Skalieren von Computeressourcen
Einer der wichtigen Vorteile der Cloud ist die Möglichkeit, Ressourcen in einem System bedarfsgesteuert zu skalieren. Das zentrale Hochskalieren (= bereitstellen größerer Ressourcen) und die horizontale Skalierung (= bereitstellten zusätzlicher Ressourcen) können dabei helfen, die Auslastung eines Systems zu reduzieren, weil mehr Kapazität vorhanden ist und die Last breiter verteilt werden kann.
Da die Skalierung dazu führt, dass mehr Anforderungen verarbeitet werden können, wirkt das System auf die Benutzer reaktions- und leistungsfähiger. Zusätzlich senkt die Skalierung die Latenzzeit während Lastspitzen bei einzelnen Ressourcen, da weniger Anforderungen in die Warteschlange verschoben werden. Außerdem verbessert die Skalierung die Zuverlässigkeit des Systems, da durch die verringerte Ressourcenauslastung eine Überlastung verhindert wird.
Die Cloud bietet Ihnen die Möglichkeit, unkompliziert neuere oder bessere Ressourcen bereitzustellen. Bedenken Sie jedoch die dadurch anfallenden Kosten. Deshalb ist es trotz aller Vorteile der zentralen Hochskalierung und der horizontalen Skalierung wichtig, zu erkennen, wann sich durch horizontales Herunterskalieren und zentrales Herunterskalieren Kosten sparen lassen.
Horizontale Skalierung (Hoch- und Herunterskalieren)
Bei der horizontalen Skalierung werden einem System zeitweise zusätzliche Ressourcen hinzugefügt oder unnötige Ressourcen entfernt. Dies ist auf Serverebene nützlich, wenn die Systemauslastung inkonsistent schwankt oder nicht vorhersehbar ist. Dabei ist es wichtig, basierend auf der Art und Dauer der Schwankungen die korrekte Anzahl von Ressourcen bereitzustellen, um die Anforderungen zu jeder Zeit verarbeiten zu können.
Die folgenden Aspekte müssen dabei berücksichtigt werden:
- die Startzeit einer Instanz (z. B. eines virtuellen Computers)
- das Preismodell des Clouddienstanbieters
- der mögliche Umsatzverlust durch eine verringerte Servicequalität aufgrund von verspätetem Hinzufügen zusätzlicher Ressourcen
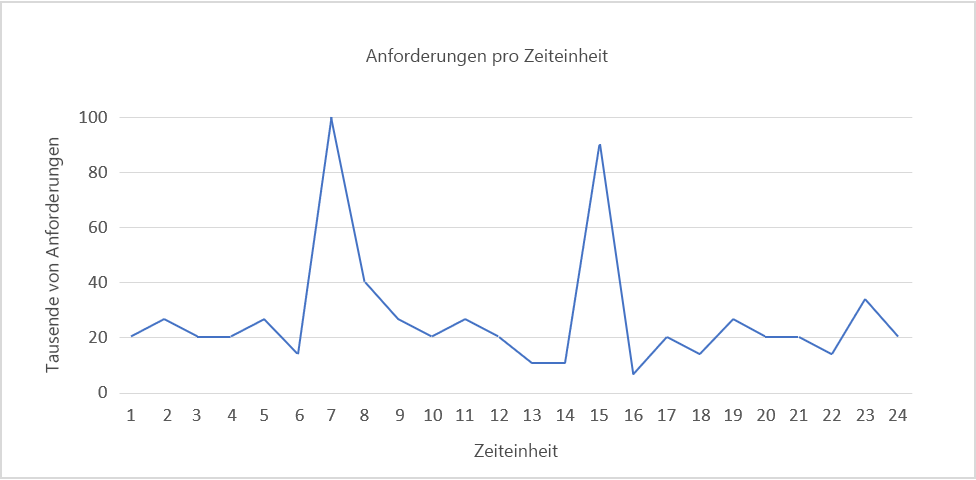
Abbildung 5: Beispiel eines Auslastungsmusters
Abbildung 5 zeigt das Beispiel eines Auslastungsmusters.
Angenommen, Sie verwenden Amazon Web Services und jede Zeiteinheit entspricht 1 Stunde. Sie benötigen einen Server, der 5.000 Anforderungen verarbeiten kann. Die Nachfrage erreicht zwischen den Zeiteinheiten 6 und 8 sowie zwischen 14 und 16 ihren Höchstwert. Betrachten Sie den zweiten Zeitabschnitt genauer: Sie erkennen, dass die Nachfrage etwa bei Zeiteinheit 16 sinkt und beginnen dort mit der Verringerung der zugeordneten Ressourcen. Die Anzahl der Anforderungen sinkt in einem Zeitraum von drei Stunden von etwa 90.000 auf 10.000, wodurch sich rein rechnerisch die Kosten für mindestens ein Dutzend zusätzlicher Instanzen einsparen lassen, die bei Zeiteinheit 15 online waren.
Abbildung 6 zeigt ein Skalierungsmuster, bei dem die Anzahl der Instanzen (in rot dargestellt) nach Bedarf an das Auslastungsmuster angepasst wird. Während der Spitzenzeiten wird die Anzahl der Instanzen auf 20 bzw. 18 hochskaliert, um die für die Verarbeitung des Datenverkehrs erforderlichen Ressourcen bereitzustellen. Während der anderen Zeitintervalle wird die Anzahl der Instanzen reduziert (herunterskaliert), um die Ressourcenverwendung relativ konstant zu halten. Wenn jede Instanz 20 Cent pro Stunde kostet, belaufen sich die Kosten für die Ausführung von 20 Instanzen über 24 Stunden hinweg auf 96 Dollar. Durch die gezeigte Skalierung der Instanzenanzahl lassen sich die Kosten auf ungefähr 42 Dollar senken, was einer jährlichen Einsparung von mehr als 15.000 Dollar entspricht. Diese Summe dürfte einen beträchtlichen Anteil des IT-Budgets vieler Firmen ausmachen.
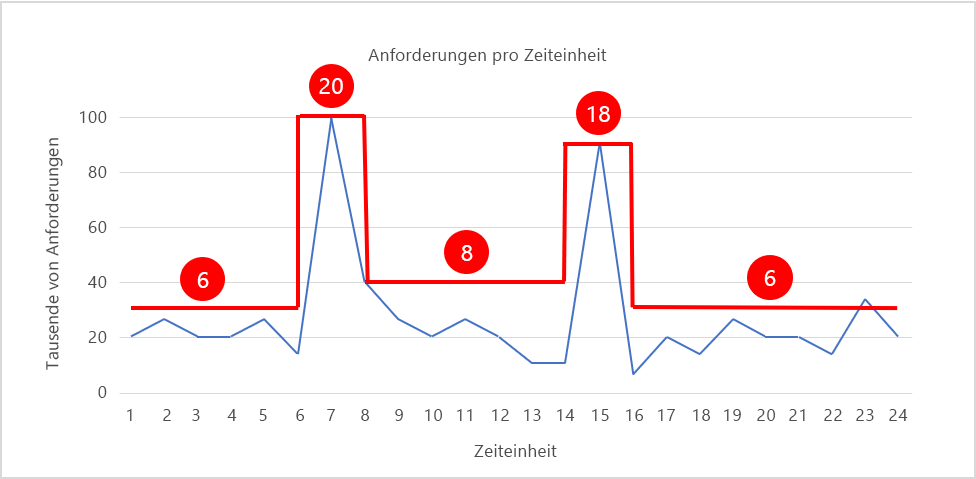
Abbildung 6: Hoch- und Herunterskalieren nach Bedarf
Die Skalierung basiert auf den Merkmalen des Datenverkehrs und der Last, die anschließend bei einem Webdienst generiert wird. Folgt der Datenverkehr einem Muster, das sich vorhersagen lässt (z. B. menschlichen Gewohnheiten wie dem Streamen von Filmen am Abend), lässt sich eine Skalierung vorsorglich durchführen, um die Dienstqualität beizubehalten. In vielen Fällen lässt sich der Datenverkehr jedoch nicht vorhersagen. Dann müssen sich die Skalierungssysteme auf Grundlage verschiedener Kriterien reaktiv verhalten.
Eine horizontale Skalierung kann sowohl mit Containerinstanzen als auch mit VM-Instanzen (virtuelle Computerinstanzen) ausgeführt werden kann. Traditionell wurden Workloads in der Cloud in virtuellen Computern ausgeführt, doch es kommen dafür immer häufiger auch Container zum Einsatz. Bei VM-basierten Workloads erfolgt die Skalierung durch Erhöhen und Verringern der Anzahl virtueller Computer. Containerbasierte Workloads können dementsprechend durch Änderung der Containeranzahl skaliert werden. Hierbei ist die Flexibilität etwas größer, da Container tendenziell schneller gestartet werden können als virtuelle Computer, wodurch neue Containerinstanzen in kürzerer Zeit online geschaltet werden können als VM-Instanzen.
Vertikale Skalierung (zentrales Hoch- und Herunterskalieren)
Die horizontale Skalierung ist nur eine Möglichkeit, flexibel auf die Nachfrage zu reagieren. Angenommen, der Datenverkehr auf Ihrer Website überschreitet selten 15.000 Anforderungen pro Zeiteinheit. Sie stellen eine einzelne große Instanz für 20.000 Anforderungen bereit, um sowohl den normalen Datenverkehr als auch kleinere Nachfragespitzen verarbeiten zu können. Bei steigender Auslastung können Sie nun auf den zunehmenden Datenverkehr reagieren, indem Sie die Serverinstanz durch eine Instanz ersetzen, die über die doppelte Anzahl von CPU-Kernen und die doppelte RAM-Größe verfügt. Diese Aufstockung wird als zentrales Hochskalieren bezeichnet.
Ein Nachteil der vertikalen Skalierung besteht darin, dass es durch den Wechsel im Allgemeinen zu einer gewissen Ausfallzeit kommt. Dies liegt daran, dass das Verschieben aller Vorgänge von der kleineren zur größeren Instanz einige Minuten dauert und die Servicequalität in dieser Zeit verringert ist.
Eine weitere Einschränkung der vertikalen Skalierung ist die geringere Granularität. Wenn Sie zehn Serverinstanzen online geschaltet haben und die Kapazität temporär um 10 % erhöhen müssen, können Sie bei der horizontalen Skalierung durch Hinzufügen einer Instanz mit elf Instanzen das gewünschte Ergebnis erzielen. Bei der vertikalen Skalierung besitzt die nächsthöhere Instanzengröße jedoch häufig etwa die doppelte Kapazität der vorherigen. Übertragen auf die horizontale Skalierung entspräche dies einer Erhöhung von zehn auf zwanzig Instanzen, um auf eine Zunahme des Datenverkehrs um 10 % zu reagieren. Daher ist die vertikale Skalierung meist teurer als die horizontale.
Ein weiterer Aspekt, den es im Zusammenhang mit der vertikalen Skalierung zu berücksichtigen gilt, ist die Verfügbarkeit. Verfügt eine Website über eine große Instanz, die die Anforderungen aller Kunden verarbeitet, fällt bei einem Ausfall dieser Instanz die gesamte Website aus. Wenn Sie dagegen für dieselbe Last zehn kleine Instanzen bereitstellen, bemerken die Benutzer beim Ausfall einer Instanz möglicherweise eine geringfügige Leistungsabnahme, doch sie können weiterhin auf die Website zugreifen. Daher entscheiden sich viele Cloudadministratoren bei zunehmender Beliebtheit eines Diensts selbst bei einer vorhersagbaren und stetigen Zunahme des Datenverkehrs für eine horizontale Skalierung anstelle einer vertikalen.
Skalieren der Serverebene
Skalierbarkeit erfordert häufig mehr als das bloße Hinzufügen von Ressourcen (horizontale Skalierung) oder Vergrößern von Ressourcen (vertikale Skalierung). Bei einer größeren Nachfrage kann es auf Serverebene zu einem Wettbewerb um bestimmte Ressourcentypen kommen, wie CPU, Arbeitsspeicher und Netzwerkbandbreite. Clouddienstanbieter stellen in der Regel virtuelle Computer bereit, die jeweils für rechenintensive, arbeitsspeicherintensive und netzwerkintensive Workloads optimiert sind. Daher sind zur Lösung des Problems das Wissen um die eigenen Workloadanforderungen und die Auswahl des richtigen VM-Typs genauso wichtig wie das Hinzufügen und Vergrößern von Ressourcen. Für die Verarbeitung von rechenintensiven Workloads sind fünf dafür optimierte VMs besser geeignet als zehn generische VMs, selbst wenn sie 20 % teurer sind.
Mit steigender Anzahl von Hardwareressourcen erhöht sich nicht automatisch die Leistung eines Diensts. So können mit effizienteren Algorithmen Ressourcenkonflikte reduziert und die Auslastung eines Diensts verbessert werden, wodurch der Bedarf nach einer Skalierung der physischen Ressourcen entfällt.
Ein wichtiger Aspekt bei der Skalierung ist die Zustandsbehaftung (bzw. die Zustandslosigkeit). Ein zustandsloser Dienst ist für eine skalierbare Architektur geeignet. „Zustandslosigkeit“ bedeutet im Wesentlichen, dass die Clientanforderung alle Informationen enthält, die für eine Verarbeitung durch den Server erforderlich sind. Der Server speichert in der Instanz keine Clientinformationen, sondern nur Sitzungsinformationen.
Ein zustandsloser Dienst erleichtert das Wechseln von Ressourcen nach Bedarf, ohne dass zur Beibehaltung des Kontexts (Zustands) der Clientverbindung für nachfolgende Anforderungen eine Konfiguration erforderlich ist. Bei einem zustandsbehafteten Dienst erfordert das Skalieren von Ressourcen eine Übertragungsstrategie des Kontexts von der bestehenden zur neuen Konfiguration. Beachten Sie, dass es für die Implementierung zustandsbehafteter Dienste verschiedene Möglichkeiten gibt, wie etwa das Beibehalten eines Netzwerkcaches zur serverübergreifenden Freigabe des Kontexts.
Skalieren der Datenebene
In datenorientierten Anwendungen mit einer großen Anzahl von Lese- und Schreibvorgängen (oder beidem) in eine Datenbank oder ein Speichersystem wird die Roundtripzeit für die einzelnen Anforderungen häufig durch die Lese- und Schreibzeiten der Festplatte eingeschränkt. Größere Instanzen ermöglichen eine höhere E/A-Leistung, wodurch die Suchzeiten auf der Festplatte verkürzt und damit die Latenzzeit des Diensts reduziert werden kann. Mehrere Dateninstanzen auf der Datenebene können die Zuverlässigkeit und Verfügbarkeit der Anwendung durch Failoverredundanzen verbessern. Das instanzenübergreifende Replizieren von Daten bietet weitere Vorteile bei der Reduzierung der Netzwerklatenz, wenn die Anforderungen des Client von einem Rechenzentrum verarbeitet werden, das sich in größerer physischer Nähe befindet. Das Sharding genannte ressourcenübergreifende Partitionieren von Daten stellt eine weitere Methode zur horizontalen Datenskalierung dar. Dabei werden die Daten nicht nur auf mehreren Instanzen repliziert, sondern in Segmente partitioniert und auf mehreren Datenservern gespeichert.
Eine weitere Schwierigkeit beim Skalieren der Datenebene ist das gleichzeitige Erfüllen der Eigenschaften Konsistenz (ein Lesevorgang ist auf allen Replikaten identisch), Verfügbarkeit (Lese- und Schreibvorgänge sind stets erfolgreich) und Partitionstoleranz (garantierte Eigenschaften im System werden auch bei fehlender Kommunikation zwischen Knoten durch einen Ausfall beibehalten). Laut dem sogenannten CAP-Theorem ist es in einem verteilten Datenbanksystem sehr schwierig, alle drei Eigenschaften vollständig zu erfüllen. Es kann nur eine Kombination aus zwei der Eigenschaften erfüllt werden1.
Literatur
- Wikipedia. CAP-Theorem https://en.wikipedia.org/wiki/CAP_theorem.