Umgang mit der Tail-Latenz
Sie haben bereits mehrere Optimierungsverfahren kennengelernt, mit denen die Latenz in der Cloud verringert werden kann. Zu den beschriebenen Maßnahmen zählen etwa das horizontale und vertikale Skalieren von Ressourcen sowie die Verwendung eines Load Balancers, um Anforderungen an die nächstgelegenen Ressourcen weiterzuleiten. Auf dieser Seite werden ausführlich die Gründe erläutert, die in einem großen Rechenzentrum oder einer umfangreichen Cloudanwendung für eine Reduzierung der Latenz aller Anforderungen sprechen, nicht nur der Gesamtlatenz. Sie werden sehen, dass schon wenige Ausreißer mit hoher Latenz zu einer deutlichen Verschlechterung der beobachteten Leistung in einem großen System führen. Außerdem lernen Sie verschiedene Methoden zur Erstellung von Diensten kennen, die vorhersagbare Antworten mit niedriger Latenz ermöglichen, und zwar selbst dann, wenn die einzelnen Komponenten dies nicht gewährleisten können. Dieses Problem ist insbesondere bei interaktiven Anwendungen relevant, die für Interaktionen eine Latenzzeit von weniger als 100 ms anstreben.
Was ist die sogenannte Tail-Latenz?
Die meisten Cloudanwendungen sind große, verteilte Systeme, die für eine möglichst geringe Latenzzeit auf parallelisierten Anforderungen basieren. Ein gängiges Verfahren besteht darin, eine in einem Stammknoten (z. B. einem Front-End-Webserver) empfangene Anforderung aufzufächern und an zahlreiche Blattknoten (Back-End-Computeserver) zu senden. Dies führt zu einer verbesserten Leistung, da die verteilte Berechnung parallel ausgeführt wird und zudem sehr kostspielige Datenverschiebungen vermieden werden. Einfacher ausgedrückt: Die Berechnung wird an den Ort verschoben, an dem die Daten gespeichert werden. Dabei verarbeitet natürlich jeder Blattknoten Hunderte oder sogar Tausende Anforderungen parallel.
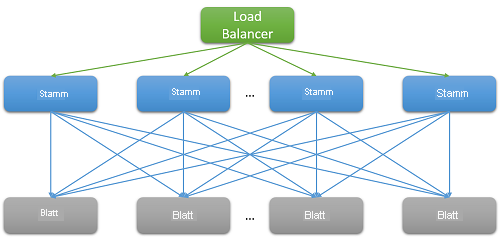
Abbildung 7: Latenz durch horizontale Skalierung
Nehmen Sie zur Veranschaulichung das Beispiel einer Suche nach einem Film auf Netflix. Beginnt ein Benutzer mit der Eingabe von Text in das Suchfeld, werden vom Stammwebserver mehrere parallele Ereignisse generiert. Diese Ereignisse umfassen mindestens die folgenden Anforderungen:
- An die AutoVervollständigen-Engine, zur Vorhersage der gewünschten Suche basierend auf früheren Trends und dem Profil des Benutzers.
- An die Korrektur-Engine, zur Suche nach Fehlern in der eingegebenen Abfrage basierend auf einem sich ständig anpassenden Sprachmodell.
- Jeweils Suchergebnisse für die einzelnen Komponenten einer Abfrage aus mehreren Wörtern, die je nach Rang und Relevanz der Filme kombiniert werden müssen.
- Eine zusätzliche Nachbearbeitung und Filterung der Ergebnisse, um die Einstellungen des Benutzers für eine sichere Suche zu erfüllen.
Solche Beispiele kommen sehr häufig vor. Bei einer einzigen Facebook-Anforderung werden Tausende Memcached-Server kontaktiert, bei einer einzigen Bing-Suche häufig sogar mehr als zehntausend Indexserver.
Der Skalierungsbedarf führt bei jeder einzelnen Anforderung an das Front-End zu einer breit angelegten Auffächerung auf dem Back-End. Die Heuristik zeigt, dass Antworten innerhalb von 100 ms erwartet werden, damit ein Dienst als „reaktionsschnell“ angesehen wird und seine Benutzerbasis halten kann. Bei der steigenden Anzahl von Servern, die für das Auflösen einer Abfrage benötigt werden, hängt die Gesamtreaktionszeit häufig von der langsamsten Antwort von einem Blatt- zu einem Stammknoten ab. Setzt man voraus, dass die Ausführung auf allen Blattknoten abgeschlossen sein muss, bevor ein Ergebnis zurückgegeben werden kann, dann fällt die Gesamtlatenz immer höher aus als die Latenz der langsamsten Komponente.
Wie bei den meisten stochastischen Prozessen kann auch die Antwortzeit eines einzelnen Blattknotens als Verteilung ausgedrückt werden. Jahrzehntelange Erfahrungen haben gezeigt, dass der überwiegende Teil der Anforderungen (> 99 %) in einem gut konfigurierten Cloudsystem normalerweise äußerst schnell ausgeführt wird. Doch häufig gibt es in einem System eine geringe Zahl von Ausreißern, die sehr langsam ausgeführt werden.
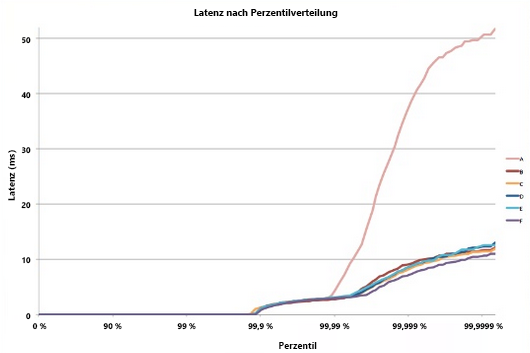
Abbildung 8: Beispiel für eine Tail-Latenz5
Stellen Sie sich folgendes Beispiel vor: Alle Blattknoten eines Systems weisen eine durchschnittliche Antwortzeit von 1 ms auf, doch es gibt eine Wahrscheinlichkeit von 1 %, dass die Antwortzeit größer als 1.000 ms (eine Sekunde) ist. Wenn jede Abfrage nur von einem einzelnen Blattknoten verarbeitet wird, beträgt die Wahrscheinlichkeit einer Verarbeitungsdauer der Abfrage von mehr als einer Sekunde ebenfalls 1 %. Wird die Anzahl der Knoten jedoch auf 100 erhöht, sinkt die Wahrscheinlichkeit, dass die Abfrage innerhalb von einer Sekunde abgeschlossen wird, von 99 % auf 36,6 %. Dies bedeutet im Umkehrschluss, dass die Abfragedauer mit einer Wahrscheinlichkeit von 63,4 % von den langsamsten 1 % der Latenzverteilung bestimmt wird. Dieser Prozentsatz der langsamsten Abfragen wird auch als „Tail“ bezeichnet.
$(,99^{100})$
Bei einer Simulation für eine Vielzahl von Fällen wird deutlich, dass die Auswirkung einer einzelnen langsamen Abfrage mit steigender Anzahl von Servern größer wird (die untere Kurve des Diagramms steigt stetig an). Zudem liegt die Kurve bei einer abnehmenden Wahrscheinlichkeit für Ausreißer von 1 % auf 0,01 % deutlich niedriger.
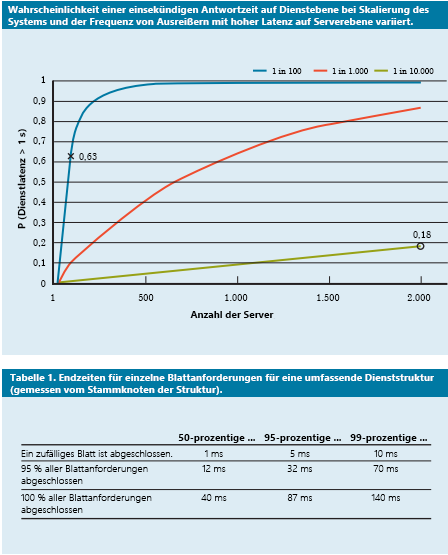
Abbildung 9: Aktuelle Studie zur Wahrscheinlichkeit von Antwortzeiten im 50sten, 95sten und 99sten Perzentil der Abfragelatenz4
Genau wie wir unsere Anwendungen so entworfen haben, dass sie fehlertolerant sind, um auf Probleme mit der Zuverlässigkeit von Ressourcen reagieren zu können, sollte jetzt klar sein, warum es wichtig ist, dass Anwendungen „tolerant gegenüber Tail-Latenz“ sind. Dafür sollten Sie die Ursachen dieser großen Leistungsvariabilität verstehen, um – wann immer möglich – Abhilfe zu schaffen und andernfalls Problemumgehungen zu finden.
Variabilität in der Cloud: Ursachen und Abhilfemaßnahmen
Bevor Sie das Problem einer großen Variabilität bei der Antwortzeit und infolgedessen das Problem von Tail-Latenz lösen können, müssen Sie die Ursachen von Leistungsvariabilität verstehen.1
- Gemeinsam verwendete Ressourcen: Viele verschiedene VMs (und Anwendungen innerhalb dieser VMs) konkurrieren um einen gemeinsamen Pool von Computeressourcen. In seltenen Fällen kann dieser Konflikt bei einigen Anforderungen zu einer geringen Latenz führen. Für wichtige Aufgaben ist es möglicherweise sinnvoll, dedizierte Instanzen zu verwenden und im Leerlauf regelmäßig Benchmarks auszuführen, um eine ordnungsgemäße Funktion sicherzustellen.
- Daemons und Wartung im Hintergrund: Sie haben bereits erfahren, warum Hintergrundprozesse zum Erstellen von Prüfpunkten und Sicherungen, zum Aktualisieren von Protokollen sowie zum Bereinigen des Speichers und von Ressourcen wichtig sind. Diese Prozesse können jedoch die Leistung des Systems während der Ausführung verschlechtern. Zur Minimierung der Auswirkungen auf den Datenverkehr sollten Unterbrechungen aufgrund von Wartungsthreads synchronisiert werden. Dadurch treten die Abweichungen nur während eines kurzen, bekannten Zeitfensters auf und nicht etwa zufällig über die Lebensdauer der Anwendung.
- Warteschlange: Eine weitere häufige Ursache für Variabilität ist das stoßweise Ankommen des Datenverkehrs.1 Diese Schwankungen werden noch verstärkt, wenn vom Betriebssystem kein Planungsalgorithmus nach dem FIFO-Prinzip verwendet wird. In Linux-Systemen werden zur Optimierung des Gesamtdurchsatzes und zur Maximierung der Serverauslastung Threads häufig außerhalb der Reihenfolge geplant. In Studien wurde nun herausgefunden, dass durch eine Planung nach dem FIFO-Prinzip im Betriebssystem die Tail-Latenz auf Kosten eines verringerten Gesamtdurchsatzes im System reduziert werden kann.
- All-to-All-Kommunikation: Das in Abbildung 7 gezeigte Kommunikationsmuster wird als „All-to-All“ bezeichnet. Da ein Großteil der Netzwerkkommunikation über TCP erfolgt, werden gleichzeitig Tausende von Anforderungen und Antworten zwischen dem Front-End-Webserver und allen Back-End-Verarbeitungsknoten generiert. Dieses äußerst stoßweise Kommunikationsmuster erzeugt oft eine besondere Art von Überlastungsfehler, der als „Incast Collapse für TCP“ bezeichnet wird.1, 2 Durch die Masse an plötzlichen Antworten von Tausenden von Servern werden viele Pakete gelöscht und erneut gesendet. Dies führt schließlich zu einer regelrechten Datenverkehrslawine aus sehr kleinen Datenpaketen. Große Rechenzentren und Cloudanwendungen verwenden häufig zur dynamischen Anpassung des TCP-Empfangsfenster und des Timers für Neuübertragungen benutzerdefinierte Netzwerktreiber. Auch Router können so konfiguriert werden, dass Datenverkehr über einer gewissen Rate gelöscht und die Größe der Sendung reduziert wird.
- Energie- und Temperaturverwaltung: Nicht zuletzt ist die Variabilität auch ein Nebenprodukt anderer Maßnahmen zur Kostenreduzierung, wie die Verwendung des Leerlaufstatus oder das Herunterskalieren der CPU-Frequenz. Ein Prozessor verbringt häufig eine nicht unerhebliche Zeit mit dem Hochskalieren aus dem Leerlaufstatus. Durch Deaktivieren dieser Art von Kostenoptimierungsfunktionen erhöhen sich zwar der Energieverbrauch und die damit verbundenen Kosten, gleichzeitig wird aber auch die Variabilität reduziert. Dies ist in der öffentlichen Cloud weniger von Belang, da Preismodelle selten interne Metriken zur Nutzung von Kundenressourcen berücksichtigen.
In Experimenten konnte festgestellt werden, dass die Variabilität solcher Systeme in der öffentlichen Cloud deutlich höher ist.3 Dies liegt normalerweise an einer unvollständigen Leistungsisolation virtueller Ressourcen und des gemeinsam genutzten Prozessors. Dieses Verhalten wird verstärkt, wenn eine Vielzahl von latenzempfindlichen Aufträgen auf demselben physischen Knoten mit hoher CPU-Intensität ausgeführt wird.
Reagieren auf Variabilität mithilfe technischer Lösungen
Viele der im vorherigen Abschnitt aufgeführten Ursachen von Variabilität können nicht vollständig aufgelöst oder vermieden werden. Daher sollten Sie nicht versuchen, sämtliche Ursachen der Tail-Latenz in Cloudanwendungen zu beseitigen, sondern sich vielmehr darauf konzentrieren, eine Toleranz gegenüber Tail-Latenzen zu erzeugen. Dies ist vergleichbar mit einer fehlertoleranten Konzipierung von Anwendungen, da meistens nicht alle möglichen Fehler behoben werden können. Folgende gängige Methoden zum Umgang mit Variabilität stehen zur Verfügung:
- Ausreichend gute Ergebnisse: Wenn das System auf die Ergebnisse von Tausenden Knoten wartet, verringert sich häufig die Bedeutung einzelner Ergebnisse. Daher antworten viele Anwendungen dem Benutzer durch Rückgabe von Ergebnissen, die in einem bestimmten, kurzen Latenzzeitfenster empfangen werden, und verwerfen die restlichen.
- Canary-Tests: Bei seltenen Codepfaden kann eine Anforderung auch zunächst nur für eine kleine Anzahl von Blattknoten getestet werden, um zu überprüfen, ob etwa ein Absturz oder Fehler mit Auswirkungen auf das gesamte System verursacht wird. Die vollständige aufgefächerte Abfrage wird erst generiert, wenn im Canary-Test kein Fehler auftritt. Der Name des Tests (canary = Kanarienvogel) stammt von einer früheren Vorgehensweise im Bergbau, bei der die Sicherheit für Bergleute in Kohlebergwerken mithilfe eines Kanarienvogels getestet wurde.
- Probe- und Integritätsprüfungen von Latenz: Die meisten Anforderungen an ein System sind für einen Canary-Test zu allgemein. Solche Anforderungen verfügen häufig dann über eine hohe Tail-Latenz, wenn einer der Blattknoten eine unzureichende Leistung aufweist. In solchen Fällen müssen Integrität und Latenz der einzelnen Blattknoten regelmäßig vom System überwacht werden, und Anforderungen dürfen nicht an Knoten weitergeleitet werden, die (aufgrund von Wartung oder Fehlern) eine geringe Leistung aufweisen.
- Differenzielle QoS: Für interaktive Anforderungen können getrennte Dienstklassen erstellt werden, über die sie in jeder Warteschlange Priorität haben. Latenzunempfindliche Anwendungen können für ihre Vorgänge längere Wartezeiten tolerieren.
- Absicherung von Anforderungen: Mit dieser einfachen Lösung werden die Auswirkungen von Variabilität verringert, indem dieselbe Anforderung an mehrere Replikate weitergeleitet und anschließend die erste empfangene Antwort verwendet wird. Dadurch wird jedoch auch die Menge der erforderlichen Ressourcen verdoppelt oder sogar verdreifacht. Zur Verringerung der Anzahl abgesicherter Anforderungen ist es möglich, die zweite Anforderung nur dann zu senden, wenn die erste Antwort länger als das 95ste Perzentil der für diese Anforderung erwarteten Latenz benötigt. Dadurch wird die Auslastung nur um etwa 5 % erhöht, die Tail-Latenz jedoch deutlich verringert (wie in der Darstellung in Abbildung 9, bei dem die Latenz des 95sten Perzentils deutlich niedriger ist als die des 99sten Perzentils).
- Spekulative Ausführung und selektive Replikation: Aufgaben auf besonders ausgelasteten Knoten können spekulativ auf nicht ausgelasteten Blattknoten gestartet werden. Dies ist insbesondere dann effektiv, wenn ein Fehler in einem bestimmten Knoten zu einer Überlastung des Knotens führt.
- UX-basierte Lösungen: Letztlich kann eine höhere Latenz auch durch eine intelligent entworfene Benutzeroberfläche verborgen werden, durch die eine Verzögerung vom Benutzer nicht als solche wahrgenommen wird. Dies kann etwa durch Animationen erreicht werden, durch das frühe Anzeigen von schnellen Ergebnissen oder durch Interaktion mit dem Benutzer wie etwa dem Senden relevanter Meldungen.
Mithilfe dieser Techniken ist es möglich, die Zufriedenheit der Benutzer von Cloudanwendungen deutlich zu verbessern und das durch lange Tail-Latenzzeiten verursachte Problem zu lösen.
References
- Li, J.; Sharma, N. K.; Ports, D. R.; Gribble, S. D. (2014): Tales of the Tail: Hardware, OS, and Application-Level Sources of Tail Latency aus den „Proceedings of the ACM Symposium on Cloud Computing, ACM“
- Wu, Haitao und Feng, Zhenqian und Guo, Chuanxiong und Zhang, Yongguang (2013). ICTCP: Incast Congestion Control for TCP in Data-Center Networks, IEEE/ACM Transactions on Networking (TON), IEEE Press
- Xu, Yunjing und Musgrave, Zachary und Noble, Brian und Bailey, Michael (2013). Bobtail: Avoiding Long Tails in the Cloud 10. USENIX-Konferenz zum Entwurf und der Implementierung von Netzwerksystemen, USENIX Association
- Dean, Jeffrey und Barroso, Luiz André (2013). The tail at scale, Communications of the ACM, ACM
- Tene, Gil (2014). [Understanding Latency – Some Key Lessons and Tools] (Latenz verstehen – Einige wichtige Lektionen und Tools) https://www.infoq.com/presentations/latency-lessons-tools/, QCon London