer Anwendung untersuchen, die Sie bewerten können.
Wenn Sie eine generative KI-App entwickeln, verwenden Sie ein Sprachmodell in Ihrer Chatanwendung, um eine Antwort zu generieren. Um zu entscheiden, welches Modell Sie in Ihre Anwendung integrieren möchten, können Sie die Leistung eines einzelnen Sprachmodells bewerten:
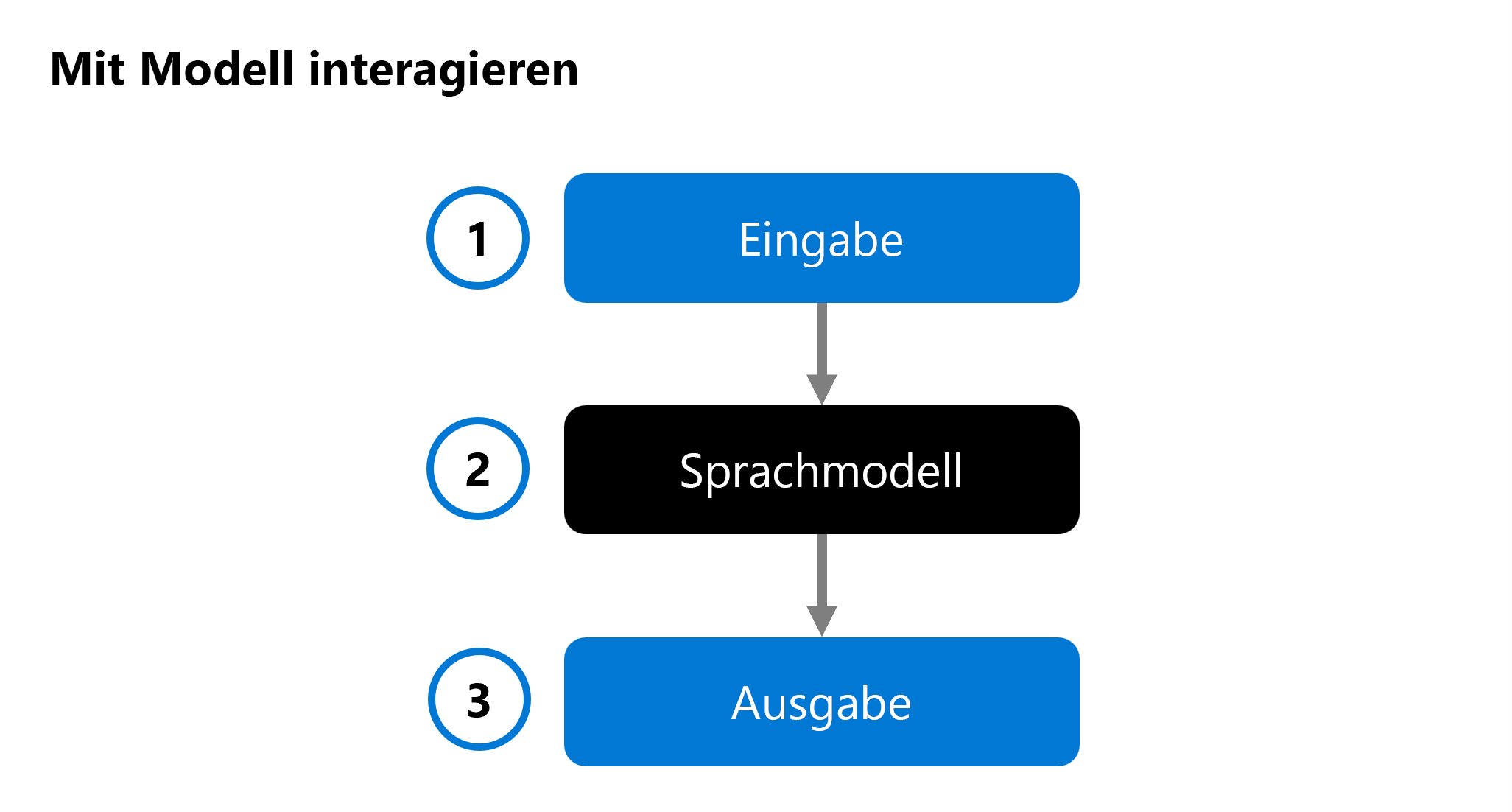
Eine Eingabe (1) wird für ein Sprachmodell (2) bereitgestellt, und eine Antwort wird als Ausgabe (3) generiert. Das Modell wird dann bewertet, indem die Eingabe und die Ausgabe analysiert werden. Wahlweise kann die Ausgabe mit einer vordefinierten erwarteten Ausgabe verglichen werden.
Wenn Sie eine generative KI-App entwickeln, integrieren Sie ein Sprachmodell in einen Chatflow:
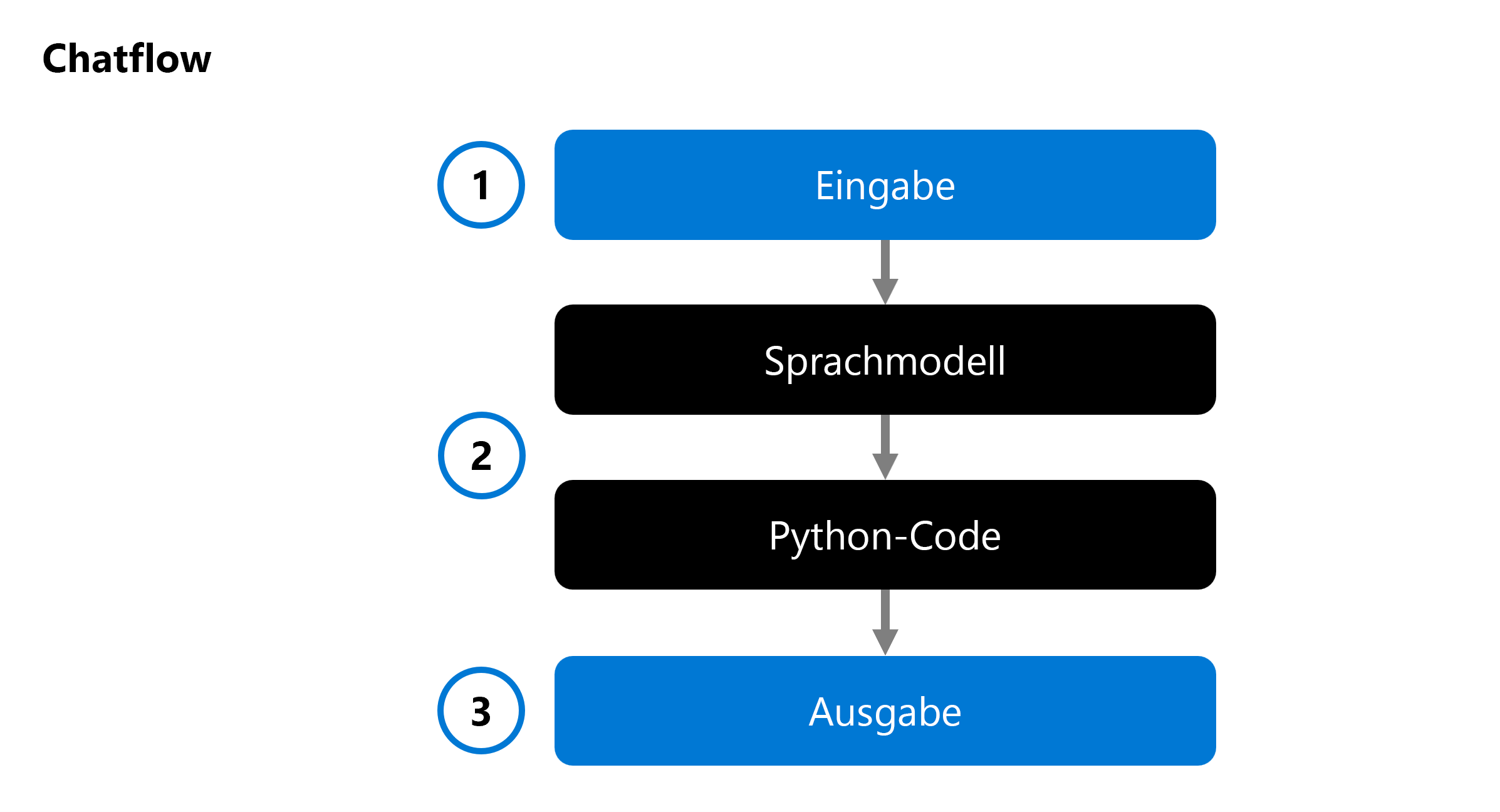
Mit einem Chatflow können Sie ausführbare Abläufe orchestrieren, die mehrere Sprachmodelle und Python-Code kombinieren können. Der Flow erwartet eine Eingabe (1), verarbeitet sie durch Ausführen verschiedener Knoten (2) und generiert eine Ausgabe (3). Sie können einen vollständigen Chatflow und seine einzelnen Komponenten bewerten.
Beim Bewerten Ihrer Lösung können Sie mit dem Testen eines einzelnen Modells beginnen und schließlich einen vollständigen Chatflow testen, um zu überprüfen, ob Ihre generative KI-App erwartungsgemäß funktioniert.
Untersuchen wir nun mehrere Ansätze, um Ihr Modell und Ihren Chatflow oder Ihre generative KI-App zu bewerten.
Modell-Benchmarks
Modell-Benchmarks sind öffentlich verfügbare Metriken für Modelle und Datasets. Mithilfe dieser Benchmarks können Sie die Leistung Ihres Modells im Vergleich mit anderen Modellen verstehen. Einige häufig verwendete Benchmarks sind:
- Genauigkeit: Vergleicht den vom Modell generierten Text mit der richtigen Antwort gemäß dem Dataset. Das Ergebnis ist 1, wenn der generierte Text genau mit der Antwort übereinstimmt, andernfalls 0.
- Kohärenz: Misst, ob die Modellausgabe reibungslos abläuft, sich natürlich liest und der menschlichen Sprache ähnelt.
- Flüssigkeit: Bewertet, wie gut der generierte Text grammatikalische Regeln und syntaktische Strukturen einhält sowie passendes Vokabular verwendet, was zu sprachlich korrekten und natürlich klingenden Antworten führt.
- GPT-Ähnlichkeit: Quantifiziert die semantische Ähnlichkeit zwischen einem Grundwahrheitssatz (Ground Truth) (oder einem Dokument) und dem Vorhersagesatz, der von einem KI-Modell generiert wird.
Im Azure KI Foundry-Portal können Sie die Modell-Benchmarks für alle verfügbaren Modelle untersuchen, bevor Sie ein Modell bereitstellen:

Manuelle Auswertungen
Manuelle Bewertungen werden von menschlichen Bewertern vorgenommen, die die Qualität der Antworten des Modells bewerten. Dieser Ansatz bietet Einblicke in Aspekte, die automatisierte Metriken möglicherweise übersehen, z. B. Kontextrelevanz und Benutzerzufriedenheit. Menschliche Bewerter können Antworten basierend auf Kriterien wie Relevanz, Informativität und Engagement bewerten.
Herkömmliche Metriken für maschinelles Lernen
Herkömmliche Metriken für das maschinelle Lernen sind bei der Bewertung der Modellleistung ebenfalls hilfreich. Eine solche Metrik ist der F1-Score, der das Verhältnis bei der Anzahl der gemeinsamen Wörter zwischen den generierten und den Grundwahrheit-Antworten misst. Der F1-Score ist nützlich für Aufgaben wie die Textklassifizierung und das Abrufen von Informationen, bei denen Präzision und Abruf wichtig sind.
KI-unterstützte Metriken
KI-unterstützte Metriken verwenden fortschrittliche Techniken, um die Modellleistung zu bewerten. Zu diesen Metriken zählen:
- Risiko- und Sicherheitsmetriken: Diese Metriken bewerten die potenziellen Risiken und Sicherheitsbedenken, die mit den Ausgaben des Modells verbunden sind. Sie tragen dazu bei, dass das Modell keine schädlichen oder voreingenommenen Inhalte generiert.
- Metriken für die Qualität der generierten Inhalte: Diese Metriken bewerten die Gesamtqualität des generierten Textes unter Berücksichtigung von Faktoren wie Kreativität, Kohärenz und Einhaltung des gewünschten Stils oder Tons.