Grundlegendes zu Deep Learning-Konzepten
Ihr Gehirn verfügt über Nervenzellen (sogenannte Neuronen), die durch Nervenfortsätze miteinander verbunden sind, die elektrochemische Signale durch das Netz leiten.

Wenn das erste Neuron im Netz stimuliert wird, wird das Eingabesignal verarbeitet. Bei Überschreiten eines bestimmten Schwellenwerts wird das Neuron aktiviert und das Signal an die Neuronen weitergeleitet, mit denen es verbunden ist. Diese Neuronen werden wiederum möglicherweise ebenfalls aktiviert und leiten das Signal an das restliche Netz weiter. Im Laufe der Zeit werden die Verbindungen zwischen den Neuronen durch häufige Nutzung gestärkt, während Sie lernen, wie Sie effektiv reagieren. Wenn Sie beispielsweise das Bild eines Pinguins ansehen, werden die Informationen des Bilds und Ihr Wissen über die Identifikationsmerkmale eines Pinguins über Ihre Neuronenverbindungen verarbeitet. Je mehr Bilder von unterschiedlichen Tieren Ihnen gezeigt werden, desto größer wird Ihr neuronales Netz zur Identifizierung von Tieren anhand ihrer Merkmale. Anders ausgedrückt: Sie können unterschiedliche Tiere immer besser identifizieren.
Deep Learning emuliert diesen biologischen Prozess mit künstlichen neuronalen Netzen, die statt elektrochemischer Reize numerische Eingaben verarbeiten.
Die eingehenden Nervenverbindungen werden durch numerische Eingaben ersetzt, die in der Regel mit x bezeichnet werden. Wenn mehr als ein Eingabewert vorhanden ist, wird x als Vektor mit Elementen namens x1, x2 usw. betrachtet.
Jedem x-Wert ist ein Gewicht (Weight, w) zugeordnet, mit dem die Auswirkungen auf den x-Wert verstärkt oder abgeschwächt werden, um Lernen zu simulieren. Darüber hinaus wird eine Biaseingabe (b) hinzugefügt, um eine differenzierte Kontrolle über das Netz zu ermöglichen. Während des Trainingsprozesses werden die Werte w und b zur Optimierung des Netzes angepasst, damit es „lernt“, die richtigen Ausgaben zu erzeugen.
Das Neuron selbst schließt eine Funktion ein, die eine gewichtete Summe von x, w und b berechnet. Diese Funktion wird wiederum von einer Aktivierungsfunktion umschlossen, die das Ergebnis einschränkt (häufig auf einen Wert zwischen 0 und 1), um zu bestimmen, ob das Neuron eine Ausgabe an die nächste Schicht mit Neuronen im Netz übergibt.
Trainieren eines Deep Learning-Modells
Deep Learning-Modelle sind neuronale Netze, die aus mehreren Schichten künstlicher Neuronen bestehen. Jede Schicht stellt eine Reihe von Funktionen dar, die für die x-Werte mit zugeordneten w-Gewichtungswerten und b-Bias-Werten ausgeführt werden. Die letzte Schicht ergibt eine Ausgabe der y-Bezeichnung, die vom Modell vorhergesagt wird. Bei einem Klassifizierungsmodell (das die wahrscheinlichste Kategorie oder Klasse für die Eingabedaten vorhersagt) ist die Ausgabe ein Vektor mit der Wahrscheinlichkeit für jede mögliche Klasse.
Die folgende Abbildung zeigt ein Deep Learning-Modell, das die Klasse einer Datenentität basierend auf vier Funktionen (den x-Werten) vorhersagt. Die Ausgabe des Modells (die y-Werte) zeigt die Wahrscheinlichkeit für jede der drei möglichen Klassenbezeichnungen.
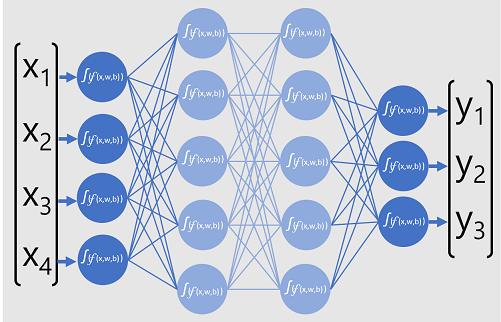
Zum Trainieren des Modells speist ein Deep Learning-Framework mehrere Batches von Eingabedaten ein (deren tatsächliche Bezeichnungswerte bekannt sind), wendet die Funktionen in allen Netzschichten an und misst den Unterschied zwischen den Ausgabewahrscheinlichkeiten und den bekannten tatsächlichen Klassenbezeichnungen der Trainingsdaten. Der aggregierte Unterschied zwischen den Vorhersageausgaben und den tatsächlichen Bezeichnungen wird als Verlust bezeichnet.
Nachdem der aggregierte Verlust für alle Datenbatches berechnet wurde, bestimmt das Deep Learning-Framework mithilfe eines Optimierers, wie die Gewichtungs- und Bias-Werte im Modell angepasst werden müssen, um den Gesamtverlust zu verringern. Diese Anpassungen werden dann per Backpropagation zurück an die Schichten des neuronalen Netzes geleitet. Anschließend werden die Daten wieder an das Netz übergeben und der Verlust neu berechnet. Dieser Prozess wird mehrmals wiederholt (wobei jede Iteration als Epoche bezeichnet wird), bis der Verlust minimiert wurde und das Modell die für eine genaue Vorhersage nötigen Gewichtungs- und Bias-Werte „gelernt“ hat.
Während jeder Epoche werden die Gewichtungs- und Bias-Werte angepasst, um den Verlust zu minimieren. Der Wert der Anpassung richtet sich nach der Lernrate, die Sie im Optimierer angeben. Bei einer zu niedrigen Lernrate kann es sehr lange dauern, bis im Trainingsprozess optimale Werte ermittelt werden. Ist die Lernrate jedoch zu hoch, findet der Optimierer möglicherweise nie die optimalen Werte.