Speichern von Vektoren in Azure Database for PostgreSQL
Erinnern Sie sich daran, dass Sie in einer Vektordatenbank gespeicherte Vektoren einbetten müssen, um eine semantische Suche auszuführen. Azure Database for PostgreSQL – Flexible Server kann als Vektordatenbank mit der vector-Erweiterung verwendet werden.
Einführung in vector
Die Open-Source-vector-Erweiterung bietet Vektorspeicher, Ähnlichkeitsabfragen und andere Vektorvorgänge für PostgreSQL. Nach der Aktivierung können Sie vector-Spalten erstellen, um Einbettungen (oder andere Vektoren) zusammen mit anderen Spalten zu speichern.
/* Enable the extension. */
CREATE EXTENSION vector;
/* Create a table containing a 3d vector. */
CREATE TABLE documents (id bigserial PRIMARY KEY, embedding vector(3));
/* Create some sample data. */
INSERT INTO documents (embedding) VALUES
('[1,2,3]'),
('[2,1,3]'),
('[4,5,6]');
Sie können vorhandenen Tabellen Vektorspalten hinzufügen:
ALTER TABLE documents ADD COLUMN embedding vector(3);
Sobald Sie einige Vektordaten haben, können Sie sie zusammen mit normalen Tabellendaten sehen:
# SELECT * FROM documents;
id | embedding
----+-----------
1 | [1,2,3]
2 | [2,1,3]
3 | [4,5,6]
Die vector-Erweiterung unterstützt mehrere Sprachen, z. B. .NET, Python, Java und viele andere. Weitere Informationen finden Sie in ihren GitHub-Repositorys.
Um ein Dokument mit Vektor [1, 2, 3] mithilfe von Npgsql in C# einzufügen, führen Sie Code wie diesen aus:
var sql = "INSERT INTO documents (embedding) VALUES ($1)";
await using (var cmd = new NpgsqlCommand(sql, conn))
{
var embedding = new Vector(new float[] { 1, 2, 3 });
cmd.Parameters.AddWithValue(embedding);
await cmd.ExecuteNonQueryAsync();
}
Einfügen und Aktualisieren von Vektoren
Sobald eine Tabelle über eine Vektorspalte verfügt, können Zeilen mit Vektorwerten hinzugefügt werden, wie zuvor erwähnt.
INSERT INTO documents (embedding) VALUES ('[1,2,3]');
Sie können Vektoren auch mithilfe der COPY-Anweisung in Massen laden (siehe vollständiges Beispiel in Python):
COPY documents (embedding) FROM STDIN WITH (FORMAT BINARY);
Vektorspalten können wie Standardspalten aktualisiert werden:
UPDATE documents SET embedding = '[1,1,1]' where id = 1;
Durchführen einer Kosinusentfernungssuche
Die vector-Erweiterung stellt den v1 <=> v2-Operator zum Berechnen des Kosinusabstands zwischen Vektoren v1 und v2 bereit. Das Ergebnis ist eine Zahl zwischen 0 und 2, wobei 0 „semantisch identisch“ (kein Abstand) und 2 „semantisch entgegengesetzt“ (maximaler Abstand) bedeutet.
Sie können die Begriffe Kosinusabstand und -gleichheit sehen. Denken Sie daran, dass die Kosinusgleichheit zwischen -1 und 1 liegt, wobei -1 „semantisch entgegengesetzt“ und 1 „semantisch identisch“ bedeutet. Beachten Sie, dass similarity = 1 - distance.
Das Ergebnis ist, dass eine Abfrage, die nach aufsteigend Entfernung sortiert ist, zuerst die am wenigsten entfernten (ähnlichsten) Ergebnisse zurückgibt, während eine Abfrage, die nach absteigend Ähnlichkeit sortiert ist, zuerst die ähnlichsten (am wenigsten entfernten) Ergebnisse zurückgibt.
Hier sind einige Vektoren und ihre Entfernungen und Ähnlichkeiten, um die Konzepte zu veranschaulichen. Sie können diese Berechnung selbst durchführen, indem Sie Folgendes ausführen:
SELECT '[1,1]' <=> '[-1,-1]';
Berücksichtigen Sie diese Vektoren:
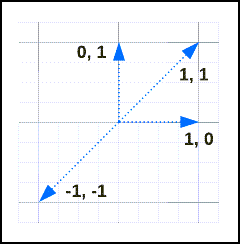
Ihre Ähnlichkeiten und Entfernungen sind:
| v1 | V2 | distance | Ähnlichkeit |
|---|---|---|---|
[1, 1] |
[1, 1] |
0 | 1 |
[1, 1] |
[-1, -1] |
2 | -1 |
[1, 0] |
[0, 1] |
1 | 0 |
Führen Sie diese Abfrage aus, um die Dokumente in der Reihenfolge der Nähe zum Vektor [2, 3, 4] abzurufen:
SELECT
*,
embedding <=> '[2,3,4]' AS distance
FROM documents
ORDER BY distance;
Ergebnisse:
id | embedding | distance
----+-----------+-----------------------
3 | [4,5,6] | 0.0053884541273605535
1 | [1,2,3] | 0.007416666029069763
2 | [2,1,3] | 0.05704583272761632
Das Dokument mit id=3 ähnelt der Abfrage am meisten, gefolgt von id=1, und zuletzt von id=2.
Fügen Sie der SELECT-Abfrage eine LIMIT N-Klausel hinzu, um die N ähnlichsten Dokumente zurückzugeben. So rufen Sie z. B. das ähnlichste Dokument ab:
SELECT
*,
embedding <=> '[2,3,4]' AS distance
FROM documents
ORDER BY distance
LIMIT 1;
Ergebnisse:
id | embedding | distance
----+-----------+-----------------------
3 | [4,5,6] | 0.0053884541273605535