Erkunden einer MLOps-Architektur
Als wissenschaftliche Fachkraft für Daten möchten Sie das beste Machine Learning-Modell trainieren. Um das Modell zu implementieren, möchten Sie es in einem Endpunkt bereitstellen und in eine Anwendung integrieren.
Im Laufe der Zeit möchten Sie das Modell vielleicht erneut trainieren. Beispielsweise können Sie das Modell erneut trainieren, wenn Sie über mehr Trainingsdaten verfügen.
Im Allgemeinen möchten Sie nach dem Trainieren eines Machine Learning-Modells das Modell für die Unternehmensebene vorbereiten. Um das Modell vorzubereiten und zu operationalisieren, müssen Sie Folgendes ausführen:
- Konvertieren Sie das Modelltraining in eine robuste und reproduzierbare Pipeline.
- Testen Sie den Code und das Modell in einer Entwicklungsumgebung.
- Stellen Sie das Modell in einer Produktionsumgebung bereit.
- Automatisieren Sie den gesamten Prozess.
Einrichten von Umgebungen für Entwicklung und Produktion
Bei MLOps ist eine Umgebung, ähnlich wie bei DevOps, eine Sammlung von Ressourcen. Diese Ressourcen werden zur Bereitstellung einer Anwendung oder bei Machine Learning-Projekten zur Bereitstellung eines Modells verwendet.
Hinweis
In diesem Modul beziehen wir uns auf die DevOps-Interpretation von Umgebungen. Beachten Sie, dass Azure Machine Learning auch den Begriff „Umgebungen“ verwendet, um eine Sammlung von Python-Paketen zu beschreiben, die zum Ausführen eines Skripts benötigt werden. Diese beiden Konzepte von Umgebungen sind unabhängig voneinander.
Mit wie vielen Umgebungen Sie arbeiten, hängt von Ihrer Organisation ab. In der Regel gibt es mindestens zwei Umgebungen: Entwicklungsumgebung oder Dev und Produktionsumgebung oder Prod. Außerdem können Sie dazwischen Umgebungen wie Staging oder Vorproduktion (Pre-Prod) einrichten.
Dies ist ein typischer Ansatz:
- Experimentieren Sie mit dem Trainieren von Modellen in der Entwicklungsumgebung.
- Verschieben Sie das beste Modell in die Umgebung Staging oder Vorproduktion, um das Modell bereitzustellen und zu testen.
- Schließlich geben Sie das Modell für die Produktionsumgebungfrei, um es bereitzustellen, sodass die Endbenutzer es verwenden können.
Organisieren von Azure Machine Learning-Umgebungen
Wenn Sie MLOps implementieren und im großen Stil mit Machine Learning-Modellen arbeiten, ist es eine bewährte Methode, mit getrennten Umgebungen für verschiedene Stages zu arbeiten.
Stellen Sie sich vor, Ihr Team verwendet eine Entwicklungs-, Vorproduktions- und Produktionsumgebung. Nicht jeder in Ihrem Team sollte Zugriff auf alle Umgebungen haben. Wissenschaftliche Fachkräfte für Daten dürfen nur in der Entwicklungsumgebung mit Nicht-Produktionsdaten arbeiten, während Techniker für maschinelles Lernen an der Bereitstellung des Modells in der Vorproduktions- und Produktionsumgebung mit Produktionsdaten arbeiten.
Durch getrennte Umgebungen lässt sich der Zugriff auf Ressourcen leichter kontrollieren. Jede Umgebung kann dann einem separaten Azure Machine Learning-Arbeitsbereich zugeordnet werden.

Innerhalb von Azure verwenden Sie die rollenbasierte Zugriffssteuerung (RBAC), um Ihren Kolleg*innen den richtigen Zugriff auf die Teilmenge der Ressourcen zu gewähren, mit denen sie arbeiten müssen.
Alternativ können Sie auch nur einen einzelnen Azure Machine Learning-Arbeitsbereich verwenden. Wenn Sie einen Arbeitsbereich für Entwicklung und Produktion verwenden, haben Sie einen geringeren Azure-Speicherbedarf und weniger Verwaltungsaufwand. RBAC gilt jedoch sowohl für die Entwicklungs- als auch für die Produktionsumgebung, was bedeuten kann, dass Sie den Betroffenen zu wenig oder zu viel Zugriff auf Ressourcen gewähren.
Tipp
Erfahren Sie mehr über bewährte Methoden zur Organisation von Azure Machine Learning-Ressourcen.
Entwerfen einer MLOps-Architektur
Damit das Modell in der Produktion bereitgestellt werden kann, müssen Sie Ihre Lösung skalieren und mit anderen Teams zusammenarbeiten. Gemeinsam mit den übrigen wissenschaftlichen und technischen Fachkräften für Daten sowie dem Infrastrukturteam könnten Sie sich für die folgende Vorgehensweise entscheiden:
- Speichern Sie alle Daten in einem Azure-Blobspeicher, der von der technischen Fachkraft für Daten verwaltet wird.
- Das Infrastrukturteam erstellt alle erforderlichen Azure-Ressourcen, z. B. den Azure Machine Learning-Arbeitsbereich.
- Wissenschaftliche Fachkräfte für Daten konzentrieren sich auf das, was sie am besten können: Entwickeln und Trainieren des Modells (innere Schleife).
- Machine Learning-Techniker stellen die trainierten Modelle bereit (äußere Schleife).
Daher umfasst Ihre MLOps-Architektur die folgenden Teile:
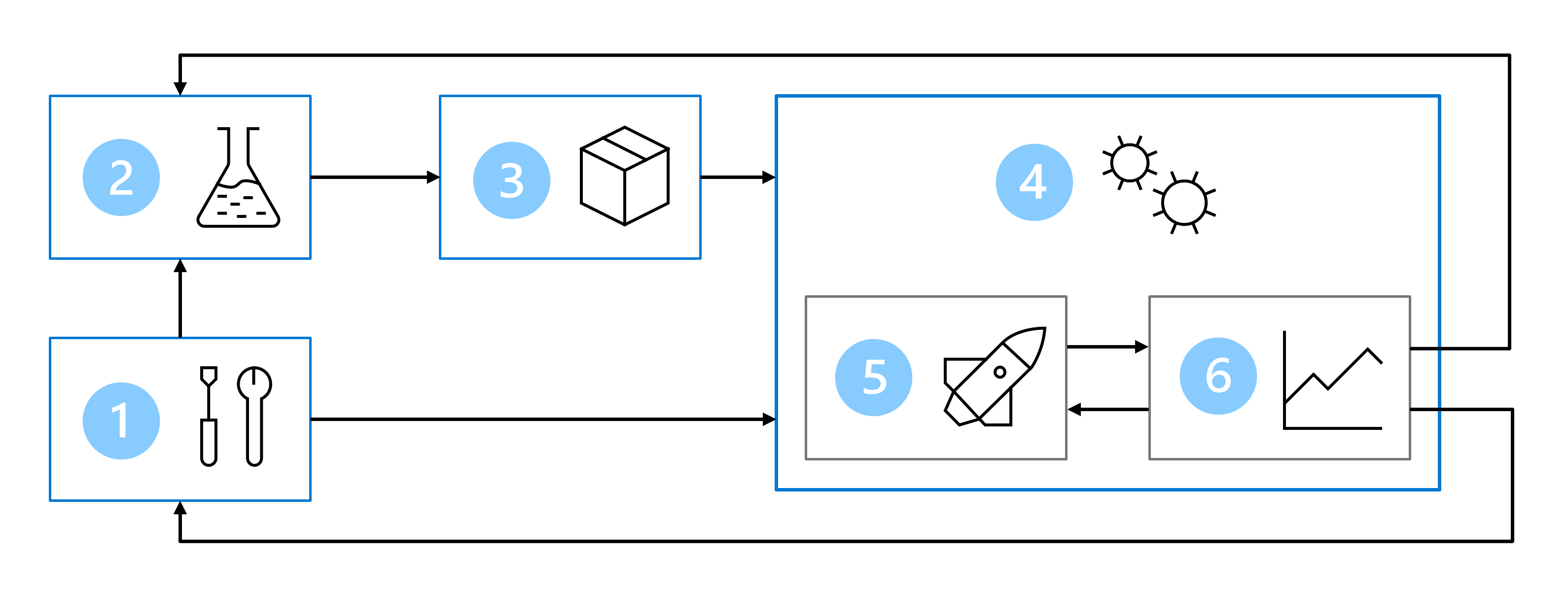
- Setup: Erstellen aller erforderlichen Azure-Ressourcen für die Lösung.
- Modellentwicklung (innere Schleife): Untersuchen und Verarbeiten der Daten zum Trainieren und Auswerten des Modells.
- Continuous Integration: Packen und Registrieren des Modells.
- Modellbereitstellung (äußere Schleife): Bereitstellen des Modells.
- Continuous Deployment: Testen des Modells und Höherstufen in die Produktionsumgebung.
- Überwachung: Überwachen der Modell- und Endpunktleistung.
Wenn Sie mit größeren Teams arbeiten, wird nicht erwartet, dass Sie als wissenschaftliche Fachkraft für Daten für alle Teile der MLOps-Architektur verantwortlich sind. Um Ihr Modell für MLOps vorzubereiten, sollten Sie jedoch darüber nachdenken, wie Ihr Entwurf für die Überwachung und das erneute Training aussehen soll.