Erkunden von Leistung und Sicherheit
Das Azure-Ökosystem bietet mehrere Leistungs- und Sicherheitsoptionen für die SQL Server-Instanz auf Ihrem virtuellen Azure-Computer. Jede Option bietet mehrere Funktionen, wie etwa verschiedene Datenträgertypen, die die Kapazitäts- und Leistungsanforderungen Ihrer Workload erfüllen.
Speicheraspekt
SQL Server erfordert eine gute Speicherleistung, um eine robuste Anwendungsleistung bereitzustellen, unabhängig davon, ob es sich um eine lokale Instanz oder eine Installation auf einer Azure-VM handelt. Azure bietet eine Vielzahl verschiedener Speicherlösungen, um die Anforderungen Ihrer Workload zu erfüllen. Azure bietet zwar verschiedene Arten von Speicher (Blob-, Datei-, Warteschlangen- oder Tabellenspeicher), jedoch nutzen SQL Server-Workloads in den meisten Fällen von Azure verwaltete Datenträger. Es bestehen jedoch die Ausnahmen, dass eine Failoverclusterinstanz auf Grundlage eines Dateispeichers erstellt werden kann und dass Sicherungen Blobspeicher verwenden. Von Azure verwaltete Datenträger fungieren als Speichergerät auf Blockebene, das Ihrer Azure-VM zur Verfügung gestellt wird. Verwaltete Datenträger bieten einige Vorteile wie eine Verfügbarkeit von 99,999 %, eine skalierbare Bereitstellung (Sie können bis zu 50.000 VM-Datenträger pro Abonnement und pro Region besitzen) und die Integration mit Verfügbarkeitsgruppen und -zonen, um ein höheres Maß an Resilienz im Falle eines Ausfalls bereitzustellen.
Von Azure verwaltete Datenträger bieten zwei Arten der Verschlüsselung. Die serverseitige Azure-Verschlüsselung wird vom Speicherdienst bereitgestellt und dient als Verschlüsselung ruhender Daten. Azure Disk Encryption verwendet BitLocker unter Windows und DM-Crypt unter Linux, um die Verschlüsselung des Betriebssystems und des Datenträgers der VMs bereitzustellen. Beide Technologien können mit Azure Key Vault integriert werden, damit Sie einen eigenen Verschlüsselungsschlüssel verwenden können.
Jeder VM sind mindestens zwei Datenträger zugeordnet:
Betriebssystemdatenträger: Jede VM erfordert einen Betriebssystemdatenträger, der das Startvolume enthält. Bei diesem Datenträger handelt es sich bei einer Windows-VM um das Laufwerk C: und bei einer Linux-VM um /dev/sda1. Das Betriebssystem wird automatisch auf dem Betriebssystemdatenträger installiert.
Temporärer Datenträger: Jede VM enthält einen Datenträger, der für den temporären Speicher verwendet wird. Dieser Speicher ist für Daten vorgesehen, die nicht dauerhaft gespeichert werden müssen, z. B. Seitendateien oder Auslagerungsdateien. Da der Datenträger temporär ist, sollten Sie ihn nicht zum Speichern wichtiger Informationen wie Datenbank- oder Transaktionsprotokolldateien verwenden, da diese bei einer Wartung oder einem Neustart der VM gelöscht werden. Dieses Laufwerk wird unter Windows als D:\ und unter Linux als /dev/sdb1 eingebunden.
Darüber hinaus können Sie zusätzliche Datenträger zu Ihren Azure-VMs hinzufügen, auf denen SQL Server ausgeführt wird. Dies wird empfohlen.
- Datenträger: Der Begriff „Datenträger“ wird zwar im Azure-Portal verwendet, in der Praxis handelt es sich jedoch lediglich um zusätzliche verwaltete Datenträger, die zu einer VM hinzugefügt werden. Diese Datenträger können gepoolt werden, um die verfügbaren IOPS- und Speicherkapazitäten mithilfe von Speicherplätzen unter Windows oder LVM (Logical Volume Manager) unter Linux zu erhöhen.
Darüber hinaus kann jeder Datenträger einem der folgenden Typen entsprechen:
| Funktion | Disk Ultra | SSD Premium | SSD Standard | HDD Standard |
|---|---|---|---|---|
| Datenträgertyp | SSD | SSD | SSD | Festplattenlaufwerk |
| Am besten geeignet für | E/A-intensive Workloads | Leistungsabhängige Workloads | Einfache Workloads | Sicherungen, nicht kritische Workloads |
| Maximale Datenträgergröße | 65.536 GiB | 32767 GiB | 32767 GiB | 32767 GiB |
| Max. Durchsatz | 2\.000 MB/s | 900 MB/s | 750 MB/s | 500 MB/s |
| Max. IOPS | 160.000 | 20.000 | 6\.000 | 2\.000 |
Die bewährten Methoden für SQL Server in Azure empfehlen gepoolte Premium-Datenträger für erhöhte IOPS- und Speicherkapazität. Datendateien sollten in ihrem eigenen Pool mit einem Lesecache auf den Azure-Datenträgern gespeichert werden.
Für Transaktionsprotokolldateien hat dieses Zwischenspeichern keine Vorteile, daher sollten diese Dateien in einem eigenen Pool ohne Cache gespeichert werden. TempDB kann optional in einem eigenen Pool oder mithilfe des temporären Datenträgers der VM gespeichert werden. Der temporäre Datenträger bietet niedrige Latenz, da er physisch an den physischen Server angefügt ist, auf dem die VMs ausgeführt werden. Ordnungsgemäß konfigurierte SSD Premium-Datenträger weisen eine Latenz von Millisekunden im einstelligen Bereich auf. Für unternehmenskritische Workloads, die eine geringere Latenz erfordern, sollten Sie SSD Ultra-Datenträger in Erwägung ziehen.
Sicherheitshinweise
Es gibt mehrere Branchenregelungen und -standards, die Azure erfüllt, damit eine kompatible Lösung mit SQL Server erstellt werden kann, die auf einem virtuellen Computer ausgeführt wird.
Microsoft Defender für SQL
Microsoft Defender für SQL bietet die Aktivierung von Azure Security Center-Sicherheitsfunktionen wie z. B. Sicherheitsrisikobewertungen und Sicherheitswarnungen.
Azure Defender für SQL kann verwendet werden, um potenzielle Sicherheitsrisiken in Ihrer SQL Server-Instanz und -Datenbank zu identifizieren und abzuschwächen. Das Feature zur Sicherheitsrisikobewertung kann potenzielle Risiken in Ihrer SQL Server-Umgebung erkennen und Ihnen dabei helfen, Abhilfe zu schaffen. Sie bietet außerdem Erkenntnisse zu Ihrem Sicherheitsstatus und Maßnahmen zum Beheben von Sicherheitsproblemen.
Azure Security Center
Azure Security Center ist ein einheitliches Sicherheitsverwaltungssystem, das verschiedene Sicherheitsaspekte Ihrer Datenumgebung bewertet und Möglichkeiten zu deren Verbesserung bietet. Azure Security Center bietet eine umfassende Ansicht der Sicherheitsintegrität aller Hybrid Cloud-Ressourcen.
Überlegungen zur Leistung
Die meisten vorhandenen lokalen SQL Server-Leistungsfeatures sind auch auf virtuellen Azure-Computern (VMs) verfügbar. Zu den angebotenen Optionen gehört Datenkomprimierung, die die Leistung von E/A-intensiven Workloads verbessern kann, während die Größe der Datenbank verringert wird. Ebenso kann die Tabellen- und Indexpartitionierung die Abfrageleistung großer Tabellen verbessern, während gleichzeitig Leistung und Skalierbarkeit verbessert werden.
Tabellenpartitionierung
Die Tabellenpartitionierung bietet viele Vorteile, wird aber häufig nur berücksichtigt, wenn die Tabelle so groß ist, dass sie beginnt, die Abfrageleistung zu beeinträchtigen. Das Ermitteln, welche Tabellen für die Tabellenpartitionierung in Frage kommen, ist eine gute Methode, die zu weniger Unterbrechungen und Interventionen führen könnte. Wenn Sie Ihre Daten mithilfe Ihrer Partitionsspalte filtern, wird nur auf eine Teilmenge der Daten zugegriffen, nicht auf die gesamte Tabelle. Ebenso verringern Wartungsvorgänge in einer partitionierten Tabelle die Wartungsdauer, z. B. durch Komprimieren bestimmter Daten in einer bestimmten Partition oder durch Neuerstellen bestimmter Partitionen eines Indexes.
Bei der Definition einer Tabellenpartition sind vier Hauptschritte erforderlich:
- Die Dateigruppenerstellung, die die Dateien definiert, die beim Erstellen der Partitionen beteiligt sind
- Die Partitionsfunktionserstellung, die die Partitionsregeln basierend auf der angegebenen Spalte definiert
- Die Partitionsschemaerstellung, die die Dateigruppe jeder Partition definiert
- Die zu partitionierende Tabelle
Im folgenden Beispiel wird veranschaulicht, wie Sie eine Partitionsfunktion für den 1. Januar 2021 bis zum 1. Dezember 2021 erstellen und die Partitionen auf verschiedene Dateigruppen verteilen.
-- Partition function
CREATE PARTITION FUNCTION PartitionByMonth (datetime2)
AS RANGE RIGHT
-- The boundary values defined is the first day of each month, where the table will be partitioned into 13 partitions
FOR VALUES ('20210101', '20210201', '20210301',
'20210401', '20210501', '20210601', '20210701',
'20210801', '20210901', '20211001', '20211101',
'20211201');
-- The partition scheme below will use the partition function created above, and assign each partition to a specific filegroup.
CREATE PARTITION SCHEME PartitionByMonthSch
AS PARTITION PartitionByMonth
TO (FILEGROUP1, FILEGROUP2, FILEGROUP3, FILEGROUP4,
FILEGROUP5, FILEGROUP6, FILEGROUP7, FILEGROUP8,
FILEGROUP9, FILEGROUP10, FILEGROUP11, FILEGROUP12);
-- Creates a partitioned table called Order that applies PartitionByMonthSch partition scheme to partition the OrderDate column
CREATE TABLE Order ([Id] int PRIMARY KEY, OrderDate datetime2)
ON PartitionByMonthSch (OrderDate) ;
GO
Datenkomprimierung
SQL Server bietet verschiedene Optionen zum Komprimieren von Daten. SQL Server speichert zwar immer noch komprimierte Daten in 8-KB-Seiten, aber wenn die Daten komprimiert sind, können mehr Datenzeilen auf einer spezifischen Seite gespeichert werden, wodurch die Abfrage weniger Seiten lesen kann. Das Lesen von weniger Seiten hat einen doppelten Vorteil: Es reduziert die Menge der ausgeführten physischen E/A-Vorgänge, und es ermöglicht die Speicherung von mehr Zeilen im Pufferpool, wodurch der Arbeitsspeicher effizienter genutzt wird. Es wird empfohlen, die Datenbankseitenkomprimierung bei Bedarf zu aktivieren.
Der Nachteil der Komprimierung ist, dass sie einen geringen CPU-Mehraufwand erfordert, in den meisten Fällen überwiegen allerdings die Vorteile bei der Speicher-E/A die zusätzliche Prozessorauslastung bei Weitem.
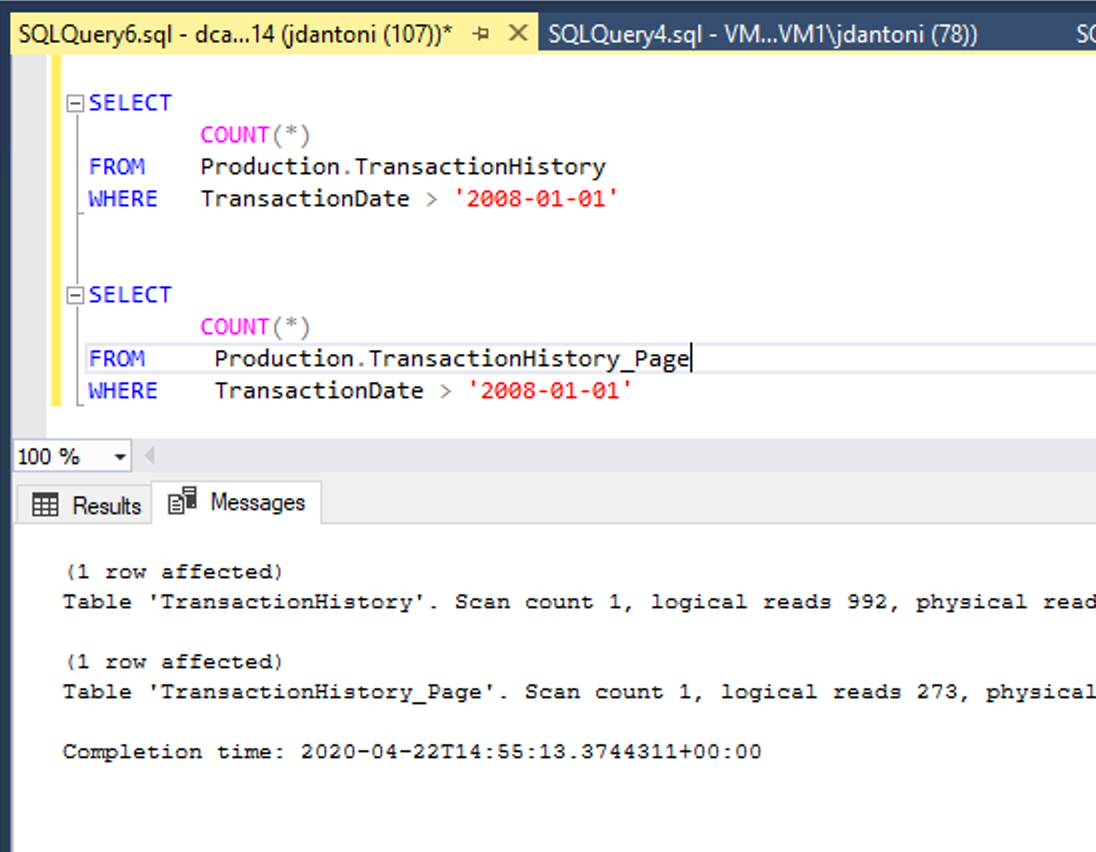
Die obige Abbildung zeigt diesen Leistungsvorteil. Diese Tabellen haben dieselben zugrunde liegenden Indizes. Der einzige Unterschied ist, dass die gruppierten und nicht gruppierten Indizes der Tabelle Production.TransactionHistory_Page seitenkomprimiert sind. Die Abfrage des seitenkomprimierten Objekts führt 72 % weniger logische Lesevorgänge aus als die Abfrage, die die unkomprimierten Objekte verwendet.
Die Komprimierung ist in SQL Server auf der Objektebene implementiert. Jeder Index oder jede Tabelle kann einzeln komprimiert werden, und Sie haben die Möglichkeit, Partitionen innerhalb einer partitionierten Tabelle oder eines Indexes zu komprimieren. Sie können abschätzen, wie viel Speicherplatz Sie sparen, indem Sie die gespeicherte Systemprozedur „sp_estimate_data_compression_savings“ verwenden. Vor SQL Server 2019 unterstützte diese Prozedur weder Columnstore-Indizes noch die Columnstore-Archivierungskomprimierung.
Zeilenkomprimierung: Die Zeilenkomprimierung ist relativ einfach und verursacht keinen großen Mehraufwand. Sie bietet jedoch nicht dasselbe Maß an Komprimierung, das die Seitenkomprimierung bieten kann (gemessen an der prozentualen Verringerung des benötigten Speicherplatzes). Bei der Zeilenkomprimierung wird im Prinzip jeder Wert in jeder Spalte in einer Zeile in dem minimalen Platz gespeichert, der zum Speichern dieses Werts erforderlich ist. Sie verwendet ein Speicherformat mit variabler Länge für numerische Datentypen wie Integer, Float und Decimal und speichert Zeichenfolgen mit fester Länge in einem variablen Längenformat.
Seitenkomprimierung: Die Seitenkomprimierung ist eine Obermenge der Zeilenkomprimierung, da alle Seiten zunächst zeilenkomprimiert werden, bevor die Seitenkomprimierung angewendet wird. Dann wird eine Kombination von Methoden namens Präfix- und Wörterbuchkomprimierung auf die Daten angewendet. Die Präfixkomprimierung eliminiert redundante Daten in einer einzelnen Spalte und speichert Zeiger zurück auf den Seitenkopf. Nach diesem Schritt sucht die Wörterbuchkomprimierung nach sich wiederholenden Werten in einer Seite und ersetzt sie durch Zeiger, was den Speicherplatz weiter reduziert. Je mehr Redundanz in Ihren Daten vorhanden ist, desto größer ist die Platzersparnis, wenn Sie Ihre Daten komprimieren.
Columnstore-Archivierungskomprimierung: Columnstore-Objekte werden immer komprimiert, können aber mit der Archivierungskomprimierung, die den Microsoft XPRESS-Komprimierungsalgorithmus auf die Daten anwendet, noch weiter komprimiert werden. Diese Art der Komprimierung eignet sich am besten für Daten, die nur selten gelesen werden, aber aus gesetzlichen oder geschäftlichen Gründen aufbewahrt werden müssen. Diese Daten werden zwar weiter komprimiert, aber die CPU-Kosten der Dekomprimierung überwiegen in der Regel jeglichen Leistungsgewinn durch E/A-Reduzierung.
Zusätzliche Optionen
Nachfolgend finden Sie eine Liste zusätzlicher SQL Server-Features und -Aktionen, die für Produktionsworkloads berücksichtigt werden sollen:
- Aktivieren Sie die Sicherungskomprimierung.
- Aktivieren Sie die sofortige Dateiinitialisierung für Datendateien
- Begrenzen Sie die automatische Vergrößerung der Datenbank
- Deaktivieren von Autoshrink/Autoclose für die Datenbanken
- Verschieben Sie alle Datenbanken, einschließlich der Systemdatenbanken, auf Datenträger für Daten.
- Verschieben Sie die Verzeichnisse für das SQL Server-Fehlerprotokoll und die Ablaufverfolgungsdateien auf die Datenträger für Daten.
- Max. SQL Server-Arbeitsspeicherlimits festlegen
- Aktivieren Sie „Seiten im Arbeitsspeicher sperren“.
- „Für Ad-hoc-Arbeitsauslastungen optimieren“ für OLTP-Umgebungen mit hoher Auslastung aktivieren
- Aktivieren des Abfragespeichers
- SQL Server-Agent-Aufträge für die Ausführung von DBCC CHECKDB-, index reorganize-, index rebuild- und update statistics-Vorgängen planen
- Integrität und Größe der Transaktionsprotokolldateien überwachen und verwalten
Weitere Informationen zu bewährten Methoden für mehr Leistung finden Sie unter Bewährte Methoden für SQL Server auf Azure-VMs.