Skill für die benutzerdefinierte Textklassifizierung
Die benutzerdefinierte Textklassifizierung ermöglicht Ihnen das Zuordnen einer Textpassage zu verschiedenen benutzerdefinierten Klassen. Sie könnten beispielsweise ein Modell für die Zusammenfassungen auf der Rückseite von Büchern trainieren, um automatisch das Genre eines Buches zu identifizieren. Anschließend verwenden Sie das identifizierte Genre, um die Suchmaschine Ihres Onlineshops mit einer Genrefacette zu erweitern.
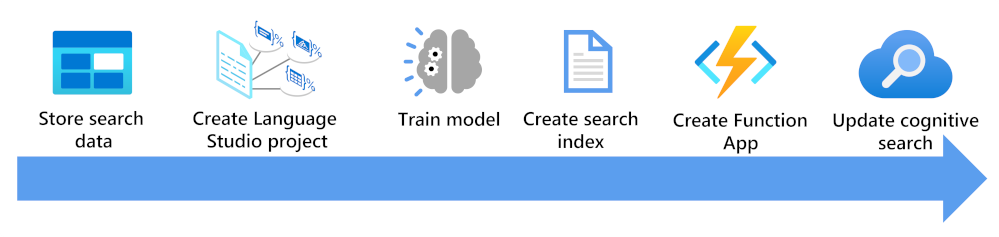
Hier sehen Sie, was Sie beachten müssen, um einen Suchindex mithilfe eines benutzerdefinierten Textklassifizierungsmodells anzureichern:
- Speichern Sie Ihre Dokumente so, dass Language Studio und Indexer der Azure KI-Suche darauf zugreifen können.
- Erstellen eines Projekts zur benutzerdefinierten Textklassifizierung.
- Trainieren und testen Sie Ihr Modell.
- Erstellen Sie einen Suchindex basierend auf Ihren gespeicherten Dokumenten.
- Erstellen Sie eine Funktions-App, die Ihr bereitgestelltes trainiertes Modell verwendet.
- Aktualisieren Sie Ihre Suchlösung, Ihren Index, den Indexer und das benutzerdefinierte Skillset.
Speichern der Daten
Azure Blob Storage ist aus Language Studio und Azure KI Services zugänglich. Der Container muss zugänglich sein, weshalb die einfachste Möglichkeit darin besteht, „Container“ auszuwählen. Es ist jedoch auch möglich, private Container mit zusätzlichen Konfigurationen zu verwenden.
Neben Ihren Daten benötigen Sie auch eine Möglichkeit, Klassifizierungen für jedes Dokument zuzuweisen. Language Studio bietet ein grafisches Tool, mit dem Sie Dokumente einzeln manuell klassifizieren können.
Sie haben die Wahl zwischen zwei verschiedenen Projekttypen. Wenn ein Dokument einer einzelnen Klasse zugeordnet ist, verwenden Sie ein einzelnes Bezeichnungsklassifizierungsprojekt. Wenn Sie ein Dokument mehreren Klassen zuordnen möchten, verwenden Sie das Projekt für die Klassifizierung mit mehreren Bezeichnungen.
Wenn Sie nicht jedes Dokument manuell klassifizieren möchten, können Sie alle Dokumente mit einer Bezeichnung versehen, bevor Sie Ihr Azure KI Language-Projekt erstellen. Dieser Prozess umfasst das Erstellen eines JSON-Bezeichnungsdokuments im folgenden Format:
{
"projectFileVersion": "2022-05-01",
"stringIndexType": "Utf16CodeUnit",
"metadata": {
"projectKind": "CustomMultiLabelClassification",
"storageInputContainerName": "{CONTAINER-NAME}",
"projectName": "{PROJECT-NAME}",
"multilingual": false,
"description": "Project-description",
"language": "en-us"
},
"assets": {
"projectKind": "CustomMultiLabelClassification",
"classes": [
{
"category": "Class1"
},
{
"category": "Class2"
}
],
"documents": [
{
"location": "{DOCUMENT-NAME}",
"language": "{LANGUAGE-CODE}",
"dataset": "{DATASET}",
"classes": [
{
"category": "Class1"
},
{
"category": "Class2"
}
]
}
]
}
Sie fügen dem classes-Array so viele Klassen hinzu, wie Sie haben. Sie fügen einen Eintrag für jedes Dokument im documents-Array hinzu, einschließlich der Information, welchen Klassen das Dokument entspricht.
Erstellen Ihres Azure AI Language-Projekts
Es gibt zwei Möglichkeiten, Ihr Azure KI Language-Projekt zu erstellen. Wenn Sie Language Studio verwenden, ohne zunächst einen Sprachdienst im Azure-Portal zu erstellen, bietet Language Studio Ihnen an, einen Dienst für Sie zu erstellen.
Die flexibelste Möglichkeit zum Erstellen eines Azure KI Language-Projekts ist, zuerst Ihren Sprachdienst mithilfe des Azure-Portals zu erstellen. Wenn Sie diese Option auswählen, erhalten Sie die Möglichkeit, benutzerdefinierte Features hinzuzufügen.
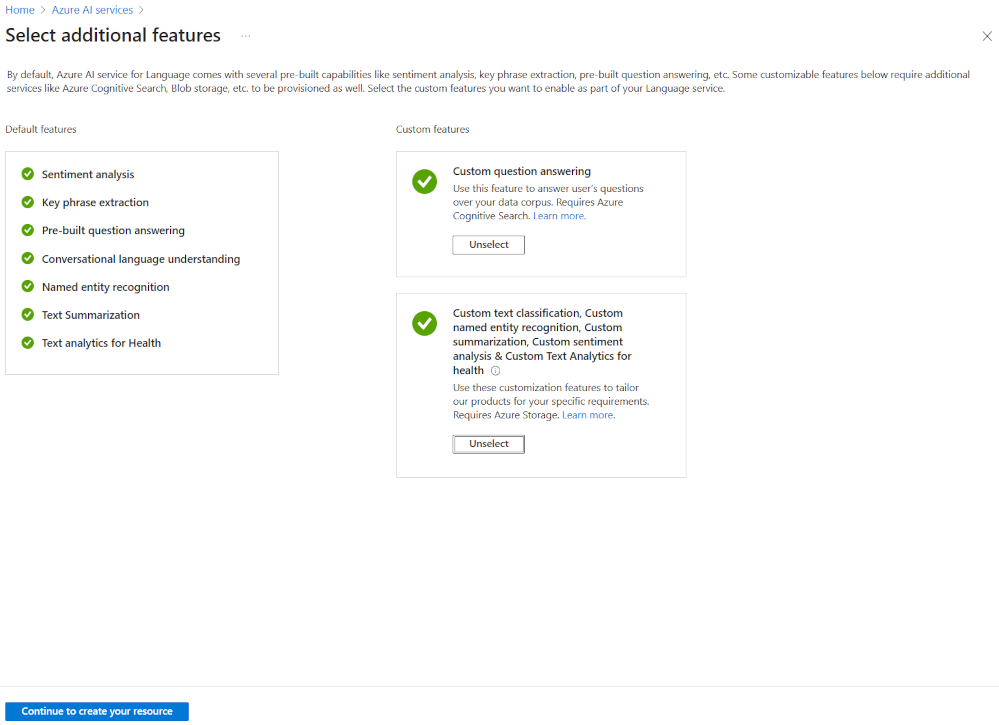
Da Sie das Ziel hatten, eine benutzerdefinierte Textklassifizierung zu erstellen, wählen Sie dieses benutzerdefinierte Feature beim Erstellen Ihres Sprachdiensts aus. Zudem verknüpfen Sie den Sprachdienst mithilfe dieser Methode mit einem Speicherkonto.
Sobald die Ressource bereitgestellt wurde, können Sie direkt über den Übersichtsbereich des Sprachdiensts zu Language Studio navigieren. Anschließend können Sie ein neues Projekt für die benutzerdefinierte Textklassifizierung erstellen.
Hinweis
Wenn Sie Ihren Sprachdienst aus Language Studio erstellt haben, müssen Sie möglicherweise die folgenden Schritte ausführen. Festlegen von Rollen für Ihr Azure Language-Ressourcen- und Speicherkonto, um Ihren Speichercontainer mit Ihrem benutzerdefinierten Textklassifizierungsprojekt zu verbinden.
Trainieren Ihres Klassifizierungsmodells
Wie bei allen KI-Modellen benötigen Sie identifizierte Daten, mit denen Sie das Modell trainieren können. Das Modell benötigt Beispiele dafür, wie Daten einer Klasse zugeordnet werden müssen. Zudem sind einige Beispiele nötig, die zum Testen des Modells verwendet werden können. Sie können Ihre Trainingsdaten automatisch durch das Modell aufteilen lassen. Standardmäßig werden 80 % der Dokumente zum Trainieren des Modells und 20 % für Blindtests verwendet. Wenn Sie über spezifische Dokumente verfügen, mit denen Sie Ihr Modell testen möchten, können Sie Dokumente für Tests markieren.

Klicken Sie in Ihrem Projekt in Language Studio auf Datenbeschriftung. Alle Ihre Dokumente werden angezeigt. Wählen Sie die Dokumente aus, die Sie der Testgruppe hinzufügen möchten, und klicken Sie dann auf Testing the model‘s performance (Leistung des Modells überprüfen). Speichern Sie Ihre aktualisierten Bezeichnungen, und erstellen Sie einen neuen Trainingsauftrag.
Erstellen eines Suchindexes
Es sind keine spezifischen Schritte erforderlich, um einen Suchindex zu erstellen, der durch ein benutzerdefiniertes Textklassifizierungsmodell erweitert wird. Führen Sie die unter Erstellen einer Azure KI-Suche-Lösung beschriebenen Schritte aus. Sie aktualisieren den Index, Indexer und benutzerdefinierten Skill, nachdem Sie eine Funktions-App erstellt haben.
Erstellen einer Azure-Funktions-App
Sie können die Sprache und Technologien Ihrer Wahl für die Funktions-App auswählen. Die App muss in der Lage sein, JSON-Daten an den Endpunkt für die benutzerdefinierte Textklassifizierung zu übergeben. Beispiel:
{
"displayName": "Extracting custom text classification",
"analysisInput": {
"documents": [
{
"id": "1",
"language": "en-us",
"text": "This film takes place during the events of Get Smart. Bruce and Lloyd have been testing out an invisibility cloak, but during a party, Maraguayan agent Isabelle steals it for El Presidente. Now, Bruce and Lloyd must find the cloak on their own because the only non-compromised agents, Agent 99 and Agent 86 are in Russia"
}
]
},
"tasks": [
{
"kind": "CustomMultiLabelClassification",
"taskName": "Multi Label Classification",
"parameters": {
"project-name": "movie-classifier",
"deployment-name": "test-release"}
}
]
}
Verarbeiten Sie dann die JSON-Antwort des Modells. Beispiel:
{
"jobId": "be1419f3-61f8-481d-8235-36b7a9335bb7",
"lastUpdatedDateTime": "2022-06-13T16:24:27Z",
"createdDateTime": "2022-06-13T16:24:26Z",
"expirationDateTime": "2022-06-14T16:24:26Z",
"status": "succeeded",
"errors": [],
"displayName": "Extracting custom text classification",
"tasks": {
"completed": 1,
"failed": 0,
"inProgress": 0,
"total": 1,
"items": [
{
"kind": "CustomMultiLabelClassificationLROResults",
"taskName": "Multi Label Classification",
"lastUpdateDateTime": "2022-06-13T16:24:27.7912131Z",
"status": "succeeded",
"results": {
"documents": [
{
"id": "1",
"class": [
{
"category": "Action",
"confidenceScore": 0.99
},
{
"category": "Comedy",
"confidenceScore": 0.96
}
],
"warnings": []
}
],
"errors": [],
"projectName": "movie-classifier",
"deploymentName": "test-release"
}
}
]
}
}
Die Funktion gibt dann eine strukturierte JSON-Nachricht an ein benutzerdefiniertes Skillset in der KI-Suche zurück. Beispiel:
[{"category": "Action", "confidenceScore": 0.99}, {"category": "Comedy", "confidenceScore": 0.96}]
Die Funktions-App muss fünf Dinge wissen:
- Zu klassifizierender Text
- Endpunkt für Ihr bereitgestelltes trainiertes Modell für die benutzerdefinierte Textklassifizierung
- Primärschlüssel für das Projekt für die benutzerdefinierte Textklassifizierung
- Der Projektname.
- Bereitstellungsname
Der zu klassifizierende Text wird von Ihrem benutzerdefinierten Skillset in der KI-Suche als Eingabe an die Funktion übergeben. Die restlichen vier Elemente finden Sie in Language Studio.

Informationen zum Namen des Endpunkts und der Bereitstellung erhalten Sie im Bereich „Deploying a model“ (Modell bereitstellen).

Der Projektname und den Primärschlüssel finden Sie im Bereich für die Projekteinstellungen.
Aktualisieren Ihrer Azure KI-Suche-Lösung
Sie müssen im Azure-Portal drei Änderungen vornehmen, um Ihren Suchindex anzureichern:
- Sie müssen Ihrem Index ein Feld hinzufügen, um die Erweiterung für die benutzerdefinierte Textklassifizierung zu speichern.
- Sie müssen ein benutzerdefiniertes Skillset hinzufügen, um Ihre Funktions-App mit dem Text aufzurufen, der klassifiziert werden soll.
- Sie müssen die Antwort aus dem Skillset dem Index zuordnen.
Hinzufügen eines Felds zu einem vorhandenen Index
Navigieren Sie im Azure-Portal zu Ihrer KI-Suche-Ressource, wählen Sie den Index aus, und fügen Sie JSON-Code im folgenden Format hinzu:
{
"name": "classifiedtext",
"type": "Collection(Edm.ComplexType)",
"analyzer": null,
"synonymMaps": [],
"fields": [
{
"name": "category",
"type": "Edm.String",
"facetable": true,
"filterable": true,
"key": false,
"retrievable": true,
"searchable": true,
"sortable": false,
"analyzer": "standard.lucene",
"indexAnalyzer": null,
"searchAnalyzer": null,
"synonymMaps": [],
"fields": []
},
{
"name": "confidenceScore",
"type": "Edm.Double",
"facetable": true,
"filterable": true,
"retrievable": true,
"sortable": false,
"analyzer": null,
"indexAnalyzer": null,
"searchAnalyzer": null,
"synonymMaps": [],
"fields": []
}
]
}
Dieser JSON-Code fügt dem Index ein zusammengesetztes Feld hinzu, um die Klasse in einem category-Feld zu speichern, das durchsucht werden kann. Das zweite confidenceScore-Feld speichert den Konfidenzprozentsatz in einem Doppelfeld.
Bearbeiten des benutzerdefinierten Skillsets
Wählen Sie im Azure-Portal das Skillset aus, und fügen Sie JSON-Code im folgenden Format hinzu:
{
"@odata.type": "#Microsoft.Skills.Custom.WebApiSkill",
"name": "Genre Classification",
"description": "Identify the genre of your movie from its summary",
"context": "/document",
"uri": "https://learn-acs-lang-serives.cognitiveservices.azure.com/language/analyze-text/jobs?api-version=2022-05-01",
"httpMethod": "POST",
"timeout": "PT30S",
"batchSize": 1,
"degreeOfParallelism": 1,
"inputs": [
{
"name": "lang",
"source": "/document/language"
},
{
"name": "text",
"source": "/document/content"
}
],
"outputs": [
{
"name": "text",
"targetName": "class"
}
],
"httpHeaders": {}
}
Die WebApiSill-Skilldefinition gibt an, dass die Sprache und der Inhalt eines Dokuments als Eingaben an die Funktions-App übergeben werden. Die App gibt JSON-Text namens class zurück.
Zuordnen der Ausgabe aus der Funktions-App zum Index
Die letzte Änderung besteht darin, die Ausgabe dem Index zuzuordnen. Wählen Sie im Azure-Portal den Indexer aus, und bearbeiten Sie den JSON-Text, um eine neue Ausgabezuordnung zu erhalten:
{
"sourceFieldName": "/document/class",
"targetFieldName": "classifiedtext"
}
Der Indexer weiß nun, dass die Ausgabe aus der Funktions-App document/class im Feld classifiedtext gespeichert werden soll. Da dies als zusammengesetztes Feld definiert wurde, muss die Funktions-App ein JSON-Array zurückgeben, das die Felder category und confidenceScore enthält.
Sie können jetzt einen erweiterten Suchindex für Ihren klassifizierten Text durchsuchen.