Skalieren mit KEDA
Ereignisgesteuerte automatische Kubernetes-Skalierung
Kubernetes Event-driven Autocaling (KEDA) ist eine zweckgerichtete und einfache Komponente zur Vereinfachung der automatischen Skalierung von Anwendungen. Sie können KEDA jedem Kubernetes-Cluster hinzufügen und zusammen mit Kubernetes-Standardkomponenten wie der horizontalen automatischen Podskalierung (Horizontal Pod Autoscaler, HPA) oder der automatischen Clusterskalierung verwenden, um ihre Funktionalität zu erweitern. Mit KEDA können Sie auf bestimmte Apps abzielen, für die die ereignisgesteuerte Skalierung genutzt werden soll, während andere Apps andere Skalierungsmethoden verwenden können. Dies macht KEDA zu einer flexiblen und sicheren Option, die zusammen mit einer beliebigen Anzahl von Kubernetes-Anwendungen oder -Frameworks ausgeführt werden kann.
Wichtige Funktionen und Features
- Erstellen nachhaltiger und kostengünstiger Anwendungen mit Funktionen für die Skalierungs auf null
- Skalieren von Anwendungsworkloads, um den Bedarf mithilfe von KEDA-Skalierungen zu erfüllen
- Automatisches Skalieren von Anwendungen mit
ScaledObjects - Automatisches Skalieren von Aufträgen mit
ScaledJobs - Verwenden der Sicherheit auf Produktionsniveau durch Entkoppeln der automatischen Skalierung und Authentifizierung von Workloads
- Verwenden eigener externer Skalierungen, um maßgeschneiderte Konfigurationen für die automatische Skalierung zu verwenden
Aufbau
KEDA bietet zwei Hauptkomponenten:
- KEDA-Operator: Ermöglicht es Endbenutzern, Workloads von null auf N-Instanzen mit Unterstützung für Kubernetes-Bereitstellungen, Aufträge, StatefulSets oder beliebige Kundenressourcen auf- oder abzuskalieren, die eine
/scale-Unterressource definieren. - Metrikserver: Macht externe Metriken für die HPA verfügbar, z. B. Nachrichten in einem Kafka-Thema oder Ereignisse in Azure Event Hubs, um automatische Skalierungsaktionen zu ermöglichen. Aufgrund von Upstreameinschränkungen muss der KEDA-Metrikserver der einzige installierte Metrikadapter im Cluster sein.
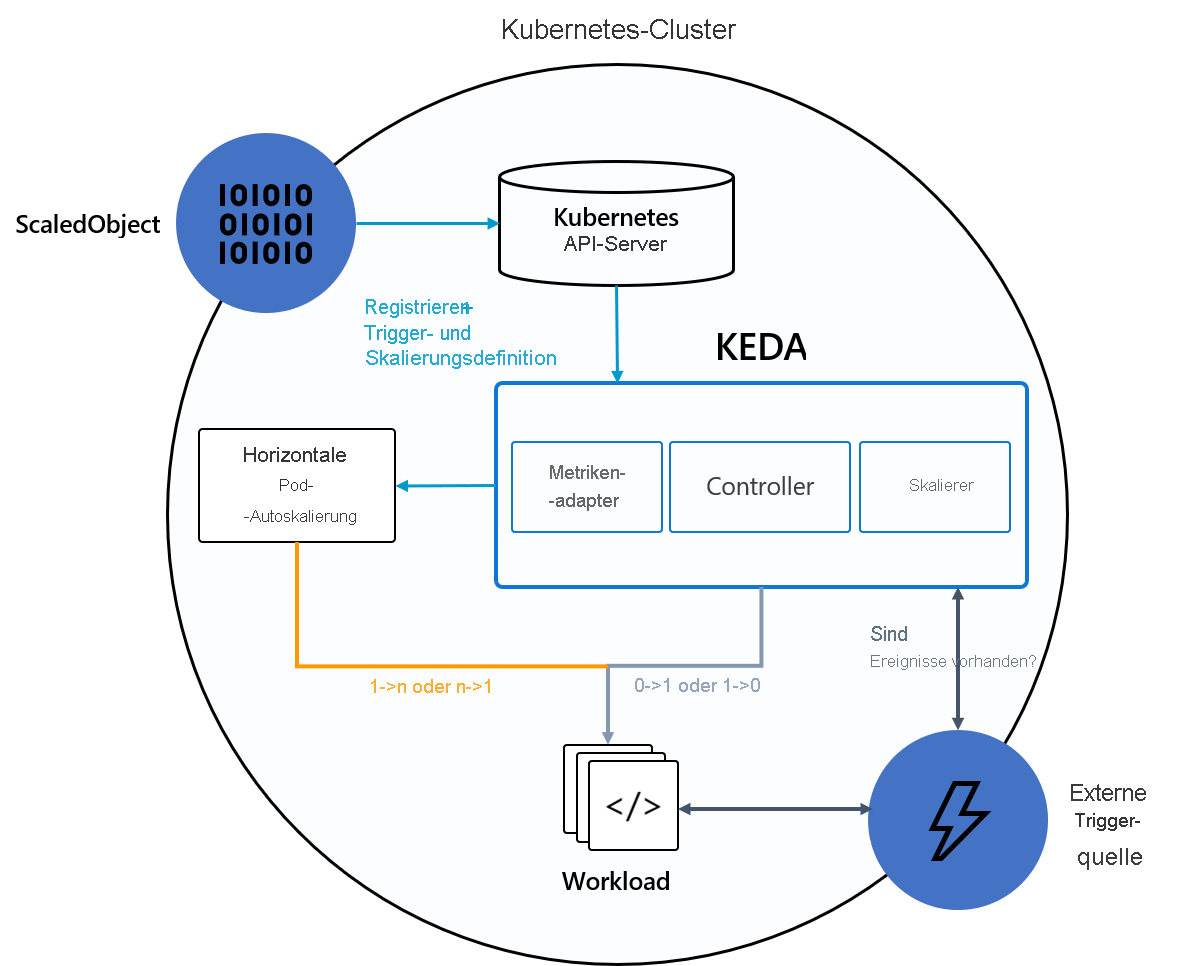
Das folgende Diagramm zeigt, wie KEDA in Kubernetes-HPA, externe Ereignisquellen und den Kubernetes-API-Server integriert wird, um Funktionen für die automatische Skalierung bereitzustellen:
Tipp
Ausführlichere Informationen finden Sie in der offiziellen KEDA-Dokumentation.
Ereignisquellen und Skalierungen
KEDA-Skalierungen können erkennen, ob eine Bereitstellung aktiviert oder deaktiviert werden sollte, sowie benutzerdefinierte Metriken für eine bestimmte Ereignisquelle bereitstellen. Bereitstellungen und StatefulSets sind die gängigste Methode zum Skalieren von Workloads mit KEDA. Sie können auch benutzerdefinierte Ressourcen skalieren, die die /scale-Unterressource implementieren. Sie können die Kubernetes-Bereitstellungen oder StatefulSets definieren, die von KEDA basierend auf einem Skalierungstrigger skaliert werden sollen. KEDA überwacht diese Dienste und skaliert sie automatisch basierend auf den auftretenden Ereignissen auf oder ab.
Im Hintergrund überwacht KEDA die Ereignisquelle und leitet diese Daten zu Kubernetes und HPA weiter, um eine schnelle Ressourcenskalierung zu ermöglichen. Jedes Replikat einer Ressource ruft aktiv Elemente per Pull aus der Ereignisquelle ab. Mit KEDA und Deployments/StatefulSets können Sie basierend auf Ereignissen skalieren und gleichzeitig eine umfassende Verbindungs- und Verarbeitungssemantik mit der Ereignisquelle beibehalten (z. B. geordnete Verarbeitung, Wiederholungen, Verschieben in die Warteschlange für unzustellbare Nachrichten oder Prüfpunktausführung).
Spezifikation für Skalierungsobjekte
apiVersion: keda.sh/v1alpha1
kind: ScaledObject
metadata:
name: {scaled-object-name}
spec:
scaleTargetRef:
apiVersion: {api-version-of-target-resource} # Optional. Default: apps/v1
kind: {kind-of-target-resource} # Optional. Default: Deployment
name: {name-of-target-resource} # Mandatory. Must be in the same namespace as the ScaledObject
envSourceContainerName: {container-name} # Optional. Default: .spec.template.spec.containers[0]
pollingInterval: 30 # Optional. Default: 30 seconds
cooldownPeriod: 300 # Optional. Default: 300 seconds
minReplicaCount: 0 # Optional. Default: 0
maxReplicaCount: 100 # Optional. Default: 100
advanced: # Optional. Section to specify advanced options
restoreToOriginalReplicaCount: true/false # Optional. Default: false
horizontalPodAutoscalerConfig: # Optional. Section to specify HPA related options
behavior: # Optional. Use to modify HPA's scaling behavior
scaleDown:
stabilizationWindowSeconds: 300
policies:
- type: Percent
value: 100
periodSeconds: 15
triggers:
# {list of triggers to activate scaling of the target resource}
Spezifikation für Skalierungsaufträge
Alternativ zur Skalierung von ereignisgesteuertem Code als Bereitstellung können Sie Ihren Code auch als Kubernetes-Auftrag ausführen und skalieren. Der Hauptgrund für die Berücksichtigung dieser Option ist die Verarbeitung von zeitintensiven Ausführungen. Anstatt mehrere Ereignisse innerhalb einer Bereitstellung zu verarbeiten, wird für jedes erkannte Ereignis ein eigener Kubernetes-Auftrag geplant. Mit diesem Ansatz können Sie jedes Ereignis isoliert verarbeiten und die Anzahl gleichzeitiger Ausführungen basierend auf der Anzahl der Ereignisse in der Warteschlange skalieren.
apiVersion: keda.sh/v1alpha1
kind: ScaledJob
metadata:
name: {scaled-job-name}
spec:
jobTargetRef:
parallelism: 1 # [max number of desired pods](https://kubernetes.io/docs/concepts/workloads/controllers/jobs-run-to-completion/#controlling-parallelism)
completions: 1 # [desired number of successfully finished pods](https://kubernetes.io/docs/concepts/workloads/controllers/jobs-run-to-completion/#controlling-parallelism)
activeDeadlineSeconds: 600 # Specifies the duration in seconds relative to the startTime that the job may be active before the system tries to terminate it; value must be positive integer
backoffLimit: 6 # Specifies the number of retries before marking this job failed. Defaults to 6
template:
# describes the [job template](https://kubernetes.io/docs/concepts/workloads/controllers/jobs-run-to-completion/)
pollingInterval: 30 # Optional. Default: 30 seconds
successfulJobsHistoryLimit: 5 # Optional. Default: 100. How many completed jobs should be kept.
failedJobsHistoryLimit: 5 # Optional. Default: 100. How many failed jobs should be kept.
envSourceContainerName: {container-name} # Optional. Default: .spec.JobTargetRef.template.spec.containers[0]
maxReplicaCount: 100 # Optional. Default: 100
scalingStrategy:
strategy: "custom" # Optional. Default: default. Which Scaling Strategy to use.
customScalingQueueLengthDeduction: 1 # Optional. A parameter to optimize custom ScalingStrategy.
customScalingRunningJobPercentage: "0.5" # Optional. A parameter to optimize custom ScalingStrategy.
triggers:
# {list of triggers to create jobs}