Erstellen fehlertoleranter Clouddienste
Bei der Verwaltung von Rechenzentren und Clouddiensten geht es häufig um den Versuch, aus unzuverlässigen Komponenten einen zuverlässigen Dienst zu entwerfen und diesen aufrechtzuerhalten. Der folgende Ausschnitt aus einer Schulung für neue Mitarbeiter veranschaulicht das Ausmaß und die Anzahl von Fehlertypen, die regelmäßig in großen Rechenzentren auftreten.

Abbildung 2: Probleme bei der Zuverlässigkeit (Ausschnitt aus einer Mitarbeiterschulung)
Die Ursache eines Fehlers in einem System ist ein fehlerbedingter ungültiger Status. Folgende Fehlertypen treten häufig in Systemen auf:
- Vorübergehende Fehler: Temporäre Fehler im System, die mit der Zeit von selbst behoben werden.
- Permanente Fehler: Bei diesem Fehlertyp können die Ressourcen nicht mehr wiederhergestellt werden und müssen in der Regel ersetzt werden.
- Periodische Fehler: Fehler, die in einem System in regelmäßigen Abständen auftreten.
Fehler können sich auf die Verfügbarkeit des Systems auswirken, da sie Dienste oder die Leistung von Systemfunktionen beeinträchtigen. Ein fehlertolerantes System ist in der Lage, seine Funktion auch bei Fehlern im System aufrechtzuerhalten. In der Cloud wird Fehlertoleranz häufig gleichgesetzt mit der konsistenten Bereitstellung von Diensten, die weniger Ausfallzeiten aufweisen als in den Vereinbarungen zum Servicelevel (Service Level Agreements, SLAs) vorgesehen.
Gründe für die Wichtigkeit von Fehlertoleranz
Fehler in großen unternehmenskritischen Systemen können bei allen Beteiligten zu erheblichen finanziellen Verlusten führen. Naturgemäß verfügen Cloud Computing-Systeme über eine Architektur aus mehreren Ebenen. Ein Fehler in einer Ressourcenebene kann einen Fehler in einer höheren Ebene auslösen und den Zugriff auf eine niedrigere Ebene ausblenden.
Beispielsweise kann sich ein Fehler in einer Hardwarekomponente des Systems auf die normale Ausführung einer SaaS-Anwendung (Software-as-a-Service) auswirken, die auf einem virtuellen Computer mit den fehlerhaften Ressourcen ausgeführt wird. Auf allen Ebenen eines Systems stehen Fehler in direkter Beziehung zu den Vereinbarungen zum Servicelevel (SLAs) zwischen den Anbietern der jeweiligen Ebene.
Proaktive Maßnahmen
Schon beim Entwurf des Systems stehen Dienstanbietern verschiedene Möglichkeiten zur Verfügung, um bekannte Probleme oder vorhersagbare Fehler zu vermeiden.
Profilerstellung und Tests
Auslastungs- und Belastungstests für Cloudressourcen spielen bei der Identifizierung möglicher Fehlerursachen und somit für das Sicherstellen der Verfügbarkeit von Diensten eine entscheidende Rolle. Eine Profilerstellung für diese Metriken ermöglicht das Entwerfen eines Systems, das die erwartete Auslastung ohne unvorhersehbares Verhalten erfolgreich verarbeiten kann.
Übermäßige Bereitstellung
Bei der übermäßigen Bereitstellung werden mehr Ressourcen bereitgestellt, als für die voraussichtliche allgemeine Ressourcenauslastung zu einem bestimmten Zeitpunkt erforderlich ist. Können die exakten Anforderungen eines Systems nicht vorhergesagt werden, kann die übermäßige Bereitstellung von Ressourcen eine geeignete Strategie zur Verarbeitung von unerwarteten Spitzenlasten darstellen.
Nehmen Sie als Beispiel eine E-Commerce-Plattform mit einer über das ganze Jahr konsistenten durchschnittlichen Serverlast. In der Weihnachtszeit wird jedoch ein stark ansteigendes Auslastungsmuster erwartet. In einem solchen Szenario ist es sinnvoll, während der Spitzenzeiten zusätzliche Ressourcen basierend auf den Daten der bisherigen Spitzenlasten bereitzustellen. In der Regel ist es schwierig, eine schnelle Zunahme des Datenverkehrs in kurzer Zeit zu bewältigen. Wie Sie in späteren Abschnitten erfahren werden, ist der Zeitaufwand für eine dynamische Skalierung nicht zu vernachlässigen. Dazu zählen zeitaufwändige Schritte wie das Erkennen einer Änderung im Auslastungsmuster und das Bereitstellen weiterer Ressourcen zur Bewältigung der zusätzlichen Last. Das Ausführen dieser beiden Schritte erfordert eine gewisse Zeit. Diese Verzögerung bei der Anpassung kann ausreichen, um das System zu überlasten, was im besten Fall zu einer Beeinträchtigung der Dienstqualität, im schlechtesten Fall zu einem Systemabsturz führen kann.
Die übermäßige Bereitstellung kann auch ein Mittel im Kampf gegen DoS- (Denial-of-Service) oder DDoS-Angriffe (verteilte DoS-Angriffe) darstellen. Bei dieser Art von Angriffen generieren Angreifer große Mengen von Anforderungen, um ein System zu überlasten und es zum Absturz zu bringen. Bei solchen Angriffen dauert es eine gewisse Zeit, bis sie vom System erkannt und Gegenmaßnahmen eingeleitet werden. Bereits während der Analyse von Anforderungsmustern muss das angegriffene System in der Lage sein, bis zur Implementierung einer Ausgleichsstrategie den zunehmenden Datenverkehr zu verarbeiten.
Replikation
Mithilfe von zusätzlichen Hardware- und Softwarekomponenten können Sie wichtige Systemkomponenten duplizieren, um Fehler in einem Teil des Systems im Hintergrund zu beheben, ohne dass das gesamte System ausfällt. Die Replikation besteht aus zwei grundlegenden Strategien:
- Bei der aktiven Replikation sind alle replizierten Ressourcen gleichzeitig aktiv, um alle Anforderungen zu beantworten und zu verarbeiten. Dies bedeutet, dass bei jeder Clientanforderung alle Ressourcen dieselbe Anforderung empfangen, diese Anforderung beantworten und der Zustand für die Reihenfolge der Anforderungen ressourcenübergreifend beibehalten wird.
- Bei der passiven Replikation werden Anforderungen nur durch die primäre Einheit verarbeitet, während die sekundären Einheiten den Status beibehalten und bei einem Ausfall der primären Einheit die Verarbeitung übernehmen. Der Client kommuniziert nur mit der primären Ressource, die die Statusänderung an alle sekundären Ressourcen übergibt. Ein Nachteil der passiven Replikation besteht darin, dass es beim Wechsel von der primären zur sekundären Instanz zu gelöschten Anforderungen oder einer verminderten Dienstqualität kommen kann.
Neben diesen beiden Strategien steht auch eine semiaktive Hybridstrategie zur Verfügung, die der aktiven Strategie sehr ähnlich ist. Der Unterschied besteht darin, dass hier nur die Ausgabe der primären Ressource für den Client verfügbar gemacht wird. Die Ausgaben der sekundären Ressourcen werden unterdrückt und protokolliert. Bei einem Ausfall der primären Ressource kann zu diesen Ressourcen gewechselt werden. In der folgenden Abbildung werden die Unterschiede zwischen den Replikationsstrategien veranschaulicht:
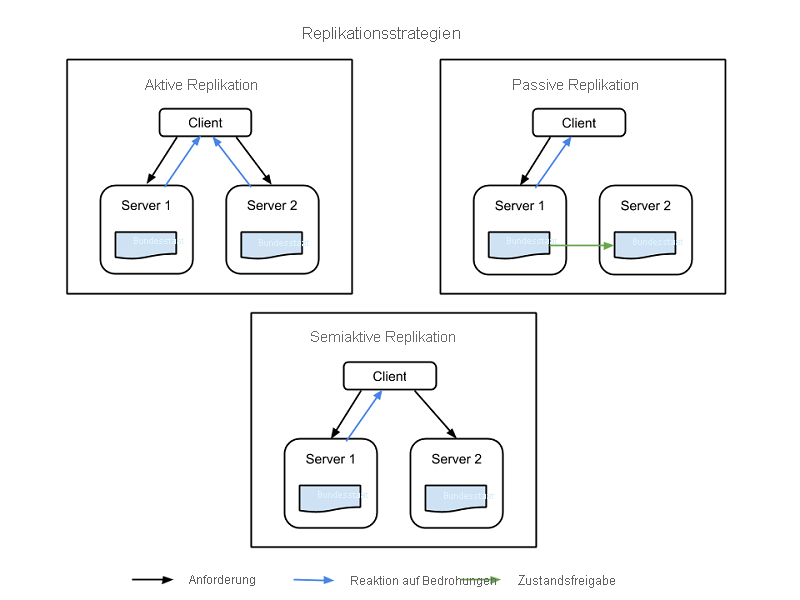
Abbildung 3: Replikationsstrategien
Ein wichtiger Faktor bei der Replikation ist die Anzahl der sekundären Ressourcen, die verwendet werden sollen. Es gibt drei formale Replikationsstufen, die je nach Wichtigkeit des Systems von Anwendung zu Anwendung variieren können:
- n+1: Bei dieser Stufe wird für eine Anwendung, die für eine normale Funktion n Knoten benötigt, eine zusätzliche Ressource zur Ausfallsicherheit bereitgestellt.
- 2n: Bei dieser Stufe wird für jeden Knoten, der für eine normale Funktion erforderlich ist, ein weiterer Knoten zur Ausfallsicherheit bereitgestellt.
- 2n+1: Bei dieser Stufe wird für jeden Knoten, der für eine normale Funktion erforderlich ist, ein zusätzlicher Knoten plus ein weiterer Knoten insgesamt zur Ausfallsicherheit bereitgestellt.
Reaktive Maßnahmen
Neben den zur Vorbeugung ausgeführten proaktiven Maßnahmen können Systeme auch die folgenden reaktiven Maßnahmen ergreifen, um auf auftretende Fehler zu reagieren:
Überprüfung und Überwachung
Alle Ressourcen werden ständig überwacht, damit nicht vorhersehbares Verhalten sowie der Verlust von Ressourcen identifiziert werden können. Basierend auf den dabei gewonnenen Informationen werden Strategien zur Wiederherstellung und Neukonfiguration entworfen, um Ressourcen erneut zu starten oder zu aktiveren. Bei der Überwachung können Fehler in den Systemen identifiziert werden. Fehler, die dazu führen, dass ein Dienst nicht verfügbar ist, werden als Absturzfehler bezeichnet. Fehler, die zu einem unregelmäßigen/falschen Verhalten im System führen, werden byzantinische Fehler genannt.
Für die Überprüfung von Absturzfehlern in einem System stehen verschiedene Überwachungsmethoden zur Verfügung. Zwei dieser Methoden sind:
- Ping-Echoüberwachung: Jede Ressource erhält vom Überwachungsdienst eine Statusanforderung, die innerhalb eines bestimmten Zeitfensters beantwortet werden muss.
- Taktüberwachung: Jede Instanz sendet ohne vorherigen Trigger ihren Status in regelmäßigen Abständen an den Überwachungsdienst.
Die Überwachung von byzantinischen Fehlern hängt in der Regel von den Eigenschaften des bereitgestellten Diensts ab. Überwachungssysteme können grundlegende Metriken wie Latenz, CPU-Auslastung und Speicherauslastung überprüfen und mit den erwarteten Werte vergleichen, um eine Beeinträchtigung der Dienstqualität festzustellen. Darüber hinaus werden in der Regel an jedem wichtigen Dienstausführungspunkt anwendungsspezifische Überwachungsprotokolle geführt und regelmäßig analysiert, um sicherzustellen, dass der Dienst jederzeit ordnungsgemäß funktioniert (oder ins System eingebrachte Fehler vorhanden sind).
Prüfpunkt und Neustart
Mehrere Programmiermodelle in der Cloud implementieren Prüfpunktstrategien, bei denen der Zustand in mehreren Ausführungsphasen gespeichert wird, um eine Wiederherstellung bis zu einem zuletzt gespeicherten Prüfpunkt zu ermöglichen. Bei Datenanalyseanwendungen gibt es häufig parallele verteilte Aufgaben mit langer Ausführungszeit, die für Datasets mit Terabyte von Daten ausgeführt werden, um Informationen zu extrahieren. Da diese Aufgaben in mehreren kleinen Ausführungsblöcken ausgeführt werden, kann jeder Schritt der Programmausführung den Gesamtausführungsstatus als Prüfpunkt speichern. Bei Fehlerquellen, bei denen einzelne Knoten ihre Arbeit nicht abschließen können, kann die Ausführung von einem vorherigen Prüfpunkt aus neu gestartet werden. Die größte Herausforderung bei der Identifizierung gültiger Prüfpunkte, auf die ein Rollback ausgeführt werden kann, besteht dann, wenn parallele Prozesse Informationen gemeinsam verwenden. Ein Fehler in einem der Prozesse kann ein kaskadierendes Rollback in einem anderen Prozess verursachen, da die in diesem Prozess erstellten Prüfpunkte das Ergebnis eines Fehlers in den Daten sein können, die vom fehlerhaften Prozess freigegeben wurden. Weitere Informationen zur Fehlertoleranz für Programmiermodelle finden Sie in späteren Modulen.
Fallstudien zu Resilienztests
Clouddienste müssen unter Berücksichtigung von Redundanz und Fehlertoleranz erstellt werden, da für keine der Komponenten eines großen verteilten Systems eine hundertprozentige Verfügbarkeit oder Uptime garantiert werden kann.
Alle Fehler (einschließlich Abhängigkeitsfehler im selben Knoten, Rack oder Rechenzentrum oder in regional redundanten Bereitstellungen) müssen ordnungsgemäß behandelt werden, ohne das System als Ganzes zu beeinträchtigen. Es ist wichtig, die Fähigkeit des Systems zu testen, mit katastrophalen Fehlern umzugehen, da manchmal schon wenige Sekunden Ausfallzeit oder Leistungsminderung eines Dienstes Hunderttausende, wenn nicht Millionen von Dollar an Einnahmeverlusten verursachen können.
Das Testen auf Fehler mit echtem Datenverkehr muss regelmäßig durchgeführt werden, damit die Sicherheit des Systems gestärkt wird und das System einen ungeplanten Ausfall verkraften kann. Es gibt verschiedene Systeme, die zum Testen der Resilienz entwickelt wurden. Eine derartige Testsammlung ist das von Netflix erstellte Tool Simian Army.
Simian Army besteht aus (als Monkeys bzw. Affen bezeichneten) Diensten in der Cloud, um verschiedene Arten von Fehlern zu generieren, ungewöhnliche Bedingungen zu erkennen und die Fähigkeit des Systems zu testen, diese zu meistern. Das Ziel besteht darin, die Cloud jederzeit sicher, geschützt und hochverfügbar zu machen. Einige der Monkeys der Simian Army sind:
- Chaos Monkey: Ein Tool, mit dem eine Produktionsinstanz zufällig ausgewählt und deaktiviert wird, um sicherzustellen, dass die Cloud gängige Fehlerarten ohne Auswirkungen auf Kunden übersteht. Netflix beschreibt Chaos Monkey wie folgt: „Stellen Sie sich vor, dass Sie einen wilden Affen mit einer Waffe in Ihrem Rechenzentrum (oder Ihrer Cloudregion) freilassen, der nach dem Zufallsprinzip Instanzen abschießt und Kabel durchkaut, während der Kundenservice ungestört aufrechterhalten wird.“ Durch diese Art von Tests mit eingehender Überwachung können unterschiedliche Schwachstellen im System aufgedeckt und auf der Grundlage der Ergebnisse automatische Wiederherstellungsstrategien entwickelt werden.
- Latency Monkey: Ein Dienst, der Verzögerungen in den RESTful-Kommunikationen zwischen verschiedenen Clients und Servern induziert und so eine Leistungsminderung des Dienstes und eine Ausfallzeit simuliert.
- Doctor Monkey: Ein Dienst, der Instanzen findet, die ein fehlerhaftes Verhalten aufweisen (z. B. CPU-Belastung), und diese aus dem Dienst entfernt. So gewinnen Dienstbesitzer Zeit, um den Grund für das Problem herauszufinden und schließlich die Instanz zu beenden.
- Chaos Gorilla: Ein Dienst, mit dem der Verlust einer ganzen AWS-Verfügbarkeitszone simuliert werden kann. Er wird verwendet, um zu testen, ob die Dienste die Funktionalität automatisch gleichmäßig auf die verbleibenden Zonen verteilen, ohne dass für den Benutzer sichtbare Auswirkungen auftreten oder manuelle Eingriffe nötig sind.