Die PaaS-Optionen für die Bereitstellung von SQL Server in Azure
Platform as a Service (PaaS) bietet eine vollständige Entwicklungs- und Bereitstellungsumgebung in der Cloud, die sich für einfache, cloudbasierte Anwendungen und größere, komplexe Unternehmensanwendungen eignet.
Azure SQL-Datenbank und Azure SQL Managed Instance sind Teil des PaaS-Angebots für Azure SQL.
Azure SQL-Datenbank: Teil einer Produktfamilie, die auf dem SQL Server-Modul basiert, in der Cloud. Entwickler erhalten ein großes Maß an Flexibilität beim Erstellen neuer Anwendungsdienste und differenzierte Bereitstellungsoptionen im großen Stil. SQL-Datenbank bietet eine Lösung mit geringem Wartungsaufwand, die eine hervorragende Option für bestimmte Workloads sein kann.
Azure SQL Managed Instance: Eignet sich am besten für die meisten Migrationsszenarien zur Cloud, da sie vollständig verwaltete Dienste und Funktionen bereitstellt.
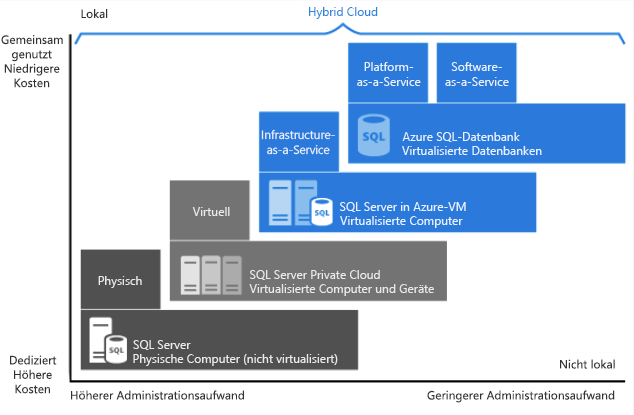
Wie Sie im Bild oben sehen können, bietet jedes dieser Angebote eine bestimmte Administrationsebene in Bezug auf die Infrastruktur und den Grad der Kosteneffizienz.
Bereitstellungsmodelle
Azure SQL-Datenbank ist in zwei verschiedenen Bereitstellungsmodellen verfügbar:
Einzeldatenbank: eine einzelne Datenbank, die datenbankweise abgerechnet und verwaltet wird Sie verwalten jede Ihrer Datenbanken einzeln aus Skalierungs- und Datengrößenperspektive. Jede in diesem Modell bereitgestellte Datenbank verfügt über eigene dedizierte Ressourcen, auch wenn sie auf demselben logischen Server bereitgestellt wird.
Pools für elastische Datenbanken: eine Gruppe von Datenbanken, die zusammen verwaltet werden und gemeinsame Ressourcen nutzen Pools für elastische Datenbanken bieten eine kostengünstige Lösung für das SaaS-Anwendungsmodell (Software-as-a-Service), da Ressourcen von allen Datenbanken gemeinsam genutzt werden. Sie können Ressourcen entweder basierend auf dem DTU-basierten Kaufmodell oder dem auf virtuellen Kernen basierenden Kaufmodell konfigurieren.
Kaufmodell
In Azure werden alle Dienste von physischer Hardware unterstützt, und Sie können aus zwei verschiedenen Einkaufsmodellen wählen:
Datenbanktransaktionseinheit (Database Transaction Unit, DTU)
DTUs werden anhand einer Formel berechnet, die Compute- und Speicherressourcen sowie E/A-Ressourcen kombiniert. Sie sind eine gute Wahl für Kunden, die einfache, vorkonfigurierte Ressourcenoptionen wünschen.
Das DTU-Einkaufsmodell verfügt über verschiedene Serviceebenen wie Basic, Standard und Premium. Jede Ebene umfasst unterschiedliche Funktionen, die bei der Auswahl dieser Plattform eine Vielzahl von Optionen bieten.
In Bezug auf die Leistung wird die Basic-Ebene für weniger anspruchsvolle Workloads verwendet, während Premium für intensive Workloadanforderungen verwendet wird.
Compute- und Speicherressourcen sind von der DTU-Ebene abhängig und bieten eine Reihe von Leistungsfunktionen mit einem festen Speicherlimit, einer festen Sicherungsaufbewahrung und festen Kosten.
Hinweis
Das DTU-Einkaufsmodell wird nur von Azure SQL-Datenbank unterstützt.
Weitere Informationen über das DTU-basierte Kaufmodell finden Sie in der Übersicht über das DTU-basierte Kaufmodell.
Virtueller Kern
Das vCore-basierte Kaufmodell ermöglicht es Ihnen, eine bestimmte Anzahl virtueller Kerne für Ihre jeweiligen Arbeitsauslastungen zu erwerben. Das vCore-basierte Modell ist das Standardkaufmodell beim Erwerb von Azure SQL-Datenbank-Ressourcen. Bei vCore-Datenbanken besteht eine bestimmte Beziehung zwischen der Anzahl der Kerne und der Menge an Arbeitsspeicher und Speicher, die für die Datenbank bereitgestellt wird. Das vCore-basierte Kaufmodell wird von Azure SQL-Datenbank oder Azure SQL Managed Instance unterstützt.
Auch vCore-Datenbanken können in drei verschiedenen Dienstebenen erworben werden:
Universell: Diese Ebene ist für universelle Arbeitsauslastungen vorgesehen. Sie wird durch Azure Storage Premium unterstützt Sie weist eine höhere Latenz als die Ebene „Unternehmenskritisch“ auf. Außerdem werden die folgenden Computeebenen bereitgestellt:
- Bereitgestellt: Computeressourcen werden vorab zugewiesen. Abrechnung pro Stunde basierend auf konfigurierten virtuellen Kernen
- Serverlos: Computeressourcen werden automatisch skaliert. Abrechnung pro Sekunde basierend auf verwendeten virtuellen Kernen
Unternehmenskritisch: Diese Ebene ist für hochleistungsfähige Arbeitsauslastungen vorgesehen und bietet unter allen Dienstebenen die geringste Latenz. Diese Ebene basiert auf lokalen SSDs statt auf Azure Blob Storage. Sie bietet zudem die höchste Ausfallsicherheit und ein integriertes, schreibgeschütztes Datenbankreplikat, auf das Berichterstellungsworkloads ausgelagert werden können.
Hyperscale: Hyperscale-Datenbanken können auf eine Größe weit jenseits der 4 TB skaliert werden, auf die die anderen Azure SQL-Datenbank-Angebote beschränkt sind, und eine individuelle Architektur aufweisen, die Datenbanken mit bis zu 100 TB unterstützt.
Serverlos
Der Name „Serverlos“ ist unter Umständen etwas verwirrend, da Sie Ihre Azure SQL-Datenbank-Instanz weiterhin auf einem logischen Server bereitstellen, zu dem Sie eine Verbindung herstellen. Im Computetarif „Serverlos“ in Azure SQL-Datenbank werden Ressourcen einer bestimmten Datenbank auf Grundlage der Workload-Nachfrage automatisch hoch- oder herunterskaliert. Sind für eine Arbeitsauslastung keine Computeressourcen mehr erforderlich, wird die Datenbank „angehalten“. Während die Datenbank inaktiv ist, fallen lediglich Gebühren für den Speicher an. Wenn ein Verbindungsversuch erfolgt, wird die Datenbank wieder in Betrieb genommen und verfügbar gemacht.
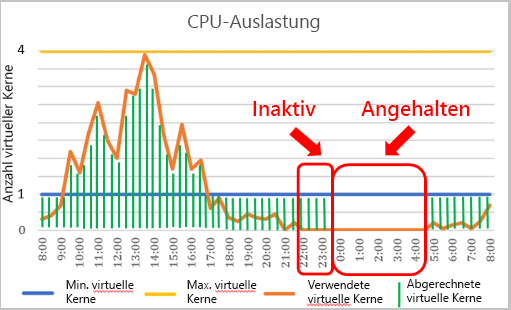
Die Einstellung, die das Aussetzen der Datenbank steuert, heißt „autopause delay“ (Verzögerung durch automatisches Anhalten) und weist einen Mindestwert von 60 Minuten sowie einen Maximalwert von sieben Tagen auf. Diese Werte geben an, wie lange sich die Datenbank im Leerlauf befinden darf, bevor sie angehalten wird.
Wenn die Datenbank für den angegebenen Zeitraum inaktiv ist, wird sie angehalten, bis eine nachfolgende Verbindungsherstellung versucht wird. Das Konfigurieren eines automatischen Computeskalierungsbereichs und einer Verzögerung für automatisches Anhalten wirken sich auf die Leistung und Computekosten der Datenbank aus.
Alle Anwendungen, die den serverlosen Tarif verwenden, sollten Verbindungsfehler verarbeiten können und eine Wiederholungslogik enthalten, da beim Herstellen einer Verbindung zu einer angehaltenen Datenbank ein Verbindungsfehler auftritt.
Ein weiterer Unterschied zwischen dem serverlosen und dem normalem vCore-Modell von Azure SQL-Datenbank besteht darin, dass Sie im serverlosen Tarif eine minimale und eine maximale Anzahl virtueller Kerne angeben können. Die Grenzwerte für den Arbeitsspeicher und die E/A verlaufen proportional zum angegebenen Bereich.
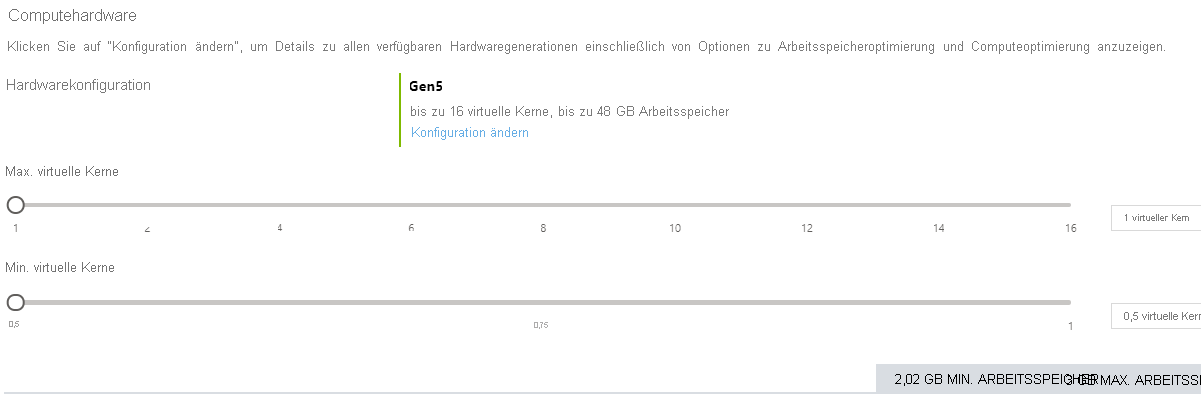
Die obige Abbildung zeigt den Konfigurationsbildschirm für eine serverlose Datenbank im Azure-Portal. Der kleinstmögliche Mindestwert liegt bei einem halben virtuellen Kern, der höchstmögliche Wert bei 16 virtuellen Kernen.
„Serverlos“ ist nicht vollständig mit allen Funktionen in Azure SQL-Datenbank kompatibel, da einige von ihnen erfordern, dass Hintergrundprozesse jederzeit ausgeführt werden können, wie etwa:
- Georeplikation
- Langfristiges Aufbewahren von Sicherungen
- Eine Auftragsdatenbank in elastischen Aufträgen
- Die Synchronisierungsdatenbank in der SQL-Datensynchronisierung (die Datensynchronisierung ist ein Dienst, der Daten zwischen einer Gruppe von Datenbanken repliziert)
Hinweis
„SQL-Datenbank – serverlos“ wird derzeit nur von der Ebene „Universell“ im vCore-basierten Kaufmodell unterstützt.
Backups
Eines der wichtigsten Features des Platform as a Service-Angebots sind Sicherungen. In diesem Fall werden Sicherungen automatisch durchgeführt, ohne dass Sie eingreifen müssen. Sicherungen werden im georedundanten Azure-Blobspeicher gespeichert und je nach Dienstebene der Datenbank standardmäßig für 7 bis 35 Tage aufbewahrt. Der Standardaufbewahrungszeitraum beträgt bei Basic- und vCore-Datenbanken sieben Tage. Bei vCore-Datenbanken kann dieser Wert vom Administrator angepasst werden. Der Aufbewahrungszeitraum kann durch Konfigurieren der Langzeitaufbewahrung (Long-Term Retention, LTR) verlängert werden, sodass Sie Sicherungen bis zu 10 Jahre lang aufbewahren können.
Sie können auch den georedundanten Blobspeicher mit Lesezugriff verwenden, um Redundanz zu gewährleisten. Dieser Speicher repliziert Ihre Datenbanksicherungen in eine sekundäre Region Ihrer Wahl. Außerdem ermöglicht er es Ihnen, bei Bedarf aus dieser sekundären Region zu lesen. Manuelle Sicherungen von Datenbanken werden nicht unterstützt. Daher verweigert die Plattform manuelle Sicherungen.
Datenbanksicherungen erfolgen nach einem bestimmten Zeitplan:
- Vollständig: einmal pro Woche
- Differenziell: alle zwölf Stunden
- Protokoll: je nach Transaktionsprotokollaktivität alle fünf bis zehn Minuten
Dieser Sicherungszeitplan sollte die Anforderungen der meisten Recovery Point und Recovery Time Objectives (RPO/RTO) erfüllen. Alle Kunden sollten jedoch prüfen, ob die Zeitpläne ihren geschäftlichen Anforderungen entsprechen.
Es gibt mehrere Optionen zum Wiederherstellen einer Datenbank. Aufgrund der Beschaffenheit von Platform as a Service-Modellen können Datenbanken nicht manuell mit herkömmlichen Methoden wiederhergestellt werden, z. B. mithilfe des T-SQL-Befehls RESTORE DATABASE.
Unabhängig von der implementierten Wiederherstellungsmethode ist es nicht möglich, eine vorhandene Datenbank wiederherzustellen. Muss eine Datenbank wiederhergestellt werden, muss die vorhandene Datenbank vor dem Initiieren des Wiederherstellungsprozesses gelöscht oder umbenannt werden. Beachten Sie außerdem, dass die Wiederherstellungszeiten je nach Plattformdienstebene nicht garantiert sind und schwanken können. Es wird empfohlen, die Wiederherstellung zu testen, um eine Baselinemetrik zu ihrer potenziellen Dauer zu ermitteln.
Verfügbare Wiederherstellungsoptionen:
Wiederherstellung über das Azure-Portal: Im Azure-Portal können Sie eine Datenbank auf demselben Azure SQL-Datenbank-Server wiederherstellen oder bei der Wiederherstellung eine neue Datenbank auf einem neuen Server in einer beliebigen Azure-Region erstellen.
Wiederherstellung mithilfe von Skriptsprachen: Datenbankwiederherstellungen können sowohl über PowerShell als auch über die Azure CLI erfolgen.
Hinweis
Reine Kopiesicherungen in Azure Blob Storage sind für SQL Managed Instance verfügbar. SQL-Datenbank unterstützt dieses Feature nicht.
Weitere Informationen zu automatisierten Sicherungen finden Sie unter Automatisierte Sicherungen – Azure SQL-Datenbank und Azure SQL Managed Instance.
Aktive Georeplikation
Die Georeplikation ist ein Feature für die Geschäftskontinuität, mit dem Datenbanken asynchron auf bis zu vier sekundäre Replikate repliziert werden. Wenn Transaktionen auf das primäre Replikat (und die zugehörigen Replikate innerhalb derselben Region) committet werden, werden die Transaktionen an die sekundären Replikate gesendet und dort neu eingespielt. Da diese Kommunikation asynchron verläuft, muss die aufrufende Anwendung nicht warten, bis das sekundäre Replikat die Transaktion committet, bevor SQL Server die Kontrolle an den Aufrufer zurückgibt.
Die sekundären Datenbanken sind lesbar und können zum Auslagern schreibgeschützter Workloads verwendet werden. Auf diese Weise werden Ressourcen für transaktionale Workloads auf dem primären Replikat freigegeben, und die Daten werden näher bei Ihren Endbenutzern platziert. Darüber hinaus können sich die sekundären Datenbanken in derselben Region wie die primäre Datenbank oder in einer anderen Azure-Region befinden.
Bei der Georeplikation können Failover entweder manuell durch den Benutzer oder durch die Anwendung initiiert werden. Tritt ein Failover auf, müssen Sie unter Umständen die Verbindungszeichenfolgen der Anwendung auf den neuen Endpunkt der primären Datenbank aktualisieren.
Failovergruppen
Failovergruppen basieren auf der gleichen Technologie, die auch bei der Georeplikation eingesetzt wird, bieten jedoch einen einzigen Verbindungsendpunkt. Der Hauptgrund für die Verwendung von Failovergruppen sind die bereitgestellten Endpunkte, über die Datenverkehr an das passende Replikat weitergeleitet werden kann. Ihre Anwendung kann dann nach einem Failover ohne Änderungen an der Verbindungszeichenfolge eine Verbindung herstellen.