SQL Graph-Architektur
Gilt für: ![]() SQL Server 2017 (14.x) und höhere Versionen
SQL Server 2017 (14.x) und höhere Versionen![]() Azure SQL-Datenbank
Azure SQL-Datenbank![]() Azure SQL verwaltete Instanz
Azure SQL verwaltete Instanz ![]() SQL-Datenbank in Microsoft Fabric
SQL-Datenbank in Microsoft Fabric
Erfahren Sie mehr über die Architektur von SQL Graph. Wenn Sie die Grundlagen kennen, können Sie andere SQL Graph-Artikel leichter verstehen.
SQL Graph-Datenbank
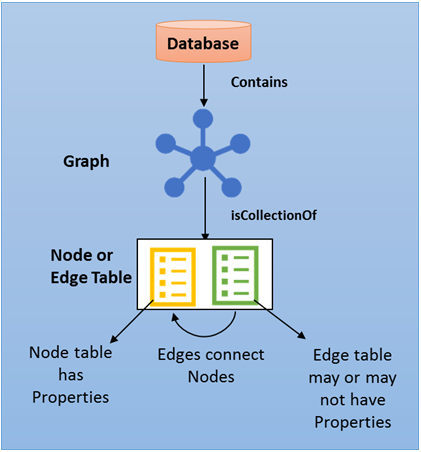
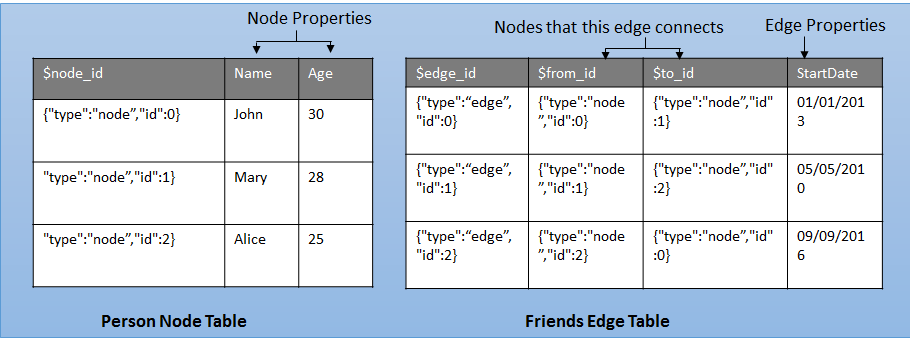
Benutzer können pro Datenbank ein Diagramm erstellen. Ein Diagramm ist eine Sammlung von Knoten- und Randtabellen. Knoten- oder Randtabellen können unter einem beliebigen Schema in der Datenbank erstellt werden, alle gehören jedoch zu einem logischen Diagramm. Eine Knotentabelle ist eine Sammlung ähnlicher Knotentypen. Beispielsweise enthält eine Person Knotentabelle alle Knoten, die Person zu einem Diagramm gehören. Ebenso ist eine Randtabelle eine Sammlung ähnlicher Kantentypen. Beispielsweise enthält eine Friends Randtabelle alle Kanten, die eine Verbindung mit einem Person anderen Personherstellen. Da Knoten und Kanten in Tabellen gespeichert werden, werden die meisten vorgänge, die in regulären Tabellen unterstützt werden, in Knoten- oder Randtabellen unterstützt.
Das folgende Diagramm zeigt die SQL Graph-Datenbankarchitektur.
Knotentabelle
Eine Knotentabelle stellt eine Entität in einem Diagrammschema dar. Jedes Mal, wenn eine Knotentabelle zusammen mit den benutzerdefinierten Spalten erstellt wird, wird eine implizite $node_id Spalte erstellt, die einen bestimmten Knoten in der Datenbank eindeutig identifiziert. Die Werte in $node_id werden automatisch generiert und sind eine Kombination aus Objekt-ID für die Diagrammtabelle dieser Knotentabelle und ein intern generierter Bigint-Wert . Wenn die $node_id Spalte ausgewählt wird, wird jedoch ein berechneter Wert in Form einer JSON-Zeichenfolge angezeigt. Außerdem ist eine Pseudospalte, $node_id die einem internen Namen mit einem eindeutigen Suffix zugeordnet ist. Wenn Sie die $node_id Pseudospalte aus der Tabelle auswählen, wird der Spaltenname als $node_id_<unique suffix>.
Hinweis
Die Verwendung der Pseudospalten in Abfragen ist die einzige unterstützte und empfohlene Methode zum Abfragen der internen $node_id Spalte. Sie sollten die $node_id_<hex_string> Spalten nicht direkt in Abfragen verwenden.
Darüber hinaus ist die berechnete JSON-Darstellung in den Pseudospalten ein Implementierungsdetail. Sie sollten keine direkte Abhängigkeit vom Format dieser JSON-Darstellung haben. Wenn Sie mit dieser JSON-Darstellung umgehen müssen, sollten Sie die verwendung der NODE_ID_FROM_PARTS() und anderer verwandter Systemfunktionen in Betracht ziehen.
Es wird nicht empfohlen, die Pseudospalten des Diagramms ($node_id, $from_id, $to_id) in Prädikaten direkt zu verwenden. Beispielsweise sollte ein Prädikat wie n.$node_id = e.$from_id vermieden werden. Solche Vergleiche sind aufgrund der Konvertierung in die JSON-Darstellung ineffizient. Verlassen Sie sich stattdessen so weit wie möglich auf die MATCH-Funktion.
Es wird empfohlen, dass Benutzer zum Zeitpunkt der Erstellung der Knotentabelle eine eindeutige Einschränkung oder einen eindeutigen Index für die $node_id Spalte erstellen, aber wenn einer nicht erstellt wird, wird automatisch ein eindeutiger, nicht gruppierter Index erstellt. Jeder Index für eine Diagramm-Pseudospalte wird jedoch in den zugrunde liegenden internen Spalten erstellt. Das heißt, ein in der $node_id Spalte erstellter Index wird in der internen graph_id_<hex_string> Spalte angezeigt.
Randtabelle
Eine Randtabelle stellt eine Beziehung in einem Diagramm dar. Kanten werden immer weitergeleitet und verbinden zwei Knoten. Mit einer Randtabelle können Benutzer m:n-Beziehungen im Diagramm modellieren. Benutzerdefinierte Spalten ("Attribute") sind in einer Randtabelle optional. Jedes Mal, wenn eine Randtabelle zusammen mit den benutzerdefinierten Spalten erstellt wird, werden drei implizite Spalten in der Randtabelle erstellt:
| Spaltenname | Beschreibung |
|---|---|
$edge_id |
Identifiziert einen bestimmten Rand in der Datenbank eindeutig. Es handelt sich um eine generierte Spalte und der Wert ist eine Kombination aus object_id der Randtabelle und einem intern generierten Bigint-Wert . Wenn die $edge_id Spalte ausgewählt wird, wird jedoch ein berechneter Wert in Form einer JSON-Zeichenfolge angezeigt. $edge_id ist eine Pseudospalte, die einem internen Namen mit einem eindeutigen Suffix zugeordnet ist. Wenn Sie aus der Tabelle auswählen $edge_id , wird der Spaltenname als $edge_id_<unique suffix>. Die Verwendung von Pseudospaltennamen in Abfragen ist die empfohlene Methode zum Abfragen der internen $edge_id Spalte und die Verwendung des internen Namens mit hex-Zeichenfolge sollte vermieden werden. |
$from_id |
Speichert den $node_id Knoten, von dem der Rand stammt. |
$to_id |
Speichert den $node_id Knoten, an dem der Rand beendet wird. |
Die Knoten, mit denen ein bestimmter Rand eine Verbindung herstellen kann, werden durch die in die $from_id Spalten $to_id eingefügten Daten gesteuert. In der ersten Version ist es nicht möglich, Einschränkungen für die Randtabelle zu definieren, um die Verbindung zwischen zwei Knotentypen einzuschränken. Das heißt, ein Rand kann unabhängig von ihren Typen beliebige zwei Knoten im Diagramm verbinden.
Ähnlich wie bei der $node_id Spalte empfiehlt es sich, dass Benutzer zum Zeitpunkt der Erstellung der Randtabelle einen eindeutigen Index oder eine Einschränkung für die $edge_id Spalte erstellen, aber wenn keines erstellt wird, wird in dieser Spalte automatisch ein eindeutiger, nicht gruppierter Standardindex erstellt. Jeder Index für eine Diagramm-Pseudospalte wird jedoch in den zugrunde liegenden internen Spalten erstellt. Das heißt, ein in der $edge_id Spalte erstellter Index wird in der internen graph_id_<unique suffix> Spalte angezeigt. Es wird auch für OLTP-Szenarien empfohlen, dass Benutzer einen Index für ($from_id, $to_id) Spalten erstellen, um schnellere Nachschlagevorgänge in Richtung des Rands zu ermöglichen.
Das folgende Diagramm zeigt, wie Knoten- und Randtabellen in der Datenbank gespeichert werden.
Metadaten
Verwenden Sie diese Metadatenansichten, um Attribute eines Knotens oder einer Randtabelle anzuzeigen.
sys.tables
Die folgenden bit Spalten in sys.tables können zum Identifizieren von Diagrammtabellen verwendet werden. Wenn is_node die Tabelle auf 1 festgelegt ist, handelt es sich bei der Tabelle um eine Knotentabelle, und wenn is_edge sie auf 1 festgelegt ist, handelt es sich bei der Tabelle um eine Randtabelle.
| Spaltenname | Datentyp | Beschreibung |
|---|---|---|
| is_node | bit | Bei Knotentabellen is_node ist die Einstellung auf 1 festgelegt. |
| is_edge | bit | Für Randtabellen is_edge ist sie auf 1 festgelegt. |
sys.columns
Die graph_type Spalten und graph_type_desc Spalten in der sys.columns Ansicht sind hilfreich, um die verschiedenen Spaltentypen zu verstehen, die in Diagrammknoten- und Randtabellen verwendet werden:
| Spaltenname | Datentyp | Beschreibung |
|---|---|---|
| graph_type | int | Interne Spalte mit einer Gruppe von Werten. Die Werte liegen zwischen 1 und 8 für Diagrammspalten und lauten NULL für andere. |
| graph_type_desc | nvarchar(60) | Interne Spalte mit einer Gruppe von Werten. |
In der folgenden Tabelle sind die gültigen Werte für graph_type die Spalte aufgeführt:
| Spaltenwert | Beschreibung |
|---|---|
| 1 | GRAPH_ID |
| 2 | GRAPH_ID_COMPUTED |
| 3 | GRAPH_FROM_ID |
| 4 | GRAPH_FROM_OBJ_ID |
| 5 | GRAPH_FROM_ID_COMPUTED |
| 6 | GRAPH_TO_ID |
| 7 | GRAPH_TO_OBJ_ID |
| 8 | GRAPH_TO_ID_COMPUTED |
sys.columns speichert auch Informationen zu impliziten Spalten, die in Knoten- oder Edgetabellen erstellt wurden. Die folgenden Informationen können jedoch aus "sys.columns" abgerufen werden. Benutzer können diese Spalten jedoch nicht aus einem Knoten oder einer Randtabelle auswählen.
Die impliziten Spalten in einer Knotentabelle sind:
| Spaltenname | Datentyp | is_hidden | Kommentar |
|---|---|---|---|
graph_id_\<hex_string> |
BIGINT | 1 | Interner Graph-ID-Wert. |
$node_id_\<hex_string> |
NVARCHAR | 0 | Externe Zeichendarstellung der Knoten-ID. |
Die impliziten Spalten in einer Randtabelle sind:
| Spaltenname | Datentyp | is_hidden | Kommentar |
|---|---|---|---|
graph_id_\<hex_string> |
BIGINT | 1 | Interner Graph-ID-Wert. |
$edge_id_\<hex_string> |
NVARCHAR | 0 | Zeichendarstellung der Edge-ID. |
from_obj_id_\<hex_string> |
INT | 1 | Interner object_id Wert für den "from node". |
from_id_\<hex_string> |
BIGINT | 1 | Interner Graph-ID-Wert für den "from node". |
$from_id_\<hex_string> |
NVARCHAR | 0 | Zeichendarstellung des "von Knoten". |
to_obj_id_\<hex_string> |
INT | 1 | Intern object_id für den Knoten "an". |
to_id_\<hex_string> |
BIGINT | 1 | Interner Graph-ID-Wert für den "zu Knoten". |
$to_id_\<hex_string> |
NVARCHAR | 0 | Externe Zeichendarstellung des "zu Knotens". |
System functions (Systemfunktionen)
Sie können die folgenden integrierten Funktionen verwenden, um mit den Pseudospalten in Diagrammtabellen zu interagieren. Detaillierte Verweise werden für jede dieser Funktionen in den jeweiligen T-SQL-Funktionsreferenzen bereitgestellt.
| Integriert | Beschreibung |
|---|---|
| OBJECT_ID_FROM_NODE_ID | Extrahieren Sie die Objekt-ID für die Diagrammtabelle aus einem node_id. |
| GRAPH_ID_FROM_NODE_ID | Extrahieren Sie den Graph-ID-Wert aus einem node_id. |
| NODE_ID_FROM_PARTS | Erstellen Sie eine node_id aus einer Objekt-ID für die Diagrammtabelle und einen Diagramm-ID-Wert. |
| OBJECT_ID_FROM_EDGE_ID | Extrahieren sie die Objekt-ID für die Diagrammtabelle aus edge_id. |
| GRAPH_ID_FROM_EDGE_ID | Extrahieren Sie den Graph-ID-Wert für einen bestimmten edge_idWert. |
| EDGE_ID_FROM_PARTS | Erstellen edge_id sie aus der Objekt-ID für die Diagrammtabelle und den Diagramm-ID-Wert. |
Transact-SQL-Referenz
Erfahren Sie, welche Transact-SQL-Erweiterungen in SQL Server eingeführt wurden, und Azure SQL-Datenbank, die das Erstellen und Abfragen von Diagrammobjekten ermöglichen. Die Abfragesprachenerweiterungen helfen beim Abfragen und Durchlaufen des Diagramms mithilfe der ASCII-Grafiksyntax.
Anweisungen der Data Definition Language (DDL)
| Aufgabe | Verwandter Artikel | Hinweise |
|---|---|---|
| CREATE TABLE | CREATE TABLE (Transact-SQL) | CREATE TABLE wird nun erweitert, um das Erstellen einer Tabelle AS NODE oder AS EDGE zu unterstützen. Für eine Randtabelle sind keine benutzerdefinierten Attribute erforderlich. |
| ALTER TABLE | ALTER TABLE (Transact-SQL) | Knoten- und Randtabellen können auf die gleiche Weise geändert werden, wie eine relationale Tabelle verwendet ALTER TABLEwird. Benutzer können benutzerdefinierte Spalten, Indizes oder Einschränkungen hinzufügen oder ändern. Das Ändern interner Diagrammspalten wie $node_id oder $edge_id, führt jedoch zu einem Fehler. |
| CREATE INDEX | CREATE INDEX (Transact-SQL) | Benutzer können Indizes für Pseudospalten und benutzerdefinierte Spalten in Knoten- und Randtabellen erstellen. Alle Indextypen werden unterstützt, einschließlich gruppierter und nicht gruppierter Spaltenspeicherindizes. |
| ERSTELLEN VON EDGEEINSCHRÄNKUNGEN | EDGE CONSTRAINTS (Transact-SQL) | Benutzer können jetzt Edgeeinschränkungen für Edgetabellen erstellen, um bestimmte Semantik zu erzwingen und auch die Datenintegrität aufrechtzuerhalten. |
| DROP TABLE | DROP TABLE (Transact-SQL) | Knoten- und Randtabellen können auf die gleiche Weise gelöscht werden, wie eine relationale Tabelle verwendet DROP TABLEwird. Derzeit gibt es keine Mechanismen, um das Löschen von Knoten zu verhindern, auf die von Rändern verwiesen wird. Beim Löschen eines Knotens (oder Löschen der gesamten Knotentabelle) gibt es keine Unterstützung für das kaskadierte Löschen von Kanten. In allen solchen Fällen müssen alle Ränder, die mit den gelöschten Knoten verbunden sind, manuell gelöscht werden, um die Konsistenz des Diagramms aufrechtzuerhalten. |
Anweisungen der Data Manipulation Language (DML)
| Aufgabe | Verwandter Artikel | Hinweise |
|---|---|---|
| INSERT | INSERT (Transact-SQL) | Das Einfügen in eine Knotentabelle unterscheidet sich nicht vom Einfügen in eine relationale Tabelle. Die Werte für $node_id Die Spalte werden automatisch generiert. Wenn Sie versuchen, einen Wert in $node_id oder $edge_id Spalte einzufügen, tritt ein Fehler auf. Benutzer müssen Beim Einfügen in eine Randtabelle Werte für $from_id und $to_id Spalten angeben. $from_id und $to_id sind die $node_id Werte der Knoten, die ein bestimmter Rand verbindet. |
| DELETE | DELETE (Transact-SQL) | Daten aus Knoten- oder Randtabellen können auf die gleiche Weise gelöscht werden wie aus relationalen Tabellen. In dieser Version gibt es jedoch keine Einschränkungen, um sicherzustellen, dass keine Ränder auf einen gelöschten Knoten zeigen und die Löschweitergabe von Kanten beim Löschen eines Knotens nicht unterstützt wird. Es wird empfohlen, dass bei jedem Löschen eines Knotens auch alle Verbindungsränder zu diesem Knoten gelöscht werden. |
| UPDATE | UPDATE (Transact-SQL) | Werte in benutzerdefinierten Spalten können mithilfe der UPDATE-Anweisung aktualisiert werden. Sie können die internen Diagrammspalten, $node_id, , $edge_id$from_id und $to_id. |
| MERGE | MERGE (Transact-SQL) | MERGE Anweisung wird für einen Knoten oder eine Randtabelle unterstützt. |
Abfrageanweisungen
| Aufgabe | Verwandter Artikel | Hinweise |
|---|---|---|
| SELECT | SELECT (Transact-SQL) | Da Knoten und Kanten als Tabellen gespeichert werden, werden die meisten Tabellenvorgänge auch für Knoten- und Randtabellen unterstützt. |
| MATCH | MATCH (Transact-SQL) | VERGLEICH integriert wird eingeführt, um Musterabgleich und Durchquerung des Diagramms zu unterstützen. |
Begrenzungen
Es gibt bestimmte Einschränkungen für Knoten- und Randtabellen:
- Lokale oder globale temporäre Tabellen können keine Knoten- oder Randtabellen sein.
- Tabellentypen und Tabellenvariablen können nicht als Knoten oder Randtabelle deklariert werden.
- Knoten- und Randtabellen können nicht als zeitliche Tabellen mit Systemversion erstellt werden.
- Knoten- und Randtabellen können keine speicheroptimierten Tabellen sein.
- Benutzer können die
$from_idSpalten$to_ideines Edges nicht mithilfe der UPDATE-Anweisung aktualisieren. Um Knoten zu aktualisieren, auf die von einem Rand verwiesen wird, müssen Benutzer einen neuen Rand einfügen, der auf neue Knoten zeigt, und das vorherige Element löschen. - Datenbankübergreifende Abfragen für Diagrammobjekte werden nicht unterstützt.
- Diagramm-Pseudospalten (
node_id,$to_id$from_idundedge_id) können nicht als Sortierspalten für einen sortierten gruppierten Spaltenspeicherindex verwendet werden. Beim Versuch, pseudospalten diagramme als Sortierspalten für sortierte gruppierte Spalten zu verwenden, tritt einMsg 102: Incorrect syntaxFehler auf. - In der Fabric SQL-Datenbank ist SQL Graph zulässig, aber Knoten- und Edgetabellen spiegeln sich nicht in Fabric OneLake.
Siehe auch
Nächste Schritte
- Informationen zu den ersten Schritten mit SQL Graph finden Sie unter SQL Graph-Datenbank – Beispiel