Verfügbarkeitsgruppen für SQL Server unter Linux
Gilt für: ![]() SQL Server – Linux
SQL Server – Linux
In diesem Artikel werden die Merkmale von Verfügbarkeitsgruppen unter Linux-basierten SQL Server-Installationen beschrieben. Außerdem werden die Unterschiede zwischen auf Linux-und Windows Server-Failoverclustern (WSFC) basierenden Tags behandelt. Siehe Übersicht über die Always On-Verfügbarkeitsgruppe für die Grundlagen von AGs, da sie unter Windows und Linux mit Ausnahme von WSFC gleich funktionieren.
Hinweis
In Verfügbarkeitsgruppen, die kein Windows Server Failover Clustering (WSFC) nutzen, z. B. schreibgeschützte Verfügbarkeitsgruppen oder Verfügbarkeitsgruppen unter Linux, zeigen Spalten in den Verfügbarkeitsgruppen-DMVs im Zusammenhang mit dem Cluster möglicherweise Daten zu einem internen Standardcluster an. Diese Spalten sind nur für die interne Verwendung vorgesehen und können ignoriert werden.
Im Allgemeinen entsprechen die Verfügbarkeitsgruppen unter SQL Server für Linux den WSFC-basierten Implementierungen. Das bedeutet, dass alle Einschränkungen und Features (mit einigen Ausnahmen) identisch sind. Die Hauptunterschiede bestehen in Folgendem:
- Microsoft Distributed Transaction Coordinator (MS DTC) wird unter Linux ab SQL Server 2017 CU 16 unterstützt. In Verfügbarkeitsgruppen unter Linux wird DTC jedoch noch nicht unterstützt. Wenn Ihre Anwendungen verteilte Transaktionen verwenden und eine Verfügbarkeitsgruppe benötigen, stellen Sie SQL Server unter Windows bereit.
- Für Linux-basierte Bereitstellungen, die Hochverfügbarkeit erfordern, verwenden Sie für das Clustering Pacemaker anstelle eines WSFC.
- Im Gegensatz zu den meisten Konfiguration für Verfügbarkeitsgruppen unter Windows (außer im Workgroupclusterszenario) ist Active Directory Domain Services (AD DS) für Pacemaker nicht erforderlich.
- Das Failover einer Verfügbarkeitsgruppe von einem Knoten auf einen anderen unterscheidet sich zwischen Linux und Windows.
- Bestimmte Einstellungen wie
required_synchronized_secondaries_to_commitkönnen unter Linux nur über Pacemaker geändert werden, während bei einer WSFC-basierten Installation Transact-SQL verwendet wird.
Anzahl der Replikate und Clusterknoten
Eine Verfügbarkeitsgruppe in der SQL Server Standard-Edition kann insgesamt über zwei Replikate verfügen: ein primäres Replikat und ein sekundäres Replikat, das nur zu Verfügbarkeitszwecken verwendet werden kann. Es kann nicht für andere Zwecke wie lesbare Abfragen verwendet werden. Eine Verfügbarkeitsgruppe in der SQL Server Enterprise-Edition kann insgesamt über bis zu neun Replikate verfügen: ein primäres Replikat und bis zu acht sekundäre Replikate, von denen bis zu drei (einschließlich des primären Replikats) synchron sein können. Wenn ein zugrunde liegender Cluster verwendet wird, können maximal 16 Knoten vorhanden sein, wenn Corosync beteiligt ist. Eine Verfügbarkeitsgruppe kann mit der SQL Server Enterprise-Edition neun von 16 Knoten umfassen und mit der SQL Server Standard-Edition zwei Knoten.
Für eine Konfiguration mit zwei Replikaten, für die ein automatisches Failover auf ein anderes Replikat möglich sein muss, muss unter Reine Konfigurationsreplikate und Quoren beschrieben ein Replikat verwendet werden, das ausschließlich für die Konfiguration konfiguriert ist. Reine Konfigurationsreplikate wurden in SQL Server 2017 (14.x) Cumulative Update 1 (CU 1) eingeführt. Diese Version sollte für die Konfiguration also als mindestens erforderliche Version festgelegt werden.
Wenn Pacemaker verwendet wird, muss die Software ordnungsgemäß konfiguriert werden, damit sie weiterhin ausgeführt wird. Das bedeutet, dass Quorum und Umgrenzung eines fehlgeschlagenen Knotens gemäß Pacemaker-Anforderungen zusätzlich zu anderen SQL Server-Anforderungen wie reinen Konfigurationsreplikaten ordnungsgemäß implementiert werden müssen.
Lesbare sekundäre Replikate werden nur mit der SQL Server Enterprise-Edition unterstützt.
Clustertyp und Failovermodus
In SQL Server 2017 (14.x) wurden Clustertypen für Verfügbarkeitsgruppen eingeführt. Für Linux gibt es zwei gültige Werte: External und None. Der Clustertyp „EXTERNAL“ bedeutet, dass Pacemaker unterhalb der Verfügbarkeitsgruppe verwendet wird. Wenn Sie den Clustertyp „EXTERNAL“ verwenden, muss auch der Failovermodus auf „External“ festgelegt werden (ebenfalls neu in SQL Server 2017 (14.x)). Das automatische Failover wird unterstützt, aber im Gegensatz zu einem WSFC wird der Failovermodus bei Verwendung von Pacemaker nicht automatisch auf „EXTERNAL“ festgelegt. Im Gegensatz zu einem WSFC wird der Pacemaker-Teil der Verfügbarkeitsgruppe nach der Konfiguration der Verfügbarkeitsgruppe erstellt.
Der Clustertyp „NONE“ bedeutet, dass Pacemaker nicht erforderlich ist und von der Verfügbarkeitsgruppe nicht verwendet wird. Auch wenn Pacemaker auf einem Server konfiguriert wird, werden Verfügbarkeitsgruppen nicht über Pacemaker angezeigt oder verwaltet, wenn der Clustertyp „NONE“ für eine Verfügbarkeitsgruppe festgelegt ist. Der Clustertyp „NONE“ unterstützt nur manuelles Failover von einem primären zu einem sekundären Replikat. Eine AG, die mit „None“ erstellt wurde, ist hauptsächlich auf Upgrades und die horizontale Leseskalierung ausgerichtet. Auch wenn es in Szenarien wie der Notfallwiederherstellung oder der lokalen Verfügbarkeit funktioniert, bei denen kein automatisches Failover erforderlich ist, wird es nicht empfohlen. Ohne Pacemaker ist der Listenerverlauf zudem komplexer.
Der Clustertyp wird in der SQL Serverdynamischen Verwaltungssicht (DMV)sys.availability_groups in den Spalten cluster_type und cluster_type_desc gespeichert.
required_synchronized_secondaries_to_commit
In SQL Server 2017 (14.x) ist nun die neue Einstellung required_synchronized_secondaries_to_commit vorhanden, die von Verfügbarkeitsgruppen verwendet wird. Über diese wird der Verfügbarkeitsgruppe die Anzahl der sekundären Replikate mitgeteilt, die auf das primäre Replikat abgestimmt sein müssen. Dadurch können beispielsweise das automatische Failover (nur bei Integration mit Pacemaker und dem Clustertyp „EXTERNAL“) ermöglicht und das Verhalten der Verfügbarkeit des Replikats gesteuert werden, wenn die richtige Anzahl sekundärer Replikate online oder offline ist. Weitere Informationen zu diesem Thema finden Sie unter Hochverfügbarkeit und Schutz von Daten für Verfügbarkeitsgruppenkonfigurationen. Der Wert required_synchronized_secondaries_to_commit wird standardmäßig festgelegt und von Pacemaker/SQL Serververwaltet. Sie können diesen Wert manuell überschreiben.
Die Kombination von required_synchronized_secondaries_to_commit und der neuen Sequenznummer (in sys.availability_groups gespeichert) informiert Pacemaker und SQL Server darüber, dass beispielsweise ein automatisches Failover möglich ist. In diesem Fall würde ein sekundäres Replikat die gleiche Sequenznummer wie das primäre Replikat aufweisen, was bedeutet, dass alle Konfigurationsinformationen auf dem neuesten Stand sind.
Für required_synchronized_secondaries_to_commit können drei Werte festgelegt werden: 0, 1 oder 2. Sie steuern, was geschieht, wenn ein Replikat nicht mehr verfügbar ist. Die Zahlen entsprechen der Anzahl von sekundären Replikaten, die mit dem primären Replikat synchronisiert werden müssen. Das Verhalten ist unter Linux wie folgt:
| Einstellung | Beschreibung |
|---|---|
0 |
Sekundäre Replikate müssen nicht mit dem primären Replikat synchronisiert sein. Wenn die sekundären Replikate jedoch nicht synchronisiert werden, wird kein automatisches Failover ausgeführt. |
1 |
Ein sekundäres Replikat muss mit dem primären Replikat synchronisiert sein. Ein automatisches Failover ist möglich. Die primäre Datenbank ist erst verfügbar, wenn ein sekundäres synchrones Replikat verfügbar ist. |
2 |
Beide sekundären Replikate in einer Verfügbarkeitsgruppenkonfiguration mit drei oder mehr Knoten müssen mit dem primären Replikat synchronisiert werden. Ein automatisches Failover ist möglich. |
required_synchronized_secondaries_to_commit steuert nicht nur das Verhalten von Failovern mit synchronen Replikaten, sondern auch den Datenverlust. Bei einem Wert von 1 oder 2 muss ein sekundäres Replikat immer synchronisiert werden, um Datenredundanz zu gewährleisten. Dies bedeutet, dass kein Datenverlust auftritt.
Verwenden Sie die folgende Syntax, um den Wert von required_synchronized_secondaries_to_commit zu ändern:
Hinweis
Das Ändern des Werts bewirkt, dass die Ressource neu gestartet wird. Es kommt zu einem kurzen Ausfall. Sie können diesen Ausfall nur vermeiden, indem Sie die Ressource so konfigurieren, dass sie vorübergehend nicht vom Cluster verwaltet wird.
Red Hat Enterprise Linux (RHEL) und Ubuntu
sudo pcs resource update <AGResourceName> required_synchronized_secondaries_to_commit=<value>
SUSE Linux Enterprise Server (SLES)
sudo crm resource param ms-<AGResourceName> set required_synchronized_secondaries_to_commit <value>
In diesem Beispiel ist <AGResourceName> der Name der für die AG konfigurierten Ressource und <value> ist 0, 1 oder 2. Wenn Sie den Standardzustand wiederherstellen möchten, dass Pacemaker den Parameter verwaltet, führen Sie die gleiche Anweisung ohne Wert (value) aus.
Ein automatisches Failover einer Verfügbarkeitsgruppe ist möglich, wenn die folgenden Bedingungen erfüllt sind:
- Das primäre und das sekundäre Replikat sind auf synchrone Datenverschiebung festgelegt.
- Das sekundäre Replikat weist den Status „Synchronisiert“ (keine Synchronisierung) auf, die beiden Replikate befinden sich also am selben Datenpunkt.
- Der Clustertyp ist auf „EXTERNAL“ festgelegt. Ein automatisches Failover ist mit dem Clustertyp „NONE“ nicht möglich.
- Der Wert
sequence_numberdes sekundären Replikats, das zum primären Replikat werden soll, weist die höchste Sequenznummer auf. Das bedeutet, dass dersequence_number-Wert des sekundären Replikats dem Wert des ursprünglichen primären Replikats entspricht.
Wenn diese Bedingungen erfüllt sind und der Server ausfällt, auf dem das primäre Replikat gehostet wird, wechselt die Verfügbarkeitsgruppe den Besitz zu einem synchronen Replikat. Das Verhalten von synchronen Replikaten (maximal ein primäres und zwei sekundäre Replikate) kann weiter von required_synchronized_secondaries_to_commit gesteuert werden. Das gilt für Verfügbarkeitsgruppen unter Windows und Linux, die Konfiguration unterscheidet sich jedoch. Unter Linux wird der Wert automatisch vom Cluster auf der Verfügbarkeitsgruppenressource konfiguriert.
Reine Konfigurationsreplikate und Quoren
Reine Konfigurationsreplikate sind ebenfalls neu in SQL Server 2017 (14.x) CU 1. Da Pacemaker sich von WSFCs unterscheidet – insbesondere in Bezug auf Quoren und die Notwendigkeit der Umgrenzung eines fehlgeschlagenen Knotens – funktioniert die Konfiguration mit nur zwei Knoten bei Verfügbarkeitsgruppen nicht. Bei einer Failoverclusterinstanz können die von Pacemaker bereitgestellten Quorummechanismen funktionieren, da die gesamte Vermittlung bei Failoverclusterinstanzen auf Clusterebene erfolgt. Bei einer Verfügbarkeitsgruppe erfolgt die Vermittlung unter Linux in SQL Server. Dort werden alle Metadaten gespeichert. In diesem Fall können reine Konfigurationsreplikate genutzt werden.
Ohne weitere Schritte wären ein dritter Knoten und mindestens ein synchronisiertes Replikat erforderlich. Das reine Konfigurationsreplikat speichert die Verfügbarkeitsgruppenkonfiguration in der master-Datenbank. Das gleiche gilt für die anderen Replikate in der Verfügbarkeitsgruppenkonfiguration. Das reine Konfigurationsreplikat verfügt nicht über die Benutzerdatenbanken, die an der Verfügbarkeitsgruppe teilnehmen. Die Konfigurationsdaten werden synchron vom primären Replikat gesendet. Diese Konfigurationsdaten werden dann während eines Failovers verwendet, unabhängig davon, ob es automatisch oder manuell ausgeführt wird.
Damit eine Verfügbarkeitsgruppe das Quorum beibehalten und automatische Failovers für den Clustertyp „EXTERNAL“ ermöglichen kann, muss eine der folgenden Bedingungen erfüllt sein:
- Drei synchrone Replikate müssen vorhanden sein (nur SQL Server Enterprise-Edition) oder
- Zwei Replikate (primär und sekundär) und ein reines Konfigurationsreplikat müssen vorhanden sein.
Ein manuelles Failover kann unabhängig davon durchgeführt werden, ob der Clustertyp „EXTERNAL“ oder „NONE“ für Verfügbarkeitsgruppenkonfigurationen verwendet wird. Ein reines Konfigurationsreplikat kann zwar für eine Verfügbarkeitsgruppe konfiguriert werden, deren Clustertyp „NONE“ ist, doch diese Vorgehensweise wird nicht empfohlen, da sie die Bereitstellung erschwert. Ändern Sie required_synchronized_secondaries_to_commit für diese Konfigurationen manuell, damit der Wert mindestens auf „1“ festgelegt und mindestens ein synchronisiertes Replikat vorhanden ist.
Ein reines Konfigurationsreplikat kann in jeder SQL Server-Edition (einschließlich SQL Server Express) gehostet werden. Dadurch werden die Lizenzierungskosten minimiert, und es wird sichergestellt, dass es mit Verfügbarkeitsgruppen in der SQL Server Standard-Edition kompatibel ist. Das bedeutet, dass der dritte erforderliche Server lediglich die Mindestspezifikation für SQL Server erfüllen muss, da er keinen Benutzertransaktionsdatenverkehr für die Verfügbarkeitsgruppe empfängt.
Wenn ein reines Konfigurationsreplikat verwendet wird, weist es folgendes Verhalten auf:
required_synchronized_secondaries_to_commitist standardmäßig auf „0“ festgelegt. Der Wert kann bei Bedarf manuell in „1“ geändert werden.Wenn das primäre Replikat ausfällt und
required_synchronized_secondaries_to_commitden Wert „0“ aufweist, wird das sekundäre Replikat zum neuen primären Replikat und ist für das Lesen und Schreiben verfügbar. Wenn der Wert „1“ ist, wird ein automatisches Failover ausgeführt. Es werden jedoch erst dann neue Transaktionen akzeptiert, wenn das andere Replikat online ist.Wenn ein sekundäres Replikat ausfällt und
required_synchronized_secondaries_to_commitden Wert „0“ aufweist, akzeptiert das primäre Replikat weiterhin Transaktionen, aber wenn das primäre Replikat zu diesem Zeitpunkt ausfällt, werden Daten nicht geschützt, und Failover (manuell oder automatisch) sind nicht möglich, da kein sekundäres Replikat verfügbar ist.Wenn das reine Konfigurationsreplikat ausfällt, funktioniert die Verfügbarkeitsgruppe wie gewohnt, es ist jedoch kein automatisches Failover möglich.
Wenn ein synchrones sekundäres Replikat und das reine Konfigurationsreplikat beide ausfallen, kann das primäre Replikat keine Transaktionen akzeptieren, und das primäre Replikat kann kein Failover durchführen.
In CU 1 gibt es einen bekannten Fehler bei der Protokollierung in der Datei corosync.log, die über mssql-server-ha generiert wird. Wenn ein sekundäres Replikat aufgrund der Anzahl erforderlicher verfügbarer Replikate nicht zum primären Replikat werden kann, enthält die Meldung aktuell den Text Expected to receive 1 sequence numbers but only received 2. Not enough replicas are online to safely promote the local replica. Die Zahlen sollten umgekehrt werden, und sie sollte Expected to receive 2 sequence numbers but only received 1. Not enough replicas are online to safely promote the local replica sagen.
Mehrere Verfügbarkeitsgruppen
Pro Pacemaker-Cluster oder -Servergruppe kann mehr als eine Verfügbarkeitsgruppe erstellt werden. Die Systemressourcen stellen die einzige Einschränkung dar. Der Besitzer der Verfügbarkeitsgruppe wird vom Primary angezeigt. Unterschiedliche Verfügbarkeitsgruppen können sich im Besitz verschiedener Knoten befinden. Sie müssen nicht alle auf demselben Knoten ausgeführt werden.
Laufwerk und Ordnerpfad für Datenbanken
Bei Windows-basierten Verfügbarkeitsgruppen sollten das Laufwerk und die Ordnerstruktur für die Benutzerdatenbanken, die an einer Verfügbarkeitsgruppe teilnehmen, identisch sein. Wenn sich die Benutzerdatenbank auf Server A beispielsweise unter /var/opt/mssql/userdata befindet, sollte der gleiche Ordner auf Server B vorhanden sein. Die einzige Ausnahme wird im Abschnitt Interoperabilität mit Windows-basierten Verfügbarkeitsgruppen und Replikaten behandelt.
Der Listener unter Linux
Der Listener ist eine optionale Funktionalität für Verfügbarkeitsgruppen. Er bietet einen einzigen Einstiegspunkt für alle Verbindungen (Lese-/Schreibzugriff auf das primäre Replikat und/oder schreibgeschützter Zugriff auf sekundäre Replikate), damit Anwendungen und Endbenutzer nicht darüber informiert sein müssen, auf welchem Server die Daten gehostet werden. In einem WSFC besteht dieser aus einer Netzwerknamenressource und einer IP-Ressource, die dann (bei Bedarf) in AD DS und als DNS registriert wird. In Kombination mit der Verfügbarkeitsgruppenressource wird diese Abstraktion bereitgestellt. Weitere Informationen zu einem Listener finden Sie unter Herstellen einer Verbindung mit einem Always On-Verfügbarkeitsgruppenlistener.
Der Listener unter Linux ist anders konfiguriert, aber seine Funktionalität ist identisch. Das Konzept der Netzwerknamenressource ist in Pacemaker nicht vorhanden, und es wird kein Objekt in AD DS erstellt. Es gibt nur eine IP-Adressressource, die in Pacemaker erstellt und auf einem beliebigen Knoten ausgeführt werden kann. Es muss ein Eintrag erstellt werden, der der IP-Ressource für den Listener im DNS mit einem Anzeigenamen zugeordnet ist. Die IP-Ressource für den Listener ist nur auf dem Server aktiv, auf dem das primäre Replikat für diese Verfügbarkeitsgruppe gehostet wird.
Wenn Pacemaker verwendet und eine IP-Adressressource erstellt wird, die dem Listener zugeordnet ist, kommt es zu einem kurzen Ausfall, weil die IP-Adresse auf einem Server angehalten und auf dem anderen gestartet wird, unabhängig davon, ob es sich um ein automatisches oder manuelles Failover handelt. Dadurch wird zwar durch die Kombination aus einem einzelnen Namen und einer IP-Adresse eine Abstraktion ermöglicht, doch der Ausfall wird nicht maskiert. Eine Anwendung muss den Verbindungsverlust mithilfe einer Funktion zum Erkennen und Wiederherstellen der Verbindung bewältigen können.
Die Kombination aus dem DNS-Namen und der IP-Adresse genügt jedoch nicht, um alle Funktionen zu bieten, die ein Listener auf einem WSFC bietet (z. B. schreibgeschütztes Routing für sekundäre Replikate). Wenn Sie eine Verfügbarkeitsgruppe konfigurieren, muss dennoch ein Listener in SQL Server konfiguriert werden. Das wird im Assistenten und in der Syntax von Transact-SQL deutlich. Es gibt zwei Möglichkeiten, die gleiche Funktionsweise wie unter Windows durch Konfiguration zu erreichen:
- Bei einer Verfügbarkeitsgruppe, die den Clustertyp „EXTERNAL“ aufweist, muss die IP-Adresse, die dem in SQL Server erstellten Listener zugeordnet ist, der IP-Adresse der in Pacemaker erstellten Ressource entsprechen.
- Bei einer Verfügbarkeitsgruppe, die den Clustertyp „NONE“ aufweist, sollten Sie die IP-Adresse verwenden, die dem primären Replikat zugeordnet ist.
Die Instanz, die der bereitgestellten IP-Adresse zugeordnet ist, koordiniert dann beispielsweise schreibgeschützte Routinganforderungen für Anwendungen.
Interoperabilität mit Windows-basierten Verfügbarkeitsgruppen und Replikaten
Eine Verfügbarkeitsgruppe, die den Clustertyp „EXTERNAL“ oder einen nicht in WSFCs verfügbaren Clustertyp aufweist, kann keine plattformübergreifenden Replikate besitzen. Dies gilt unabhängig davon, ob die Verfügbarkeitsgruppe für die SQL Server Standard-Edition oder die SQL Server Enterprise-Edition verwendet wird. Das bedeutet, dass es in einer herkömmlichen Verfügbarkeitsgruppenkonfiguration mit einem zugrunde liegenden Cluster nicht möglich ist, dass ein Replikat sich auf einem WSFC und ein anderes unter Linux mit Pacemaker befindet.
Eine Verfügbarkeitsgruppe mit dem Clustertyp „NONE“ kann Replikate auf unterschiedlichen Betriebssystemen besitzen. Es können also Linux- und Windows-basierte Replikate in derselben Verfügbarkeitsgruppe vorhanden sein. Im Folgenden sehen Sie ein Beispiel, bei dem das primäre Replikat Windows-basiert ist, während das sekundäre sich auf einer Linux-Distribution befindet.
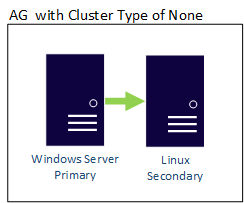
Auch eine verteilte Verfügbarkeitsgruppe kann betriebssystemübergreifende Replikate besitzen. Die zugrunde liegenden Verfügbarkeitsgruppen sind an die Regeln der entsprechenden Konfiguration gebunden. So können beispielsweise eine für Linux konfigurierte Verfügbarkeitsgruppe mit dem Clustertyp „EXTERNAL“ und eine mithilfe eines WSFC konfigurierte Verfügbarkeitsgruppe miteinander verknüpft sein. Betrachten Sie das folgende Beispiel:
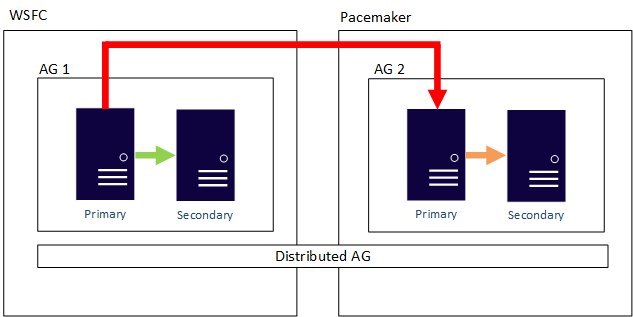
Zugehöriger Inhalt
- Konfigurieren von SQL Server-Always On-Verfügbarkeitsgruppen für Hochverfügbarkeit unter Linux
- Konfigurieren einer SQL Server-Verfügbarkeitsgruppe zur Leseskalierung unter Linux
- Hinzufügen einer Clusterressource für Verfügbarkeitsgruppen unter Linux
- Konfigurieren einer SQL Server Always On-Verfügbarkeitsgruppe unter Windows und Linux (plattformübergreifend)