Skalieren von Ressourcen
Einer der wichtigen Vorteile der Cloud ist die Möglichkeit, Ressourcen in einem System bedarfsgesteuert zu skalieren. Das zentrale Hochskalieren (= Vergrößern der Ressourcen) und die horizontale Skalierung (= Bereitstellen zusätzlicher Ressourcen) ermöglichen eine Reduzierung der Auslastung einzelner Ressourcen. Dies wird durch eine Erhöhung der Kapazität oder eine breitere Verteilung der Workloads erreicht.
Durch Erhöhen des Durchsatzes kann eine Skalierung die Leistung verbessern, da nun eine größere Anzahl von Anforderungen verarbeitet werden kann. Zusätzlich senkt die Skalierung die Latenzzeit während Lastspitzen bei einzelnen Ressourcen, da weniger Anforderungen in die Warteschlange verschoben werden. Darüber hinaus kann auch die Zuverlässigkeit des Systems verbessert werden, da durch die verringerte Ressourcenauslastung eine Überlastung der Ressource unwahrscheinlicher wird.
Die Cloud bietet Ihnen die Möglichkeit, unkompliziert neuere oder bessere Ressourcen bereitzustellen. Bedenken Sie jedoch die dadurch anfallenden Kosten. Deshalb ist es trotz aller Vorteile der zentralen bzw. horizontalen Hochskalierung wichtig zu erkennen, wann sich durch zentrales bzw. horizontales Herunterskalieren Kosten sparen lassen. In einer N-Tier-Anwendung müssen Engpässe unbedingt ermittelt sowie die Ebene identifiziert werden, für die eine Skalierung durchgeführt werden soll: die Datenebene oder die Serverebene.
Wie im vorherigen Kapitel erläutert kann ein Lastenausgleich das Skalieren von Ressourcen erleichtern, da der Skalierungsaspekt eines Systems hinter einem konsistenten Endpunkt verborgen wird.
Skalierungsstrategien
Horizontale Skalierung (Hoch- und Herunterskalieren)
Bei der horizontalen Skalierung werden einem System zusätzliche Ressourcen hinzugefügt oder unnötige Ressourcen entfernt. Dies ist auf Serverebene nützlich, wenn die Systemauslastung nicht vorhersehbar ist und inkonsistent schwankt. Dabei ist es wichtig, basierend auf der Art und Dauer der Schwankungen die korrekte Anzahl von Ressourcen effizient bereitzustellen, um die Anforderungen zu jeder Zeit verarbeiten zu können.
Folgende Überlegungen sollten dabei berücksichtigt werden: die Startzeit einer Instanz, das Preismodell des Clouddienstanbieters sowie der potenzielle Umsatzverlust durch eine Verschlechterung der Dienstqualität (Quality of Service, QoS), wenn keine rechtzeitige Skalierung durchgeführt wird. Betrachten Sie etwa das folgende Beispiel eines Auslastungsmusters:
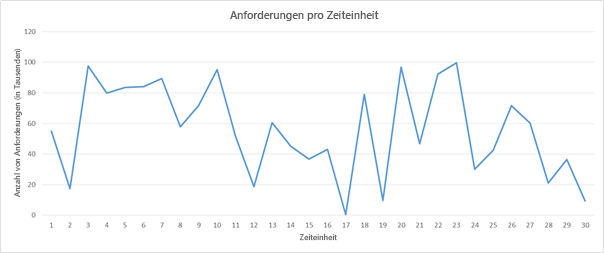
Abbildung 6: Beispiel eines Auslastungsmusters für Anforderungen
Angenommen, Sie verwenden in diesem Szenario Amazon Web Services. Jede Zeiteinheit soll hier drei Stunden entsprechen, und Sie benötigen einen Server, der 5.000 Anforderungen verarbeiten kann. Wie Sie sehen, schwankt die Auslastung zwischen den Zeiteinheiten 16 und 22 enorm. Da die Nachfrage etwa bei Zeiteinheit 16 sinkt, beginnen Sie dort mit der Verringerung der zugeordneten Ressourcen. Da in einem Zeitraum von drei Stunden die Anzahl der Anforderungen von etwa 50.000 auf nahezu 0 sinkt, können Sie verglichen mit Zeiteinheit 16 rein rechnerisch die Kosten für zehn Instanzen einsparen.
Stellen Sie sich nun vor, dass jede Zeiteinheit nicht mehr drei Stunden, sondern einem Zeitraum von zwanzig Minuten entspricht. In diesem Fall würden durch das Abschalten aller Ressourcen bei Zeiteinheit 16 und das Starten von neuen Ressourcen nur zwanzig Minuten später die Kosten nicht gesenkt, sondern vielmehr erhöht werden. Dies liegt daran, dass AWS die einzelnen Compute-Instanzen auf Stundenbasis abrechnet.
Neben den beiden oben genannten Überlegungen muss ein Dienstanbieter auch die Verluste berücksichtigen, die durch eine beeinträchtigte Dienstqualität bei Zeiteinheit 20 entstehen, wenn die Kapazität nur für 90.000 Anforderungen anstelle von 100.000 ausreicht.
Die Skalierung hängt von den Merkmalen des Datenverkehrs und der Last ab, die anschließend bei einem Webdienst generiert wird. Folgt der Datenverkehr einem Muster, das sich vorhersagen lässt (z. B. menschlichen Gewohnheiten wie dem Streamen von Filmen am Abend), lässt sich eine Skalierung vorsorglich durchführen, um die Dienstqualität beizubehalten. In vielen Fällen lässt sich der Datenverkehr, wie im Beispiel oben, jedoch nicht vorhersagen. Dann müssen reaktive Skalierungssysteme auf Grundlage verschiedener Kriterien eingerichtet werden.
Vertikale Skalierung (zentrales Hoch- und Herunterskalieren)
Bestimmte Arten von Auslastungen sind für Dienstanbieter leichter vorherzusagen als andere. Lag die Anzahl der Anforderungen beispielweise in den bisherigen Mustern immer zwischen 10.000 und 15.000, können Sie davon ausgehen, dass ein Server, der 20.000 Anforderungen verarbeiten kann, für diesen Zweck ausreicht. Sollte die Last eines Tages steigen, kann der Dienst in eine größere Instanz verschoben werden, die mehr Anforderungen verarbeiten kann, solange sich die Anzahl konstant erhöht. Diese Vorgehensweise eignet sich für kleine Anwendungen mit einer geringen Menge Datenverkehr.
Ein Nachteil der vertikalen Skalierung besteht darin, dass es durch den Wechsel immer zu einer gewissen Ausfallzeit kommt. Dies liegt daran, dass das Verschieben aller Vorgänge von der kleineren zu einer größeren Instanz einige Minuten dauert und die Dienstqualität in dieser Zeit verringert ist.
Darüber hinaus erhöhen die meisten Cloudanbieter die Computeressourcen, indem sie die Computeleistung einer Ressource verdoppeln. Das heißt, dass die Granularität bei der vertikalen Skalierung gröber ist als bei der horizontalen. Daher entscheiden sich viele Dienstanbieter bei zunehmender Beliebtheit eines Diensts selbst bei einer vorhersagbaren und stetigen Zunahme des Datenverkehrs für eine horizontale Skalierung anstelle einer vertikalen.
Überlegungen zur Skalierung
Überwachung
Für eine effektive Skalierung von Ressourcen ist die Überwachung sehr entscheidend, da Ihnen damit Metriken zur Verfügung stehen, um die Komponenten innerhalb des Systems zu bestimmen, für die eine Skalierung durchgeführt werden muss, sowie den dafür am besten geeigneten Zeitpunkt. Durch Analyse von Datenverkehrsmustern oder Ressourcenauslastung können Sie entscheiden, wann und wie stark die Ressourcen skaliert werden müssen, um die Dienstqualität und den Gewinn zu maximieren.
Bei Ressourcen gibt es mehrere Aspekte, die überwacht werden, weil sie eine Skalierung erforderlich machen könnten. Die häufigste Metrik ist die Ressourcenverwendung. Ein Überwachungsdienst kann z. B. die CPU-Auslastung der einzelnen Ressourcenknoten nachverfolgen und die Ressourcen skalieren, wenn die Auslastung zu hoch oder zu niedrig ist. Liegt beispielsweise bei jeder Ressource eine Auslastung von mehr als 95 % vor, sollten zusätzliche Ressourcen hinzugefügt werden, da das System stark ausgelastet ist. Normalerweise legen die Dienstanbieter fest, wann eine Skalierung ausgelöst werden soll. Dazu bestimmen sie den Punkt, an dem ein Ressourcenknoten wegen Überlastung nicht mehr korrekt arbeitet, und geben zusätzlich das Verhalten für verschiedene Auslastungsstufen vor. Obwohl aus Kostengründen jede Ressource maximal ausgelastet sein sollte, wird empfohlen, für entstehenden Mehraufwand im Betriebssystem noch Kapazitäten freizuhalten. Umgekehrt gilt bei einer Auslastung deutlich unter z. B. 50 %, dass möglicherweise nicht alle Ressourcenknoten benötigt werden und die Bereitstellung für einige von ihnen aufgehoben werden kann.
In der Praxis überwachen Dienstanbieter normalerweise eine Kombination verschiedener Metriken eines Ressourcenknotens, um zu bewerten, wann eine Ressourcenskalierung nötig ist. Dazu zählen z. B. CPU-Auslastung, Arbeitsspeichernutzung, Durchsatz und Latenz. Azure bietet mit Azure Monitor einen zusätzlichen Dienst zur Überwachung von Azure-Ressourcen, der auch die erforderlichen Metriken bereitstellt.
Zustandsloser Dienst
Ein zustandsloser Dienst ist für eine skalierbare Architektur geeignet. „Zustandslosigkeit“ bedeutet im Wesentlichen, dass die Clientanforderung alle Informationen enthält, die für eine Verarbeitung durch den Server erforderlich sind. Der Server speichert auf der Instanz keine Clientinformationen, sondern nur Sitzungsinformationen.
Ein zustandsloser Dienst erleichtert das Wechseln von Ressourcen nach Bedarf, ohne dass zur Beibehaltung des Kontexts (Zustands) der Clientverbindung für nachfolgende Anforderungen eine Konfiguration erforderlich ist. Bei einem zustandsbehafteten Dienst erfordert das Skalieren von Ressourcen eine Übertragungsstrategie für den Kontext von der bestehenden zur neuen Knotenkonfiguration. Beachten Sie, dass es für die Implementierung zustandsbehafteter Dienste verschiedene Möglichkeiten gibt, wie etwa das Beibehalten eines Netzwerkcaches mit Memcached für eine serverübergreifende Freigabe des Kontexts.
Welche Ressourcen sollen skaliert werden?
Basierend auf der Art des Diensts müssen je nach Anforderung unterschiedliche Ressourcen skaliert werden. Mit steigender Anzahl von Workloads auf der Serverebene können je nach Anwendungstyp die Ressourcenkonflikte um CPU, Arbeitsspeicher, Netzwerkbandbreite oder um alle diese Ressourcen zunehmen. Durch die Überwachung des Datenverkehrs können Sie herausfinden, für welche Ressource eine Überlastung droht, und diese Ressource dementsprechend skalieren. Meist stellen Clouddienstanbieter keine gestaffelte Skalierbarkeit für ausschließlich Compute- bzw. Arbeitsspeicherressourcen bereit, sondern unterschiedliche Arten von Compute-Instanzen für rechenintensive bzw. arbeitsspeicherintensive Anforderungen. Für eine Anwendung mit arbeitsspeicherintensiven Workloads wäre also etwa ein zentrales Hochskalieren in speicheroptimierte Instanzen sinnvoller. Für Anwendungen mit einer großen Anzahl von Anforderungen, die nicht unbedingt rechen- bzw. arbeitsspeicherintensiv sind, ist das horizontale Hochskalieren in mehrerer Standardcomputeinstanzen möglicherweise besser geeignet.
Zur Verbesserung der Leistung eines Diensts müssen nicht zwangsläufig die Hardwareressourcen erhöht werden. So können auch mit effizienteren Algorithmen Ressourcenkonflikte reduziert und die Auslastung eines Diensts verbessert werden, wodurch der Bedarf nach einer Skalierung der physischen Ressourcen entfällt.
Skalieren der Datenebene
In datenorientierten Anwendungen mit einer großen Anzahl von Lese- und Schreibvorgängen (oder beidem) in eine Datenbank oder ein Speichersystem wird die Roundtripzeit für die einzelnen Anforderungen häufig durch die E/A-Lese- und Schreibzeiten der Festplatte eingeschränkt. Größere Instanzen ermöglichen eine höhere E/A-Leistung für Lese- und Schreibvorgänge, wodurch die Suchzeiten auf der Festplatte verkürzt werden können, was wiederum zu einer deutlich verkürzten Latenzzeit des Diensts führen kann. Mit mehreren Dateninstanzen in der Datenebene kann die Zuverlässigkeit und Verfügbarkeit der Anwendung durch Failoverredundanzen verbessert werden. Zudem wird durch das instanzenübergreifende Replizieren von Daten die Netzwerklatenz reduziert, wenn der Client von einem physisch näher gelegenen Rechenzentrum verarbeitet wird. Das „Sharding“ genannte ressourcenübergreifende Partitionieren von Daten stellt eine weitere Methode zur horizontalen Datenskalierung dar. Dabei werden die Daten nicht nur auf mehreren Instanzen repliziert, sondern in mehrere Partitionen aufgeteilt und auf verschiedenen Datenservern gespeichert.
Eine weitere Schwierigkeit beim Skalieren der Datenebene ist das gleichzeitige Erfüllen der Eigenschaften Konsistenz (ein Lesevorgang ist auf allen Replikaten identisch), Verfügbarkeit (Lese- und Schreibvorgänge sind stets erfolgreich) und Partitionstoleranz (garantierte Eigenschaften im System werden auch bei fehlender Kommunikation zwischen Knoten als Folge eines Fehlers beibehalten). Laut dem sogenannten CAP-Theorem ist es in einem verteilten Datenbanksystem sehr schwierig, alle drei Eigenschaften vollständig zu erfüllen. Das System kann höchstens zwei der Eigenschaften gleichzeitig erfüllen. Weitere Informationen zu Skalierungsstrategien für Datenbanken und dem CAP-Theorem erhalten Sie in späteren Modulen.