Verwendungsszenarien für temporale Tabellen
Gilt für:![]() SQL Server 2016 (13.x) und höhere Versionen
SQL Server 2016 (13.x) und höhere Versionen ![]() Azure SQL-Datenbank
Azure SQL-Datenbank![]() azure SQL Managed Instance
azure SQL Managed Instance![]() SQL-Datenbank in Microsoft Fabric
SQL-Datenbank in Microsoft Fabric
Temporale Tabellen mit Systemversionsverwaltung sind in Szenarien nützlich, in denen der Verlauf von Datenänderungen nachverfolgt werden muss. Für maßgebliche Produktivitätsvorteile empfehlen wir Ihnen den Einsatz temporaler Tabellen in den folgenden Anwendungsfällen.
Datenüberwachung
Sie können die temporale Systemversionsverwaltung für Tabellen verwenden, in denen wichtige Informationen gespeichert werden, um nachzuverfolgen, was sich wann geändert hat, und um Datenforensik zu einem beliebigen Zeitpunkt durchzuführen.
Temporale Tabellen ermöglichen es Ihnen, Datenüberwachungsszenarios in den frühen Phasen des Entwicklungszyklus zu planen oder vorhandenen Anwendungen oder Lösungen bei Bedarf eine Datenüberwachung hinzuzufügen.
Das folgende Diagramm zeigt eine Employee-Tabelle mit dem Datenbeispiel, einschließlich der Versionen für Zeilen mit aktuellen Daten (blau markiert) und mit Verlaufsdaten (grau markiert).
Der rechte Bereich des Diagramms stellt die Zeilenversionen auf einer Zeitachse dar und die Zeilen, die Sie mit verschiedenen Abfragetypen für die temporale Tabelle mit oder ohne SYSTEM_TIME-Klausel auswählen.

Aktivieren der Systemversionsverwaltung für eine neue Tabelle zur Datenüberwachung
Wenn Sie Informationen angeben, für die eine Datenüberwachung durchgeführt werden soll, erstellen Sie die Datenbanktabellen als temporale Tabellen mit Systemversionsverwaltung. Das folgende Beispiel veranschaulicht ein Szenario mit einer Tabelle namens Employee in der hypothetischem HR-Datenbank:
CREATE TABLE Employee (
[EmployeeID] INT NOT NULL PRIMARY KEY CLUSTERED,
[Name] NVARCHAR(100) NOT NULL,
[Position] VARCHAR(100) NOT NULL,
[Department] VARCHAR(100) NOT NULL,
[Address] NVARCHAR(1024) NOT NULL,
[AnnualSalary] DECIMAL(10, 2) NOT NULL,
[ValidFrom] DATETIME2(2) GENERATED ALWAYS AS ROW START,
[ValidTo] DATETIME2(2) GENERATED ALWAYS AS ROW END,
PERIOD FOR SYSTEM_TIME(ValidFrom, ValidTo)
)
WITH (SYSTEM_VERSIONING = ON (HISTORY_TABLE = dbo.EmployeeHistory));
Verschiedene Optionen zum Erstellen von temporalen Tabellen mit Systemversionsverwaltung werden unter Erstellen einer temporalen Tabelle mit Systemversionsverwaltung beschrieben.
Aktivieren der Systemversionsverwaltung für eine vorhandene Tabelle zur Datenüberwachung
Wenn Sie in vorhandenen Datenbanken eine Datenüberwachung durchführen müssen, verwenden Sie ALTER TABLE, um nicht temporale Tabellen mit der Systemversionsverwaltung zu erweitern. Fügen Sie zum Vermeiden von Breaking Changes in Ihrer Anwendung wie unter HIDDEN beschrieben Zeitraumspalten als hinzu.
Das folgende Beispiel veranschaulicht die Aktivierung der Systemversionsverwaltung für eine vorhandene Employee-Tabelle in einer hypothetischen Personaldatenbank. Die Systemversionsverwaltung wird in der Employee-Tabelle in zwei Schritten aktiviert. Zuerst werden neue Zeitraumspalten als HIDDEN hinzugefügt. Anschließend wird die Standardverlaufstabelle erstellt.
ALTER TABLE Employee ADD
ValidFrom DATETIME2(2) GENERATED ALWAYS AS ROW START HIDDEN
CONSTRAINT DF_ValidFrom DEFAULT DATEADD (SECOND, -1, SYSUTCDATETIME()),
ValidTo DATETIME2(2) GENERATED ALWAYS AS ROW END HIDDEN
CONSTRAINT DF_ValidTo DEFAULT '9999.12.31 23:59:59.99',
PERIOD FOR SYSTEM_TIME(ValidFrom, ValidTo);
ALTER TABLE Employee
SET (SYSTEM_VERSIONING = ON (HISTORY_TABLE = dbo.Employee_History));
Wichtig
Die Genauigkeit des Datentyps datetime2 muss in der Quelltabelle gleich sein wie in der Verlaufstabelle mit Systemversionsverwaltung.
Nachdem Sie das vorangehende Skript ausgeführt haben, werden alle Datenänderungen transparent in der Verlaufstabelle gesammelt. In einem typischen Szenario für die Datenüberwachung fragen Sie alle Datenänderungen ab, die innerhalb eines gewünschten Zeitraums auf eine einzelne Zeile angewendet wurden. Die Standardverlaufstabelle wird mit einem gruppiertem B-Struktur-Zeilenspeicher erstellt, um diesen Anwendungsfall effizient zu bearbeiten.
Hinweis
In der Dokumentation wird der Begriff „B-Struktur“ im Allgemeinen in Bezug auf Indizes verwendet. In Zeilenspeicherindizes implementiert die Datenbank-Engine eine B+-Struktur. Dies gilt nicht für Columnstore-Indizes oder In-Memory-Datenspeicher. Weitere Informationen finden Sie im Leitfaden zur Architektur und zum Entwerfen von SQL Server- und Azure SQL-Indizes.
Durchführen einer Datenanalyse
Nachdem Sie die Systemversionsverwaltung mithilfe einem der vorangehenden Ansätze aktiviert haben, ist die Datenüberwachung nur eine Abfrage entfernt. Die folgende Abfrage sucht nach Zeilenversionen für Datensätze in der Employee-Tabelle mit EmployeeID = 1000, die zwischen dem 1. Januar 2021 und dem 1. Januar 2022 (einschließlich der oberen Grenze) mindestens eine Zeit lang aktiv waren:
SELECT * FROM Employee
FOR SYSTEM_TIME BETWEEN '2021-01-01 00:00:00.0000000'
AND '2022-01-01 00:00:00.0000000'
WHERE EmployeeID = 1000
ORDER BY ValidFrom;
Ersetzen Sie FOR SYSTEM_TIME BETWEEN...AND durch FOR SYSTEM_TIME ALL, um den gesamten Verlauf der Datenänderungen für diesen bestimmten Mitarbeiter zu analysieren:
SELECT * FROM Employee
FOR SYSTEM_TIME ALL
WHERE EmployeeID = 1000
ORDER BY ValidFrom;
Verwenden Sie CONTAINED IN, um nach Zeilenversionen zu suchen, die nur innerhalb eines bestimmten Zeitraums aktiv waren (und nicht außerhalb). Diese Abfrage ist effizient, da sie nur die Verlaufstabelle abfragt:
SELECT * FROM Employee
FOR SYSTEM_TIME CONTAINED IN (
'2021-01-01 00:00:00.0000000', '2022-01-01 00:00:00.0000000'
)
WHERE EmployeeID = 1000
ORDER BY ValidFrom;
In einigen Überwachungsszenarien möchten Sie vielleicht herausfinden, wie die gesamte Tabelle zu einem beliebigen Punkt in der Vergangenheit aussah:
SELECT * FROM Employee
FOR SYSTEM_TIME AS OF '2021-01-01 00:00:00.0000000';
Temporale Tabellen mit Systemversionsverwaltung speichern Werte für Zeitraumspalten in der UTC-Zeitzone, es ist jedoch vorteilhafter, beim Filtern von Daten und Anzeigen von Ergebnissen mit Ihrer lokalen Zeitzone zu arbeiten. Im folgenden Codebeispiel wird gezeigt, wie Sie Filterbedingungen anwenden, die in der lokalen Zeitzone angegeben wurden und dann mit AT TIME ZONE in UTC konvertiert wurden. Dies wurde in SQL Server 2016 (13.x) eingeführt:
/* Add offset of the local time zone to current time*/
DECLARE @asOf DATETIMEOFFSET = GETDATE() AT TIME ZONE 'Pacific Standard Time';
/* Convert AS OF filter to UTC*/
SET @asOf = DATEADD(HOUR, - 9, @asOf) AT TIME ZONE 'UTC';
SELECT EmployeeID,
[Name],
Position,
Department,
[Address],
[AnnualSalary],
ValidFrom AT TIME ZONE 'Pacific Standard Time' AS ValidFromPT,
ValidTo AT TIME ZONE 'Pacific Standard Time' AS ValidToPT
FROM Employee
FOR SYSTEM_TIME AS OF @asOf
WHERE EmployeeId = 1000;
AT TIME ZONE ist auch in allen anderen Szenarios hilfreich, in denen Tabellen mit Systemversionsverwaltung verwendet werden.
Filterbedingungen, die mit FOR SYSTEM_TIME in temporalen Klausen angegeben sind, sind SARG-fähig. SARG steht für search argument (Suchargument), und SARG-fähig bedeutet, dass SQL Server anhand des zugrunde liegenden gruppierten Index eine Suche anstelle eines Scanvorgangs durchführen kann. Weitere Informationen finden Sie unter Leitfaden zur Architektur und zum Entwurf von SQL Server-Indizes.
Wenn Sie die Verlaufstabelle direkt abfragen, stellen Sie sicher, dass die Filterbedingung ebenfalls SARG-fähig ist, indem Sie Filter im Format <period column> { < | > | =, ... } date_condition AT TIME ZONE 'UTC' angeben.
Wenn Sie AT TIME ZONE auf Spalten für Zeiträume anwenden, führt SQL Server eine Tabellen- oder Indexüberprüfung durch, die sehr leistungsintensiv sein kann. Vermeiden Sie folgenden Bedingungstyp in Ihren Abfragen:
<period column> AT TIME ZONE '<your time zone>' > {< | > | =, ...} date_condition.
Weitere Informationen finden Sie unter Abfragen von Daten in einer temporalen Tabelle mit Systemversionsverwaltung.
Zeitpunktanalyse (Zeitreise)
Zeitreisenszenarien konzentrieren sich nicht auf Änderungen an einzelnen Datensätzen, sondern zeigen, wie sich ganze Datensätze im Laufe der Zeit ändern. Zeitreisen umfassen gelegentlich mehrere verknüpfte temporale Tabellen, die sich alle in unterschiedlichem Tempo ändern, die Sie analysieren möchten:
- Trends für wichtige Indikatoren in den Verlaufsdaten und aktuellen Daten
- Exakte Momentaufnahme der gesamten Daten „ab“ (as of) einem beliebigen Zeitpunkt in der Vergangenheit (gestern, vor einem Monat usw.)
- Unterschiede zwischen zwei interessanten Zeitpunkten (z. B. vor einem Monat im Vergleich zu vor drei Monaten)
Es gibt viele reale Szenarios, in denen eine Zeitreiseanalyse erforderlich ist. Um dieses Verwendungsszenario zu veranschaulichen, sehen Sie sich OLTP mit automatisch generiertem Verlauf an.
OLTP mit automatisch generiertem Datenverlauf
In Transaktionsverarbeitungssystemen können Sie die Änderung von wichtigen Metriken im Verlauf der Zeit zu analysieren. Die Analyse des Verlaufs sollte idealerweise nicht die Leistung der OLTP-Anwendung beeinträchtigen, bei der der Zugriff auf den aktuellen Zustand der Daten mit minimaler Wartezeit und Datensperre erfolgen muss. Sie können temporale Tabellen mit Systemversionsverwaltung verwenden, um den vollständigen Änderungsverlauf für eine spätere Analyse getrennt von den aktuellen Daten transparent behalten können, und das bei minimalen Auswirkungen auf die OLTP-Hauptarbeitsauslastung.
Für hohe Transaktionsverarbeitungs-Workloads in SQL Server und Azure SQL Managed Instance empfehlen wir, systemversionierte zeitliche Tabellen mit speicheroptimierten Tabellenzu verwenden, mit denen Sie aktuelle Daten im Arbeitsspeicher und den vollständigen Verlauf von Änderungen auf dem Datenträger auf kostengünstige Weise speichern können.
Für die Verlaufstabelle empfehlen wir aus den folgenden Gründen die Verwendung eines gruppierten Columnstore-Indexes:
Die typische Trendanalyse profitiert von der Abfrageleistung, die von einem gruppierten Columnstore-Index bereitgestellt wird.
Die Datenleerungsaufgabe mit speicheroptimierten Tabellen funktioniert am besten bei hoher OLTP-Arbeitsauslastung, wenn die Verlaufstabelle über einen gruppierten Columnstore-Index verfügt.
Ein gruppierter Columnstore-Index bietet eine hervorragende Komprimierung, besonders in Szenarien, in denen nicht alle Spalten gleichzeitig geändert werden.
Bei temporalen Tabellen mit In-Memory OLTP ist es weniger notwendig, den gesamten Dataset im Arbeitsspeicher zu behalten. Zudem haben Sie die Möglichkeit, mühelos zwischen heißen und kalten Daten zu unterscheiden.
Beispiele für reale Szenarien, die gut in diese Kategorie passen, sind u. a. die Bestandsverwaltung oder der Devisenhandel.
Das folgende Diagramm zeigt ein vereinfachtes Datenmodell für die Bestandsverwaltung:

Das folgende Codebeispiel erstellt ProductInventory als eine temporale In-Memory-Tabelle mit Systemversionsverwaltung und mit einem gruppierten Columnstore-Index für die Verlaufstabelle (der tatsächlich den standardmäßig erstellten Zeilenspeicherindex ersetzt):
Hinweis
Stellen Sie sicher, dass die Datenbank die Erstellung von speicheroptimierten Tabellen ermöglicht. Weitere Informationen finden Sie unter Erstellen einer speicheroptimierten Tabelle und einer systemintern kompilierten gespeicherten Prozedur.
USE TemporalProductInventory;
GO
BEGIN
--If table is system-versioned, SYSTEM_VERSIONING must be set to OFF first
IF ((SELECT temporal_type
FROM SYS.TABLES
WHERE object_id = OBJECT_ID('dbo.ProductInventory', 'U')) = 2)
BEGIN
ALTER TABLE [dbo].[ProductInventory]
SET (SYSTEM_VERSIONING = OFF);
END
DROP TABLE IF EXISTS [dbo].[ProductInventory];
DROP TABLE IF EXISTS [dbo].[ProductInventoryHistory];
END
GO
CREATE TABLE [dbo].[ProductInventory] (
ProductId INT NOT NULL,
LocationID INT NOT NULL,
Quantity INT NOT NULL CHECK (Quantity >= 0),
ValidFrom DATETIME2 GENERATED ALWAYS AS ROW START NOT NULL,
ValidTo DATETIME2 GENERATED ALWAYS AS ROW END NOT NULL,
PERIOD FOR SYSTEM_TIME(ValidFrom, ValidTo),
--Primary key definition
CONSTRAINT PK_ProductInventory PRIMARY KEY NONCLUSTERED (
ProductId,
LocationId
)
)
WITH (
MEMORY_OPTIMIZED = ON,
SYSTEM_VERSIONING = ON (
HISTORY_TABLE = [dbo].[ProductInventoryHistory],
DATA_CONSISTENCY_CHECK = ON
)
);
CREATE CLUSTERED COLUMNSTORE INDEX IX_ProductInventoryHistory
ON [ProductInventoryHistory] WITH (DROP_EXISTING = ON);
Für das vorangehende Modell kann die Prozedur zum Verwalten des Bestands folgendermaßen aussehen:
CREATE PROCEDURE [dbo].[spUpdateInventory]
@productId INT,
@locationId INT,
@quantityIncrement INT
WITH NATIVE_COMPILATION, SCHEMABINDING
AS
BEGIN ATOMIC
WITH (
TRANSACTION ISOLATION LEVEL = SNAPSHOT,
LANGUAGE = N'English'
)
UPDATE dbo.ProductInventory
SET Quantity = Quantity + @quantityIncrement
WHERE ProductId = @productId
AND LocationId = @locationId
-- If zero rows were updated then this is an insert
-- of the new product for a given location
IF @@rowcount = 0
BEGIN
IF @quantityIncrement < 0
SET @quantityIncrement = 0
INSERT INTO [dbo].[ProductInventory] (
[ProductId], [LocationID], [Quantity]
)
VALUES (@productId, @locationId, @quantityIncrement)
END
END;
Die gespeicherte Prozedur spUpdateInventory fügt entweder ein neues Produkt im Bestand ein oder aktualisiert die Produktmenge für den jeweiligen Standort. Die Geschäftslogik ist einfach und konzentriert sich auf die Verwaltung des aktuellen Zustands, der dauerhaft akkurat ist, indem der Wert im Quantity-Feld durch eine Tabellenaktualisierung erhöht/verringert wird, während Tabellen mit Systemversionsverwaltung den Daten wie im folgenden Diagramm dargestellt Verlaufsdimensionen transparent hinzufügen.

Die Abfrage des aktuellen Zustands kann effizient aus dem nativ kompilierten Modul durchgeführt werden:
CREATE PROCEDURE [dbo].[spQueryInventoryLatestState]
WITH NATIVE_COMPILATION, SCHEMABINDING
AS
BEGIN ATOMIC
WITH (
TRANSACTION ISOLATION LEVEL = SNAPSHOT,
LANGUAGE = N'English'
)
SELECT ProductId, LocationID, Quantity, ValidFrom
FROM dbo.ProductInventory
ORDER BY ProductId, LocationId
END;
GO
EXEC [dbo].[spQueryInventoryLatestState];
Die Analyse von Datenänderungen im Verlauf der Zeit wird mit der FOR SYSTEM_TIME ALL-Klausel zum Kinderspiel, wie im folgenden Beispiel gezeigt:
DROP VIEW IF EXISTS vw_GetProductInventoryHistory;
GO
CREATE VIEW vw_GetProductInventoryHistory
AS
SELECT ProductId,
LocationId,
Quantity,
ValidFrom,
ValidTo
FROM [dbo].[ProductInventory]
FOR SYSTEM_TIME ALL;
GO
SELECT * FROM vw_GetProductInventoryHistory
WHERE ProductId = 2;
Das folgende Diagramm zeigt den Datenverlauf für ein Produkt, der problemlos durch den Import der vorangehenden Ansicht in Power Query, Power BI oder ähnlichen Business-Intelligence-Tools gerendert werden kann:

Temporale Tabellen können in diesem Szenario verwendet werden, um andere Arten von Zeitreiseanalysen durchzuführen, z. B. Rekonstruktion des Bestandszustands AS OF einem bestimmten Zeitpunkt in der Vergangenheit oder Vergleich von Momentaufnahmen, die sich auf verschiedene Momente beziehen.
Für dieses Verwendungsszenario können Sie auch die Produkt- und Standorttabellen zu temporalen Tabellen erweitern, sodass Sie den Änderungsverlauf für UnitPrice und NumberOfEmployee später analysieren können.
ALTER TABLE Product ADD
ValidFrom DATETIME2 GENERATED ALWAYS AS ROW START HIDDEN
CONSTRAINT DF_ValidFrom DEFAULT DATEADD (SECOND, -1, SYSUTCDATETIME()),
ValidTo DATETIME2 GENERATED ALWAYS AS ROW END HIDDEN
CONSTRAINT DF_ValidTo DEFAULT '9999.12.31 23:59:59.99',
PERIOD FOR SYSTEM_TIME(ValidFrom, ValidTo);
ALTER TABLE Product
SET (SYSTEM_VERSIONING = ON (HISTORY_TABLE = dbo.ProductHistory));
ALTER TABLE [Location] ADD
ValidFrom DATETIME2 GENERATED ALWAYS AS ROW START HIDDEN
CONSTRAINT DFValidFrom DEFAULT DATEADD (SECOND, -1, SYSUTCDATETIME()),
ValidTo DATETIME2 GENERATED ALWAYS AS ROW END HIDDEN
CONSTRAINT DFValidTo DEFAULT '9999.12.31 23:59:59.99',
PERIOD FOR SYSTEM_TIME(ValidFrom, ValidTo);
ALTER TABLE [Location]
SET (SYSTEM_VERSIONING = ON (HISTORY_TABLE = dbo.LocationHistory));
Da das Datenmodell jetzt mehrere temporale Tabellen umfasst, besteht die bewährte Methode für die AS OF-Analyse darin, eine Ansicht zu erstellen, die die erforderlichen Daten aus den verknüpften Tabellen extrahiert, und FOR SYSTEM_TIME AS OF auf die Ansicht anzuwenden, da dies die Rekonstruktion des Zustands des gesamten Datenmodells maßgeblich vereinfacht:
DROP VIEW IF EXISTS vw_ProductInventoryDetails;
GO
CREATE VIEW vw_ProductInventoryDetails
AS
SELECT PrInv.ProductId,
PrInv.LocationId,
P.ProductName,
L.LocationName,
PrInv.Quantity,
P.UnitPrice,
L.NumberOfEmployees,
P.ValidFrom AS ProductStartTime,
P.ValidTo AS ProductEndTime,
L.ValidFrom AS LocationStartTime,
L.ValidTo AS LocationEndTime,
PrInv.ValidFrom AS InventoryStartTime,
PrInv.ValidTo AS InventoryEndTime
FROM dbo.ProductInventory AS PrInv
INNER JOIN dbo.Product AS P
ON PrInv.ProductId = P.ProductID
INNER JOIN dbo.Location AS L
ON PrInv.LocationId = L.LocationID;
GO
SELECT * FROM vw_ProductInventoryDetails
FOR SYSTEM_TIME AS OF '2022-01-01';
Der folgende Screenshot zeigt den Ausführungsplan, der für die SELECT-Abfrage generiert wird. Dies veranschaulicht, dass die Datenbank-Engine die gesamte Komplexität im Umgang mit temporalen Beziehungen übernimmt:

Verwenden Sie den folgenden Code, um den Status des Produktbestands zwischen zwei Zeitpunkten (vor einem Tag und vor einem Monat) zu vergleichen:
DECLARE @dayAgo DATETIME2 = DATEADD (DAY, -1, SYSUTCDATETIME());
DECLARE @monthAgo DATETIME2 = DATEADD (MONTH, -1, SYSUTCDATETIME());
SELECT inventoryDayAgo.ProductId,
inventoryDayAgo.ProductName,
inventoryDayAgo.LocationName,
inventoryDayAgo.Quantity AS QuantityDayAgo,
inventoryMonthAgo.Quantity AS QuantityMonthAgo,
inventoryDayAgo.UnitPrice AS UnitPriceDayAgo,
inventoryMonthAgo.UnitPrice AS UnitPriceMonthAgo
FROM vw_ProductInventoryDetails
FOR SYSTEM_TIME AS OF @dayAgo AS inventoryDayAgo
INNER JOIN vw_ProductInventoryDetails
FOR SYSTEM_TIME AS OF @monthAgo AS inventoryMonthAgo
ON inventoryDayAgo.ProductId = inventoryMonthAgo.ProductId
AND inventoryDayAgo.LocationId = inventoryMonthAgo.LocationID;
Anomalieerkennung
Bei der Erkennung von Anomalien (oder Ausreißererkennung) werden Elemente identifiziert, die einem erwarteten Muster oder anderen Elementen in einem Dataset nicht entsprechen. Sie können temporale Tabellen mit Systemversionsverwaltung verwenden, um Anomalien zu erkennen, die in regelmäßigen Abständen oder unregelmäßig auftreten, da Sie mit temporalen Abfragen schnell bestimmte Muster auffinden können. Die Form der Anomalie hängt von der Art von Daten ab, die Sie sammeln, sowie von Ihrer Geschäftslogik.
Das folgende Beispiel zeigt die vereinfachte Logik zum Erkennen von „Spitzen“ in Verkaufszahlen. Angenommen, Sie arbeiten mit einer temporalen Tabelle, in der der Verlauf von erworbenen Produkten erfasst wird:
CREATE TABLE [dbo].[Product] (
[ProdID] [int] NOT NULL PRIMARY KEY CLUSTERED,
[ProductName] [varchar](100) NOT NULL,
[DailySales] INT NOT NULL,
[ValidFrom] [datetime2] GENERATED ALWAYS AS ROW START NOT NULL,
[ValidTo] [datetime2] GENERATED ALWAYS AS ROW END NOT NULL,
PERIOD FOR SYSTEM_TIME([ValidFrom], [ValidTo])
)
WITH (
SYSTEM_VERSIONING = ON (
HISTORY_TABLE = [dbo].[ProductHistory],
DATA_CONSISTENCY_CHECK = ON
)
);
Das folgende Diagramm zeigt die Verkaufszahlen im Verlauf der Zeit:

Angenommen die Anzahl der erworbenen Produkte weist an typischen Tagen kleine Abweichungen auf, so identifiziert die folgende Abfrage Singleton-Ausreißer – Proben, die sich im Vergleich zu ihren unmittelbaren Nachbarn erheblich unterscheiden (2x), während umgebende Proben nicht maßgeblich abweichen (weniger als 20 %):
WITH CTE (
ProdId,
PrevValue,
CurrentValue,
NextValue,
ValidFrom,
ValidTo
)
AS (
SELECT ProdId,
LAG(DailySales, 1, 1) OVER (PARTITION BY ProdId ORDER BY ValidFrom) AS PrevValue,
DailySales,
LEAD(DailySales, 1, 1) OVER (PARTITION BY ProdId ORDER BY ValidFrom) AS NextValue,
ValidFrom,
ValidTo
FROM Product
FOR SYSTEM_TIME ALL
)
SELECT ProdId,
PrevValue,
CurrentValue,
NextValue,
ValidFrom,
ValidTo,
ABS(PrevValue - NextValue) / convert(FLOAT, (
CASE
WHEN NextValue > PrevValue THEN PrevValue
ELSE NextValue
END)) AS PrevToNextDiff,
ABS(CurrentValue - PrevValue) / convert(FLOAT, (
CASE
WHEN CurrentValue > PrevValue THEN PrevValue
ELSE CurrentValue
END)) AS CurrentToPrevDiff,
ABS(CurrentValue - NextValue) / convert(FLOAT, (
CASE
WHEN CurrentValue > NextValue THEN NextValue
ELSE CurrentValue
END)) AS CurrentToNextDiff
FROM CTE
WHERE ABS(PrevValue - NextValue) / (
CASE
WHEN NextValue > PrevValue THEN PrevValue
ELSE NextValue
END) < 0.2
AND ABS(CurrentValue - PrevValue) / (
CASE
WHEN CurrentValue > PrevValue THEN PrevValue
ELSE CurrentValue
END) > 2
AND ABS(CurrentValue - NextValue) / (
CASE
WHEN CurrentValue > NextValue THEN NextValue
ELSE CurrentValue
END) > 2;
Hinweis
Dieses Beispiel wurde absichtlich vereinfacht. In den Produktionsszenarien verwenden Sie wahrscheinlich statistische Methoden, um die Proben zu ermitteln, die nicht dem allgemeinen Muster folgen.
Langsam veränderliche Dimensionen
Dimensionen beim Data Warehousing enthalten i. d. R. relativ statische Daten zu Entitäten wie z. B. geografische Standorte, Kunden oder Produkte. Einige Szenarien erfordern jedoch ebenfalls das Nachverfolgen von Datenänderungen in Dimensionstabellen. Da Änderungen an Dimensionen sehr viel seltener, auf unvorhersehbare Weise und außerhalb des regulären Zeitplans für Faktentabellen auftreten, werden diese Typen von Dimensionstabellen als langsam veränderliche Dimensionen (SCD) bezeichnet.
Es gibt verschiedene Kategorien von langsam veränderlichen Dimensionen basierend darauf, wie der Änderungsverlauf beibehalten wird:
| Dimensionstyp | Details |
|---|---|
| Typ 0 | Verlauf wird nicht beibehalten. Dimensionsattribute spiegeln die ursprünglichen Werte wider. |
| Typ 1 | Dimensionsattribute reflektieren die aktuellen Werte (die vorherigen Werte werden überschrieben). |
| Typ 2 | Jede Version des Dimensionselements wird mit einer separaten Zeile in der Tabelle dargestellt, in der Regel mit Spalten, die die Gültigkeitsdauer angeben. |
| Typ 3 | Der Verlauf wird für ausgewählte Attribute mit zusätzlichen Spalten in der gleichen Zeile eingeschränkt aufbewahrt |
| Typ 4 | Der Verlauf wird in der separaten Tabelle aufbewahrt, während die Originaltabelle die neuesten (aktuellsten) Dimensionselementversionen beibehält. |
Wenn Sie sich für eine SCD-Strategie entscheiden, so ist die ETL-Ebene (Extrahieren-Transformieren-Laden) dafür verantwortlich, die Dimensionstabellen korrekt beizubehalten. Dafür ist in der Regel komplexer Code und eine umfangreichere Wartung erforderlich.
Temporale Tabellen mit Systemversionsverwaltung können verwendet werden, um die Komplexität des Codes maßgeblich zu verringern, da der Verlauf der Daten automatisch beibehalten wird. Angesichts der Implementierung mithilfe von zwei Tabellen, entsprechen temporale Tabellen am ehesten dem Typ 4 SCD. Da temporale Abfragen es Ihnen jedoch nur ermöglichen, auf die aktuelle Tabelle zu verweisen, können Sie den Einsatz von temporalen Tabellen auch in Umgebungen in Betracht ziehen, in denen Sie Typ 2 SCD verwenden möchten.
Erstellen Sie einfach eine neue Dimension, oder ändern Sie eine vorhandene in eine temporale Tabelle mit Systemversionsverwaltung, um Ihre normale Dimension in SCD zu konvertieren. Wenn Ihre vorhandene Dimensionstabelle Verlaufsdaten enthält, erstellen Sie eine separate Tabelle und verschieben Sie Verlaufsdaten dorthin. Behalten Sie die aktuellen (tatsächlichen) Dimensionsversionen in der ursprünglichen Dimensionstabelle. Verwenden Sie dann die ALTER TABLE-Syntax, um die Dimensionstabelle in eine temporale Tabelle mit Systemversionsverwaltung mit einer vordefinierten Verlaufstabelle zu konvertieren.
Das folgende Beispiel veranschaulicht den Prozess. Dabei wird davon ausgegangen, dass die DimLocation-Dimensionstabelle bereits über ValidFrom und ValidTo verfügt, da datetime2-Spalten keine NULL-Werte zulassen und vom ETL-Prozess aufgefüllt werden:
/* Move "closed" row versions into newly created history table*/
SELECT * INTO DimLocationHistory
FROM DimLocation
WHERE ValidTo < '9999-12-31 23:59:59.99';
GO
/* Create clustered columnstore index which is a very good choice in DW scenarios*/
CREATE CLUSTERED COLUMNSTORE INDEX IX_DimLocationHistory ON DimLocationHistory;
/* Delete previous versions from DimLocation which will become current table in temporal-system-versioning configuration*/
DELETE FROM DimLocation
WHERE ValidTo < '9999-12-31 23:59:59.99';
/* Add period definition*/
ALTER TABLE DimLocation
ADD PERIOD FOR SYSTEM_TIME(ValidFrom, ValidTo);
/* Enable system-versioning and bind history table to the DimLocation*/
ALTER TABLE DimLocation
SET (SYSTEM_VERSIONING = ON (HISTORY_TABLE = dbo.DimLocationHistory));
Nach dem Erstellen ist während des Data Warehouse-Prozesses kein zusätzlicher Code erforderlich, um SCD zu verwalten.
Die folgende Abbildung zeigt, wie Sie temporale Tabellen in einem einfachen Szenario mit zwei SCDs (DimLocation und DimProduct) und einer Faktentabelle verwenden können.

Um die vorangehenden SCDs in Berichten verwenden zu können, müssen Sie die Abfragen effektiv anpassen. Sie können beispielsweise den Gesamtumsatz und die durchschnittliche Anzahl der verkauften Produkte pro Kopf in den letzten sechs Monaten berechnen. Beide Metriken erfordern die Korrelation von Daten aus der Faktentabelle und den Dimensionen, deren für die Analyse wichtige Attribute möglicherweise geändert wurden (DimLocation.NumOfCustomers, DimProduct.UnitPrice). Mit der folgenden Abfrage werden die erforderlichen Metriken ordnungsgemäß berechnet:
DECLARE @now DATETIME2 = SYSUTCDATETIME();
DECLARE @sixMonthsAgo DATETIME2;
SET @sixMonthsAgo = DATEADD(month, - 12, SYSUTCDATETIME());
SELECT DimProduct_History.ProductId,
DimLocation_History.LocationId,
SUM(F.Quantity * DimProduct_History.UnitPrice) AS TotalAmount,
AVG(F.Quantity / DimLocation_History.NumOfCustomers) AS AverageProductsPerCapita
FROM FactProductSales F
/* find corresponding record in SCD history in last 6 months, based on matching fact */
INNER JOIN DimLocation
FOR SYSTEM_TIME BETWEEN @sixMonthsAgo AND @now AS DimLocation_History
ON DimLocation_History.LocationId = F.LocationId
AND F.FactDate BETWEEN DimLocation_History.ValidFrom AND DimLocation_History.ValidTo
/* find corresponding record in SCD history in last 6 months, based on matching fact */
INNER JOIN DimProduct
FOR SYSTEM_TIME BETWEEN @sixMonthsAgo AND @now AS DimProduct_History
ON DimProduct_History.ProductId = F.ProductId
AND F.FactDate BETWEEN DimProduct_History.ValidFrom AND DimProduct_History.ValidTo
WHERE F.FactDate BETWEEN @sixMonthsAgo AND @now
GROUP BY DimProduct_History.ProductId, DimLocation_History.LocationId;
Überlegungen
Die Verwendung von temporalen Tabellen mit Systemversionsverwaltung für SCD ist dann akzeptabel, wenn die Gültigkeitsdauer anhand der Datenbanktransaktionszeit berechnet wird und zu Ihrer Geschäftslogik passt. Wenn Sie Daten mit erheblicher Verzögerung laden, ist die Transaktionszeit möglicherweise nicht akzeptabel.
Standardmäßig ermöglichen temporale Tabellen mit Systemversionsverwaltung nicht die Änderung von Verlaufsdaten nach dem Laden (Sie können den Verlauf ändern, nachdem Sie SYSTEM_VERSIONING auf OFF setzen). Dies kann möglicherweise in Fällen eingeschränkt sein, bei denen die Verlaufsdaten regelmäßig geändert werden.
Temporale Tabellen mit Systemversionsverwaltung generieren eine Zeilenversion bei jeder Spaltenänderung. Wenn Sie neue Versionen auf bestimmte Spaltenänderungen unterdrücken möchten, müssen Sie eine solche Einschränkung in die ETL-Logik integrieren.
Wenn Sie eine erhebliche Anzahl von Zeilen mit Verlaufsdaten in SCD-Tabellen erwarten, ziehen Sie den Einsatz eines gruppierten Columnstore-Indexes als Hauptspeicheroption für die Verlaufstabelle in Betracht. Die Verwendung eines Columnstore-Index reduziert den Speicherbedarf der Verlaufstabelle und beschleunigt Ihre analytischen Abfragen.
Reparieren von Datenbeschädigungen auf Zeilenebene
Sie können Verlaufsdaten in temporalen Tabellen mit Systemversionsverwaltung verwenden, um schnell einzelne Zeilen anhand eines der zuvor erfassten Zustände zu reparieren. Diese Eigenschaft von temporalen Tabellen ist nützlich, wenn Sie die betroffenen Zeilen ermitteln können und/oder den Zeitpunkt der unerwünschten Datenänderung kennen. Mit diesem Wissen können Sie die Reparatur effizient durchführen, ohne mit Sicherungen zu arbeiten.
Dieser Ansatz hat mehrere Vorteile:
Sie können den Umfang der Reparatur genau steuern. Nicht betroffene Datensätze müssen den aktuellen Zustand beibehalten, wobei es sich oftmals um eine kritische Voraussetzung handelt.
Der Vorgang ist effizient, und die Datenbank bleibt für alle Arbeitsauslastungen online, bei denen die Daten verwendet werden.
Der Reparaturvorgang selbst ist versionsspezifisch. Sie verfügen über einen Überwachungspfad für den Reparaturvorgang selbst, damit Sie später bei Bedarf analysieren können, was passiert ist.
Der Reparaturvorgang kann relativ leicht automatisiert werden. Im nächsten Codebeispiel wird eine gespeicherte Prozedur gezeigt, die eine Datenreparatur für die Tabelle Employee durchführt, die in einem Datenüberwachungsszenario verwendet wird.
DROP PROCEDURE IF EXISTS sp_RepairEmployeeRecord;
GO
CREATE PROCEDURE sp_RepairEmployeeRecord
@EmployeeID INT,
@versionNumber INT = 1
AS
WITH History
AS (
/* Order historical rows by their age in DESC order*/
SELECT
ROW_NUMBER() OVER (PARTITION BY EmployeeID
ORDER BY [ValidTo] DESC) AS RN,
*
FROM Employee FOR SYSTEM_TIME ALL
WHERE YEAR(ValidTo) < 9999 AND Employee.EmployeeID = @EmployeeID
)
/* Update current row by using N-th row version from history (default is 1 - i.e. last version) */
UPDATE Employee
SET [Position] = H.[Position],
[Department] = H.Department,
[Address] = H.[Address],
AnnualSalary = H.AnnualSalary
FROM Employee E
INNER JOIN History H ON E.EmployeeID = H.EmployeeID AND RN = @versionNumber
WHERE E.EmployeeID = @EmployeeID;
Diese gespeicherte Prozedur nimmt @EmployeeID und @versionNumber als Eingabeparameter. Dieses Verfahren stellt den Zeilenzustand standardmäßig auf die letzte Version des Verlaufs (@versionNumber = 1) wieder her.
Das folgende Bild zeigt den Zustand der Zeile vor und nach dem Prozeduraufruf. Das rote Rechteck markiert die aktuelle Zeilenversion, die falsch ist; das grüne Rechteck kennzeichnet die richtige Version aus dem Verlauf.

EXEC sp_RepairEmployeeRecord @EmployeeID = 1, @versionNumber = 1;

Diese gespeicherte Reparaturprozedur kann so definiert werden, dass anstelle einer Zeilenversion ein genauer Zeitstempel akzeptiert wird. Die Zeile wird auf eine beliebige Version wiederhergestellt, die zum angegebenen Zeitpunkt aktiv war (d. h. AS OF-Zeitpunkt).
DROP PROCEDURE IF EXISTS sp_RepairEmployeeRecordAsOf;
GO
CREATE PROCEDURE sp_RepairEmployeeRecordAsOf
@EmployeeID INT,
@asOf DATETIME2
AS
/* Update current row to the state that was actual AS OF provided date*/
UPDATE Employee
SET [Position] = History.[Position],
[Department] = History.Department,
[Address] = History.[Address],
AnnualSalary = History.AnnualSalary
FROM Employee AS E
INNER JOIN Employee FOR SYSTEM_TIME AS OF @asOf AS History
ON E.EmployeeID = History.EmployeeID
WHERE E.EmployeeID = @EmployeeID;
Beim gleichen Datenbeispiel veranschaulicht das folgende Bild das Reparaturszenario mit einer Zeitbedingung. Hervorgehoben sind der @asOf-Parameter, die ausgewählte Zeile im Verlauf, die zum angegebenen Zeitpunkt aktiv war, und die neue Zeilenversion in der aktuellen Tabelle nach der Reparatur:

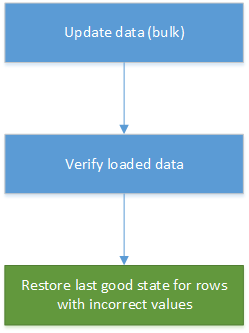
Datenkorrektur kann Teil des automatischen Datenladevorgangs in Data Warehousing- und Berichterstattungssystemen werden. Wenn ein neu aktualisierter Wert nicht korrekt ist, ist die Wiederherstellung der vorherigen Version aus dem Verlauf für viele Szenarios oftmals ausreichend. Das folgende Diagramm zeigt, wie dieser Vorgang automatisiert werden kann:
Zugehöriger Inhalt
- Temporale Tabellen
- Erste Schritte mit temporalen Tabellen mit Systemversionsverwaltung
- Systemkonsistenzprüfungen von temporalen Tabellen
- Partitionierung mit temporalen Tabellen
- Überlegungen und Einschränkungen zu temporalen Tabellen
- Sicherheit bei temporalen Tabellen
- Temporale Tabellen mit Systemversionsverwaltung für speicheroptimierte Tabellen
- Metadatenansichten und Funktionen für temporale Tabellen