Grundlegendes zu Hyperscale in SQL-Datenbank
Azure SQL-Datenbank war seit vielen Jahren auf 4 TB Speicher pro Datenbank beschränkt. Diese Einschränkung war auf eine physische Einschränkung der Azure-Infrastruktur zurückzuführen. Azure SQL-Datenbank – Hyperscale eröffnet neue Horizonte und ermöglicht Datenbanken mit 100 TB oder mehr. Hyperscale führt neue Verfahren für die horizontale Skalierung ein, mit denen bei zunehmenden Datengrößen Computeknoten hinzugefügt werden. Die Kosten von Hyperscale sind mit den Kosten von Azure SQL-Datenbank identisch. Für den Speicher fallen jedoch pro Terabyte Kosten an. Beachten Sie, dass Sie eine Instanz von Azure SQL-Datenbank nach dem Konvertieren zu Hyperscale nicht wieder in eine reguläre Instanz umwandeln können. Hyperscale ist die Möglichkeit der bedarfsgerechten Skalierung einer Architektur.
Hyperscale in Azure SQL-Datenbank ist für die meisten geschäftlichen Workloads eine hervorragende Option, da sie große Flexibilität und Hochleistung mit unabhängig skalierbaren Compute- und Speicherressourcen bietet.
Hyperscale trennt die Abfrageverarbeitungs-Engine, in der die Semantik der verschiedenen Datenmodulen divergiert, von den Komponenten, die für die langfristige Speicherung und Dauerhaftigkeit der Daten sorgen. Auf diese Weise kann die Speicherkapazität nahtlos nach Bedarf horizontal hochskaliert werden.
Die Dienstebene „Hyperscale“ in Azure SQL-Datenbank ist die neueste Dienstebene im vCore-basierten Kaufmodell. Diese Dienstebene bietet eine hochgradig skalierbare Speicher- und Computeleistung, mit der die Speicher- und Computeressourcen für eine Azure SQL-Datenbank-Instanz mithilfe von Azure weit über die Limits der Dienstebenen „Universell“ und „Unternehmenskritisch“ hinaus skaliert werden können.
Vorteile
Die Dienstebene „Hyperscale“ beseitigt viele praktische Einschränkungen, die normalerweise für Clouddatenbanken gelten. Während die meisten anderen Datenbanken durch die auf einem einzelnen Knoten verfügbaren Ressourcen eingeschränkt werden, gelten in der Dienstebene „Hyperscale“ keine solchen Limits. Aufgrund der flexiblen Speicherarchitektur wächst der Speicher nach Bedarf. Hyperscale-Datenbanken werden ohne Definition einer maximalen Größe erstellt. Eine Hyperscale-Datenbank wächst nach Bedarf – und Ihnen wird nur die tatsächlich verwendete Kapazität in Rechnung gestellt. Für leseintensive Workloads bietet die Dienstebene „Hyperscale“ eine schnelle horizontale Skalierung, indem nach Bedarf zusätzliche Replikate zur Abladung von Leseworkloads bereitgestellt werden.
Darüber hinaus ist die Zeit, die zum Erstellen von Datenbanksicherungen oder zum Hoch- oder Herunterskalieren erforderlich ist, nicht mehr an die Menge der Daten in der Datenbank gebunden. Hyperscale-Datenbanken können sofort gesichert werden. Außerdem können Sie eine Datenbank in Minutenschnelle in der Größenordnung von zig Terabyte hoch- oder herunterskalieren. Durch diese Funktion müssen Sie nicht befürchten, durch Ihre Auswahl bei der Anfangskonfiguration eingeschränkt zu werden. Hyperscale bietet auch schnelle Datenbankwiederherstellungen, die in Minuten statt in Stunden oder Tagen ausgeführt werden.
Hyperscale bietet schnelle Skalierbarkeit basierend auf Ihrem Workloadbedarf.
Hoch-/Herunterskalieren: Sie können die primäre Computegröße im Hinblick auf Ressourcen wie CPU und Arbeitsspeicher in konstanter Zeit hochskalieren und anschließend herunterskalieren. Da der Speicher freigegeben ist, wird die Skalierung nach oben und unten nicht mit dem Datenvolumen in der Datenbank verknüpft.
Hoch-/Herunterskalieren: Sie erhalten auch die Möglichkeit, mindestens ein Computereplikat bereitzustellen, mit dem Sie Ihre Leseanforderungen verarbeiten können. Dies bedeutet, dass Sie zusätzliche Computereplikate als schreibgeschützte Replikate verwenden können, um Ihre Leseworkload vom primären Computeknoten auszulagern. Diese Replikate sind nicht nur schreibgeschützt, sondern dienen außerdem als Hot Standbys bei einem Failover vom primären Knoten.
Die Bereitstellung der einzelnen zusätzlichen Computereplikate kann in konstanter Zeit erfolgen und ist ein Onlinevorgang. Sie können eine Verbindung mit schreibgeschützten Computereplikaten herstellen, indem Sie das Argument ApplicationIntent in Ihrer Verbindungszeichenfolge auf ReadOnly festlegen. Verbindungen mit der Anwendungsabsicht ReadOnly werden automatisch an eines der schreibgeschützten Computereplikate weitergeleitet.
Hyperscale trennt das Abfrageverarbeitungsmodul von den Komponenten, die langfristige Speicherung und Dauerhaftigkeit für die Daten bereitstellen. Diese Architektur bietet die Möglichkeit, die Speicherkapazität problemlos nach Bedarf (ursprüngliches Ziel sind 100 TB) und auch die Computeressourcen schnell zu skalieren.
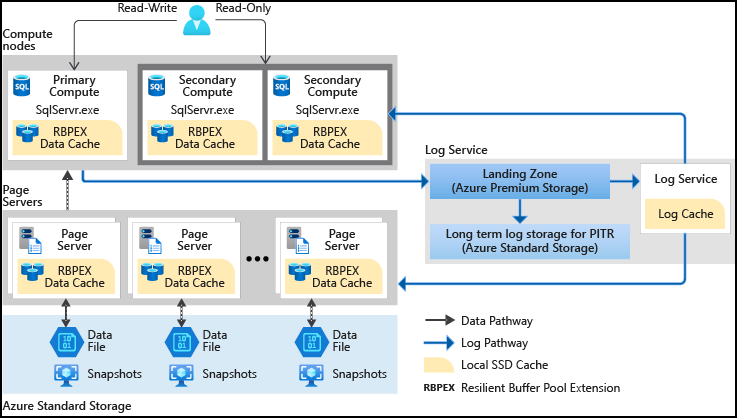
Sicherheitshinweise
Die Sicherheit der Hyperscale-Dienstebene teilt die gleichen großen Funktionen wie die anderen Azure SQL-Datenbankebenen. Sie werden geschützt vom Defense-in-Depth-Schichtenmodell, das in der folgenden Abbildung dargestellt ist und von außen nach innen durchlaufen wird:
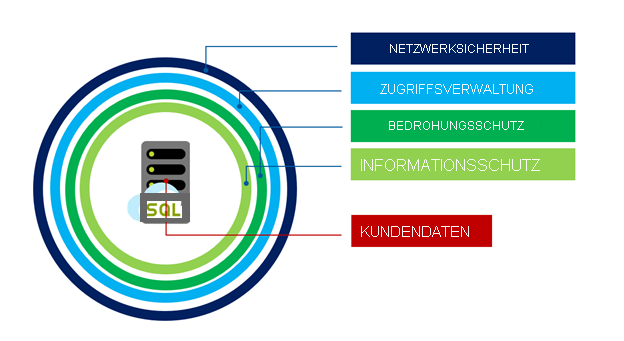
Netzwerksicherheit ist die erste Schutzebene und verwendet IP-Firewallregeln, um den Zugriff basierend auf der ursprünglichen IP-Adresse und Virtual Network-Firewallregeln zu ermöglichen und um die Möglichkeit zu bieten, Kommunikationen von ausgewählten Subnetzen in einem virtuellen Netzwerk entgegenzunehmen.
Zugriffsverwaltung wird über die folgenden Authentifizierungsmethoden bereitgestellt, um sicherzustellen, dass ein Benutzer der ist, der er angibt zu sein:
- SQL-Authentifizierung
- Microsoft Entra-Authentifizierung
- Windows-Authentifizierung für Microsoft Entra-Prinzipale (Vorschau)
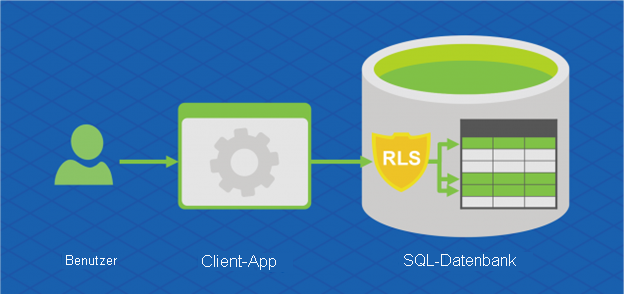
Hyperscale in Azure SQL-Datenbank unterstützt auch Sicherheit auf Zeilenebene. Mithilfe der Sicherheit auf Zeilenebene können Kunden den Zugriff auf die Zeilen in einer Datenbanktabelle auf Grundlage der Merkmale des Benutzers steuern, der eine Abfrage ausführt (z.B. Gruppenmitgliedschaft oder Ausführungskontext).
Threat Protection-Funktionen in Überwachungs- und Bedrohungserkennungsfunktionen. Bei der Überwachung von SQL-Datenbank und SQL Managed Instance werden Datenbankaktivitäten nachverfolgt, und Sie erhalten Unterstützung bei der Einhaltung von Sicherheitsstandards, indem Datenbankereignisse in einem Überwachungsprotokoll in einem Azure Storage-Konto des Kunden aufgezeichnet werden. Advanced Threat Protection kann pro Server für eine zusätzliche Gebühr aktiviert werden und analysiert Ihre Protokolle, um ungewöhnliches Verhalten und potenziell schädliche Zugriffs- oder Missbrauchsversuche auf Datenbanken zu erkennen. Warnungen werden für verdächtige Aktivitäten wie SQL-Injektion, potenzielle Dateninfiltration und Brute-Force-Angriffe oder für Anomalien in den Zugriffsmustern erstellt, um Berechtigungserweiterungen und die Verwendung gefährdeter Anmeldeinformationen zu erfassen.
Information Protection wird auf folgende verschiedene Arten bereitgestellt:
- Transport Layer Security (Verschlüsselung bei der Übertragung)
- Transparent Data Encryption (Verschlüsselung im Ruhezustand)
- Schlüsselverwaltung mit Azure Key Vault
- Always Encrypted (Verschlüsselung während der Verwendung)
- Dynamische Datenmaskierung
Überlegungen zur Leistung
Die Dienstebene „Hyperscale“ ist für Kunden konzipiert, die große lokale SQL Server-Datenbanken verwenden und ihre Anwendungen durch eine Migration zur Cloud modernisieren möchten, oder für Kunden, die bereits Azure SQL-Datenbank verwenden und das Potenzial zum Datenbankwachstum noch umfassender ausschöpfen möchten. Außerdem eignet sich Hyperscale für Kunden, die eine hohe Leistung und Skalierbarkeit wünschen.
Hyperscale bietet die folgenden Leistungsfunktionen:
- Nahezu sofortige Datenbanksicherungen (basierend auf in Azure Blob Storage gespeicherten Dateimomentaufnahmen) unabhängig von der Größe und ohne E/A-Auswirkung auf Computeressourcen.
- Schnelle Datenbankwiederherstellungen (basierend auf Dateimomentaufnahmen) in Minuten statt Stunden oder Tagen (kein von der Datengröße abhängiger Vorgang).
- Höhere Gesamtleistung aufgrund eines höheren Transaktionsprotokolldurchsatzes und schnellerer Transaktionscommits unabhängig von Datenmengen.
- Schnelle Aufskalierung: Sie können ein oder mehrere schreibgeschützte Replikate zum Abladen Ihrer Leseworkload und zur Verwendung als unmittelbar betriebsbereite Standbyserver bereitstellen.
- Schnelle Hochskalierung: Sie können Ihre Computeressourcen in konstanter Zeit hochskalieren, um hohe Workloads nach Bedarf zu bewältigen, und anschließend wieder herunterskalieren, sobald sie nicht mehr benötigt werden.
Hinweis
Hyperscale in SQL-Datenbank unterstützt die folgenden Features nicht:
- Verwaltete SQL-Instanz
- Pools für elastische Datenbanken
- Georeplikation
- Statistik zur Abfrageleistung
Bereitstellen von Hyperscale in Azure SQL-Datenbank
So stellen Sie Azure SQL-Datenbank mit der Hyperscale-Ebene bereit
Navigieren Sie zur Seite SQL-Bereitstellungsoption auswählen.
Behalten Sie unter SQL-Datenbanken für Einzeldatenbank den festgelegten Wert Ressourcentyp bei, und wählen Sie Erstellen aus.
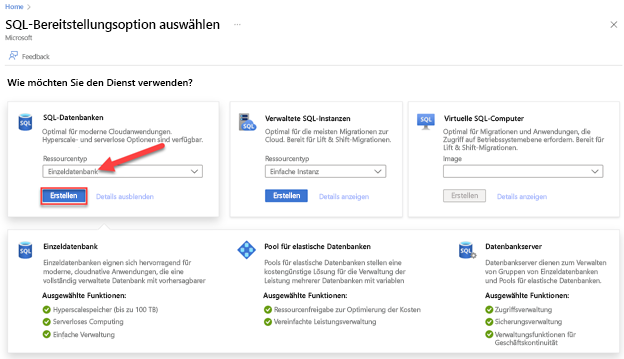
Wählen Sie auf der Registerkarte Grundlagen auf der Seite SQL-Datenbank erstellen den gewünschten Abonnement-, Ressourcengruppen- und Datenbanknamen aus.
Wählen Sie den Link Neu erstellen für den Server, und füllen Sie die Informationen des neuen Servers aus, wie etwa Servername, Serveradministratoranmeldung und Speicherort.
Klicken Sie unter Compute + Speicher auf Datenbank konfigurieren.
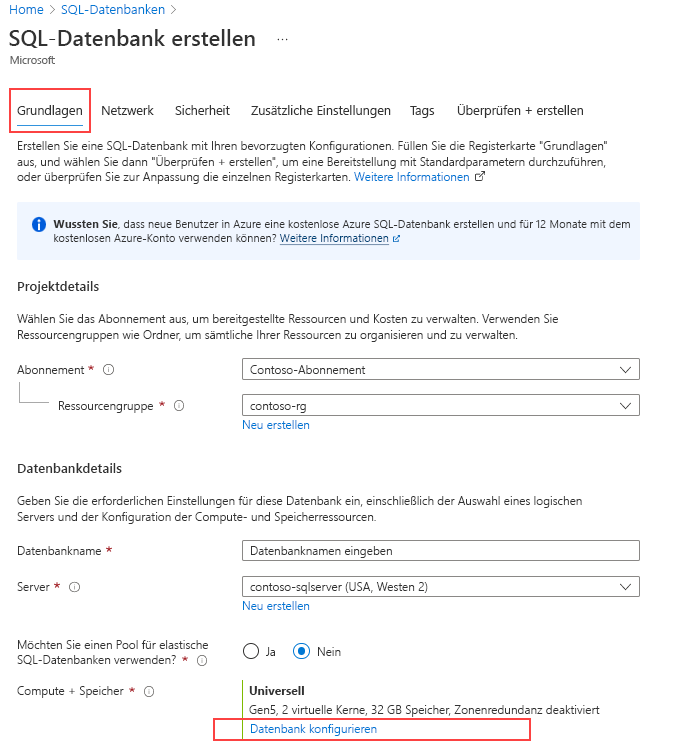
Wählen Sie für die Dienstebene die Option Hyperscale aus.
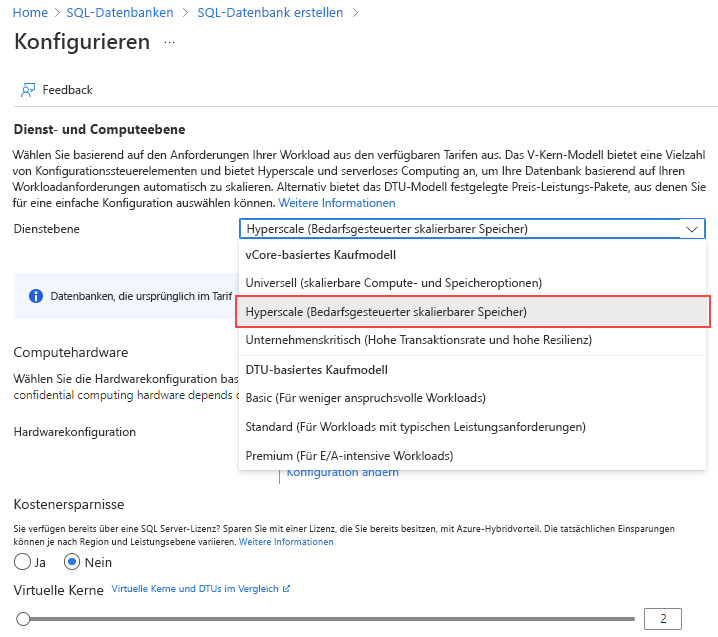
Wählen Sie unter Hardwarekonfiguration den Link Konfiguration ändern aus. Überprüfen Sie die verfügbaren Hardwarekonfigurationen, und wählen Sie die am besten geeignete Konfiguration für Ihre Datenbank aus. In diesem Beispiel wählen wir die Gen5-Konfiguration aus.
Wählen Sie „OK“ aus, um die Hardwaregenerierung zu bestätigen.
Passen Sie optional den Schieberegler Virtuelle Kerne an, wenn Sie die Anzahl virtueller Kerne für Ihre Datenbank erhöhen möchten. Für dieses Beispiel wählen wir 2 virtuelle Kerne aus.
Passen Sie den Schieberegler für sekundäre Hochverfügbarkeitsreplikate an, um ein Hochverfügbarkeitsreplikat (HA) zu erstellen. Wählen Sie Übernehmen.
Klicken Sie auf Weiter: Netzwerk aus (im unteren Bereich der Seite).
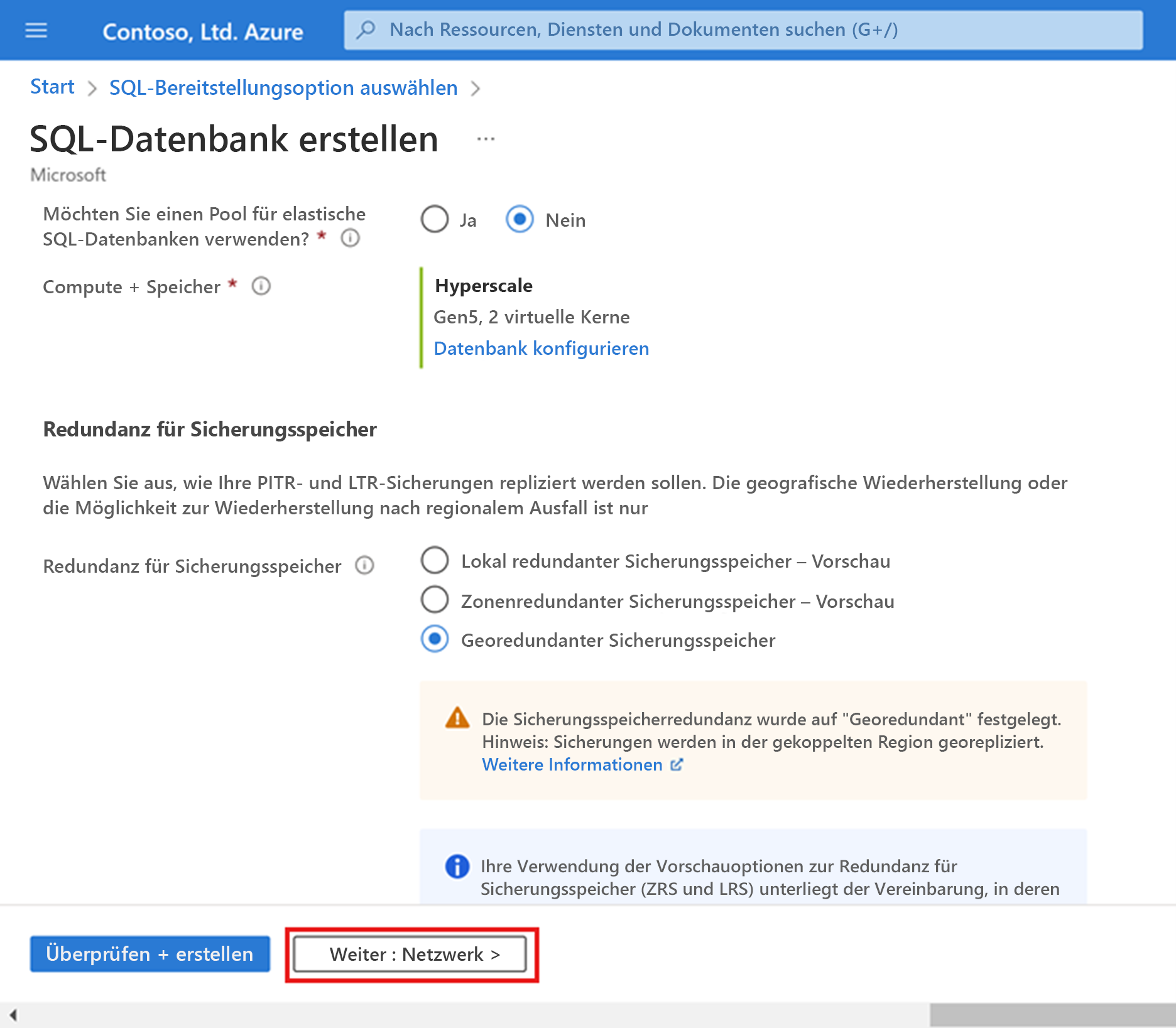
Setzen Sie für Firewallregeln auf der Registerkarte Netzwerk die Einstellung Aktuelle Client-IP-Adresse auf Ja. Behalten Sie für Azure-Diensten und -Ressourcen den Zugriff auf diese Servergruppe gestatten den Wert Nein bei.
Wählen Sie Weiter: Sicherheit unten auf der Seite aus.
Wählen Sie auf der Registerkarte Überprüfen + erstellen die Option Erstellen aus.
