Tutorial: Erstellen eines Clusteringmodells in R mit SQL Machine Learning
Gilt für: ![]() SQL Server 2016 (13.x) und höher
SQL Server 2016 (13.x) und höher ![]() Azure SQL Managed Instance
Azure SQL Managed Instance
Im dritten Teil dieser vierteiligen Tutorialreihe erstellen Sie ein K-Means-Modell in R, um das Clustering durchzuführen. Im nächsten Teil dieser Reihe stellen Sie dann dieses Modell in einer Datenbank mit SQL Server Machine Learning Services oder in Big Data-Clustern bereit.
Im dritten Teil dieser vierteiligen Tutorialreihe erstellen Sie ein K-Means-Modell in R, um das Clustering durchzuführen. Im nächsten Teil dieser Reihe stellen Sie dann dieses Modell in einer Datenbank mit SQL Server Machine Learning Services bereit.
Im dritten Teil dieser vierteiligen Tutorialreihe erstellen Sie ein K-Means-Modell in R, um das Clustering durchzuführen. Im nächsten Teil dieser Reihe stellen Sie dann dieses Modell in einer Datenbank mit SQL Server R Services bereit.
Im dritten Teil dieser vierteiligen Tutorialreihe erstellen Sie ein K-Means-Modell in R, um das Clustering durchzuführen. Im nächsten Teil dieser Reihe stellen Sie dieses Modell in einer Datenbank mit Machine Learning Services in Azure SQL Managed Instance bereit.
In diesem Artikel lernen Sie Folgendes:
- Definieren der Anzahl der Cluster für einen K-Means-Algorithmus
- Durchführen des Clustering
- Analysieren der Ergebnisse
In Teil 1 haben Sie die Voraussetzungen installiert und die Beispieldatenbank wiederhergestellt.
In Teil 2 haben Sie gelernt, wie Sie die Daten aus einer Datenbank für das Clustering vorbereiten.
In Teil 4 erfahren Sie, wie Sie eine gespeicherte Prozedur in einer Datenbank erstellen, die Clustering auf der Grundlage neuer Daten in R durchführen kann.
Voraussetzungen
- In Teil 3 dieser Tutorialreihe wird vorausgesetzt, dass Sie die Voraussetzungen für Teil 1 erfüllt und die Schritte in Teil 2 durchgeführt haben.
Definieren der Anzahl der Cluster
Für das Clustering Ihrer Kundendaten verwenden Sie den K-Means-Clusteringalgorithmus. Dies ist eine der einfachsten und bekanntesten Methoden zum Gruppieren von Daten. Weitere Informationen zum K-Means-Algorithmus finden Sie im Umfassenden Leitfaden zu K-Means-Clusteringalgorithmus.
Der Algorithmus akzeptiert zwei Eingaben: Die Daten selbst und eine vordefinierte Zahl „k“, die die Anzahl der zu generierenden Cluster darstellt. Die Ausgabe entspricht k Clustern mit den partitionierten Eingabedaten.
Verwenden Sie einen Plot aus der Abweichungsquadratsumme der enthaltenen Gruppen nach der Anzahl der extrahierten Cluster, um die Anzahl der zu verwendenden Cluster für den Algorithmus zu bestimmen. Die angemessene Anzahl der zu verwendenden Cluster befindet sich an der Knickstelle bzw. am „Ellenbogen“ des Plots.
# Determine number of clusters by using a plot of the within groups sum of squares,
# by number of clusters extracted.
wss <- (nrow(customer_data) - 1) * sum(apply(customer_data, 2, var))
for (i in 2:20)
wss[i] <- sum(kmeans(customer_data, centers = i)$withinss)
plot(1:20, wss, type = "b", xlab = "Number of Clusters", ylab = "Within groups sum of squares")
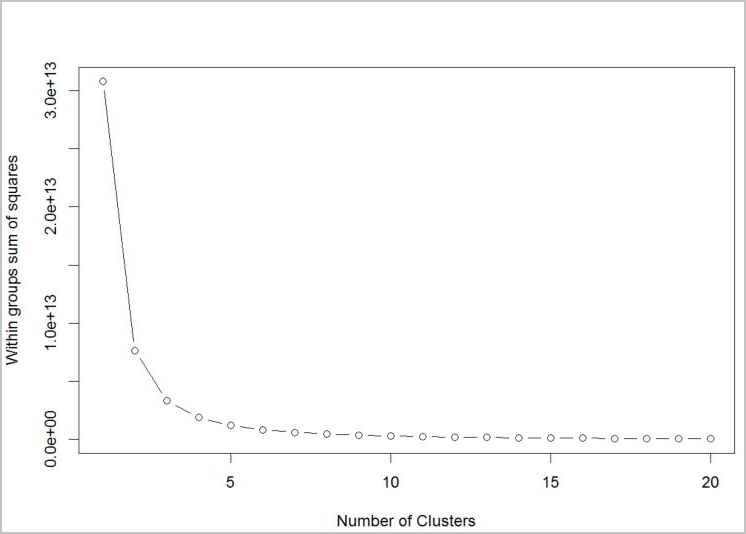
Aus diesem Graph geht k = 4 als geeigneter Wert hervor. Mit diesem k-Wert werden die Kunden in vier Cluster gruppiert.
Durchführen des Clustering
Im folgenden R-Skript verwenden Sie die Funktion kmeans, um Clustering auszuführen.
# Output table to hold the customer group mappings.
# Generate clusters using Kmeans and output key / cluster to a table
# called return_cluster
## create clustering model
clust <- kmeans(customer_data[,2:5],4)
## create clustering output for table
customer_cluster <- data.frame(cluster=clust$cluster,customer=customer_data$customer,orderRatio=customer_data$orderRatio,
itemsRatio=customer_data$itemsRatio,monetaryRatio=customer_data$monetaryRatio,frequency=customer_data$frequency)
## write cluster output to DB table
sqlSave(ch, customer_cluster, tablename = "return_cluster")
# Read the customer returns cluster table from the database
customer_cluster_check <- sqlFetch(ch, "return_cluster")
head(customer_cluster_check)
Analysieren der Ergebnisse
Nach Abschluss des K-Means-Clusterings muss das Ergebnis analysiert werden, um zu ermitteln, ob verwertbare Informationen vorliegen.
#Look at the clustering details to analyze results
clust[-1]
$centers
orderRatio itemsRatio monetaryRatio frequency
1 0.621835791 0.1701519 0.35510836 1.009025
2 0.074074074 0.0000000 0.05886575 2.363248
3 0.004807692 0.0000000 0.04618708 5.050481
4 0.000000000 0.0000000 0.00000000 0.000000
$totss
[1] 40191.83
$withinss
[1] 19867.791 215.714 660.784 0.000
$tot.withinss
[1] 20744.29
$betweenss
[1] 19447.54
$size
[1] 4543 702 416 31675
$iter
[1] 3
$ifault
[1] 0
Die vier Clusterdurchschnittswerte werden mittels der Variablen angegeben, die Sie in Teil 2 des Tutorials definiert haben:
- orderRatio = Retourenquote für Bestellungen (Gesamtzahl der teilweise oder vollständig zurückgegebenen Bestellungen im Vergleich zur Gesamtzahl der Bestellungen)
- itemsRatio = Retourenquote für Artikel (Gesamtzahl der zurückgegebenen Artikel im Vergleich zur Anzahl der gekauften Artikel)
- monetaryRatio = Rückzahlungsquote (Monetärer Gesamtbetrag der zurückgegebenen Artikel im Vergleich zum erworbenen Betrag)
- frequency = Häufigkeit der Retouren
Data Mining mit K-Means erfordert häufig weitere Analysen der Ergebnisse sowie weitere Schritte, um die einzelnen Cluster besser zu verstehen, kann jedoch gute Leads erzielen. Im Folgenden finden Sie Beispiele für die Interpretation dieser Ergebnisse:
- Beim ersten Cluster (dem größten Cluster) scheint es sich um eine Gruppe von inaktiven Kunden zu handeln. (Alle Werte sind null.)
- Cluster 3 scheint eine Gruppe mit erhöhtem Retournierverhalten zu sein.
Bereinigen von Ressourcen
Wenn Sie nicht mit diesem Tutorial fortfahren möchten, löschen Sie die Datenbank „tpcxbb_1gb“.
Nächste Schritte
In Teil 3 dieser Tutorialreihe haben Sie Folgendes gelernt:
- Definieren der Anzahl der Cluster für einen K-Means-Algorithmus
- Durchführen des Clustering
- Analysieren der Ergebnisse
Fahren Sie mit Teil 4 dieser Tutorialreihe fort, um das von Ihnen erstellte Machine Learning-Modell einzusetzen: