Erstellen eines HDInsight-Clusters
Es gibt verschiedene Methoden zum Erstellen eines HDInsight-Clusters. Dies kann von der Verwendung des Azure-Portals für eine einfache Benutzeroberfläche bis hin zu skriptgesteuerten Einrichtungen reichen, die bei automatisierten Bereitstellungen helfen können. Die folgende Tabelle zeigt die verschiedenen Methoden, mit denen Sie einen HDInsight-Cluster einrichten können.
| Verfahren zur Clustererstellung | Webbrowser | Befehlszeile | REST-API | SDK |
|---|---|---|---|---|
| Azure-Portal | ✔ | |||
| Azure Data Factory | ✔ | ✔ | ✔ | ✔ |
| Azure CLI | ✔ | |||
| Azure PowerShell | ✔ | |||
| cURL | ✔ | ✔ | ||
| .NET SDK | ✔ | |||
| Azure Resource Manager-Vorlage | ✔ |
Für alle HDInsight-Einrichtungen sind die folgenden grundlegenden Informationen erforderlich, einschließlich:
Registerkarte „Grundlagen“
Projektdetails
Abonnement
Definiert das Azure-Abonnement, unter dem der HDInsight-Cluster abgerechnet und verwaltet wird.
Ressourcengruppenname
Eine Ressourcengruppe ist eine logische Gruppierung von Azure-Technologien und -Diensten, die sich typischerweise auf dieselbe Anwendung oder denselben Anwendungslebenszyklus beziehen. Die Gruppierung von Diensten in derselben Ressourcengruppe erleichtert die administrative Wartung.
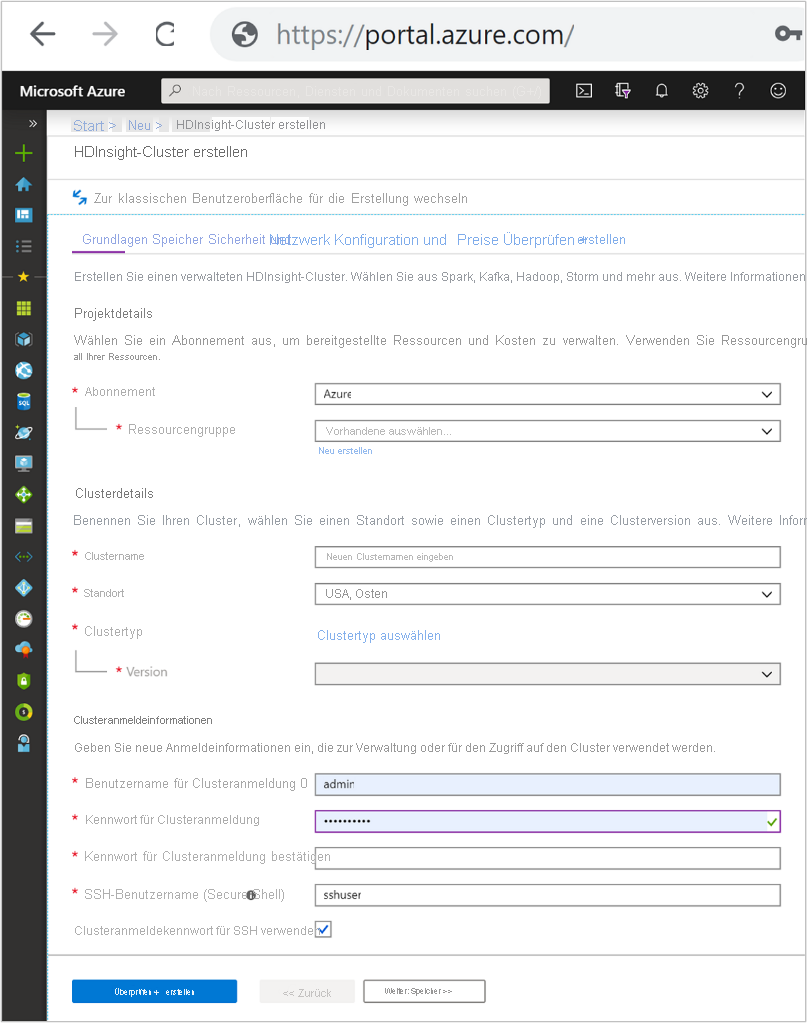
Clusterdetails
Clustername
Für Namen von HDInsight-Clustern gelten folgende Einschränkungen:
- Zulässige Zeichen: a-z, 0–9, A-Z
- Max. Länge: 59
- Reservierte Namen: apps
- Der Benennungsbereich des Clusters gilt überall in Azure und in allen Abonnements. Also muss der Clustername weltweit eindeutig sein.
- Die ersten sechs Zeichen müssen innerhalb eines VNETs eindeutig sein.
Location
Gibt den Ort an, an dem der Clustertyp gespeichert wird. Wenn kein Speicherort definiert ist, wird der Cluster am selben Ort wie der Standardspeicher platziert. Der Standort sollte so nah wie möglich bei Ihren Benutzern sein, um Wartezeiten zu reduzieren.
Clustertypen
Definiert den Technologiestapel, der auf Ihrem Ressourcencluster bereitgestellt wird. Wählen Sie einen Clustertyp basierend auf der Art Ihrer Daten und der Art der Verarbeitung, die Ihr Szenario erfordert, aus. Die verfügbaren Clustertypen sind in der folgenden Tabelle aufgeführt.
| Clustertyp | Beschreibung |
|---|---|
| Apache Hadoop | Ein Framework, das HDFS und ein einfaches MapReduce-Programmiermodell zum Verarbeiten und Analysieren von Batchdaten nutzt. |
| Apache Spark | Ein Open-Source-Framework für die Parallelverarbeitung, das die arbeitsspeicherinterne Verarbeitung unterstützt, um die Leistung von Anwendungen zur Analyse von Big Data zu steigern. |
| HBase | Eine auf Hadoop basierende NoSQL-Datenbank, die wahlfreien Zugriff und starke Konsistenz für große Mengen unstrukturierter und teilstrukturierter Daten bietet – in einer potenziellen Dimension von Milliarden von Zeilen multipliziert mit Milliarden von Spalten. |
| Apache Interactive Query | Arbeitsspeicherinternes Caching für interaktive und schnellere Hive-Abfragen. |
| Apache Kafka | Eine Open Source-Plattform zum Erstellen von Streamingdatenpipelines und -anwendungen. Kafka bietet auch eine Nachrichtenwarteschlangenfunktion, die Ihnen das Veröffentlichen und Abonnieren von Datenströmen ermöglicht. |
Version
Definiert die Version von HDInsight für diesen Cluster. HDInsight 4.0 ist die neueste Version und verfügt über die neuesten Frameworks, die für Cluster bereitgestellt werden.
Clusteranmeldeinformationen
Bei HDInsight-Clustern können Sie bei der Clustererstellung zwei Benutzerkonten konfigurieren.
Clusteranmeldung und Kennwort
Der Standardbenutzername ist „admin“. Er verwendet die Grundkonfiguration im Azure-Portal. Er wird auch als „Clusterbenutzer“ bezeichnet.
SSH-Benutzername und Kennwort
Wird verwendet, um die Verbindung mit dem Cluster über SSH herzustellen.
Hinweis
Mit dem Sicherheitspaket für Unternehmen können Sie HDInsight mit Active Directory und Apache Ranger integrieren. Mithilfe des Enterprise-Sicherheitspakets können mehrere Benutzer erstellt werden.
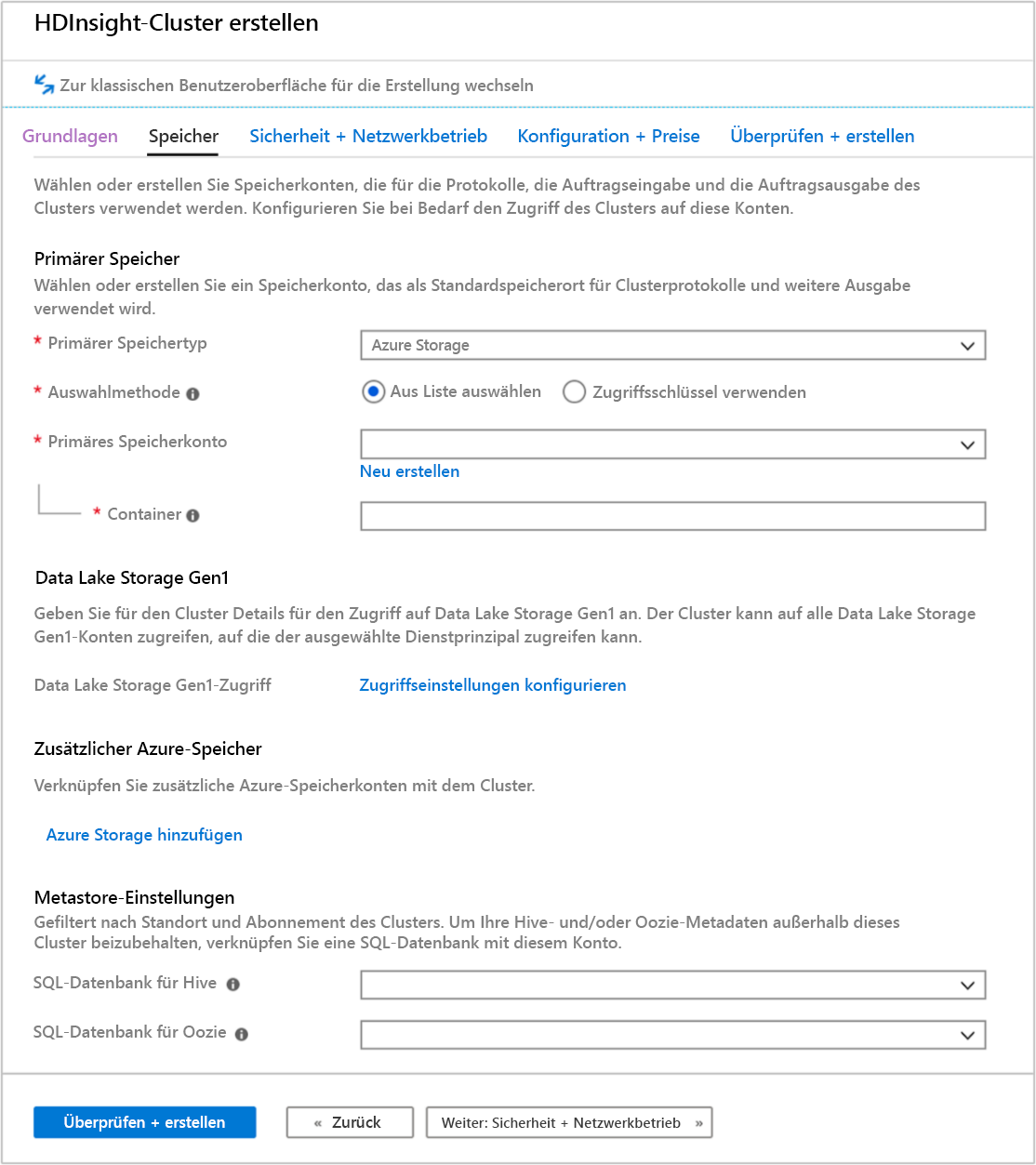
Registerkarte „Speicher“
HDInsight-Cluster können die folgenden Speicheroptionen verwenden, wie im Speicherbildschirm gezeigt:
- Azure Data Lake Storage Gen2
- Azure Data Lake Storage Gen1
- Azure Storage vom Typ „Allgemein v2“
- Azure Storage vom Typ „Allgemein v1“
- Azure Storage-Blockblob (nur als sekundärer Speicher unterstützt)
Im Bildschirm „Speicher“ können Sie das primäre Speicherkonto und den Standardcontainer definieren. Sie können auch zusätzlichen Azure Storage mit dem Cluster verknüpfen. Mit den Metastore-Einstellungen können Sie eine externe SQL-Datenbank definieren, um Hive-Tabellen nach dem Löschen eines Clusters zu speichern, und die Leistung von Oozie verbessern, indem die Metadaten in einem externen Speicher abgelegt werden.
Sicherheit und Netzwerk
Für Cluster der Typen Hadoop, Spark, HBase, Kafka und Interactive Query können Sie das Enterprise-Sicherheitspaket aktivieren. Dieses Paket bietet die Möglichkeit, mithilfe von Apache Ranger und der Integration in Microsoft Entra ID eine sicherere Clustereinrichtung zu erreichen.
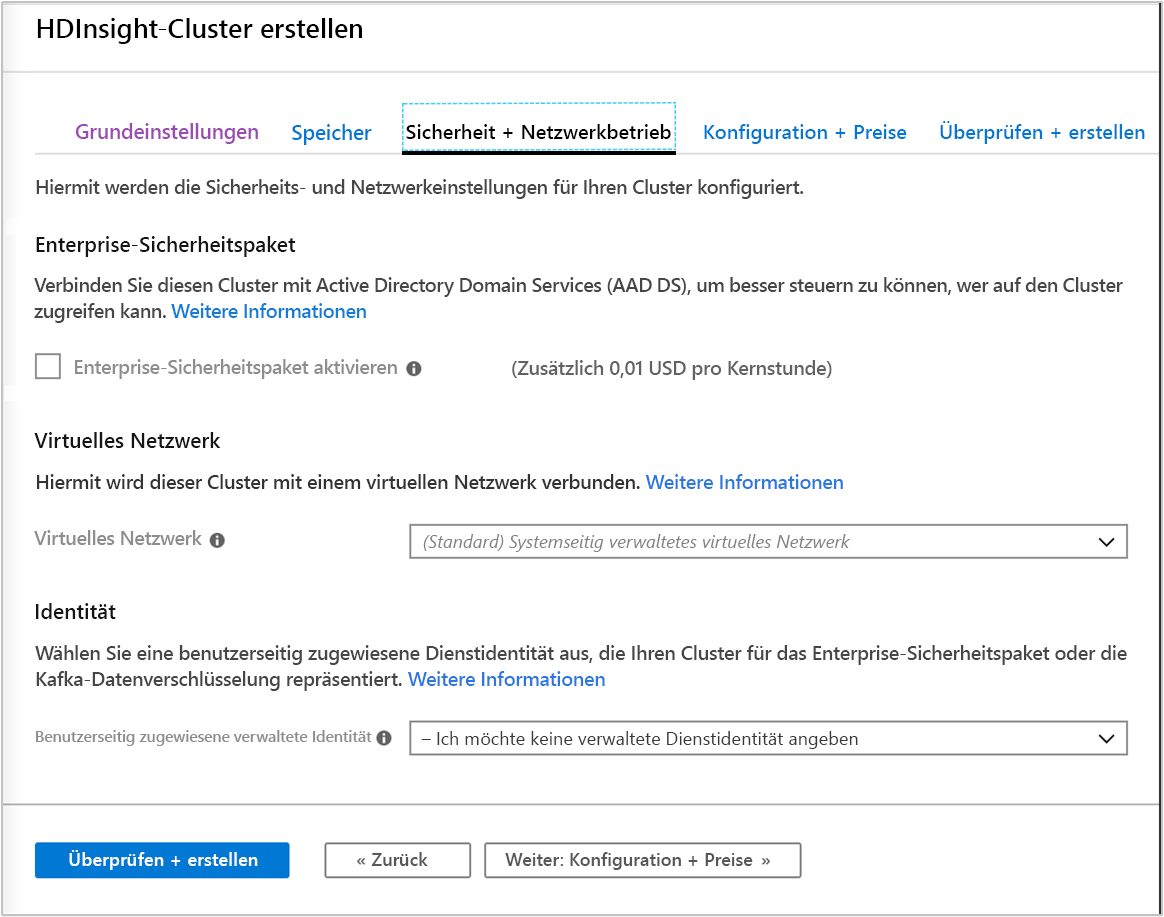
Darüber hinaus wird immer empfohlen, HDInsight-Cluster innerhalb eines VNet bereitzustellen. Sie können das virtuelle Netzwerk in diesem Bildschirm definieren und einstellen. Wenn für Ihre Lösung Technologien erforderlich sind, die auf mehrere HDInsight-Clustertypen verteilt sind, können Sie die erforderlichen Clustertypen über ein virtuelles Azure-Netzwerk miteinander verbinden. Durch diese Konfiguration können die Cluster und der gesamte Code, den Sie dafür bereitstellen, direkt miteinander kommunizieren.
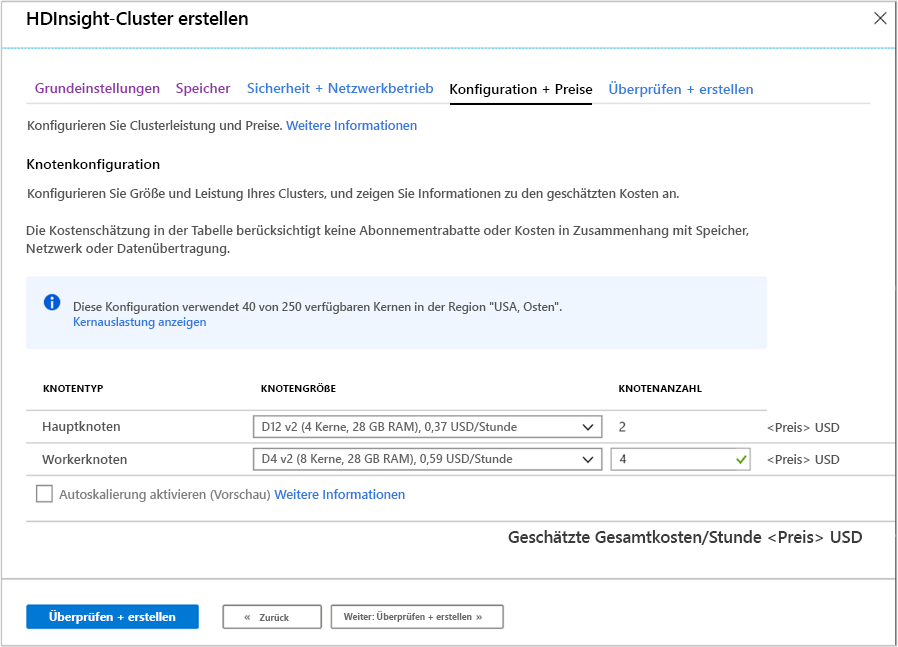
Konfiguration und Preise
Auf dieser Seite können Sie die Größe und Leistung Ihres Clusters konfigurieren und geschätzte Kosteninformationen anzeigen. In diesem Bildschirm können Sie die virtuellen Computer definieren, die für die Haupt(Master)knoten und auch für die Workerknoten verwendet werden.