Übung: Erstellen und Trainieren eines neuronalen Netzes
In dieser Lerneinheit verwenden Sie Keras, um ein neuronales Netz zu erstellen und zu trainieren, das die Stimmung von Texten analysiert. Sie benötigen Daten, um ein neuronales Netz zu trainieren. Wir laden hierfür kein externes Dataset herunter, sondern verwenden das in Keras enthaltene Dataset IMDb Movie reviews sentiment classification (Stimmungsklassifizierung von Filmkritiken aus der IMDb). Das IMDb-Dataset enthält 50.000 Filmkritiken, die einzeln als positiv (1) oder negativ (0) bewertet wurden. Das Dataset ist in 25.000 Bewertungen für das Training und 25.000 Bewertungen für das Testen unterteilt. Die Stimmung, die in diesen Bewertungen ausgedrückt wird, dient als Grundlage, auf der Ihr neuronales Netz Texte analysiert und deren Stimmung bewertet.
Das IMDb-Dataset ist nur eines der nützlichen Datasets, die in Keras enthalten sind. Eine vollständige Liste der integrierten Datasets finden Sie unter https://keras.io/datasets/.
Geben oder fügen Sie folgenden Code in die erste Zelle des Notebooks ein, und klicken Sie auf Run (Ausführen) (oder drücken Sie UMSCHALT+EINGABETASTE), um den Code auszuführen und eine neue Zelle darunter einzufügen:
from keras.datasets import imdb top_words = 10000 (x_train, y_train), (x_test, y_test) = imdb.load_data(num_words=top_words)Mit diesem Code wird das in Keras enthaltene IMDb-Dataset geladen und ein Wörterbuch erstellt, das die Wörter aller 50.000 Bewertungen ganzzahligen Werten zuweist, die die relative Häufigkeit dieser Wörter angeben. Jedes Wort wird einem eindeutigen ganzzahligen Wert zugewiesen. Dem häufigsten Wort wird die Zahl 1 zugewiesen, dem zweithäufigsten die Zahl 2 (und so weiter).
load_datagibt zudem zwei Tupel zurück, die die Filmkritiken enthalten (in diesem Beispielx_trainundx_test), und die Bewertungen werden durch die Werte 1 und 0 als positiv oder negativ (y_trainundy_test) klassifiziert.Vergewissern Sie sich, dass die Meldung „Using TensorFlow backend“ (TensorFlow-Back-End wird verwendet) angezeigt wird, die angibt, dass Keras TensorFlow als Back-End verwendet.
Laden des IMDb-Dataset
Wenn Sie möchten, dass Keras das Microsoft Cognitive Toolkit (auch CNTK) als Back-End verwendet, können Sie dies erreichen, indem Sie ein paar Codezeilen am Anfang des Notebooks hinzufügen. Ein Beispiel hierfür finden Sie unter CNTK and Keras in Azure Notebooks (CNTK und Keras in Azure Notebooks).
Was genau hat die Funktion
load_datanun geladen? Die Variable namensx_trainstellt eine Liste mit 25.000 Listen dar, von der jeder einer Filmkritik entspricht. (x_testist ebenfalls eine Liste mit 25.000 Listen, die 25.000 Kritiken darstellen.x_trainwird für das Training undx_testzum Testen verwendet.) Die inneren Listen, also die, die Filmkritiken darstellen, enthalten keine Wörter, sondern ganze Zahlen. Lesen Sie sich hierzu diese Beschreibung aus der Keras-Dokumentation durch: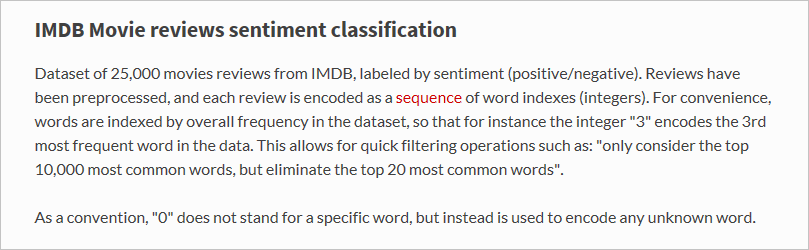
Die inneren Listen enthalten Zahlen anstelle von Text, weil Sie ein neuronales Netz nicht mit Text, sondern mit Zahlen trainieren. Genau genommen trainieren Sie es mit sogenannten Tensoren. In diesem Fall entspricht jede Bewertung einem eindimensionalen Tensor (stellen Sie sich diesen wie ein eindimensionales Array vor), der ganzzahlige Werte enthält, mit denen die in der Bewertung verwendeten Wörter erkannt werden. Testen Sie diese Funktion, indem Sie folgende Python-Anweisung in eine leere Zelle eingeben und diese ausführen, um die ganzzahligen Werte zu anzuzeigen, die die erste Bewertung im Trainingsdataset darstellen:
x_train[0]
Ganzzahlige Werte, die aus der ersten Bewertung im IMDb-Trainingsdataset ermittelt wurden
Die erste Zahl auf der Liste, 1, steht nicht für ein Wort. Sie kennzeichnet den Beginn der Bewertung und wird in allen Bewertungen im Dataset zu diesem Zweck verwendet. Die Zahlen 0 und 2 sind ebenfalls reserviert, und Sie müssen von den anderen Zahlen den Wert 3 subtrahieren, um einen ganzzahligen Wert in der Bewertung der entsprechenden (ganzen) Zahl im Wörterbuch zuzuordnen. Die zweite Zahl, 14, verweist auf das Wort, das der Zahl 11 im Wörterbuch entspricht, und die dritte Zahl verweist auf das Wort, das der Zahl 19 im Wörterbuch zugeordnet ist (und so weiter).
Möchten Sie wissen, wie das Wörterbuch aussieht? Führen Sie folgende Anweisung in einer neuen Zelle des Notebooks aus:
imdb.get_word_index()Nur eine Teilmenge der Wörterbucheinträge wird angezeigt. Insgesamt enthält das Wörterbuch jedoch über 88.000 Wörter und die entsprechenden ganzzahligen Werte. Ihre Ausgabe stimmt wahrscheinlich nicht mit der Ausgabe auf dem Screenshot überein, da das Wörterbuch jedes Mal neu generiert wird, wenn
load_dataaufgerufen wird.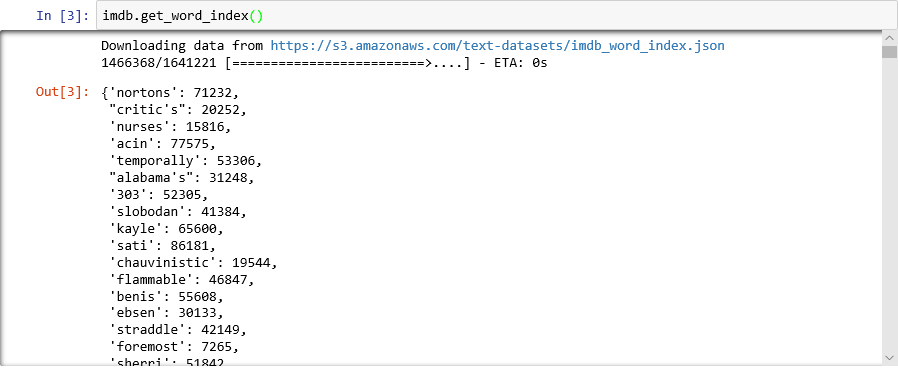
Wörterbuch, das Wörter ganzzahligen Werten zuordnet
Wie Sie sehen, wird jede Bewertung im Dataset als Auflistung ganzzahliger Werte anstatt als Wörter codiert. Ist es möglich, eine Bewertung rückwärts zu codieren, sodass der ursprüngliche Text angezeigt wird, aus dem sie abgeleitet wurde? Geben Sie folgende Anweisungen in eine neue Zelle ein, und führen Sie diese aus, um die erste Bewertung in
x_trainim Textformat anzuzeigen:word_dict = imdb.get_word_index() word_dict = { key:(value + 3) for key, value in word_dict.items() } word_dict[''] = 0 # Padding word_dict['>'] = 1 # Start word_dict['?'] = 2 # Unknown word reverse_word_dict = { value:key for key, value in word_dict.items() } print(' '.join(reverse_word_dict[id] for id in x_train[0]))In der Ausgabe markiert „>“ den Beginn der Bewertung, während „?“ Wörter markiert, die nicht zu den häufigsten 10.000 Wörtern im Dataset zählen. Diese „unbekannten“ Wörter werden in der Liste der ganzzahligen Werte einer Bewertung mit dem Wert 2 dargestellt. Erinnern Sie sich an den Parameter
num_words, den Sie anload_dataübergeben haben? Hier kommt er zum Einsatz. Er reduziert nicht die Größe des Wörterbuchs, sondern schränkt den ganzzahligen Wertebereich ein, der zum Codieren der Bewertungen verwendet wird.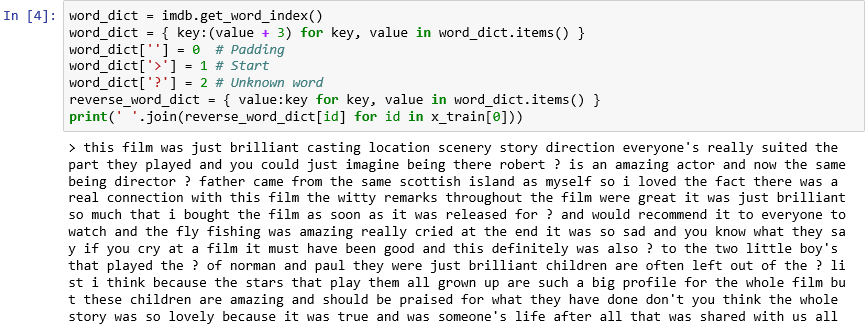
Die erste Bewertung im Textformat
Die Bewertungen wurden insofern „bereinigt“, dass die Buchstaben in Kleinbuchstaben konvertiert und die Satzzeichen entfernt wurden. Sie sind jedoch noch nicht dafür geeignet, ein neuronales Netz für die Analyse der Stimmung von Texten zu trainieren. Wenn Sie ein neuronales Netz mit einer Sammlung von Tensoren trainieren, muss jeder Tensor die gleiche Länge aufweisen. Derzeit weisen die Listen, die Bewertungen in
x_trainundx_testdarstellen, unterschiedliche Längen auf.Praktischerweise enthält Keras eine Funktion, die eine Liste von Listen als Eingabe akzeptiert und die inneren Listen auf eine bestimmte Länge konvertiert, indem diese bei Bedarf gekürzt oder mit Nullen (0) aufgefüllt werden. Geben Sie folgenden Code in das Notebook ein, und führen Sie diesen aus, um alle Listen, die Filmkritiken in
x_trainundx_testdarstellen, auf eine Länge von 500 ganzzahligen Werten zu vereinheitlichen:from keras.preprocessing import sequence max_review_length = 500 x_train = sequence.pad_sequences(x_train, maxlen=max_review_length) x_test = sequence.pad_sequences(x_test, maxlen=max_review_length)Da die Trainings- und Testdaten nun vorbereitet sind, können Sie mit dem Erstellen des Modells beginnen! Führen Sie folgenden Code im Notebook aus, um ein neuronales Netz zu erstellen, das die Stimmung analysiert:
from keras.models import Sequential from keras.layers import Dense from keras.layers.embeddings import Embedding from keras.layers import Flatten embedding_vector_length = 32 model = Sequential() model.add(Embedding(top_words, embedding_vector_length, input_length=max_review_length)) model.add(Flatten()) model.add(Dense(16, activation='relu')) model.add(Dense(16, activation='relu')) model.add(Dense(1, activation='sigmoid')) model.compile(loss='binary_crossentropy',optimizer='adam', metrics=['accuracy']) print(model.summary())Vergewissern Sie sich, dass die Ausgabe folgendermaßen aussieht:
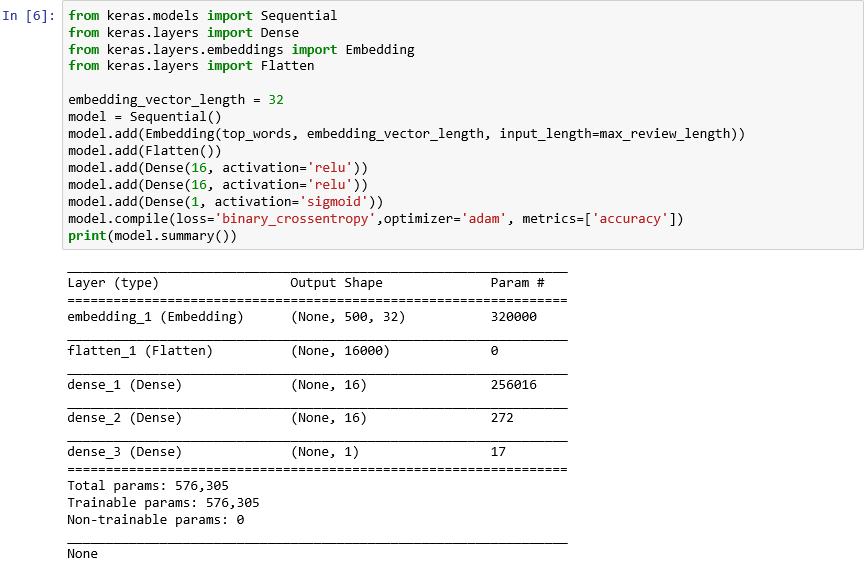
Erstellen eines neuronalen Netzes mit Keras
Dieser Code ist das Grundgerüst für das Erstellen eines neuronalen Netzes mit Keras. Zuerst wird ein
Sequential-Objekt instanziiert, das ein sequenzielles Modell darstellt, also ein Modell, das aus einem End-to-End-Stapel aus Schichten besteht, bei denen die Ausgabe einer Schicht die Eingabe für die nächste bereitstellt.Die nächsten Anweisungen fügen Schichten zum Modell hinzu. Die erste ist eine Einbettungsschicht, die in neuronalen Netzen vorhanden sein muss, die Wörter verarbeiten. Die Einbettungsschicht ordnet im wesentlichen mehrdimensionale Arrays mit ganzzahligen Wortindizes Gleitkommaarrays mit weniger Dimensionen zu. Zudem ermöglicht diese Ebene, dass Wörter mit ähnlichen Bedeutungen gleich verarbeitet werden. Eine vollständige Erläuterung der Worteinbettungen würde den Umfang dieser Übung überschreiten. Wenn Sie mehr zu diesem Thema erfahren möchten, können Sie den Artikel Why You Need to Start Using Embedding Layers (Deshalb sollten Sie Einbettungsschichten verwenden) lesen. Wenn Sie eine wissenschaftlichere Erklärung bevorzugen, können Sie das Paper Efficient Estimation of Word Representations in Vector Space (Effiziente Schätzung von Wortdarstellungen im Vektorraum) lesen. Der Aufruf von Flatten gefolgt vom Hinzufügen der Einbettungsschicht erstellt aus der Ausgabe die Eingabe für die nächste Schicht.
Die nächsten drei Schichten, die zum Modell hinzugefügt werden, sind dichte Schichten (alternativ vollständig verbundene Schichten). Diese Schichten sind in neuronalen Netzen üblicherweise vorhanden. Jede Schicht enthält n Knoten oder Neuronen, und jedes Neuron empfängt Eingaben von allen Neuronen in der vorherigen Schicht. Daher stammt der Begriff „vollständig verbunden“. Durch diese Schichten kann ein neuronales Netz aus Eingabedaten „lernen“, indem es iterativ die Ausgabe schätzt, die Ergebnisse überprüft und die Verbindungen anpasst, um bessere Ergebnisse zu erzielen. Die ersten beiden dichten Schichten in diesem Netz enthalten jeweils 16 Neuronen. Diese Anzahl wurde willkürlich ausgewählt. Sie können die Genauigkeit des Modells verbessern, indem Sie mit unterschiedlichen Größen experimentieren. Die letzte dichte Schicht enthält nur ein Neuron, da das Ziel des Netzes darin besteht, eine Ausgabe vorherzusagen: einen Stimmungswert zwischen 0.0 und 1.0.
Das Ergebnis ist folgendes neuronales Netz. Das Netz enthält eine Eingabeschicht, eine Ausgabeschicht und zwei verborgene Schichten (die dichten Schichten enthalten je 16 Neuronen). Zum Vergleich: Einige der heutzutage verwendeten komplexeren neuronalen Netze bestehen aus über 100 Schichten. Ein Beispiel hierfür ist das Netz ResNet-152 von Microsoft Research, dessen Genauigkeit beim Identifizieren von Objekten in Fotos manchmal die eines Menschen übersteigt. Sie können ResNet-152 mit Keras erstellen, aber Sie würden einen mit GPUs ausgestatteten Computercluster benötigen, um das Modell von Grund auf zu trainieren.
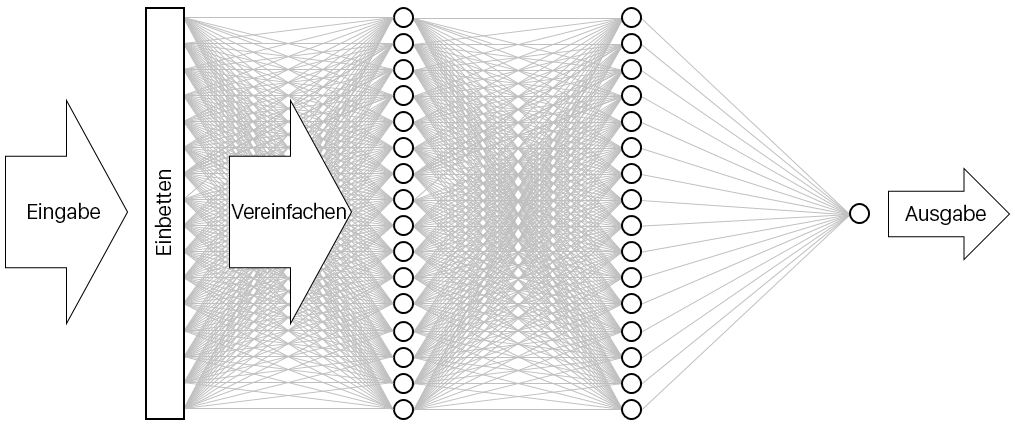
Visualisieren des neuronalen Netzes
Durch den Aufruf der compile-Funktion wird das Modell kompiliert, indem wichtige Parameter festgelegt werden – z.B., welcher Optimierer verwendet werden soll und welche Metriken zur Bewertung der Genauigkeit des Modells in jedem Trainingsschritt verwendet werden sollen. Das Training beginnt erst, wenn Sie die Funktion
fitdes Modells aufrufen. Der Aufruf voncompilewird also in der Regel schnell ausgeführt.Rufen Sie nun die Funktion fit auf, um das neuronale Netz zu trainieren:
hist = model.fit(x_train, y_train, validation_data=(x_test, y_test), epochs=5, batch_size=128)Das Training sollte etwa sechs Minuten bzw. etwas mehr als eine Minute pro Periode dauern.
epochs=5weist Keras an, je 5 Vorwärts- und Rückwärtsdurchläufe durch das Modell auszuführen. Mit jedem Durchlauf lernt das Modell aus den Trainingsdaten und misst („überprüft“), wie gut es aus den Testdaten gelernt hat. Anschließend nimmt es Anpassungen vor und fährt mit dem nächsten Durchlauf bzw. der nächsten Periode fort. Dieser Vorgang wird in der Ausgabe der Funktionfitersichtlich, die die Genauigkeit des Trainings (acc) und der Überprüfung (val_acc) für jede Periode anzeigt.batch_size=128weist Keras an, 128 Trainingsbeispiele gleichzeitig zu verwenden, um das Netz zu trainieren. Durch größere Batches wird die Trainingsdauer verkürzt (für jede Periode werden weniger Durchläufe benötigt, um alle Trainingsdaten zu verwenden), aber durch kleinere Batches kann manchmal die Genauigkeit verbessert werden. Wenn Sie dieses Lab abgeschlossen haben, sollten Sie das Modell mit einer Batchgröße von 32 erneut trainieren, um festzustellen, welche Auswirkung dieser Vorgang ggf. auf die Genauigkeit des Modells hat. Die Trainingsdauer wird dadurch in etwa verdoppelt.
Trainieren des Modells
Das Ungewöhnliche an diesem Modell ist, dass es in nur wenigen Perioden gute Lernfortschritte macht. Die Genauigkeit des Trainings verbessert sich schnell auf nahezu 100 %, während die Genauigkeit der Überprüfung für ein bis zwei Perioden ansteigt und dann sinkt. Sie sollten ein Modell generell nicht länger als nötig trainieren, damit die Genauigkeit sich stabilisiert. Es besteht das Risiko der Überanpassung, die dazu führt, dass das Modell für Testdaten gut geeignet ist, nicht aber für Daten in der Praxis. Ein Anzeichen dafür, dass ein Modell überangepasst wurde, ist eine größer werdende Abweichung zwischen der Trainings- und der Überprüfungsgenauigkeit. Eine Einführung in die Überanpassung finden Sie unter Overfitting in Machine Learning: What It Is and How to Prevent It (Überanpassung beim Machine Learning: Definition und vorbeugende Maßnahmen).
Führen Sie folgende Anweisungen in einer neuen Zelle des Notebooks aus, um diese Änderungen bei der Trainings- und Überprüfungsgenauigkeit während des Trainingsfortschritts zu visualisieren:
import seaborn as sns import matplotlib.pyplot as plt %matplotlib inline sns.set() acc = hist.history['acc'] val = hist.history['val_acc'] epochs = range(1, len(acc) + 1) plt.plot(epochs, acc, '-', label='Training accuracy') plt.plot(epochs, val, ':', label='Validation accuracy') plt.title('Training and Validation Accuracy') plt.xlabel('Epoch') plt.ylabel('Accuracy') plt.legend(loc='upper left') plt.plot()Die Genauigkeitsdaten stammen aus dem
history-Objekt, das von der Funktionfitdes Modells zurückgegeben wird. Würden Sie anhand des erstellten Diagramms empfehlen, die Anzahl der Trainingsperioden zu erhöhen, zu verringern oder nicht zu verändern?Sie können das Modell auch auf Überanpassung überprüfen, indem Sie den Trainingsverlust mit dem Überprüfungsverlust während des Trainingsfortschritts vergleichen. Sie können die Verlustfunktion minimieren, indem Sie diese Probleme beheben. Weitere Informationen finden Sie hier. Wenn der Trainingsverlust in einer Periode erheblich größer als der Überprüfungsverlust ist, kann das auf eine Überanpassung hindeuten. Im vorherigen Schritt haben Sie die Eigenschaften
accundval_accderhistory-Eigenschaft deshistory-Objekts verwendet, um die Trainings- und Überprüfungsgenauigkeit darzustellen. Diese Eigenschaft enthält auch die Wertelossundval_loss, die den Trainings- bzw. Genauigkeitsverlust darstellen. Wie würden Sie den oben stehenden Code anpassen, damit diese Werte in einem Diagramm wie dem folgenden dargestellt werden?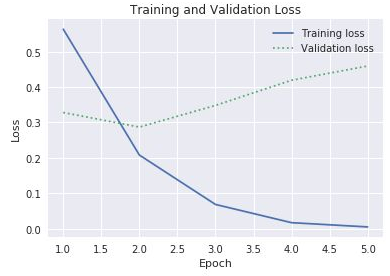
Trainings- und Überprüfungsverlust
Sehen Sie sich die Lücke zwischen dem Trainings- und dem Überprüfungsverlust an, die in der dritten Periode beginnt. Was würden Sie antworten, wenn jemand vorschlägt, die Anzahl der Perioden auf 10 oder 20 zu erhöhen?
Rufen Sie zum Schluss die Methode
evaluatedes Modells auf, um zu bestimmen, wie genau das Modell die Stimmung im Text anhand der Testdaten inx_test(Bewertungen) undy_test(0- und 1-Werte bzw. „Bezeichnung“, die für positive und negative Bewertungen stehen) definieren kann:scores = model.evaluate(x_test, y_test, verbose=0) print("Accuracy: %.2f%%" % (scores[1] * 100))Welche Genauigkeit wird für Ihr Modell berechnet?
Sie haben wahrscheinlich eine Genauigkeit zwischen 85 % und 90 % erzielt. Das ist ein akzeptabler Wert, da Sie das Modell von Grund auf erstellt haben, anstatt ein vortrainiertes neuronales Netz zu verwenden, und da die Trainingsdauer auch ohne GPU kurz war. Es ist möglich, mit anderen Architekturen für neuronale Netze eine Genauigkeit von 95 % oder höher zu erzielen, insbesondere mit rekurrenten neuronalen Netzen (RNNs), die Long Short-Term Memory-Schichten (LSTM) verwenden. Mit Keras können Sie solche Netze mühelos erstellen, die Trainingsdauer kann sich jedoch exponentiell erhöhen. Das von Ihnen erstellte Modell weist eine gute Balance zwischen Genauigkeit und Trainingsdauer auf. Wenn Sie jedoch mehr über das Erstellen rekurrenter neuronaler Netze mit Keras erfahren möchten, finden Sie weitere Informationen unter Understanding LSTM and its Quick Implementation in Keras for Sentiment Analysis (Grundlegendes zu Long Short-Term Memory und der schnellen Implementierung in Keras für die Stimmungsanalyse).