Erkunden von Event Hubs Capture
Azure Event Hubs ermöglicht Ihnen die automatische Erfassung von Streamingdaten in Event Hubs in einem Azure Blob Storage- oder Azure Data Lake Store-Konto Ihrer Wahl. Um für mehr Flexibilität zu sorgen, ist dabei die Angabe eines Zeit- oder Größenintervalls möglich. Capture lässt sich schnell einrichten, es fallen keine Verwaltungskosten zur Ausführung an, und es wird automatisch mit Event Hubs-Durchsatzeinheiten im Standard-Tarif oder Verarbeitungseinheiten im Premium-Tarif skaliert.
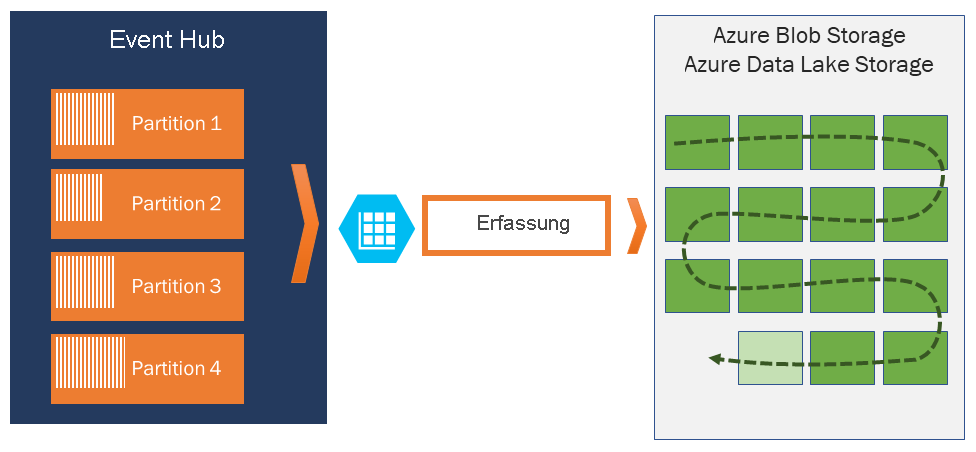
Event Hubs Capture ermöglicht Ihnen das Verarbeiten von Echtzeitpipelines und batchbasierten Pipelines für den gleichen Datenstrom. Dies bedeutet, dass Sie Lösungen erstellen können, die im Laufe der Zeit gemäß Ihren veränderten Anforderungen mitwachsen.
Funktionsweise von Event Hubs Capture
Event Hubs ist ein beständiger Puffer mit zeitbasierter Speicherung für Telemetrieeingänge, vergleichbar mit einem verteilten Protokoll. Der Schlüssel zur Skalierung in Event Hubs ist das partitionierte Consumermodell. Jede Partition ist ein unabhängiges Datensegment und wird unabhängig genutzt. Mit der Zeit werden diese Daten basierend auf der konfigurierbaren Beibehaltungsdauer ersetzt. Daher kann ein Event Hub nie „zu voll“ werden.
Mit Event Hubs Capture können Sie zum Speichern der erfassten Daten ein eigenes Azure Blob Storage-Konto und einen Container bzw. ein Azure Data Lake Store-Konto angeben. Diese Konten können sich in der gleichen Region wie Ihr Event Hub oder in einer anderen Region befinden, um die Flexibilität von Event Hubs Capture zu erhöhen.
Erfasste Daten werden im Apache Avro-Format geschrieben. Hierbei handelt es sich um ein kompaktes, schnelles, binäres Format mit umfangreichen Datenstrukturen und Inlineschema. Dieses Format wird häufig im Hadoop-Ökosystem, von Stream Analytics und von Azure Data Factory verwendet. Weitere Informationen zum Arbeiten mit Avro finden Sie weiter unten in diesem Artikel.
Capture-Fenster
Event Hubs Capture ermöglicht Ihnen das Einrichten eines Fensters zur Steuerung der Erfassung. Dieses Fenster ist eine Konfiguration mit Mindestgröße und -zeit, für die das Prinzip „First wins“ gilt. Dies bedeutet, dass der erste Trigger, der auftritt, zu einem Erfassungsvorgang führt. Jede Partition wird unabhängig erfasst und schreibt zum Erfassungszeitpunkt einen abgeschlossenen Blockblob. Dieser wird nach dem Zeitpunkt benannt, zu dem das Erfassungsintervall aufgetreten ist. Die Namenskonvention für die Speicherung lautet wie folgt:
{Namespace}/{EventHub}/{PartitionId}/{Year}/{Month}/{Day}/{Hour}/{Minute}/{Second}
Beachten Sie, dass die Datumswerte mit Nullen aufgefüllt werden. Ein Beispieldateiname hierfür lautet:
https://mystorageaccount.blob.core.windows.net/mycontainer/mynamespace/myeventhub/0/2017/12/08/03/03/17.avro
Skalierung auf Durchsatzeinheiten
Der Datenverkehr von Event Hubs wird von Durchsatzeinheiten gesteuert. Eine einzelne Durchsatzeinheit lässt eingehenden Datenverkehr von 1 MB pro Sekunde oder 1,000 Ereignisse pro Sekunde und die doppelte Menge an ausgehendem Datenverkehr zu. Event Hubs Standard kann mit 1 bis 20 Durchsatzeinheiten konfiguriert werden, und über eine Supportanfrage für eine Kontingenterhöhung können weitere Einheiten erworben werden. Bei Überschreitung der erworbenen Durchsatzeinheiten wird die Nutzung gedrosselt. Bei Event Hubs Capture werden Daten direkt aus dem internen Event Hubs-Speicher kopiert. Dabei werden Durchsatzeinheitenkontingente für ausgehenden Datenverkehr umgangen und stattdessen für andere Verarbeitungsreader wie Stream Analytics oder Spark verwendet.
Nach der Konfiguration wird Event Hubs Capture automatisch ausgeführt, wenn Sie Ihr erstes Ereignis senden, und die Ausführung bleibt aktiv. Damit für Ihre Downstreamverarbeitung leichter erkannt wird, dass der Prozess ausgeführt wird, schreibt Event Hubs leere Dateien, wenn keine Daten vorhanden sind. Dieser Prozess sorgt für einen vorhersagbaren Rhythmus und Marker, die als Feed für Ihre Batchprozessoren fungieren.