Übung: Ausführen von Abfragen auf einem HDInsight Spark-Cluster
In dieser Übung erfahren Sie, wie Sie auf der Grundlage einer CSV-Datei einen Datenrahmen erstellen und interaktive Spark SQL-Abfragen für einen Apache Spark-Cluster in Azure HDInsight ausführen. In Spark ist ein Dataframe eine verteilte Sammlung von Daten, die in benannten Spalten organisiert sind. Der Datenrahmen entspricht vom Konzept her einer Tabelle in einer relationalen Datenbank oder einem Datenrahmen in R/Python.
In diesem Tutorial lernen Sie Folgendes:
- Erstellen eines Dataframes aus einer CSV-Datei
- Ausführen von Abfragen gegen Dataframes
Erstellen eines Dataframes aus einer CSV-Datei
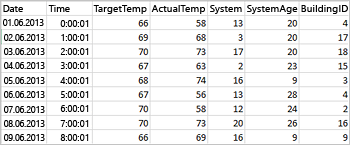
Die folgende CSV-Beispieldatei enthält Temperaturinformationen eines Gebäudes und wird im Dateisystem des Spark-Clusters gespeichert.
Fügen Sie den folgenden Code in eine leere Zelle des Jupyter Notebooks ein und drücken Sie dann UMSCHALT+EINGABE, um den Code auszuführen. Der Code importiert die für dieses Szenario erforderlichen Typen.
from pyspark.sql import * from pyspark.sql. types import *Wenn Sie eine interaktive Abfrage in Jupyter ausführen, wird im Webbrowserfenster oder in der Registerkartenbeschriftung ein (Belegt) Status zusammen mit dem Titel des Notebooks angezeigt. Sie sehen auch einen gefüllten Kreis neben dem PySpark-Text in der oberen rechten Ecke. Wenn der Auftrag abgeschlossen ist, wird ein Kreis ohne Füllung angezeigt.
Führen Sie den folgenden Code aus, um einen Dataframe und eine temporäre Tabelle (hvac) zu erstellen.
# Create a dataframe and table from sample data csvFile = spark.read.csv ('/HdiSamples/HdiSamples/SensorSampleData/hvac/HVAC.csv', header=True, inferSchema=True) csvFile.write. saveAsTable("hvac")
Ausführen von Abfragen gegen Dataframes
Nach dem Erstellen der Tabelle führen Sie eine interaktive Abfrage für die Daten aus.
Führen Sie den folgenden Code in einer leeren Zelle des Notebooks aus:
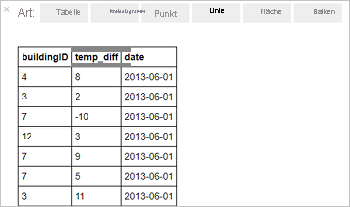
%%sql SELECT buildingID, (targettemp - actualtemp) AS temp_diff, date FROM hvac WHERE date = \"6/1/13\"Die folgende Ausgabe in Tabellenform wird angezeigt.
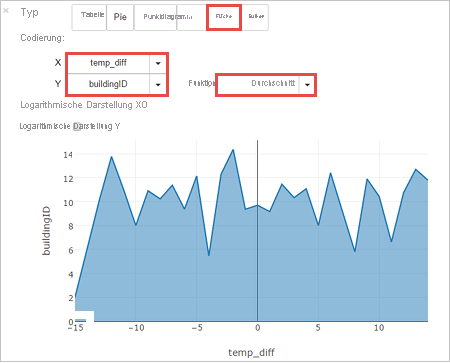
Sie können die Ergebnisse auch in anderen Visualisierungen anzeigen. Wählen Sie zum Anzeigen eines Bereichsdiagramms für die gleiche Ausgabe Bereich aus, und legen Sie die anderen Werte wie gezeigt fest.
Navigieren Sie in der Menüleiste des Notebooks zu Datei > Save and Checkpoint (Speichern und Prüfpunkt).
Fahren Sie das Notebook herunter, um die Clusterressourcen freizugeben: Navigieren Sie in der Menüleiste des Notebooks zu Datei > Close and Halt (Schließen und anhalten).