Heaps (Tabellen ohne gruppierte Indizes)
Gilt für: ![]() SQL Server
SQL Server ![]() Azure SQL-Datenbank
Azure SQL-Datenbank ![]() Azure SQL Managed Instance
Azure SQL Managed Instance ![]() SQL-Datenbank in Microsoft Fabric
SQL-Datenbank in Microsoft Fabric
Ein Heap ist eine Tabelle ohne gruppierten Index. Ein oder mehrere nicht gruppierte Indizes können für Tabellen erstellt werden, die als Heap gespeichert sind. Daten werden ohne bestimmte Reihenfolge im Heap gespeichert. Normalerweise werden Daten zunächst in der Reihenfolge gespeichert, in der die Zeilen eingefügt werden. Die Datenbank-Engine kann Daten jedoch im Heap verschieben, um die Zeilen effizient zu speichern. In Abfrageergebnissen lässt sich keine Datenreihenfolge vorhersagen. Um die von einem Heap zurückgegebene Zeilenreihenfolge zu garantieren, verwenden Sie die ORDER BY-Klausel. Erstellen Sie einen gruppierten Index für die Tabelle, damit die Tabelle kein Heap ist, um eine permanente logische Reihenfolge für die Speicherung von Zeilen festzulegen.
Hinweis
In bestimmten Fällen gibt es gute Gründe, eine Tabelle als einen Heap zu belassen, statt einen gruppierten Index zu erstellen. Die effektive Verwendung von Heaps ist jedoch Benutzern mit fortgeschrittenen Kenntnissen vorbehalten. Die meisten Tabellen sollten über einen sorgfältig ausgewählten gruppierten Index verfügen, es sei denn, es gibt gute Gründe, die Tabelle als Heap beizubehalten.
Verwendungsbereiche für Heaps
Ein Heap eignet sich ideal für Tabellen, die häufig abgeschnitten und neu geladen werden. Die Datenbank-Engine optimiert den Speicherplatz in einem Heap, indem sie den frühesten verfügbaren Speicherplatz ausfüllt.
Beachten Sie Folgendes:
- Das Auffinden von freiem Speicherplatz in einem Heap kann kostspielig sein, insbesondere, wenn viele Lösch- oder Aktualisierungsvorgänge vorhanden sind.
- Gruppierte Indizes bieten eine gleichbleibende Leistung für Tabellen, die nicht häufig abgeschnitten werden.
Bei Tabellen, die regelmäßig abgeschnitten oder neu erstellt werden, z. B. temporäre oder Stagingtabellen, ist der Einsatz eines Heaps häufig effizienter.
Die Wahl zwischen dem Einsatz eines Heaps und eines gruppierten Indexes kann sich erheblich auf die Leistung und Effizienz Ihrer Datenbank auswirken.
Wenn eine Tabelle als Heap gespeichert wird, werden einzelne Zeilen durch einen 8-Byte-Zeilenbezeichner (RID, Row Identifier) gekennzeichnet, der aus der Dateinummer, der Datenseitennummer und einem Slot auf der Seite (FileID:PageID:SlotID) besteht. Die Zeilen-ID ist eine kleine und effiziente Struktur.
Heaps können als Stagingtabellen für große, unsortierte Einfügevorgänge verwendet werden. Da beim Einfügen von Daten keine strikte Reihenfolge erzwungen wird, ist der Einfügevorgang hier in der Regel schneller als beim Einfügen in einen gruppierten Index. Wenn die Heapdaten gelesen und im endgültigen Ziel verarbeitet werden, kann es hilfreich sein, einen schmalen, nicht gruppierten Index mit dem Suchprädikat der Abfrage zu erstellen.
Hinweis
Die Daten werden aus einem Heap in der Reihenfolge der Datenseiten abgerufen. Diese muss jedoch nicht notwendigerweise mit der Reihenfolge übereinstimmen, in der die Daten eingefügt wurden.
In einigen Fällen verwenden Datenexperten Heaps, wenn immer über nicht gruppierte Indizes auf Daten zugegriffen wird und die RID kleiner als der Schlüssel eines gruppierten Indexes ist.
Wenn eine Tabelle ein Heap ist und nicht über nicht gruppierte Indizes verfügt, muss die gesamte Tabelle gelesen werden (mit einem Tabellenscan), um eine Zeile zu finden. SQL Server kann die RID nicht direkt auf dem Heap suchen. Dieses Verhalten kann akzeptabel sein, wenn die Tabelle klein ist.
Keine Verwendungsbereiche für Heaps
Verwenden Sie keinen Heap, wenn die Daten häufig in einer sortierten Reihenfolge zurückgegeben werden. Mit einem gruppierten Index für die Sortierspalte kann der Sortiervorgang vermieden werden.
Verwenden Sie keinen Heap, wenn die Daten häufig zusammen gruppiert werden. Daten müssen vor dem Gruppieren sortiert werden, und ein gruppierter Index für die Sortierspalte kann den Sortiervorgang vermeiden.
Verwenden Sie keinen Heap, wenn häufig Datenbereiche aus der Tabelle abgefragt werden. Mit einem gruppierten Index für die Bereichsspalte kann der Sortiervorgang für den gesamten Heap vermieden werden.
Verwenden Sie keinen Heap, wenn keine nicht gruppierten Indizes vorhanden sind und die Tabelle sehr groß ist. Die einzige Anwendung für diesen Entwurf besteht darin, den gesamten Tabelleninhalt ohne eine bestimmte Reihenfolge zurückzugeben. In einem Heap liest die Datenbank-Engine alle Zeilen, um eine beliebige Zeile zu finden.
Verwenden Sie keinen Heap, wenn die Daten regelmäßig aktualisiert werden. Wenn Sie einen Datensatz aktualisieren und dafür mehr Speicherplatz in den Datenseiten benötigen, als diese derzeit verwenden, muss der Datensatz auf eine Datenseite verschoben werden, die über ausreichend freien Speicherplatz verfügt. Dadurch wird ein weitergeleiteter Datensatz erstellt, der auf den neuen Speicherort der Daten verweist, und ein weiterleitender Zeiger muss in die Seite geschrieben werden, die die Daten zuvor enthalten hat, um den neuen physischen Ort anzugeben. Dies führt zu Fragmentierung im Heap. Wenn die Datenbank-Engine einen Heap durchsucht, folgt er diesen Zeigern. Diese Aktion schränkt die Leistung beim Vorauslesen ein und kann zusätzliche E/A-Vorgänge verursachen, wodurch die Scanleistung reduziert wird.
Verwalten von Heaps
Erstellen Sie zum Anlegen eines Heaps eine Tabelle ohne gruppierten Index. Alternativ dazu können Sie den gruppierten Index löschen, wenn die Tabelle bereits über einen gruppierten Index verfügt, damit die Tabelle wieder ein Heap ist.
Erstellen Sie zum Löschen eines Heaps auf dem Heap einen gruppierten Index.
So erstellen Sie einen Heap neu, um nicht verwendeten Speicherplatz freizugeben:
- Erstellen Sie auf dem Heap einen gruppierten Index, und löschen Sie den ihn dann wieder.
- Verwenden Sie den Befehl
ALTER TABLE ... REBUILD, um den Heap neu zu erstellen.
Warnung
Das Erstellen oder Löschen von gruppierten Indizes erfordert, dass die gesamte Tabelle neue geschrieben werden muss. Wenn die Tabelle über nicht gruppierte Indizes verfügt, müssen alle nicht gruppierten Indizes immer dann neu erstellt werden, wenn der gruppierte Index geändert wird. Aus diesem Grund kann es sehr lange dauern, von einem Heap zu einem gruppierten Index zu wechseln und umgekehrt, sowie viel Festplattenspeicher zum Neuordnen der Daten in tempdb erfordern.
Identifizieren von Heaps
Die folgende Abfrage gibt die Liste der Heaps aus der aktuellen Datenbank zurück. Die Liste enthält:
- Tabellennamen
- Schemanamen
- Anzahl der Zeilen
- Tabellengröße in KB
- Indexgröße in KB
- Nicht verwendeter Speicherplatz
- Eine Spalte zum Identifizieren eines Heaps
SELECT t.name AS 'Your TableName',
s.name AS 'Your SchemaName',
p.rows AS 'Number of Rows in Your Table',
SUM(a.total_pages) * 8 AS 'Total Space of Your Table (KB)',
SUM(a.used_pages) * 8 AS 'Used Space of Your Table (KB)',
(SUM(a.total_pages) - SUM(a.used_pages)) * 8 AS 'Unused Space of Your Table (KB)',
CASE
WHEN i.index_id = 0
THEN 'Yes'
ELSE 'No'
END AS 'Is Your Table a Heap?'
FROM sys.tables t
INNER JOIN sys.indexes i
ON t.object_id = i.object_id
INNER JOIN sys.partitions p
ON i.object_id = p.object_id
AND i.index_id = p.index_id
INNER JOIN sys.allocation_units a
ON p.partition_id = a.container_id
LEFT JOIN sys.schemas s
ON t.schema_id = s.schema_id
WHERE i.index_id <= 1 -- 0 for Heap, 1 for Clustered Index
GROUP BY t.name,
s.name,
i.index_id,
p.rows
ORDER BY 'Your TableName';
Heapstrukturen
Ein Heap ist eine Tabelle ohne gruppierten Index. Heaps haben eine Zeile in sys.partitions, mit index_id = 0 für jede vom Heap verwendete Partition. Standardmäßig verfügt ein Heap über eine einzelne Partition. Wenn ein Heap über mehrere Partitionen verfügt, hat jede Partition eine Heapstruktur, in der die Daten für die jeweilige Partition enthalten sind. Wenn ein Heap z. B. über vier Partitionen verfügt, gibt es vier Heapstrukturen – jeweils eine in jeder Partition.
Je nach den im Heap enthaltenen Datentypen weist jede Heapstruktur eine oder mehrere Zuordnungseinheiten auf, um die Daten für eine bestimmte Partition zu speichern und zu verwalten. Zumindest verfügt jeder Heap über eine IN_ROW_DATA -Zuordnungseinheit pro Partition. Der Heap hat außerdem eine LOB_DATA -Zuordnungseinheit pro Partition, wenn diese LOB-Spalten (Large OBject) enthält. Außerdem ist eine ROW_OVERFLOW_DATA -Zuordnungseinheit pro Partition vorhanden, wenn der Index Spalten variabler Länge aufweist, die die Zeilengrößenbegrenzung von 8.060 Byte übersteigen.
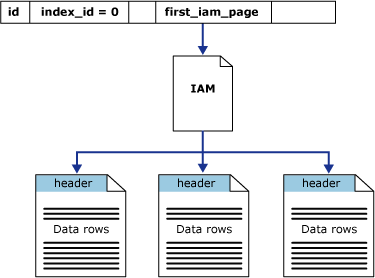
Die Spalte first_iam_page in der Systemsicht sys.system_internals_allocation_units verweist auf die erste IAM-Seite in der Kette der IAM-Seiten, die den Speicherplatz auf dem Heap in einer bestimmten Partition verwalten. SQL Server verwendet die IAM-Seiten, um sich durch den Heap zu bewegen. Die Datenseiten und die Zeilen innerhalb eines Heaps weisen keine bestimmte Reihenfolge auf und sind nicht verknüpft. Die einzige logische Verbindung zwischen den Datenseiten sind die Informationen, die auf den IAM-Seiten aufgezeichnet sind.
Wichtig
Die Systemansicht sys.system_internals_allocation_units ist nur für die interne Verwendung durch SQL Server reserviert. Zukünftige Kompatibilität wird nicht sichergestellt.
Tabellenscans oder serielle Lesevorgänge in einem Heap können durchgeführt werden, indem die IAM-Seiten gescannt werden, um auf diese Weise die Blöcke zu ermitteln, die Seiten des Heaps enthalten. Da die IAM die Blöcke in derselben Reihenfolge darstellt, in der sie in der Datendatei vorliegen, werden serielle Heapscans immer sequenziell durch jede Datei ausgeführt. Das Verwenden der IAM-Seiten zum Festlegen der Scanfolge bedeutet weiterhin, dass Zeilen aus dem Heap nicht notwendigerweise in der Reihenfolge zurückgegeben werden, in der sie eingefügt wurden.
Die folgende Abbildung zeigt, wie die SQL Server-Datenbank-Engine die IAM-Seiten zum Abrufen von Datenzeilen in einem Heap mit einer einzelnen Partition verwendet.
Verwandte Inhalte
CREATE INDEX (Transact-SQL)
DROP INDEX (Transact-SQL)
Beschreibung von gruppierten und nicht gruppierten Indizes