Diagnostizieren und Lösen von Latchkonflikten in SQL Server
In diesem Leitfaden wird beschrieben, wie Sie Latchkonflikte identifizieren und lösen, die auftreten, wenn SQL Server-Anwendungen mit bestimmten Arbeitsauslastungen auf Systemen mit hoher Parallelität ausgeführt werden.
Während die Anzahl der CPU-Kerne in Servern weiterhin steigt, kann der entsprechende Anstieg der Parallelität zu Konflikten in Datenstrukturen führen, auf die auf serielle Weise in der Datenbank-Engine zugegriffen werden muss. Dies gilt insbesondere für OLTP-Arbeitsauslastungen (Arbeitsauslastungen mit hohem Durchsatz/hoher Parallelität für die Transaktionsverarbeitung). Es gibt eine Vielzahl von Tools, Verfahren und Möglichkeiten, um diese Herausforderungen zu bewältigen. Außerdem gibt es bewährte Methoden zum Entwerfen von Anwendungen, mit denen diese vollständig vermieden werden können. In diesem Artikel wird eine bestimmte Art von Konflikten bei Datenstrukturen behandelt, die Spinlocks zum Serialisieren des Zugriffs auf diese Datenstrukturen verwenden.
Hinweis
Dieser Inhalt wurde vom SQLCAT von Microsoft auf Grundlage seines Verfahrens zum Identifizieren und Lösen von Problemen im Zusammenhang mit Seitenlatchkonflikten in SQL Server-Anwendungen in Systemen mit hoher Parallelität verfasst. Die hier dokumentierten Empfehlungen und bewährten Methoden basieren auf praktischen Erfahrungen bei der Entwicklung und Bereitstellung von realen OLTP-Systemen.
Was sind SQL Server-Latchkonflikte?
Latches sind einfache Synchronisierungsprimitiven, die von der SQL Server-Engine verwendet werden, um die Konsistenz von In-Memory-Strukturen zu gewährleisten. Dazu gehören beispielsweise Indizes, Datenseiten und interne Strukturen wie Seiten, die sich nicht am Ende der Struktur befinden, in einer B-Struktur. SQL Server verwendet Pufferlatches, um Seiten im Pufferpool zu schützen, und E/A-Latches, um Seiten zu schützen, die noch nicht in den Pufferpool geladen wurden. Wenn Daten in eine Seite geschrieben oder aus dieser gelesen werden, die sich im SQL Server-Pufferpool befindet, muss ein Workerthread zunächst ein Pufferlatch für die Seite abrufen. Es stehen verschiedene Pufferlatchtypen für den Zugriff auf Seiten im Pufferpool zur Verfügung, einschließlich exklusiver Latches (PAGELATCH_EX) und gemeinsamer Latches (PAGELATCH_SH). Wenn SQL Server versucht, auf eine Seite zuzugreifen, die noch nicht im Pufferpool vorhanden ist, wird eine asynchrone Eingabe/Ausgabe veröffentlicht, um die Seite in den Pufferpool zu laden. Wenn SQL Server auf eine Antwort des E/A-Subsystems warten muss, wird je nach Art von Anforderung auf einen exklusiven oder gemeinsamen E/A-Latch gewartet. Damit soll verhindert werden, dass ein anderer Workerthread dieselbe Seite mit einem inkompatiblen Latch in den Pufferpool lädt. Latches werden auch zum Schützen des Zugriff auf interne Arbeitsspeicherstrukturen verwendet, bei denen es sich nicht um Pufferpoolseiten handelt. Diese werden als Nicht-Pufferlatches bezeichnet.
Konflikte in Seitenlatches stellen das gängigste Szenario in Systemen mit mehreren CPUs dar, daher befasst sich dieser Artikel hauptsächlich mit diesen.
Latchkonflikte treten auf, wenn mehrere Threads gleichzeitig versuchen, inkompatible Latches für dieselbe In-Memory-Struktur abzurufen. Da Latches ein interner Steuermechanismus sind, bestimmt die SQL-Engine automatisch, wann sie verwendet werden sollen. Aufgrund des deterministischen Verhaltens von Latches können sich Anwendungsentscheidungen, z. B. der Schemaentwurf, auf dieses Verhalten auswirken. Dieser Artikel bietet die folgenden Informationen:
- Hintergrundinformationen zur Verwendung von Latches durch SQL Server
- Tools zum Untersuchen von Latchkonflikten
- Wie wird ermittelt, ob die vorhandene Konfliktmenge problematisch ist?
Es werden außerdem einige gängige Szenarios und die besten Vorgehensweisen zum Lösen dieser Konflikte behandelt.
Wie verwendet SQL Server Latches?
Eine Seite in SQL Server ist 8 KB groß und kann mehrere Zeilen enthalten. Im Gegensatz zu Sperren, die für die Dauer der logischen Transaktion beibehalten werden, werden Pufferlatches zum Erhöhen der Parallelität und Leistung nur für die Dauer des physischen Vorgangs auf der Seite beibehalten.
Latches sind intern in der SQL-Engine und werden dazu verwendet, Arbeitsspeicherkonsistenz bereitzustellen, während Sperren von SQL Server verwendet werden, um Konsistenz für logische Transaktionen bereitzustellen. In der folgenden Tabelle werden Latches mit Sperren verglichen:
| Struktur | Zweck | Gesteuert von | Leistungskosten | Zur Verfügung gestellt durch |
|---|---|---|---|---|
| Latch | Gewährleisten der Konsistenz von In-Memory-Strukturen | Nur SQL Server-Engine | Die Leistungskosten sind niedrig. Im Gegensatz zu Sperren, die für die Dauer der logischen Transaktion beibehalten werden, werden Latches für die bestmögliche Parallelität und Leistung nur für die Dauer des physischen Vorgangs für die In-Memory-Struktur beibehalten. | sys.dm_os_wait_stats (Transact-SQL): bietet Informationen zur Verwendung der Wartetypen PAGELATCH, PAGEIOLATCH und LATCH (LATCH_EX und LATCH_SH werden zum Gruppieren aller Wartevorgänge aller Latchwartevorgänge ohne Puffer verwendet). sys.dm_os_latch_stats (Transact-SQL): stellt ausführliche Informationen über Latchwartevorgänge ohne Puffer bereit. sys.dm_db_index_operational_stats (Transact-SQL): Diese DMV (dynamische Verwaltungssicht) stellt aggregierte Wartevorgänge für jeden Index bereit. Dies ist für die Problembehandlung bei Leistungsproblemen im Zusammenhang mit Latches nützlich. |
| Sperren | Gewährleisten der Konsistenz von Transaktionen | Kann vom Benutzer gesteuert werden | Die Leistungskosten sind im Vergleich zu Latches hoch, da Sperren für die Dauer der Transaktion beibehalten werden müssen. | sys.dm_tran_locks (Transact-SQL) sys.dm_exec_sessions (Transact-SQL) |
SQL Server-Latchmodi und -kompatibilität
Einige Latchkonflikte sind als normaler Teil des Vorgangs der SQL Server-Engine zu erwarten. Es ist unvermeidlich, dass mehrere gleichzeitige Latchanforderungen mit variierender Kompatibilität in einem System mit hoher Parallelität auftreten. SQL Server erzwingt die Latchkompatibilität, indem erzwungen wird, dass inkompatible Latchanforderungen in einer Warteschlange warten müssen, bis ausstehende Latchanforderungen abgeschlossen sind.
Latches werden in einem von fünf Modi abgerufen, die sich auf das Ausmaß des Zugriffs beziehen. SQL Server-Latchmodi können folgendermaßen zusammengefasst werden:
KP (Keep latch, Beibehaltungslatch): Dieser Latch stellt sicher, dass die referenzierte Struktur nicht gelöscht werden kann. Er wird verwendet, wenn ein Thread eine Pufferstruktur überprüfen möchte. Da der KP-Latch mit allen Latches außer dem DT-Latch (Destroy latch, Löschlatch) kompatibel ist, gilt der KP-Latch als „lightweight“. Das bedeutet, dass seine Auswirkungen auf die Leistung minimal ausfallen. Da der KP-Latch nicht mit dem DT-Latch kompatibel ist, wird verhindert, dass andere Threads die referenzierte Struktur löschen. Ein KP-Latch verhindert beispielsweise, dass die referenzierte Struktur vom Prozess für verzögertes Schreiben gelöscht wird. Weitere Informationen dazu, wie der Prozess für verzögertes Schreiben mit der SQL Server-Pufferseitenverwaltung verwendet wird, finden Sie unter Schreiben von Seiten.
SH: Der freigegebene Latch, der zum Lesen der referenzierten Struktur (z. B. Lesen einer Datenseite) erforderlich ist. Mehrere Threads können gleichzeitig auf eine Ressource zum Lesen unter einem freigegebenen Latch zugreifen.
UP (Updatelatch): Dieser Latch ist mit SH- und KP-Latches kompatibel, aber mit keinen anderen. Daher wird es einem EX-Latch nicht erlaubt, in die referenzierte Struktur zu schreiben.
EX (Exclusive latch, Exklusiver Latch): Dieser Latch hindert andere Latches daran, in die referenzierte Struktur zu schreiben oder aus dieser zu lesen. Ein Beispiel hierfür ist die Verwendung zum Ändern der Inhalte einer Seite für den Schutz vor zerrissenen Seiten.
DT (Destroy latch, Löschlatch): Dieser Latch muss abgerufen werden, bevor Inhalte aus der referenzierten Struktur gelöscht werden. Ein DT-Latch muss beispielsweise vom Prozess für verzögertes Schreiben abgerufen werden, um eine bereinigte Seite freizugeben, bevor sie zur Liste der freien Puffer hinzugefügt wird, die von anderen Threads verwendet werden können.
Latchmodi weisen verschiedene Grade an Kompatibilität auf, beispielsweise sind SH-Latches mit UP- und KP-Latches kompatibel, aber nicht mit DT-Latches. Mehrere Latches können gleichzeitig für dieselbe Struktur abgerufen werden, solange die Latches kompatibel sind. Wenn ein Thread versucht, einen Latch abzurufen, der einen inkompatiblen Modus aufweist, wird er in eine Warteschlange platziert, um auf ein Signal zu warten, das die Verfügbarkeit der Ressource angibt. Ein Spinlock vom Typ SOS_Task wird zum Schützen der Warteschlange verwendet, indem der serialisierte Zugriff auf die Warteschlange erzwungen wird. Dieser Spinlock muss zum Hinzufügen von Elementen zur Warteschlange abgerufen werden. Der SOS_Task-Spinlock informiert Threads in der Warteschlange auch, wenn inkompatible Latches freigegeben werden, sodass die wartenden Threads einen kompatiblen Latch abrufen und weiter arbeiten können. Die Warteschlange wird nach der FIFO-Methode (first in, first out) verarbeitet, wenn Latchanforderungen freigegeben werden. Latches unterliegen diesem FIFO-System, um Fairness sicherzustellen und Threadmangel zu vermeiden.
Die Latchmoduskompatibilität wird in der folgenden Tabelle aufgeführt (J steht für Kompatibilität und N steht für Inkompatibilität):
| Latchmodus | KP | SH | UP | EX | DT |
|---|---|---|---|---|---|
| KP | Y | Y | Y | Y | N |
| SH | Y | Y | Y | N | N |
| UP | Y | Y | N | N | N |
| EX | Y | N | N | N | N |
| DT | N | N | N | N | N |
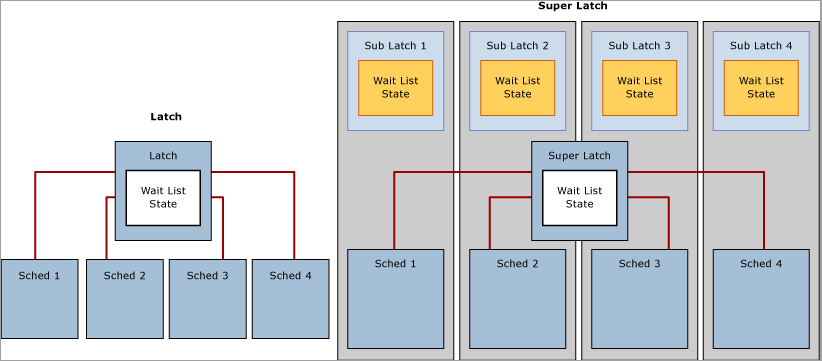
SQL Server-SuperLatches und -SubLatches
Mit der zunehmenden Präsenz NUMA-basierter Systeme mit mehreren Sockets/Kernen wurden SuperLatches mit SQL Server 2005 eingeführt. Diese sind auch als SubLatches bekannt und nur auf Systemen mit 32 oder mehr logischen Prozessoren wirksam. SuperLatches erhöhen die Effizienz der SQL-Engine für bestimmte Nutzungsmuster in OLTP-Arbeitsauslastungen mit hoher Parallelität, z. B., wenn bestimmte Seiten ein Muster mit hohem schreibgeschützten SH-Zugriff aufweisen, in die aber nur selten geschrieben wird. Ein Beispiel für eine Seite mit einem solchen Zugriffsmuster ist eine Stammseite der B-Struktur (d. h. ein Index). Die SQL-Engine erfordert, dass ein gemeinsamer Latch auf der Stammseite beibehalten wird, wenn eine Seitenteilung auf einer beliebigen Ebene der B-Struktur auftritt. Bei einer OLTP-Arbeitsauslastung mit hoher Parallelität und vielen Einfügevorgängen steigt die Anzahl der Seitenteilungen deutlich entsprechend des Durchsatzes an, was die Leistung beeinträchtigen kann. SuperLatches können für den Zugriff auf gemeinsame Seiten eine bessere Leistung erzielen, wenn mehrere gleichzeitig ausgeführte Workerthreads SH-Latches benötigen. Hierzu stuft die SQL Server-Engine einen Latch für eine solche Seite dynamisch auf einen SuperLatch herauf. Ein SuperLatch unterteilt einen einzelnen Latch in ein Array von Sublatchstrukturen mit einem Sublatch pro Partition für jeden CPU-Kern. Dabei wird der Hauptlatch zu einem Proxyredirector, und die Synchronisierung des globalen Zustands ist für schreibgeschützte Latches nicht erforderlich. Dadurch muss der Worker, der immer einer spezifischen CPU zugewiesen wird, nur den SH-Sublatch abrufen, der dem lokalen Planer zugewiesen ist.
Hinweis
In der Dokumentation wird der Begriff „B-Struktur“ im Allgemeinen in Bezug auf Indizes verwendet. In Zeilenspeicherindizes implementiert die Datenbank-Engine eine B+-Struktur. Dies gilt nicht für Columnstore-Indizes oder In-Memory-Datenspeicher. Weitere Informationen finden Sie im Leitfaden zur Architektur und zum Entwerfen von SQL Server- und Azure SQL-Indizes.
Das Abrufen kompatibler Latches, z. B. gemeinsamer SuperLatches, nutzt weniger Ressourcen und kann besser als ein nicht partitionierter, gemeinsamer Latch für aktive Seiten skaliert werden, da das Entfernen der Synchronisierungsanforderung des globalen Zustands die Leistung erheblich verbessert wird, indem lediglich auf lokalen NUMA-Arbeitsspeicher zugegriffen wird. Im Gegensatz dazu ist das Abrufen eines exklusiven SuperLatches aufwendiger als das Abrufen eines regulären, exklusiven Latches, da SQL Signale an alle Sublatches übermitteln muss. Wenn ein SuperLatch mit hohem EX-Zugriff beobachtet wird, kann die SQL-Engine diesen herabstufen, nachdem die Seite aus dem Pufferpool verworfen wurde. Auf der folgenden Abbildung wird ein normaler Latch und ein partitionierter SuperLatch veranschaulicht:
Verwenden Sie das Objekt SQL Server:Latches und die zugehörigen Leistungsindikatoren im Systemmonitor, um Informationen über SuperLatches zu sammeln, einschließlich der Anzahl von SuperLatches, SuperLatch-Höherstufungen pro Sekunde und SuperLatch-Herabstufungen pro Sekunde. Weitere Informationen über das Objekt SQL Server:Latches und den zugehörigen Leistungsindikatoren finden Sie unter SQL Server: Latches-Objekt.
Latchwartetypen
Kumulative Warteinformationen werden von SQL Server nachverfolgt und können über die DMV (dynamische Verwaltungssicht) sys.dm_os_wait_stats eingesehen werden. SQL Server nutzt drei Latchwartetypen, die vom entsprechenden Wert wait_type in der DMV sys.dm_os_wait_stats definiert werden:
Pufferlatch (BUF): Mit diesem Typ wird die Konsistenz von Index- und Datenseiten für Benutzerobjekte gewährleistet. Sie werden außerdem dazu verwendet, den Zugriff auf Datenseiten zu schützen, die SQL Server für Systemobjekte verwendet. Beispielsweise werden Seiten, die Zuteilungen verwalten, durch Pufferlatches geschützt. Dazu gehören folgende Seiten: PFS (Page Free Space), GAM (Global Allocation Map), SGAM (Shared Global Allocation Map) und IAM (Index Allocation Map). Pufferlatches werden in
sys.dm_os_wait_statsmit demwait_type-Wert PAGELATCH_* angezeigt.Nicht-Pufferlatch (Non-BUF): Mit diesem Typ wird die Konsistenz beliebiger In-Memory-Strukturen gewährleistet, bei denen es sich nicht um Pufferpoolseiten handelt. Alle Wartevorgänge für Nicht-Pufferlatches werden mit dem
wait_type-Wert LATCH_*. angezeigt.E/A-Latch: Hierbei handelt es sich um eine Teilmenge von Pufferlatches, die die Konsistenz derselben Strukturen gewährleisten, die durch Pufferlatches geschützt werden, wenn diese Strukturen mit einem E/A-Vorgang in den Pufferpool geladen werden müssen. E/A-Latches hindern andere Threads am Laden derselben Seite in den Pufferpool mit einem inkompatiblen Latch. Mit einem
wait_type-Wert von PAGEIOLATCH_* verknüpft.Hinweis
Wenn lange PAGEIOLATCH-Wartezeiten vorliegen, bedeutet dies, dass SQL Server auf das E/A-Subsystem wartet. Eine gewisse Menge an PAGEIOLATCH-Wartevorgängen wird erwartet und entspricht dem normalen verhalten. Wenn die durchschnittlichen PAGEIOLATCH-Wartezeiten jedoch konsistent über 10 Millisekunden (ms) liegen, sollten Sie untersuchen, wieso das E/A-Subsystem überlastet ist.
Wenn Sie beim Untersuchen der DMV sys.dm_os_wait_stats Nicht-Puffer-Latches finden, müssen Sie sys.dm_os_latch_stats untersuchen, um eine detaillierte Aufschlüsselung der kumulativen Warteinformationen für Nicht-Puffer-Latches zu erhalten. Alle Puffer-Latchwartevorgänge werden mit der Latchklasse BUFFER klassifiziert. Die restlichen werden zum Klassifizieren von Nicht-Pufferlatches verwendet.
Symptome und Ursachen von SQL Server-Latchkonflikten
Bei einem ausgelasteten System mit hoher Parallelität ist es normal, dass aktive Konflikte bei Strukturen auftreten, auf die häufig zugegriffen wird und die von Latches und anderen Kontrollmechanismen in SQL Server geschützt werden. Es gilt als problematisch, wenn ein Konflikt und die Wartezeit zum Abrufen eines Latches für eine Seite die CPU-Auslastung reduziert, was den Durchsatz beeinträchtigt.
Beispiel für einen Latchkonflikt
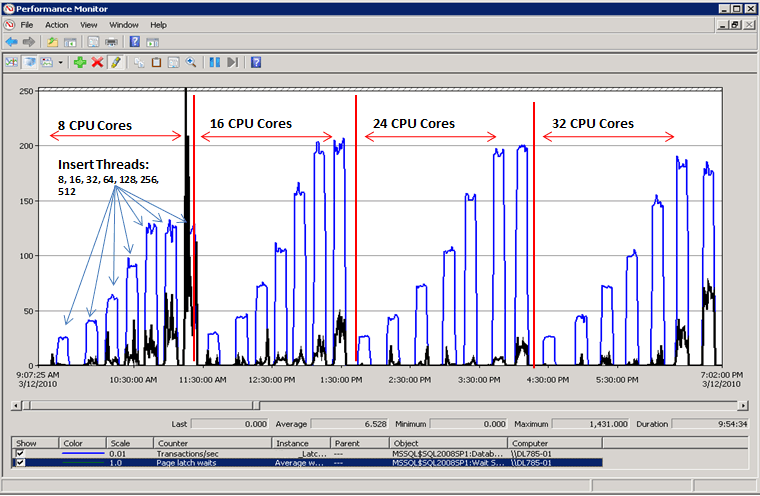
Im folgenden Diagramm stellt die blaue Linie den Durchsatz in SQL Server in Form von Transaktionen pro Sekunde dar. Die schwarze Linie stellt die durchschnittliche Dauer von Latchwartevorgängen für Seiten dar. In diesem Fall führt jede Transaktion einen INSERT-Vorgang in einen gruppierten Index mit einem sequenziell steigenden, führenden Wert durch, z. B. beim Auffüllen einer IDENTITY-Spalte vom Datentyp „bigint“. Wenn die Anzahl der CPU-Kerne auf 32 erhöht wird, ist erkennbar, dass der allgemeine Durchsatz gesunken ist und die Wartezeiten für Seitenlatches auf etwa 48 Millisekunden gestiegen sind, wie von der schwarzen Linie dargestellt wird. Durch diese umgekehrte Beziehung zwischen dem Durchsatz und der Wartezeit für Seitenlatches ist ein gängiges Szenario, das mühelos diagnostiziert werden kann.

Leistung nach Auflösung des Latchkonflikts
Wie im folgenden Diagramm gezeigt, wurde der Engpass der Wartevorgänge für Seitenlatches in SQL Server gelöst und der Durchsatz in Transaktionen pro Sekunde wurde um 300 % gesteigert. Dies wurde mit dem Verfahren Verwenden der Hashpartitionierung mit einer berechneten Spalte erzielt, das später in diesem Artikel erläutert wird. Diese Leistungsverbesserung gilt für Systeme mit einer hohen Anzahl an Kernen und einem hohen Grad an Parallelität.
Aspekte von Latchkonflikten
Latchkonflikte, die die Leistung in OLTP-Umgebungen behindern, werden üblicherweise durch hohe Parallelität im Zusammenhang mit einem oder mehreren der folgenden Faktoren verursacht:
| Faktor | Details |
|---|---|
| Hohe Anzahl logischer CPUs, die von SQL Server verwendet werden | Ein Latchkonflikt kann auf jedem System mit mehreren Kernen auftreten. In SQLCAT-Umgebungen wurden übermäßige Latchkonflikte, die sich stark auf die Anwendungsleistung auswirken, am häufigsten auf Systemen beobachtet, die mehr als 16 CPU-Kerne aufweisen. Diese Leistungsbeeinträchtigung kann steigen, wenn zusätzliche Kerne bereitgestellt werden. |
| Schemaentwurf und Zugriffsmuster | Der Umfang der B-Struktur, der Entwurf von gruppierten und nicht gruppierten Indizes, die Größe und Dichte der Zeilen pro Seite und die Zugriffsmuster (Lese-, Schreib- und Löschaktivitäten) sind Faktoren, die zu übermäßigen Seitenlatchkonflikten beitragen können. |
| Hoher Grad an Parallelität in der Logikschicht | Übermäßige Seitenlatchkonflikte treten in der Regel im Zusammenhang mit einer großen Menge gleichzeitiger Anforderungen der Logikschicht auf. Es gibt gewisse Programmierverfahren, die ebenfalls zu einer hohen Anzahl von Anforderungen für eine spezifische Seite führen können. |
| Layout logischer Dateien, die von SQL Server-Datenbanken verwendet werden | Das Layout logischer Dateien kann sich auf Seitenlatchkonflikte auswirken, die von Zuteilungsstrukturen wie PFS-, GAM-, SGAM- und IAM-Seiten verursacht werden. Weitere Informationen finden Sie unter Überwachung und Problembehandlung von TempDB: Zuteilungsengpässe. |
| E/A-Subsystemleistung | Erhebliche PAGEIOLATCH-Wartezeiten sind ein Zeichen dafür, dass SQL Server auf das E/A-Subsystem wartet. |
Diagnose von SQL Server-Latchkonflikten
In diesem Abschnitt finden Sie Informationen zur Diagnose von SQL Server-Latchkonflikten, um zu bestimmen, ob diese ein Problem für Ihre Umgebung darstellen.
Tools und Methoden für die Diagnose von Latchkonflikten
Die primären Tools für die Diagnose von Latchkonflikten sind:
Der Systemmonitor zum Überwachen der CPU-Auslastung und der Wartezeiten in SQL Server und zur Überprüfung, ob eine Beziehung zwischen der CPU-Auslastung und den Latchwartezeiten besteht.
Die SQL Server-DMVs, die zum Ermitteln der betroffenen Ressource und des Latchtyps verwendet werden können, der das Problem verursacht.
In einigen Fällen müssen Arbeitsspeicherabbilder des SQL Server-Prozesses mit Windows-Debugtools abgerufen und analysiert werden.
Hinweis
Diese erweiterte Problembehandlung ist in der Regel nur für die Problembehandlung von Konflikten bei Nicht-Pufferlatches erforderlich. Für diese erweiterte Problembehandlung können Sie sich an den Produktsupport von Microsoft wenden.
Der technische Prozess für die Diagnose von Latchkonflikten kann in den folgenden Schritten zusammengefasst werden:
Ermitteln Sie, ob ein Konflikt vorliegt, der möglicherweise einen Zusammenhang mit Latches aufweist.
Verwenden Sie die DMV-Ansichten, die im Anhang: Skripts für SQL Server-Latchkonflikte bereitgestellt werden, um den Latchtyp und die betroffenen Ressourcen zu ermitteln.
Lösen Sie mit einem der unter Behandeln von Latchkonflikten für verschiedene Tabellenmuster beschriebenen Verfahren.
Anzeichen für Latchkonflikte
Wie bereits erwähnt sind Latchkonflikte nur problematisch, wenn der Konflikt und die Wartezeiten zum Abrufen von Seitenlatches den Durchsatz daran hindert, zu steigen, wenn CPU-Ressourcen verfügbar sind. Zum Ermitteln der akzeptablen Menge von Konflikten ist ein ganzheitlicher Ansatz erforderlich, der Leistungs- und Durchsatzanforderungen zusammen mit den verfügbaren E/A- und CPU-Ressourcen berücksichtigt. In diesem Abschnitt durchlaufen Sie den Prozess zum Ermitteln der Auswirkungen von Latchkonflikten auf Arbeitsauslastungen wie folgt:
Messen Sie die Gesamtwartezeiten während eines repräsentativen Tests.
Sortieren Sie sie der Reihe nach.
Bestimmen Sie den Anteil der Ergebnisse, die sich auf Latches beziehen.
Kumulative Warteinformationen finden Sie in der DMV sys.dm_os_wait_stats. Die gängigsten Latchkonflikte sind Pufferlatchkonflikte, bei denen erhöhte Wartezeiten für Latches mit dem wait_type-Wert PAGELATCH_* auftreten. Nicht-Pufferlatches werden nach dem Wartetyp LATCH* gruppiert. Wie im folgenden Diagramm veranschaulicht wird, sollten Sie zunächst die Systemwartezeiten kumulativ mithilfe der DMV sys.dm_os_wait_stats betrachten, um den Prozentsatz der Gesamtwartezeit zu bestimmen, die von Pufferlatches oder Nicht-Puffer-Latches verursacht wird. Wenn Nicht-Pufferlatches auftreten, müssen Sie auch die DMV sys.dm_os_latch_stats untersuchen.
Im folgenden Diagramm wird die Beziehung zwischen Informationen veranschaulicht, die von den DMVs sys.dm_os_wait_stats und sys.dm_os_latch_stats bereitgestellt werden.

Weitere Informationen über die DMV sys.dm_os_wait_stats finden Sie in der SQL Server-Hilfe unter sys.dm_os_wait_stats (Transact-SQL).
Weitere Informationen über die DMV sys.dm_os_latch_stats finden Sie in der SQL Server-Hilfe unter sys.dm_os_latch_stats (Transact-SQL).
Die folgenden Measures der Latchwartezeit sind Anzeichen dafür, dass übermäßige Latchkonflikte sich auf die Anwendungsleistung auswirken:
Die durchschnittliche Wartezeit für Seitenlatches steigt konstant mit zunehmendem Durchsatz: Wenn die durchschnittlichen Wartezeiten für Seitenlatches konstant mit zunehmendem Durchsatz steigen und die durchschnittlichen Wartezeiten für Pufferlatches ebenfalls über die erwarteten Antwortzeiten des Datenträgers hinaus steigen, sollten Sie die aktuell wartenden Tasks mithilfe der DMV
sys.dm_os_waiting_tasksuntersuchen. Durchschnittswerte können irreführend sein, wenn sie isoliert untersucht werden. Daher ist es wichtig, dass Sie das System nach Möglichkeit in Echtzeit betrachten, um die Merkmale der Arbeitsauslastung zu verstehen. Überprüfen Sie insbesondere, ob hohe Wartezeiten bei PAGELATCH_EX- und/oder PAGELATCH_SH-Anforderungen für beliebige Seiten vorliegen. Führen Sie die folgenden Schritte aus, um steigende durchschnittliche Wartezeiten für Seitenlatches bei zunehmenden Durchsatz zu diagnostizieren:- Verwenden Sie die Beispielskripts Abfragen von sys.dm_os_waiting_tasks nach Sitzungs-ID und Berechnen der Wartezeiten in einem Zeitraum, um die aktuellen wartenden Tasks zu untersuchen und die durchschnittliche Latchwartezeit zu messen.
- Verwenden Sie das Beispielskript Abfragen von Pufferdeskriptoren zum Ermitteln von Objekten als Ursache für Latchkonflikte, um den Index und die zugrunde liegende Tabelle zu ermitteln, in denen der Konflikt aufgetreten ist.
- Messen Sie die durchschnittliche Wartezeit für Seitenlatches mit dem Indikator MSSQL%InstanceName%\Wait Statistics\Page Latch Waits\Average Wait Time des Leistungsmonitors oder mit der DMV
sys.dm_os_wait_stats.
Hinweis
Teilen Sie die Gesamtwartezeit (als
sys.dm_os_wait_statszurückgegeben) durch die Anzahl der wartenden Tasks (alswait_time_mszurückgegeben), um die durchschnittliche Wartezeit für einen bestimmten Wartetyp (wird vonwaiting_tasks_countals wt_:type zurückgegeben) zu berechnen.Prozentsatz der gesamten Wartezeit für Latchwartetypen während Spitzenlasten:Wenn die durchschnittliche Latchwartezeit als Prozentsatz der Gesamtwartezeit mit zunehmender Anwendungslast steigt, beeinträchtigen Latchkonflikte möglicherweise die Leistung, was untersucht werden sollte.
Messen Sie Wartevorgänge für Seitenlatches und Nicht-Seitenlatches mit den SQLServer:Wait Statistics Object-Leistungsindikatoren. Vergleichen Sie dann die Werte für diese Leistungsindikatoren mit Leistungsindikatoren für die CPU, E/A-Vorgänge, den Arbeitsspeicher und den Netzwerkdurchsatz. Beispielsweise eignen sich die Measures „Transaktionen/Sekunde“ und „Batchanforderungen/Sekunde“ für die Ressourcennutzung.
Hinweis
Die relative Wartezeit für jeden Wartetyp ist nicht in der DMV
sys.dm_os_wait_statsenthalten, da diese DMV die Wartezeiten seit dem letzten Start der SQL Server-Instanz oder der letzten Zurücksetzung der kumulativen Wartestatistik mit DBCC SQLPERF misst. Erfassen Sie eine Momentaufnahme vonsys.dm_os_wait_statsvor und nach Spitzenlasten, und berechnen Sie dann die Differenz, um die relative Wartezeit für jeden Wartetyp zu berechnen. Hierzu können Sie das Beispielskript Berechnen der Wartevorgänge in einem Zeitraum verwenden.Bereinigen Sie die DMV
sys.dm_os_wait_statsmit dem folgenden Befehl nur für Nicht-Produktionsumgebungen:dbcc SQLPERF ('sys.dm_os_wait_stats', 'CLEAR')Ein ähnlicher Befehl kann ausgeführt werden, um die DMV
sys.dm_os_latch_statszu löschen:dbcc SQLPERF ('sys.dm_os_latch_stats', 'CLEAR')Der Durchsatz steigt nicht und fällt in einigen Fällen, während die Anwendungslast und die Anzahl der für SQL Server verfügbaren Kerne steigen: Dies wurde unter Beispiel für einen Latchkonflikt veranschaulicht.
Die CPU-Auslastung steigt nicht, wenn die Anwendungsarbeitsauslastung steigt: Wenn die CPU-Auslastung des Systems nicht steigt, wenn die Parallelität durch den Anwendungsdurchsatz steigt, ist dies ein Zeichen dafür, dass SQL Server auf etwas wartet und dass Latchkonflikte Probleme verursachen.
Analysieren Sie die Grundursache. Selbst wenn alle genannten Bedingungen vorliegen, ist es möglich, dass eine andere Grundursache für die Leistungsprobleme verantwortlich ist. In den meisten Fällen sind suboptimale CPU-Auslastungen auf andere Arten von Wartevorgängen wie blockierte Sperren, E/A-bezogene Wartevorgänge oder Netzwerkprobleme zurückzuführen. Als Faustregel gilt: Die beste Lösung besteht immer darin, die Ressourcenwartevorgänge zu lösen, die den größten Anteil der Gesamtwartezeit darstellt, bevor Sie mit ausführlicheren Analysen fortfahren.
Analysieren aktueller Wartevorgänge von Pufferlatches
Pufferlatchkonflikte äußern sich in erhöhten Wartezeiten für Latches mit den wait_type-Werten PAGELATCH_* oder PAGEIOLATCH_*, die in der DMV sys.dm_os_wait_stats angezeigt werden. Um das System in Echtzeit zu betrachten, führen Sie die folgende Abfrage in einem System aus, um die DMVs sys.dm_os_wait_stats, sys.dm_exec_sessions und sys.dm_exec_requests zu verbinden. Anhand der Ergebnisse können Sie den aktuellen Wartetyp für Sitzungen ermitteln, die auf dem Server ausgeführt werden.
SELECT wt.session_id, wt.wait_type
, er.last_wait_type AS last_wait_type
, wt.wait_duration_ms
, wt.blocking_session_id, wt.blocking_exec_context_id, resource_description
FROM sys.dm_os_waiting_tasks wt
JOIN sys.dm_exec_sessions es ON wt.session_id = es.session_id
JOIN sys.dm_exec_requests er ON wt.session_id = er.session_id
WHERE es.is_user_process = 1
AND wt.wait_type <> 'SLEEP_TASK'
ORDER BY wt.wait_duration_ms desc
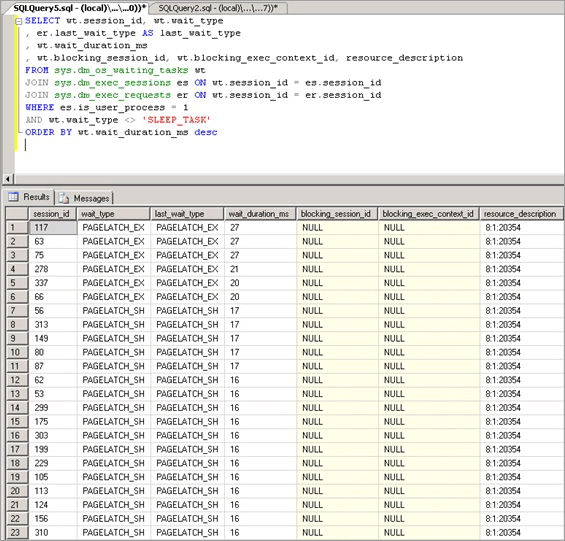
Die von dieser Abfrage zur Verfügung gestellten Statistiken werden wie folgt beschrieben:
| Statistik | Beschreibung |
|---|---|
| Session_id | ID der Sitzung, die dem Task zugeordnet ist. |
| Wait_type | Dies ist der Typ des Wartevorgangs, den SQL Server in der Engine aufgezeichnet hat und der die Ausführung einer aktuellen Anforderung verhindert. |
| Last_wait_type | Wenn diese Anforderung zuvor bereits blockiert war, gibt diese Spalte den Typ des letzten Wartevorgangs zurück. Lässt keine NULL-Werte zu. |
| Wait_duration_ms | Die Gesamtwartezeit in Millisekunden, die für diesen Wartetyp aufgebracht wurde, seitdem die SQL Server-Instanz gestartet oder die kumulativen Wartestatistik zuletzt zurückgesetzt wurde. |
| Blocking_session_id | ID der Sitzung, die die Anforderung blockiert. |
| Blocking_exec_context_id | ID des Ausführungskontexts, der dem Task zugeordnet ist. |
| Resource_description | In der Spalte resource_description ist die exakte Seite im Format <database_id>:<file_id>:<page_id> aufgeführt, auf die gewartet wird. |
Die folgende Abfrage gibt Informationen zu allen Nicht-Pufferlatches zurück:
select * from sys.dm_os_latch_stats where latch_class <> 'BUFFER' order by wait_time_ms desc;
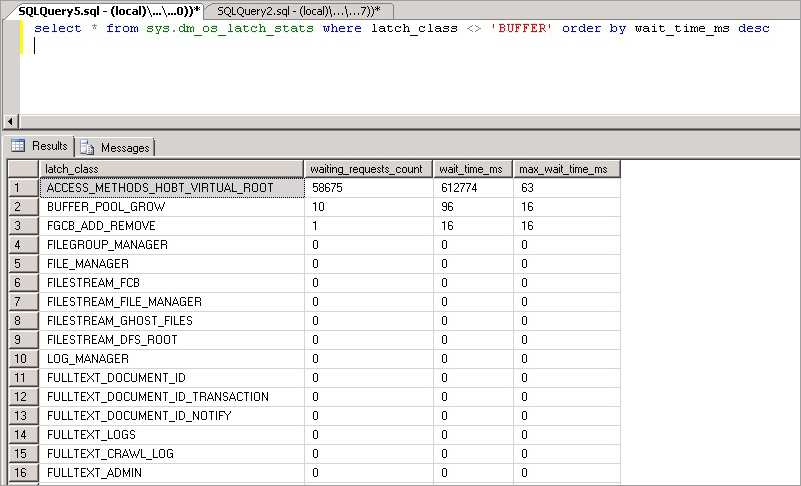
Die von dieser Abfrage zur Verfügung gestellten Statistiken werden wie folgt beschrieben:
| Statistik | Beschreibung |
|---|---|
| latch_class | Dies ist der Typ des Latch, den SQL Server in der Engine aufgezeichnet hat und der die Ausführung einer aktuellen Anforderung verhindert. |
| waiting_requests_count | Hierbei handelt es sich um die Anzahl der Wartevorgänge für Latches in dieser Klasse seit dem Neustart von SQL Server. Dieser Leistungsindikator wird beim Starten eines Latchwartevorgangs erhöht. |
| wait_time_ms | Hierbei handelt es sich um die Gesamtwartezeit in Millisekunden für diesen Latchtyp. |
| max_wait_time_ms | Hierbei handelt es sich um die maximale Zeit in Millisekunden, die alle Anforderungen auf diesen Latchtyp gewartet haben. |
Hinweis
Die von dieser DMV zurückgegebenen Werte werden kumulativ seit dem letzten Neustart der Datenbank-Engine oder der letzten Zurücksetzung der DMV gezählt. Verwenden Sie die sqlserver_start_time-Spalte in sys.dm_os_sys_info, um die aktuellste Startzeit der Datenbank-Engine zu suchen. Bei einem System, das sehr lange ausgeführt wird, sind Statistiken wie max_wait_time_ms selten nützlich. Der folgende Befehl kann dazu verwendet werden, die Wartestatistiken für diese DMV zurückzusetzen:
DBCC SQLPERF ('sys.dm_os_latch_stats', CLEAR);
Szenarios für SQL Server-Latchkonflikte
Die folgenden Szenarios sind dafür bekannt, übermäßige Latchkonflikte zu verursachen.
Konflikt beim Einfügen der letzten/nachstehenden Seite
Ein gängiges OLTP-Verfahren besteht darin, einen gruppierten Index für eine Identitäts- oder Datumsspalte zu erstellen. Dies trägt zu einer guten physischen Sortierung des Index bei, was sich positiv auf die Leistung von Lese- und Schreibvorgängen im Index auswirken kann. Dieser Schemaentwurf kann jedoch auch zu versehentlichen Latchkonflikten führen. Dieses Problem tritt häufig bei großen Tabellen mit kleinen Zeilen und Einfügevorgängen in einen Index, der eine sequenziell steigende führende Schlüsselspalte enthält, z. B. ein steigender Integer oder Datetime-Schlüssel. In diesem Szenario führt die Anwendung, wenn überhaupt, nur selten Update- oder Löschvorgänge durch, es sei denn, Vorgänge werden archiviert.
Im folgenden Beispiel möchten Thread 1 und Thread 2 beide einen Datensatz einfügen, der auf Seite 299 gespeichert wird. Aus der Perspektive der logischen Sperre liegt kein Problem vor, da Sperren auf Zeilenebene verwendet werden und exklusive Sperren für beide Datensätze auf derselben Seite gleichzeitig aufrechterhalten werden können. Zum Sicherstellen der Integrität des physischen Arbeitsspeichers kann immer nur ein Thread einen exklusiven Latch abrufen, damit der Zugriff auf die Seite serialisiert wird, um verlorene Updates im Arbeitsspeicher zu vermeiden. In diesem Fall ruft Thread 1 den exklusiven Latch ab, und Thread 2 wartet, wodurch ein PAGELATCH_EX-Wartevorgang für diese Ressource in den Wartestatistiken registriert wird. Dies wird durch den wait_type-Wert in der DMV sys.dm_os_waiting_tasks angezeigt.
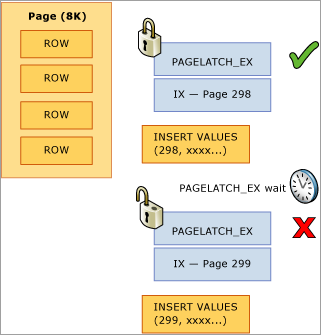
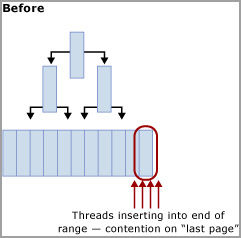
Dieser Konflikt wird häufig als „Last Page Insert“ (Einfügen der letzten Seite) bezeichnet, da er wie im folgenden Diagramm gezeigt am Edge am rechten Rand der B-Struktur auftritt:
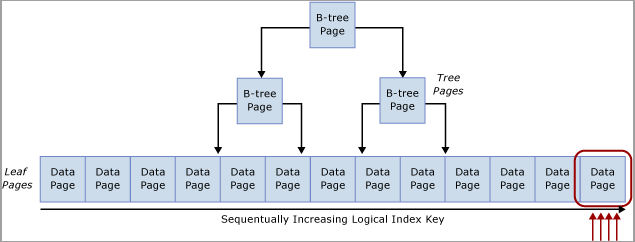
Diese Art von Latchkonflikt kann folgendermaßen erklärt werden: Wenn eine neue Zeile in einen Index eingefügt wird, verwendet SQL Server den folgenden Algorithmus zum Ausführen der Änderung:
Durchlaufen Sie die B-Struktur, um die richtige Seite zu finden, die den neuen Datensatz enthalten soll.
Verwenden Sie einen PAGELATCH_EX-Latch für die Seite, damit sie nicht von anderen geändert werden kann, und rufen Sie PAGELATCH_SH-Latches für alle Seiten ab, die sich nicht am Ende der Struktur befinden.
Hinweis
In einigen Fällen erfordert die SQL-Engine, dass auch EX-Latches für die Seiten abgerufen werden, die sich nicht am Ende der B-Struktur befinden. Wenn beispielsweise eine Seitenteilung auftritt, müssen PAGELATCH_EX-Latches für alle direkt betroffenen Seiten verwendet werden.
Zeichnen Sie einen Protokolleintrag auf, der angibt, dass die Zeile geändert wurde.
Fügen Sie die Zeile zur Seite hinzu, und markieren Sie die Seite als geändert.
Heben Sie die Latches für alle Seiten auf.
Wenn der Tabellenindex auf einem sequenziell aufsteigenden Schlüssel basiert, wird jeder neue Einfügevorgang an dieselbe Seite am Ende der B-Struktur weitergeleitet, bis diese Seite voll ist. Bei Szenarios mit hoher Parallelität kann dies zu Konflikten am rechten Edge der B-Struktur führen. Dies kann bei gruppierten und nicht gruppierten Indizes auftreten. Tabellen, die von dieser Art von Konflikt betroffen sind, akzeptieren hauptsächlich INSERT-Vorgänge, und die Seiten für die problematischen Indizes sind in der Regel relativ dicht (z. B. entspricht eine Zeilengröße von 165 Bytes (einschließlich Zeilenmehraufwand) 49 Zeilen pro Seite). In diesem Beispiel mit vielen Einfügevorgängen ist zu erwarten, dass PAGELATCH_EX-/PAGELATCH_SH-Wartezeiten auftreten, da dies üblich ist. Verwenden Sie die DMV sys.dm_db_index_operational_stats, um Seitenlatch-Wartevorgänge im Vergleich zu Strukturseitenlatches zu untersuchen.
In der folgenden Tabelle werden die wichtigsten Faktoren zusammengefasst, die bei dieser Art von Latchkonflikten festgestellt werden:
| Faktor | Typische Beobachtungen |
|---|---|
| Von SQL Server verwendete logische CPUs | Diese Art von Latchkonflikten tritt hauptsächlich in Systemen mit mehr als 16 CPU-Kernen und am häufigsten auf Systemen mit mehr als 32 CPU-Kernen auf. |
| Schemaentwurf und Zugriffsmuster | Hierbei wird ein sequenziell steigender Identitätswert als führende Spalte in einem Index für eine Tabelle für Transaktionsdaten verwendet. Der Index weist einen steigenden Primärschlüssel mit einer hohen Rate von Einfügevorgängen auf. Der Index weist mindestens einen sequenziell steigenden Spaltenwert auf. In der Regel liegt eine kleine Zeilengröße mit vielen Zeilen pro Seite vor. |
| Beobachteter Wartetyp | Viele Threads, die für dieselbe Ressource im Konflikt mit EX- oder SH-Latchwartevorgängen im Zusammenhang mit derselben resource_description-Spalte in der DMV sys.dm_os_waiting_tasks stehen, werden von der Abfrage der DMV „sys.dm_os_waiting_tasks“ sortiert nach der Wartezeit zurückgegeben. |
| Zu berücksichtigende Entwurfsfaktoren | Erwägen Sie, die Reihenfolge der Indexspalten wie in der Strategie zur Migration nicht-sequenzieller Indizes beschrieben zu ändern, wenn Sie gewährleisten können, dass Einfügevorgänge jederzeit gleichmäßig auf die B-Struktur verteilt werden. Wenn die Strategie zur Minderung der Hashpartitionierung verwendet wird, wird die Fähigkeit zum Verwenden der Partitionierung für jegliche andere Zwecke wie die Archivierung mit gleitenden Fenstern entfernt. Die Verwendung der Strategie zur Minderung der Hashpartitionierung kann zu Problemen bei der Partitionsentfernung für SELECT-Abfragen führen, die von der Anwendung verwendet werden. |
Latchkonflikte für kleine Tabellen mit einem nicht gruppierten Index und zufälligen Einfügungen (Warteschlangentabelle)
Dieses Szenario wird in der Regel angezeigt, wenn eine SQL-Tabelle als temporäre Warteschlange verwendet wird (z. B. in einem asynchronen Messagingsystem).
In diesem Szenario können unter den folgenden Bedingungen EX- und SH-Latchkonflikte auftreten:
- INSERT-, SELECT-, UPDATE- und DELETE-Vorgänge treten mit hoher Parallelität auf.
- Die Zeilengröße ist relativ klein (was zu dichten Seiten führt).
- Die Anzahl der Zeilen in der Tabelle ist relativ klein, was zu einer flachen B-Struktur führt, die durch eine Indextiefe von zwei oder drei Ebenen definiert wird.
Hinweis
Selbst bei tieferen B-Strukturen als diesen können Konflikte mit dieser Art von Zugriffsmuster auftreten, wenn die Häufigkeit der Datenbearbeitungssprache (DML) und Parallelität des Systems ausreichend hoch sind. Das Ausmaß der Latchkonflikte kann mit steigender Parallelität wachsen, wenn 16 oder mehr CPU-Kerne für das System verfügbar sind.
Latchkonflikte können sogar auftreten, wenn der Zugriff in der gesamten B-Struktur zufällig erfolgt, z. B. wenn eine nicht sequenzielle Spalte der führende Schlüssel in einem gruppierten Index ist. Im folgenden Screenshot sehen Sie ein System mit dieser Art von Latchkonflikt. In diesem Beispiel ist die Dichte der Seiten, die von der kleinen Zeilengröße und der relativ flachen B-Struktur verursacht wird, die Ursache des Konflikts. Bei zunehmender Parallelität treten Latchkonflikte bei Seiten auf, obwohl die Einfügevorgänge zufällig auf die B-Struktur verteilt werden, da die führende Spalte im Index eine GUID ist.
Im folgenden Screenshot treten die Wartezeiten auf Pufferdatenseiten und PFS-Seiten auf. Weitere Informationen über Latchkonflikte bei PFS-Seiten finden Sie im folgenden Blogbeitrag eines Drittanbieters auf der SQLSkills-Website: Benchmarktests: Mehrere Datendateien auf SSD-Datenträgern. Selbst wenn die Anzahl der Datendateien erhöht wurde, blieb der Latchkonflikt auf den Pufferdatenseiten bestehen.
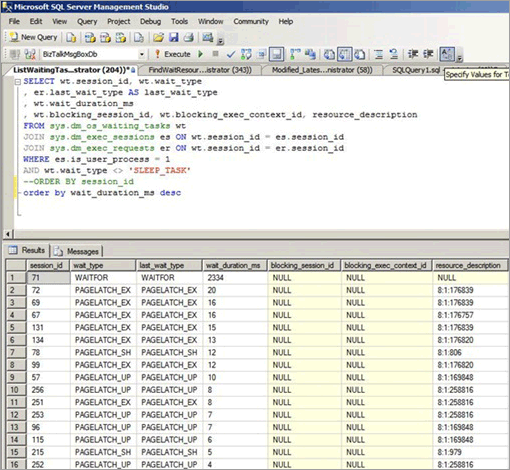
In der folgenden Tabelle werden die wichtigsten Faktoren zusammengefasst, die bei dieser Art von Latchkonflikten festgestellt werden:
| Faktor | Typische Beobachtungen |
|---|---|
| Von SQL Server verwendete logische CPUs | Der Latchkonflikt tritt hauptsächlich auf Computern mit mehr als 16 CPU-Kernen auf. |
| Schemaentwurf und Zugriffsmuster | Es liegt eine hohe Rate INSERT-, SELECT-, UPDATE- und DELETE-Zugriffsmustern für kleine Tabellen vor. Es liegt eine flache B-Struktur vor (Indextiefe von zwei oder drei Ebenen). Es liegt eine kleine Zeilengröße vor (viele Datensätze pro Seite). |
| Parallelitätsgrad | Der Latchkonflikt tritt nur bei einer hohen Anzahl gleichzeitiger Anforderungen der Logikschicht auf. |
| Beobachteter Wartetyp | Beobachten Sie die Wartevorgänge für Pufferlatches (PAGELATCH_EX und PAGELATCH_SH) und den Nicht-Pufferlatch ACCESS_METHODS_HOBT_VIRTUAL_ROOT aufgrund der Stammteilungen. Beachten Sie auch die PAGELATCH_UP-Wartevorgänge für PFS-Seiten. Weitere Informationen über Wartevorgänge von Nicht-Pufferlatches finden Sie im SQL Server-Hilfsartikel sys.dm_os_latch_stats (Transact-SQL). |
Die Kombination einer flachen B-Struktur und der zufälligen Einfügungen im Index neigt dazu, Seitenteilungen in der B-Struktur zu verursachen. Zum Durchführen einer Seitenteilung muss SQL Server SH-Latches auf allen Ebenen und anschließend EX-Latches für Seiten in der B-Struktur abrufen, die an den Seitenteilungen beteiligt sind. Wenn außerdem eine hohe Parallelität vorliegt und kontinuierlich Daten eingefügt und gelöscht werden, können Stammteilungen in der B-Struktur auftreten. In diesem Fall müssen andere Einfügungen möglicherweise darauf warten, dass Nicht-Pufferlatches für die B-Struktur abgerufen werden. Dies zeigt sich in Form einer großen Anzahl von Wartevorgängen für den ACCESS_METHODS_HBOT_VIRTUAL_ROOT-Latchtyp, der in der DMV sys.dm_os_latch_stats angezeigt wird.
Das folgende Skript kann geändert werden, um die Tiefe der B-Struktur für die Indizes in der betroffenen Tabelle zu ermitteln.
select o.name as [table],
i.name as [index],
indexProperty(object_id(o.name), i.name, 'indexDepth')
+ indexProperty(object_id(o.name), i.name, 'isClustered') as depth, --clustered index depth reported doesn't count leaf level
i.[rows] as [rows],
i.origFillFactor as [fillFactor],
case (indexProperty(object_id(o.name), i.name, 'isClustered'))
when 1 then 'clustered'
when 0 then 'nonclustered'
else 'statistic'
end as type
from sysIndexes i
join sysObjects o on o.id = i.id
where o.type = 'u'
and indexProperty(object_id(o.name), i.name, 'isHypothetical') = 0 --filter out hypothetical indexes
and indexProperty(object_id(o.name), i.name, 'isStatistics') = 0 --filter out statistics
order by o.name;
Latchkonflikte auf PFS-Seiten
PFS steht für Page Free Space (Freier Seitenspeicherplatz). SQL Server ordnet in jeder Datenbankdatei alle 8088 Seiten (beginnend mit PageID = 1) eine PFS-Seite zu. Jedes Byte der PFS-Seite zeichnet Informationen auf, einschließlich des freien Speicherplatzes in der Seite, ob sie zugeteilt ist und ob die Seite inaktive Datensätze enthält. Die PFS-Seite enthält Informationen über die Seiten, die für die Zuteilung verfügbar sind, wenn eine neue Seite für einen INSERT- oder UPDATE-Vorgang benötigt wird. Die PFS-Seite muss in mehreren Szenarios aktualisiert werden, auch wenn Zuteilungen durchgeführt oder aufgehoben werden. Da die Verwendung eines UP-Latches zum Schutz der PFS-Seite erforderlich ist, können Latchkonflikte auf PFS-Seiten auftreten, wenn Sie über relativ wenige Datendateien in einer Dateigruppe und eine große Anzahl von CPU-Kernen verfügen. Eine einfache Lösung hierfür besteht darin, die Anzahl der Dateien pro Dateigruppe zu erhöhen.
Warnung
Das Erhöhen der Anzahl der Dateien pro Dateigruppe kann sich negativ auf die Leistung bestimmter Arbeitsauslastungen auswirken, beispielsweise Arbeitsauslastungen mit vielen großen Sortiervorgängen, durch die Speicher zum Datenträger überläuft.
Wenn bei PFS- oder SGAM-Seiten in tempdb viele PAGELATCH_UP-Wartevorgänge auftreten, führen Sie die folgenden Schritte durch, um diesen Engpass zu beseitigen:
Fügen Sie Datendateien zu tempdb hinzu, sodass die Anzahl der tempdb-Datendatei mit der Anzahl der Prozessorkerne Ihres Servers übereinstimmt.
Aktivieren Sie das SQL Server-Ablaufverfolgungsflag 1118.
Weitere Informationen über Engpässe bei der Zuteilung aufgrund von Konflikten auf Systemseiten finden Sie im Blogbeitrag Was sind Zuteilungsengpässe?.
Tabellenwertfunktionen und Latchkonflikte in tempdb
Neben Zuteilungskonflikten gibt es auch andere Faktoren, die zu Latchkonflikten in tempdb führen können, z. B. die übermäßige Verwendung von Tabellenwertfunktionen in Abfragen.
Behandeln von Latchkonflikten für verschiedene Tabellenmuster
In den folgenden Abschnitten werden Verfahren beschrieben, die dazu verwendet werden können, Leistungsprobleme bei übermäßigen Latchkonflikten zu behandeln oder zu umgehen.
Verwenden eines nicht sequenziellen führenden Indexschlüssels
Eine Methode zur Behandlung von Latchkonflikten ist das Ersetzen eines sequenziellen Indexschlüssels durch einen nicht sequenziellen Schlüssel, um Einfügevorgänge gleichmäßig auf einen Indexbereich zu verteilen.
In der Regel erfolgt dies mithilfe einer führenden Spalte im Index, die die Arbeitsauslastung proportional verteilt. Verfügbare Optionen:
Option: Verwenden einer Spalte in der Tabelle zum Verteilen von Werten auf den Indexschlüsselbereich
Bewerten Sie Ihre Arbeitsauslastung, um einen natürlichen Wert zu erhalten, der zum Verteilen der Einfügevorgänge auf den Schlüsselbereich verwendet werden kann. Stellen Sie sich beispielsweise ein Szenario mit einem Geldautomat vor, bei dem der ATM_ID-Wert sich dafür eignet, die Einfügevorgänge auf eine Transaktionstabelle für Geldabhebungen zu verteilen, da immer nur ein Kunde den Geldautomaten verwenden kann. Ähnlich könnte bei einem POS-System (Point of Sale, Verkaufsort) möglicherweise ein Checkout_ID- oder Store-ID-Wert ein natürlicher Wert sein, der für die Verteilung der Einfügevorgänge auf einen Schlüsselbereich verwendet werden kann. Für dieses Verfahren muss ein zusammengesetzter Indexschlüssel erstellt werden, bei dem die führende Schlüsselspalte entweder den Wert der identifizierten Spalte oder einen Hash des Werts in Kombination mit einer oder mehreren Spalten enthält, um die Eindeutigkeit zu gewährleisten. In den meisten Fällen funktioniert ein Hash des Werts am besten, da zu viele unterschiedliche Werte zu einer schlechten physischen Organisation führen. Beispielsweise könnte ein Hashwert in einem POS-System aus der Store-ID erstellt werden, bei der es sich um ein Modulo handelt, das der Anzahl der CPU-Kerne entspricht. Dieses Verfahren würde zu einer relativ kleinen Anzahl von Bereichen in der Tabelle führen, dies würde jedoch ausreichen, um die Einfügevorgänge auf eine Weise zu verteilen, mit der Latchkonflikte vermieden werden würden. Dieses Verfahren wird auf der folgenden Abbildung veranschaulicht.
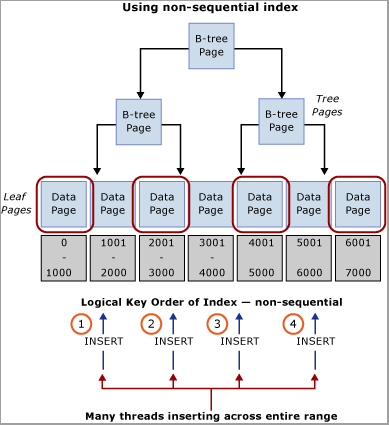
Wichtig
Dieses Muster widerspricht den herkömmlichen bewährten Methoden für die Indizierung. Während dieses Muster dazu beiträgt, eine gleichmäßige Verteilung der Einfügevorgänge auf die B-Struktur sicherzustellen, kann möglicherweise auch eine Schemaänderung in der Logikschicht erforderlich sein. Darüber hinaus kann sich dieses Muster negativ auf die Leistung von Abfragen auswirken, die Bereichsüberprüfungen erfordern, die den gruppierten Index nutzen. Analysen der Arbeitsauslastungsmuster sind erforderlich, um zu bestimmen, ob diese Vorgehensweise gut funktionieren wird. Dieses Muster sollte implementiert werden, wenn Sie etwas Leistung der sequenziellen Überprüfung opfern können, um Durchsatz und Skalierung von Einfügevorgängen zu erzielen.
Dieses Muster wurde während einem Leistungslabprojekt implementiert, wodurch Latchkonflikte auf einem System mit 32 physischen CPU-Kernen gelöst wurden. Diese Tabelle wurde dazu verwendet, den Abschlusssaldo nach einer Transaktion zu speichern. Jede Geschäftstransaktion hat einen einzelnen Einfügevorgang in die Tabelle durchgeführt.
Ursprüngliche Tabellendefinition
Bei der ursprünglichen Tabellendefinition sind übermäßige Latchkonflikte im gruppierten Index „pk_table1“ aufgetreten:
create table table1
(
TransactionID bigint not null,
UserID int not null,
SomeInt int not null
);
go
alter table table1
add constraint pk_table1
primary key clustered (TransactionID, UserID);
go
Hinweis
Die ursprünglichen Werte der Objektnamen in der Tabellendefinition wurden geändert.
Neu sortierte Indexdefinition
Die Neusortierung der Schlüsselspalten des Index mit UserID als führende Spalte im Primärschlüssel führte zu einer nahezu zufälligen Verteilung der Einfügevorgänge auf die Seiten. Die resultierende Verteilung war nicht zum 100 % zufällig, da nicht alle Benutzer gleichzeitig online sind, jedoch war die Verteilung ausreichend zufällig, um die übermäßigen Latchkonflikte zu beheben. Ein Nachteil der Neusortierung der Indexdefinition besteht darin, dass jegliche SELECT-Abfragen dieser Tabelle geändert werden müssen, sodass sie sowohl UserID als auch TransactionID als Gleichheitsprädikate verwenden.
Wichtig
Stellen Sie sicher, dass Sie alle Änderungen gründlich in einer Testumgebung testen, bevor Sie sie in einer Produktionsumgebung verwenden.
create table table1
(
TransactionID bigint not null,
UserID int not null,
SomeInt int not null
);
go
alter table table1
add constraint pk_table1
primary key clustered (UserID, TransactionID);
go
Verwenden eines Hashwerts als führende Spalte im Primärschlüssel
Die folgende Tabellendefinition kann dazu verwendet werden, ein Modulo zu generieren, das der Anzahl der CPU-Kerne entspricht. Der HashValue-Wert wird mithilfe des sequenziell steigenden TransactionID-Werts generiert, um eine gleichmäßige Verteilung auf die B-Struktur zu gewährleisten:
create table table1
(
TransactionID bigint not null,
UserID int not null,
SomeInt int not null
);
go
-- Consider using bulk loading techniques to speed it up
ALTER TABLE table1
ADD [HashValue] AS (CONVERT([tinyint], abs([TransactionID])%(32))) PERSISTED NOT NULL
alter table table1
add constraint pk_table1
primary key clustered (HashValue, TransactionID, UserID);
go
Option: Verwenden einer GUID als führende Schlüsselspalte des Index
Wenn keine natürliche Trennung vorliegt, kann eine GUID-Spalte als führende Schlüsselspalte des Index verwendet werden, um die gleichmäßige Verteilung der Einfügungen sicherzustellen. Die Verwendung der GUID als führende Spalte im Indexschlüsselansatz ermöglicht zwar die Partitionierung anderer Features, jedoch kann dieses Verfahren auch potenzielle Nachteile mit mehr Seitenteilungen, schlechter physischer Sortierung und niedriger Seitendichte mit sich bringen.
Hinweis
Die Verwendung von GUIDs als führende Schlüsselspalten von Indizes ist ein umstrittenes Thema. Eine ausführliche Erörterung der Vor- und Nachteile wird in diesem Artikel nicht behandelt.
Verwenden der Hashpartitionierung mit einer berechneten Spalte
Die Tabellenpartitionierung in SQL Server kann dazu verwendet werden, übermäßige Latchkonflikte zu vermeiden. Das Erstellen eines Hashpartitionierungsschemas mit einer berechneten Spalte für eine partitionierte Tabelle ist ein gängiger Ansatz, der mit den folgenden Schritten durchgeführt wird:
Erstellen Sie eine neue Dateigruppe, oder verwenden Sie eine vorhandene Dateigruppe zum Speichern der Partitionen.
Wenn Sie eine neue Dateigruppe verwenden, sollten Sie die einzelnen Dateien gleichmäßig auf die LUNs (logische Gerätenummer) verteilen. Achten Sie dabei darauf, dass Sie ein optimales Layout verwenden. Wenn das Zugriffsmuster eine hohe Anzahl von Einfügungen involviert, sollten Sie sicherstellen, dass Sie eine Anzahl von Dateien erstellen, die mit der Anzahl der physischen CPU-Kerne im SQL Server-Computer übereinstimmt.
Verwenden Sie den Befehl CREATE PARTITION FUNCTION, um die Tabellen in X Partitionen zu unterteilen, wobei X der Anzahl der physischen CPU-Kerne im SQL Server-Computer entspricht. (Mindestens 32 Partitionen)
Hinweis
Eine 1:1-Übereinstimmung der Anzahl der Partitionen und der Anzahl der CPU-Kerne ist nicht immer notwendig. In vielen Fällen kann eine Anzahl verwendet werden, die unter der Anzahl der CPU-Kerne liegt. Die Verwendung von mehr Partitionen kann zu Mehraufwand für Abfragen führen, die alle Partitionen durchsuchen müssen. In diesen Fällen sind weniger Partitionen hilfreich. In Tests von 64 und 128 logischen CPU-Systemen mit echten Kundenarbeitsauslastungen hat das SQLCAT festgestellt, dass 32 Partitionen ausreichen, um übermäßige Latchkonflikte zu lösen und Skalierungsziele zu erreichen. Letztendlich sollte die ideale Anzahl der Partitionen mithilfe von Tests bestimmt werden.
Verwenden Sie den Befehl CREATE PARTITION SCHEME:
- Binden Sie die Partitionsfunktion an die Dateigruppen.
- Fügen Sie eine Hashspalte vom Typ „tinyint“ oder „smallint“ zur Tabelle hinzu.
- Berechnen Sie eine gute Hashverteilung. Verwenden Sie beispielsweise Hashbytes mit einem Modulo oder binary_checksum-Wert.
Sie können das folgende Beispielskript entsprechend Ihrer Implementierung anpassen:
--Create the partition scheme and function, align this to the number of CPU cores 1:1 up to 32 core computer
-- so for below this is aligned to 16 core system
CREATE PARTITION FUNCTION [pf_hash16] (tinyint) AS RANGE LEFT FOR VALUES
(0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15);
CREATE PARTITION SCHEME [ps_hash16] AS PARTITION [pf_hash16] ALL TO ( [ALL_DATA] );
-- Add the computed column to the existing table (this is an OFFLINE operation)
-- Consider using bulk loading techniques to speed it up
ALTER TABLE [dbo].[latch_contention_table]
ADD [HashValue] AS (CONVERT([tinyint], abs(binary_checksum([hash_col])%(16)),(0))) PERSISTED NOT NULL;
--Create the index on the new partitioning scheme
CREATE UNIQUE CLUSTERED INDEX [IX_Transaction_ID]
ON [dbo].[latch_contention_table]([T_ID] ASC, [HashValue])
ON ps_hash16(HashValue);
Dieses Skript kann zur Hashpartitionierung einer Tabelle verwendet werden, die Probleme aufgrund von Konflikten beim Einfügen der letzten/nachstehenden Seite aufweist. Mit diesem Verfahren wird der Konflikt aus der letzten Seite verschoben, indem die Tabelle partitioniert und die Einfügevorgänge auf die Tabellenpartitionen mit einer Modulo-Berechnung des Hashwerts verteilt werden.
Ergebnisse der Hashpartitionierung mit einer berechneten Spalte
Wie im folgenden Diagramm gezeigt wird der Konflikt durch dieses Verfahren aus der letzten Seite verschoben, indem der Index für die Hashfunktion neu erstellt und so viele Partitionen erstellt werden, wie physische CPU-Kerne im SQL Server-Computer vorhanden sind. Die Einfügevorgänge werden weiterhin am Ende des logischen Bereichs (ein sequenziell steigender Wert) eingefügt, jedoch stellt die Modulo-Berechnung des Hashwerts sicher, dass die Einfügevorgänge auf die verschiedenen B-Strukturen verteilt werden, wodurch der Engpass gemindert wird. Dies wird in den folgenden Abbildungen veranschaulicht:
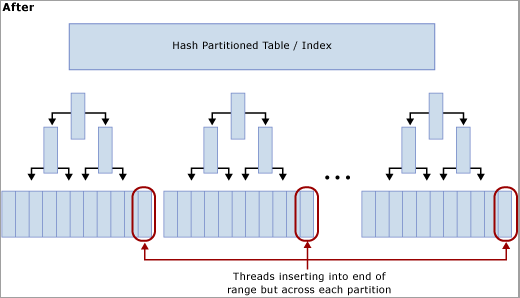
Nachteile der Hashpartitionierung
Zwar kann die Hashpartitionierung Konflikte bei Einfügungen beheben, jedoch gibt es einige Nachteile, die Sie bei der Entscheidung berücksichtigen sollten, ob Sie dieses Verfahren verwenden möchten:
SELECT-Abfragen müssen in den meisten Fällen angepasst werden, sodass sie die Hashpartition im Prädikat enthalten und zu einem Abfrageplan führen, der keine Partitionsentfernung bereitstellt, wenn diese Abfragen ausgegeben werden. Im folgenden Screenshot wird ein schlechter Abfrageplan ohne Partitionsentfernung gezeigt, nachdem die Hashpartitionierung implementiert wurde.
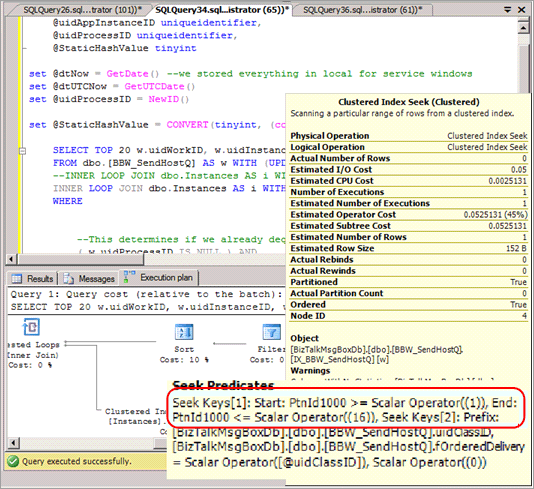
Dadurch entfällt die Möglichkeit, die Partitionsentfernung für bestimmte andere Abfragen wie bereichsbasierte Berichte zu verwenden.
Wenn eine Tabelle mit Hashpartitionierung mit einer anderen Tabelle verknüpft wird, um die Partitionsentfernung zu erzielen, muss die Hashpartitionierung für die zweite Tabelle mit dem gleichen Schlüssel durchgeführt werden. Außerdem sollte der Hashschlüssel ein Teil der Verknüpfungskriterien sein.
Die Hashpartitionierung verhindert die Verwendung der Partitionierung für andere Verwaltungsfeatures wie die Archivierung mit gleitenden Fenstern und die Partitionswechselfunktion.
Die Hashpartitionierung ist eine effektive Strategie zum Mindern übermäßiger Latchkonflikte, da der allgemeine Systemdurchsatz erhöht wird, indem Konflikte bei Einfügungen gelöst werden. Aufgrund der Nachteile handelt es sich für einige Zugriffsmuster möglicherweise nicht um die beste Lösung.
Zusammenfassung der Verfahren zum Beheben von Latchkonflikten
In den folgenden zwei Abschnitten finden Sie eine Zusammenfassung der Verfahren, die zur Behandlung von übermäßigen Latchkonflikten verwendet werden können:
Nicht sequenzieller Schlüssel/Index
Vorteile:
- Ermöglicht die Verwendung anderer Partitionierungsfeatures wie die Archivierung von Daten mithilfe eines Schemas mit gleitenden Fenstern oder die Partitionswechselfunktion
Nachteile:
- Es treten möglicherweise Herausforderungen bei der Auswahl eines Schlüssels/Index auf, um immer eine „nahezu“ gleichmäßige Verteilung der Einfügungen zu gewährleisten.
- Die GUID als führende Spalte kann dazu verwendet werden, die gleichmäßige Verteilung zu gewährleisten. Dabei besteht der Nachteil, dass dies zu übermäßigen Seitenteilungsvorgängen führen kann.
- Zufällige Einfügungen in die B-Struktur kann zu übermäßigen Seitenteilungsvorgängen führen, was wiederum zu Latchkonflikten in Seiten führt, die sich nicht am Ende der Struktur befinden.
Hashpartitionierung mit einer berechneten Spalte
Vorteile:
- Transparenz für Einfügungen
Nachteile:
- Die Partitionierung kann nicht für beabsichtigte Verwaltungsfeatures wie die Archivierung von Daten mithilfe von Partitionswechseloptionen verwendet werden.
- Dieser Ansatz kann zu Partitionsentfernungsproblemen bei Abfragen führen. Dies umfasst einzelne und bereichsbasierte SELECT-/UPDATE-Abfragen und Abfragen, die eine Verknüpfung durchführen.
- Das Hinzufügen einer persistierten berechneten Spalte ist ein Offlinevorgang.
Tipp
Informationen zu weiteren Verfahren finden Sie im Blogbeitrag PAGELATCH_EX-Konflikt bei Wartevorgängen und vielen Einfügungen.
Exemplarische Vorgehensweise: Diagnostizieren eines Latchkonflikts
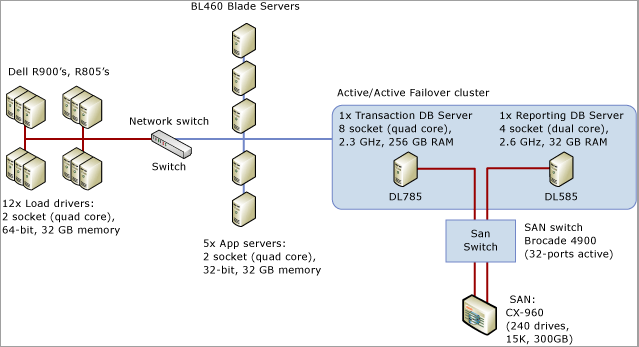
In dieser folgenden exemplarischen Vorgehensweise werden die in Diagnose von SQL Server-Latchkonflikten und Behandeln von Latchkonflikten für verschiedene Tabellenmuster beschriebenen Tools und Verfahren verwendet, um ein Problem in einem realen Szenario zu lösen. In diesem Szenario wird ein Kundenbindungsprojekt zum Durchführen von Auslastungstests für ein POS-System beschrieben, das etwa 8.000 Filialen simuliert hat, die Transaktionen mit einer SQL Server-Anwendung durchführen, die auf einem System mit 8 Sockets, 32 physischen CPU-Kernen und 256 GB Arbeitsspeicher ausgeführt wird.
Auf der folgenden Abbildung wird die Hardware veranschaulicht, die zum Testen des POS-Systems verwendet wurde:
Symptom: Übermäßige Latches
In diesem Fall wurden hohe Wartezeiten für PAGELATCH_EX-Latches festgestellt, die in der Regel mit einem durchschnittlichen Wert von mehr als 1 ms als hoch gelten. Im Szenario wurden Wartezeiten über 20 ms festgestellt.
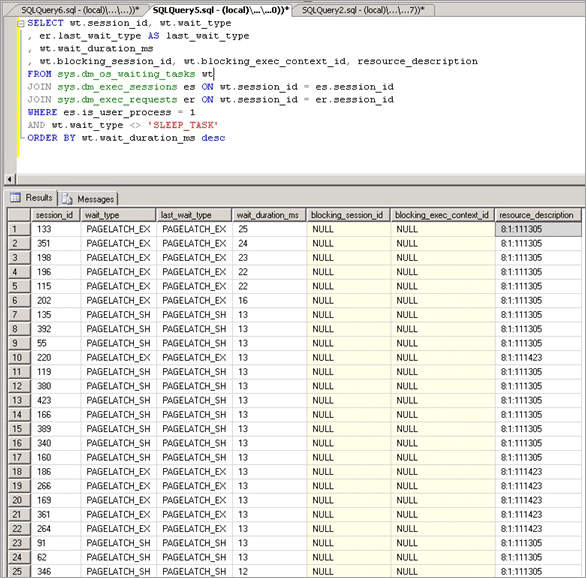
Nachdem bestätigt wurde, dass die Latchkonflikte problematisch waren, musste die Ursache der Latchkonflikte ermittelt werden.
Isolieren des Objekts als Ursache der Latchkonflikte
Im folgenden Skript wird die resource_description-Spalte verwendet, um zu isolieren, welcher Index den PAGELATCH_EX-Konflikt verursacht hat:
Hinweis
Die von diesem Skript zurückgegebene resource_description-Spalte stellt die Ressourcenbeschreibung im Format <DatabaseID,FileID,PageID> bereit. Der Name der Datenbank, die dem DatabaseID-Wert zugeordnet ist, kann durch Übergeben des DatabaseID-Werts an die DB_NAME()-Funktion ermittelt werden.
SELECT wt.session_id, wt.wait_type, wt.wait_duration_ms
, s.name AS schema_name
, o.name AS object_name
, i.name AS index_name
FROM sys.dm_os_buffer_descriptors bd
JOIN (
SELECT *
--resource_description
, CHARINDEX(':', resource_description) AS file_index
, CHARINDEX(':', resource_description, CHARINDEX(':', resource_description)+1) AS page_index
, resource_description AS rd
FROM sys.dm_os_waiting_tasks wt
WHERE wait_type LIKE 'PAGELATCH%'
) AS wt
ON bd.database_id = SUBSTRING(wt.rd, 0, wt.file_index)
AND bd.file_id = SUBSTRING(wt.rd, wt.file_index+1, 1) --wt.page_index)
AND bd.page_id = SUBSTRING(wt.rd, wt.page_index+1, LEN(wt.rd))
JOIN sys.allocation_units au ON bd.allocation_unit_id = au.allocation_unit_id
JOIN sys.partitions p ON au.container_id = p.partition_id
JOIN sys.indexes i ON p.index_id = i.index_id AND p.object_id = i.object_id
JOIN sys.objects o ON i.object_id = o.object_id
JOIN sys.schemas s ON o.schema_id = s.schema_id
order by wt.wait_duration_ms desc;
Wie hier gezeigt liegt der Konflikt bei der Tabelle LATCHTEST mit dem Indexnamen CIX_LATCHTEST vor. Beachten Sie, dass die Namen zur Anonymisierung der Arbeitsauslastung geändert wurden.
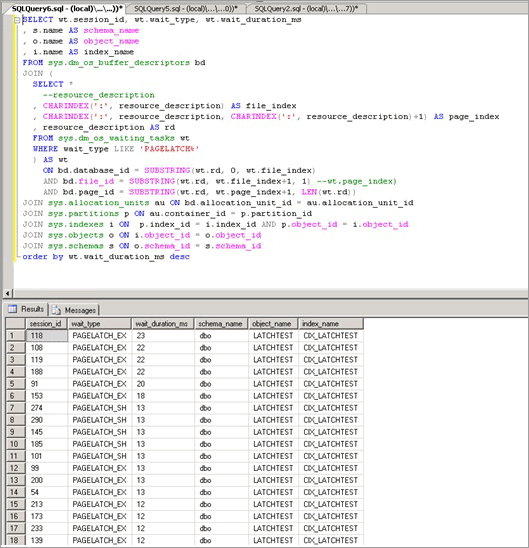
Ein erweitertes Skript, das wiederholt Abfragen durchführt und eine temporäre Tabelle verwendet, um die Gesamtwartezeit über einen konfigurierbaren Zeitraum zu ermitteln, finden Sie im Anhang unter Abfragen von Pufferdeskriptoren zum Ermitteln von Objekten als Ursache für Latchkonflikte.
Alternatives Verfahren zum Isolieren der Ursache der Latchkonflikte
Manchmal ist es unpraktisch, sys.dm_os_buffer_descriptors abzufragen. Wenn der für das System und den Pufferpool verfügbare Arbeitsspeicher steigt, steigt auch die erforderliche Zeit zum Ausführen dieser DMV. Auf einem System mit 256 GB Arbeitsspeicher kann das Ausführen dieser DMV bis zu 10 Minuten oder länger dauern. Es gibt auch ein alternatives Verfahren, das im Folgenden grob beschrieben und mit einer anderen Arbeitsauslastung veranschaulicht wird:
Fragen Sie die aktuell wartenden Tasks mithilfe des Skripts Abfragen von „sys.dm_os_waiting_tasks“ nach der Wartezeit.
Identifizieren Sie die Schlüsselseite, bei dem ein Konflikt vorliegt, der auftritt, wenn mehrere Threads dieselbe Seite beanspruchen möchten. In diesem Beispiel möchten die Threads, die den Einfügevorgang durchführen, die nachstehende Seite in der B-Struktur beanspruchen, und sie warten, bis sie einen EX-Latch abrufen können. Dies wird vom resource_description-Wert in der ersten Abfrage angegeben, in diesem Beispiel handelt es sich um den Wert „8:1:111305“.
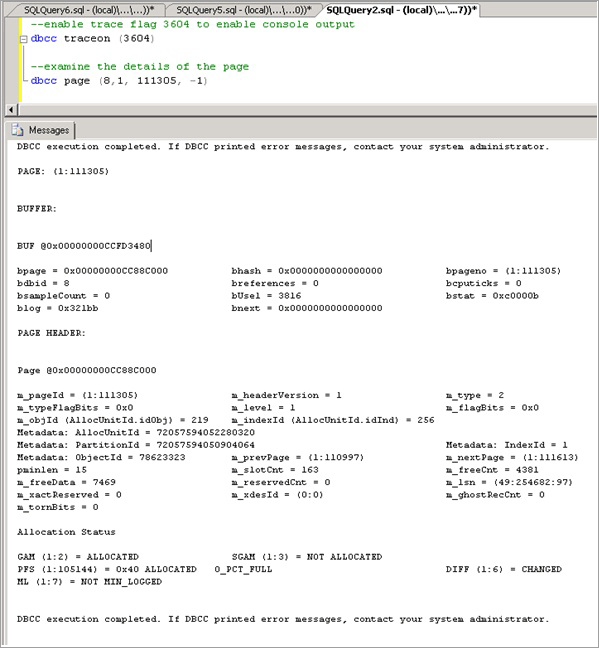
Aktivieren Sie das Ablaufverfolgungsflag 3604, das weitere Informationen über die Seite über DBCC PAGE mit der folgenden Syntax bereitstellt. Ersetzen Sie den Wert in den Klammern durch den Wert, den Sie resource_descrition entnommen haben:
--enable trace flag 3604 to enable console output dbcc traceon (3604); --examine the details of the page dbcc page (8,1, 111305, -1);Untersuchen Sie die DBCC-Ausgabe. Sie sollten einen zugehörigen ObjectID-Wert in den Metadaten finden. Im Beispiel wurde der Wert „78623323“ ermittelt.
Sie können nun den folgenden Befehl ausführen, um den Namen des Objekts zu ermitteln, das den Konflikt verursacht. Dabei handelt es sich wie erwartet um LATCHTEST.
Hinweis
Stellen Sie sicher, dass Sie sich im richtigen Datenbankkontext befinden, da die Abfrage sonst NULL zurückgibt.
--get object name select OBJECT_NAME (78623323);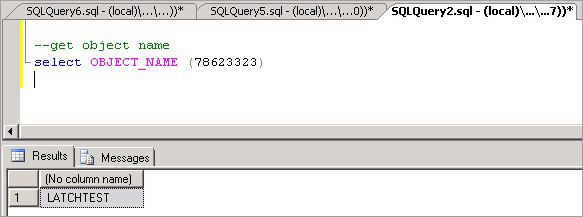
Zusammenfassung und Ergebnisse
Mithilfe des oben genannten Verfahrens konnten Sie bestätigen, dass der Konflikt bei einem gruppierten Index mit einem sequenziell steigenden Schlüsselwert in der Tabelle vorliegt, die bei weitem die höchste Anzahl an Einfügungen empfangen hat. Diese Art von Konflikt ist für Indizes mit sequenziell steigendem Schlüsselwert (z. B. ein Datetime-, Identity- oder von der Anwendung generierter transactionID-Wert) nicht ungewöhnlich.
Zum Lösen dieses Problems wurde die Hashpartitionierung mit einer berechneten Spalte verwendet, wodurch eine Leistungsverbesserung von 690 % erzielt wurde. In der folgenden Tabelle wird die Leistung der Anwendung vor und nach Implementierung der Hashpartitionierung mit einer berechneten Spalte zusammengefasst. Die CPU-Auslastung steigt erwartungsgemäß dem Durchsatz entsprechend an, nachdem der Latchkonfliktengpass entfernt wurde:
| Verbrauchsberechnung | Vor der Hashpartitionierung | Nach der Hashpartitionierung |
|---|---|---|
| Geschäftstransaktionen/Sekunde | 36 | 249 |
| Durchschnittliche Wartezeit für Seitenlatches | 36 Millisekunden | 0,6 Millisekunden |
| Latchwartevorgänge/Sekunde | 9.562 | 2\.873 |
| SQL-Prozessorzeit | 24 % | 78 % |
| SQL-Batchanforderungen/Sekunde | 12.368 | 47.045 |
Wie Sie der obigen Tabelle entnehmen können, kann die Identifizierung und Lösung von Leistungsproblemen, die von übermäßigen Seitenlatchkonflikten verursacht werden, sich positiv auf die Gesamtleistung einer Anwendung auswirken.
Anhang: Alternative Technik
Eine mögliche Strategie zum Vermeiden übermäßiger Seitenlatchkonflikte besteht darin, Zeilen mit einer CHAR-Spalte aufzufüllen, um sicherzustellen, dass jede Zeile eine vollständige Seite verwendet. Diese Strategie ist eine Option, wenn die Gesamtgröße der Daten klein ist und Sie EX-Seitenlatchkonflikte beheben müssen, die durch eine Kombination der folgenden Faktoren verursacht werden:
- Kleine Zeilengröße
- Flache B-Struktur
- Zugriffsmuster mit vielen zufälligen INSERT-, SELECT-, UPDATE- und DELETE-Vorgängen
- Kleine Tabellen (z. B. temporäre Warteschlangentabellen)
Durch Auffüllen der Zeilen, um eine gesamte Seite zu beanspruchen, muss SQL zusätzliche Seiten zuordnen, wodurch mehr Seiten für Einfügungen verfügbar werden und die Anzahl der EX-Seitenlatchkonflikte verringert wird.
Auffüllen von Zeilen zum Sicherstellen der Beanspruchung einer ganzen Seite
Ein Skript, das dem folgenden ähnelt, kann zum Auffüllen der Zeilen verwendet werden, damit sie eine ganze Seite beanspruchen:
ALTER TABLE mytable ADD Padding CHAR(5000) NOT NULL DEFAULT ('X');
Hinweis
Verwenden Sie den kleinsten möglichen CHAR-Wert, der eine Zeile pro Seite erzwingt, um die zusätzliche CPU-Auslastung für den Füllwert und den zusätzlichen erforderlichen Speicherplatz zum Protokollieren der Zeile zu reduzieren. In einem Hochleistungssystem zählt jedes Byte.
Dieses Verfahren wird der Vollständigkeit halber erläutert. In der Praxis hat das SQLCAT dieses Verfahren nur für eine kleine Tabelle mit 10.000 Zeilen in einem einzelnen Leistungstestprojekt verwendet. Dieses Verfahren ist nur begrenzt anwendbar, da es die Arbeitsspeicherauslastung von SQL Server für große Tabellen erhöht und zu Nicht-Pufferlatchkonflikten auf Seiten führen kann, die sich nicht am Ende der Struktur befinden. Die zusätzliche Arbeitsspeicherauslastung kann eine erhebliche Einschränkung für die Anwendung dieses Verfahrens darstellen. Aufgrund der Menge des Arbeitsspeichers, der in einem modernen Server verfügbar ist, wird ein großer Anteil des Arbeitssatzes der OLTP-Arbeitsauslastungen in der Regel im Arbeitsspeicher gespeichert. Wenn das Dataset auf eine Größe erhöht wird, die nicht mehr in den Arbeitsspeicher passt, kommt es zu einem erheblichen Leistungsabfall. Daher kann dieses Verfahren nur für kleine Tabellen genutzt werden. Dieses Verfahren wird vom SQLCAT nicht für Szenarios verwendet, z. B. für Konflikte beim Einfügen der letzten/nachstehenden Seite bei großen Tabellen.
Wichtig
Das Einsetzen dieser Strategie kann zu einer großen Anzahl an Wartevorgängen für den Latchtyp ACCESS_METHODS_HOBT_VIRTUAL_ROOT führen, da diese Strategie zu einer großen Anzahl von Seitenteilungen in den Knoten der B-Struktur führen kann, die sich nicht am Ende der Struktur befinden. Wenn dies auftritt muss SQL Server SH-Latches in allen Ebenen gefolgt von EX-Latches auf Seiten in der B-Struktur abrufen, für die eine Seitenteilung möglich ist. Untersuchen Sie die DMV sys.dm_os_latch_stats auf eine hohe Anzahl von Wartevorgängen für den Latchtyp ACCESS_METHODS_HOBT_VIRTUAL_ROOT, nachdem Sie die Zeilen aufgefüllt haben.
Anhang: Skripts für SQL Server-Latchkonflikte
In diesem Abschnitt finden Sie Skripts für die Diagnose und Problembehandlung bei Latchkonflikten.
Abfragen von sys.dm_os_waiting_tasks nach Sitzungs-ID
Das folgende Beispielskript fragt die DMV sys.dm_os_waiting_tasks ab und gibt Latchwartevorgänge sortiert nach der Sitzungs-ID zurück:
-- WAITING TASKS ordered by session_id
SELECT wt.session_id, wt.wait_type
, er.last_wait_type AS last_wait_type
, wt.wait_duration_ms
, wt.blocking_session_id, wt.blocking_exec_context_id,
resource_description
FROM sys.dm_os_waiting_tasks wt
JOIN sys.dm_exec_sessions es ON wt.session_id = es.session_id
JOIN sys.dm_exec_requests er ON wt.session_id = er.session_id
WHERE es.is_user_process = 1
AND wt.wait_type <> 'SLEEP_TASK'
ORDER BY session_id;
Abfragen von sys.dm_os_waiting_tasks nach Wartezeit
Das folgende Beispielskript fragt die DMV sys.dm_os_waiting_tasks ab und gibt Latchwartevorgänge sortiert nach der Wartedauer zurück:
-- WAITING TASKS ordered by wait_duration_ms
SELECT wt.session_id, wt.wait_type
, er.last_wait_type AS last_wait_type
, wt.wait_duration_ms
, wt.blocking_session_id, wt.blocking_exec_context_id, resource_description
FROM sys.dm_os_waiting_tasks wt
JOIN sys.dm_exec_sessions es ON wt.session_id = es.session_id
JOIN sys.dm_exec_requests er ON wt.session_id = er.session_id
WHERE es.is_user_process = 1
AND wt.wait_type <> 'SLEEP_TASK'
ORDER BY wt.wait_duration_ms desc;
Berechnen der Wartezeiten in einem Zeitraum
Das folgende Skript berechnet Latchwartevorgänge über einen Zeitraum und gibt diese zurück:
/* Snapshot the current wait stats and store so that this can be compared over a time period
Return the statistics between this point in time and the last collection point in time.
**This data is maintained in tempdb so the connection must persist between each execution**
**alternatively this could be modified to use a persisted table in tempdb. if that
is changed code should be included to clean up the table at some point.**
*/
use tempdb
go
declare @current_snap_time datetime;
declare @previous_snap_time datetime;
set @current_snap_time = GETDATE();
if not exists(select name from tempdb.sys.sysobjects where name like '#_wait_stats%')
create table #_wait_stats
(
wait_type varchar(128)
,waiting_tasks_count bigint
,wait_time_ms bigint
,avg_wait_time_ms int
,max_wait_time_ms bigint
,signal_wait_time_ms bigint
,avg_signal_wait_time int
,snap_time datetime
);
insert into #_wait_stats (
wait_type
,waiting_tasks_count
,wait_time_ms
,max_wait_time_ms
,signal_wait_time_ms
,snap_time
)
select
wait_type
,waiting_tasks_count
,wait_time_ms
,max_wait_time_ms
,signal_wait_time_ms
,getdate()
from sys.dm_os_wait_stats;
--get the previous collection point
select top 1 @previous_snap_time = snap_time from #_wait_stats
where snap_time < (select max(snap_time) from #_wait_stats)
order by snap_time desc;
--get delta in the wait stats
select top 10
s.wait_type
, (e.waiting_tasks_count - s.waiting_tasks_count) as [waiting_tasks_count]
, (e.wait_time_ms - s.wait_time_ms) as [wait_time_ms]
, (e.wait_time_ms - s.wait_time_ms)/((e.waiting_tasks_count - s.waiting_tasks_count)) as [avg_wait_time_ms]
, (e.max_wait_time_ms) as [max_wait_time_ms]
, (e.signal_wait_time_ms - s.signal_wait_time_ms) as [signal_wait_time_ms]
, (e.signal_wait_time_ms - s.signal_wait_time_ms)/((e.waiting_tasks_count - s.waiting_tasks_count)) as [avg_signal_time_ms]
, s.snap_time as [start_time]
, e.snap_time as [end_time]
, DATEDIFF(ss, s.snap_time, e.snap_time) as [seconds_in_sample]
from #_wait_stats e
inner join (
select * from #_wait_stats
where snap_time = @previous_snap_time
) s on (s.wait_type = e.wait_type)
where
e.snap_time = @current_snap_time
and s.snap_time = @previous_snap_time
and e.wait_time_ms > 0
and (e.waiting_tasks_count - s.waiting_tasks_count) > 0
and e.wait_type NOT IN ('LAZYWRITER_SLEEP', 'SQLTRACE_BUFFER_FLUSH'
, 'SOS_SCHEDULER_YIELD','DBMIRRORING_CMD', 'BROKER_TASK_STOP'
, 'CLR_AUTO_EVENT', 'BROKER_RECEIVE_WAITFOR', 'WAITFOR'
, 'SLEEP_TASK', 'REQUEST_FOR_DEADLOCK_SEARCH', 'XE_TIMER_EVENT'
, 'FT_IFTS_SCHEDULER_IDLE_WAIT', 'BROKER_TO_FLUSH', 'XE_DISPATCHER_WAIT'
, 'SQLTRACE_INCREMENTAL_FLUSH_SLEEP')
order by (e.wait_time_ms - s.wait_time_ms) desc ;
--clean up table
delete from #_wait_stats
where snap_time = @previous_snap_time;
Abfragen von Pufferdeskriptoren zum Ermitteln von Objekten als Ursache für Latchkonflikte
Das folgende Skript gibt Pufferdeskriptoren zurück, um zu ermitteln, welche Objekte im Zusammenhang mit den längsten Latchwartezeiten stehen.
IF EXISTS (SELECT * FROM tempdb.sys.objects WHERE [name] like '#WaitResources%') DROP TABLE #WaitResources;
CREATE TABLE #WaitResources (session_id INT, wait_type NVARCHAR(1000), wait_duration_ms INT,
resource_description sysname NULL, db_name NVARCHAR(1000), schema_name NVARCHAR(1000),
object_name NVARCHAR(1000), index_name NVARCHAR(1000));
GO
declare @WaitDelay varchar(16), @Counter INT, @MaxCount INT, @Counter2 INT
SELECT @Counter = 0, @MaxCount = 600, @WaitDelay = '00:00:00.100'-- 600x.1=60 seconds
SET NOCOUNT ON;
WHILE @Counter < @MaxCount
BEGIN
INSERT INTO #WaitResources(session_id, wait_type, wait_duration_ms, resource_description)--, db_name, schema_name, object_name, index_name)
SELECT wt.session_id,
wt.wait_type,
wt.wait_duration_ms,
wt.resource_description
FROM sys.dm_os_waiting_tasks wt
WHERE wt.wait_type LIKE 'PAGELATCH%' AND wt.session_id <> @@SPID
--select * from sys.dm_os_buffer_descriptors
SET @Counter = @Counter + 1;
WAITFOR DELAY @WaitDelay;
END;
--select * from #WaitResources;
update #WaitResources
set db_name = DB_NAME(bd.database_id),
schema_name = s.name,
object_name = o.name,
index_name = i.name
FROM #WaitResources wt
JOIN sys.dm_os_buffer_descriptors bd
ON bd.database_id = SUBSTRING(wt.resource_description, 0, CHARINDEX(':', wt.resource_description))
AND bd.file_id = SUBSTRING(wt.resource_description, CHARINDEX(':', wt.resource_description) + 1, CHARINDEX(':', wt.resource_description, CHARINDEX(':', wt.resource_description) +1 ) - CHARINDEX(':', wt.resource_description) - 1)
AND bd.page_id = SUBSTRING(wt.resource_description, CHARINDEX(':', wt.resource_description, CHARINDEX(':', wt.resource_description) +1 ) + 1, LEN(wt.resource_description) + 1)
--AND wt.file_index > 0 AND wt.page_index > 0
JOIN sys.allocation_units au ON bd.allocation_unit_id = AU.allocation_unit_id
JOIN sys.partitions p ON au.container_id = p.partition_id
JOIN sys.indexes i ON p.index_id = i.index_id AND p.object_id = i.object_id
JOIN sys.objects o ON i.object_id = o.object_id
JOIN sys.schemas s ON o.schema_id = s.schema_id;
select * from #WaitResources order by wait_duration_ms desc;
GO
/*
--Other views of the same information
SELECT wait_type, db_name, schema_name, object_name, index_name, SUM(wait_duration_ms) [total_wait_duration_ms] FROM #WaitResources
GROUP BY wait_type, db_name, schema_name, object_name, index_name;
SELECT session_id, wait_type, db_name, schema_name, object_name, index_name, SUM(wait_duration_ms) [total_wait_duration_ms] FROM #WaitResources
GROUP BY session_id, wait_type, db_name, schema_name, object_name, index_name;
*/
--SELECT * FROM #WaitResources
--DROP TABLE #WaitResources;
Skript für die Hashpartitionierung
Die Verwendung dieses Skripts wurde unter Verwenden der Hashpartitionierung mit einer berechneten Spalte beschrieben. Es sollte gemäß Ihrer Implementierung angepasst werden.
--Create the partition scheme and function, align this to the number of CPU cores 1:1 up to 32 core computer
-- so for below this is aligned to 16 core system
CREATE PARTITION FUNCTION [pf_hash16] (tinyint) AS RANGE LEFT FOR VALUES
(0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15);
CREATE PARTITION SCHEME [ps_hash16] AS PARTITION [pf_hash16] ALL TO ( [ALL_DATA] );
-- Add the computed column to the existing table (this is an OFFLINE operation)
-- Consider using bulk loading techniques to speed it up
ALTER TABLE [dbo].[latch_contention_table]
ADD [HashValue] AS (CONVERT([tinyint], abs(binary_checksum([hash_col])%(16)),(0))) PERSISTED NOT NULL;
--Create the index on the new partitioning scheme
CREATE UNIQUE CLUSTERED INDEX [IX_Transaction_ID]
ON [dbo].[latch_contention_table]([T_ID] ASC, [HashValue])
ON ps_hash16(HashValue);
Nächste Schritte
Weitere Informationen über Tools für die Leistungsüberwachung finden Sie unter Tools für die Leistungsüberwachung und -optimierung.