Entwurf für die Überwachung
Im Rahmen einer MLOps-Architektur (Machine Learning Operations) sollten Sie darüber nachdenken, wie Sie Ihre Machine Learning-Lösung überwachen.
Die Überwachung ist in jeder MLOps-Umgebung von Vorteil. Sie sollten das Modell, die Daten und die Infrastruktur überwachen, um Metriken zu sammeln, die Ihnen bei der Entscheidung über die erforderlichen nächsten Schritte helfen.
Überwachen des Modells
In den meisten Fällen möchten Sie die Leistung Ihres Modells überwachen. Während der Entwicklung verwenden Sie MLflow, um Ihre Machine Learning-Modelle zu trainieren und nachzuverfolgen. Abhängig vom Modell, das Sie trainieren, können Sie anhand verschiedener Metriken bewerten, ob das Modell wie erwartet funktioniert.
Um ein Modell in der Produktion zu überwachen, können Sie mit dem trainierten Modell Vorhersagen mit einer kleinen Teilmenge neuer eingehender Daten zu generieren. Indem Sie die Leistungsmetriken für diese Testdaten generieren, können Sie überprüfen, ob das Modell sein Ziel weiterhin erreicht.
Darüber hinaus können Sie auch Probleme mit verantwortungsvoller künstlicher Intelligenz (KI) überwachen. Beispielsweise, ob das Modell faire Vorhersagen macht.
Bevor Sie ein Modell überwachen können, müssen Sie entscheiden, welche Leistungsmetriken Sie überwachen möchten, und welcher Benchmark für die einzelnen Metriken verwendet werden soll. Wann sollten Sie gewarnt werden, wenn das Modell nicht mehr korrekt ist?
Überwachen der Daten
In der Regel trainieren Sie ein Machine Learning-Modell mithilfe eines Datasets aus Verlaufsdaten, die repräsentativ für die neuen Daten sind, die Ihr Modell bei der Bereitstellung erhält. Im Lauf der Zeit ändern verschiedene Trends jedoch möglicherweise das Profil der Daten, was die Genauigkeit Ihres Modells einschränkt.
Nehmen Sie als Beispiel an, ein Modell wurde darauf trainiert, die erwartete Kilometerleistung von Benzin für ein Auto basierend auf der Anzahl Zylinder, der Motorgröße, dem Gewicht und weiteren Merkmalen vorherzusagen. Wenn sich im Lauf der Zeit Fertigungs- und Motortechnologien weiterentwickeln, ändert sich die übliche Kraftstoffeffizienz für Fahrzeuge möglicherweise erheblich. In Folge nimmt die Genauigkeit von Vorhersagen des Modells ab, die auf dem Training mit älteren Daten basieren.
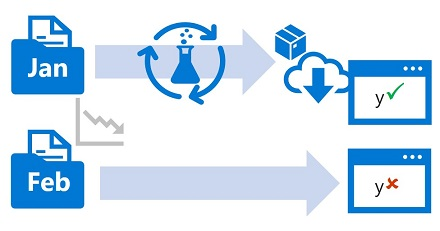
Diese Änderungen von Datenprofilen zwischen den aktuellen und den Trainingsdaten wird als Datendrift bezeichnet. Datendrift kann für Vorhersagemodelle, die in der Produktion verwendet werden, zu einem ernsthaften Problem werden. Deshalb ist es wichtig, im Lauf der Zeit für eine Datendriftüberwachung zu sorgen und Modelle gegebenenfalls neu zu trainieren, um die Genauigkeit von Vorhersagen zu gewährleisten.
Überwachen der Infrastruktur
Neben dem Modell und den Daten sollten Sie auch die Infrastruktur überwachen, um die Kosten zu minimieren und die Leistung zu optimieren.
Während des gesamten Machine Learning-Lebenszyklus verwenden Sie Compute, um Modelle zu trainieren und bereitzustellen. Bei Machine Learning-Projekten in der Cloud erfordert Compute möglicherweise eine Ihrer größten Ausgaben. Sie möchten daher überwachen, ob Ihre Computeressourcen effizient genutzt werden.
Beispielsweise können Sie die Computeauslastung Ihrer Computeressourcen während des Trainings und während der Bereitstellung überwachen. Durch die Überprüfung der Computeauslastung wissen Sie, ob Sie Ihre bereitgestellte Computeinstanz herunterskalieren können, oder ob Sie horizontal skalieren müssen, um Kapazitätseinschränkungen zu vermeiden.
Tipp
Erfahren Sie mehr über die Überwachung des Azure Machine Learning-Arbeitsbereichs und seiner Ressourcen.