Übung: Implementieren von Azure OpenAI Service
Wir beginnen mit der einfachsten Vorlage: OpenAiService Dieser Dienst enthält nur zwei Methoden, die wir implementieren müssen, damit wir sofort einfache Prompts und Vervollständigungen implementieren können. Wir implementieren unseren Azure Cosmos DB for NoSQL-Datendienst erst später, sodass wir unsere Sitzungen noch nicht über Debugsitzungen hinaus aufrechterhalten können.
In dieser Übung gibt es einige wichtige Anforderungen:
- Senden einer Benutzerfrage an den KI-Assistenten mit Bitte um eine Antwort
- Senden einer Reihe von Prompts an den KI-Assistenten mit Bitte um eine Zusammenfassung der Unterhaltung
Stellen einer Frage an das KI-Modell
Implementieren Sie zunächst eine Frage-Antwort-Unterhaltung, indem Sie einen Systemprompt, eine Frage und Sitzungs-ID senden, damit das KI-Modell eine Antwort im Kontext der aktuellen Unterhaltung geben kann. Stellen Sie sicher, dass Sie die Anzahl der Token messen, die benötigt werden, um den Prompt zu parsen und eine Antwort (oder eine Vervollständigung in diesem Kontext) zurückzugeben.
Öffnen Sie die Datei Services/OpenAiService.cs.
Entfernen Sie innerhalb der
GetChatCompletionAsync-Methode eventuell vorhandenen Platzhaltercode:public async Task<(string completionText, int completionTokens)> GetChatCompletionAsync(string sessionId, string userPrompt) { }Erstellen Sie eine
ChatRequestSystemMessage-Variable mit dem NamensystemMessage. Verwenden Sie für diese Variable die RolleUserund die_systemPrompt-Variable für Inhalt.ChatRequestSystemMessage systemMessage = new(_systemPrompt);Erstellen Sie eine
ChatRequestUserMessage-Variable mit dem NamenuserMessage. Für diese Variable sollte die RolleChatRole.Userlauten und der KonstruktorparameteruserPromptfür den Inhalt der Nachricht verwendet werden.ChatRequestUserMessage userMessage = new(userPrompt);Erstellen Sie eine neue Variable mit dem Namen
optionsvom TypChatCompletionsOptions. Fügen Sie derMessages-Liste die beiden Nachrichtenvariablen hinzu, legen Sie den WertUserfür den KonstruktorparametersessionIdfest, legen SieMaxTokensauf4000fest, und legen Sie die restlichen Eigenschaften auf die hier empfohlenen Werte fest.ChatCompletionsOptions options = new() { DeploymentName = _modelName, Messages = { systemMessage, userMessage }, User = sessionId, MaxTokens = 4000, Temperature = 0.3f, NucleusSamplingFactor = 0.5f, FrequencyPenalty = 0, PresencePenalty = 0 };Tipp
4096 ist die maximale Anzahl an Token für das GPT-35-Turbo-Modell. Wir runden hier lediglich ab, um alles zu vereinfachen.
Rufen Sie asynchron die
GetChatCompletionsAsync-Methode der Azure OpenAI-Clientvariable (_client) auf. Übergeben Sie die von Ihnen erstellteoptionsVariable. Speichern Sie das Ergebnis in einer Variablen namenscompletionsvom TypChatCompletions.ChatCompletions completions = await _client.GetChatCompletionsAsync(options);Tipp
Die
GetChatCompletionsAsync-Methode gibt ein Objekt vom TypTask<Response<ChatCompletions>>zurück. DieResponse<T>-Klasse enthält eine implizite Konvertierung in den TypT, wodurch Sie einen Typ basierend auf den Anforderungen Ihrer Anwendung auswählen können. Sie können das Ergebnis entweder alsResponse<ChatCompletions>speichern, um die vollständigen Metadaten aus der Antwort abzurufen, oder nur alsChatCompletions, wenn Sie sich nur für den Inhalt des Ergebnisses selbst interessieren.Geben Sie schließlich ein Tupel als Ergebnis der
GetChatCompletionAsync-Methode zurück, mit dem Inhalt der Vervollständigung als Zeichenfolge, der Anzahl der Token, die dem Prompt zugeordnet sind, und der Anzahl der Token für die Antwort.return ( response: completions.Choices[0].Message.Content, promptTokens: completions.Usage.PromptTokens, responseTokens: completions.Usage.CompletionTokens );Speichern Sie die Datei Services/OpenAiService.cs.
Bitten des KI-Modells um die Zusammenfassung einer Unterhaltung
Senden Sie nun einen anderen Prompt, Ihre aktuelle Unterhaltung und die Sitzungs-ID an das KI-Modell, damit das KI-Modell die Unterhaltung in einigen Wörtern zusammenfassen kann.
Entfernen Sie innerhalb der
SummarizeAsync-Methode eventuell vorhandenen Platzhaltercode:public async Task<string> SummarizeAsync(string sessionId, string conversationText) { }Erstellen Sie eine
ChatRequestSystemMessage-Variable mit dem NamensystemMessage. Verwenden Sie für diese Variable die RolleUserund die_summarizePrompt-Variable für Inhalt.ChatRequestSystemMessage systemMessage = new(_summarizePrompt);Erstellen Sie eine weitere „
ChatRequestUserMessage“-Variable mit dem Namen „userMessage“. Verwenden Sie die RolleUsererneut, und verwenden Sie den KonstruktorparameterconversationTextfür den Inhalt der Nachricht.ChatRequestUserMessage userMessage = new(conversationText);Erstellen Sie eine
ChatCompletionsOptions-Variable mit dem Namenoptionsmit den beiden Nachrichtenvariablen in derMessages-Liste, wobeiUserauf densessionIdKonstruktorparameter undMaxTokensauf200festgelegt ist. Die restlichen Eigenschaften sind auf die hier empfohlenen Werte festgelegt:ChatCompletionsOptions options = new() { DeploymentName = _modelName, Messages = { systemMessage, userMessage }, User = sessionId, MaxTokens = 200, Temperature = 0.0f, NucleusSamplingFactor = 1.0f, FrequencyPenalty = 0, PresencePenalty = 0 };Rufen Sie
_client.GetChatCompletionsAsyncasynchron dieoptionsVariable als Parameter auf. Speichern Sie das Ergebnis in einer Variablen namenscompletionsvom TypChatCompletions.ChatCompletions completions = await _client.GetChatCompletionsAsync(options);Geben Sie den Inhalt der Vervollständigung als Zeichenfolge im Ergebnis der
SummarizeAsync-Methode zurück.return completions.Choices[0].Message.Content;Speichern Sie die Datei Services/OpenAiService.cs.
Arbeit überprüfen
Zu diesem Zeitpunkt sollte Ihre Anwendung über eine Implementierung von Azure OpenAI Service verfügen, die für Testzwecke ausreichend ist. Bedenken Sie, dass Sie noch keinen Datenspeicher implementiert haben, sodass Ihre Unterhaltungen zwischen Debugsitzungen nicht gespeichert werden.
Öffnen Sie ein neues Terminal.
Starten Sie die Anwendung mit aktivierten Hot Reloads mithilfe von
dotnet watch.dotnet watch run --non-interactiveTipp
Das Feature Hot Reload ist aktiviert, falls Sie eine kleine Korrektur am Code der Anwendung vornehmen müssen. Weitere Informationen finden Sie unter .NET Hot Reload-Unterstützung für ASP.NET Core.
Visual Studio Code startet den einfachen Browser im Tool mit der ausgeführten Webanwendung neu. Erstellen Sie in der Webanwendung eine neue Chatsitzung, und stellen Sie dem KI-Assistenten eine Frage. Der KI-Assistent antwortet nun mit einer Vervollständigung, die vom Modell erstellt wurde. Beachten Sie auch, dass die Benutzeroberflächenfelder Token jetzt mit der tatsächlichen Tokenverwendung für jede Vervollständigung und jeden Prompt aufgefüllt werden.
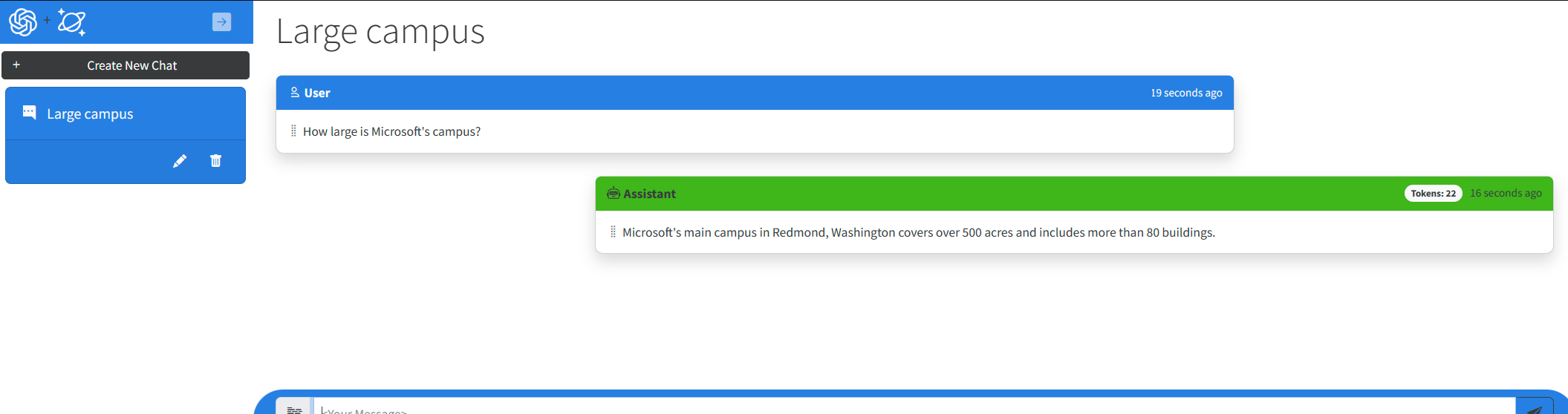
Schließen Sie das Terminal.
