Tutorial: Erfassen von Daten in einem SQL Server-Datenpool mit Transact-SQL
Gilt für: ![]() SQL Server 2019 (15.x)
SQL Server 2019 (15.x)
Wichtig
Das Microsoft SQL Server 2019-Big Data-Cluster-Add-On wird eingestellt. Der Support für SQL Server 2019-Big Data-Clusters endet am 28. Februar 2025. Alle vorhandenen Benutzer*innen von SQL Server 2019 mit Software Assurance werden auf der Plattform vollständig unterstützt, und die Software wird bis zu diesem Zeitpunkt weiterhin über kumulative SQL Server-Updates verwaltet. Weitere Informationen finden Sie im Ankündigungsblogbeitrag und unter Big Data-Optionen auf der Microsoft SQL Server-Plattform.
In diesem Tutorial wird erläutert, wie Daten über Transact-SQL in den Datenpool eines SQL Server 2019: Big Data-Cluster geladen werden. Mit Big Data-Cluster für SQL Server können Daten aus einer Vielzahl von Quellen eingelesen und auf Datenpoolinstanzen verteilt werden.
In diesem Tutorial lernen Sie Folgendes:
- Erstellen einer externen Tabelle im Datenpool
- Einfügen von Webclickstream-Beispieldaten in die Datenpooltabelle
- Verknüpfen von Daten aus der Datenpooltabelle mit lokalen Tabellen
Tipp
Wenn Sie möchten, können Sie ein Skript für die Befehle in diesem Tutorial herunterladen und ausführen. Anweisungen finden Sie in den Beispielen zu Datenpools auf GitHub.
Voraussetzungen
- Big-Data-Tools
- kubectl
- Azure Data Studio
- Erweiterung von SQL Server 2019
- Laden von Beispieldaten in einen Big Data-Cluster von SQL Server
Erstellen einer externen Tabelle im Datenpool
Mit den folgenden Schritten wird eine externe Tabelle namens web_clickstream_clicks_data_pool im Datenpool erstellt. Diese Tabelle kann dann als Speicherort für die Erfassung von Daten im Big-Data-Cluster verwendet werden.
Stellen Sie in Azure Data Studio eine Verbindung mit der SQL Server-Masterinstanz Ihres Big Data-Clusters her. Weitere Informationen finden Sie unter Herstellen einer Verbindung mit der SQL Server-Masterinstanz.
Doppelklicken Sie im Fenster Server auf die Verbindung, um das Serverdashboard der SQL Server-Masterinstanz anzuzeigen. Wählen Sie Neue Abfrage aus.
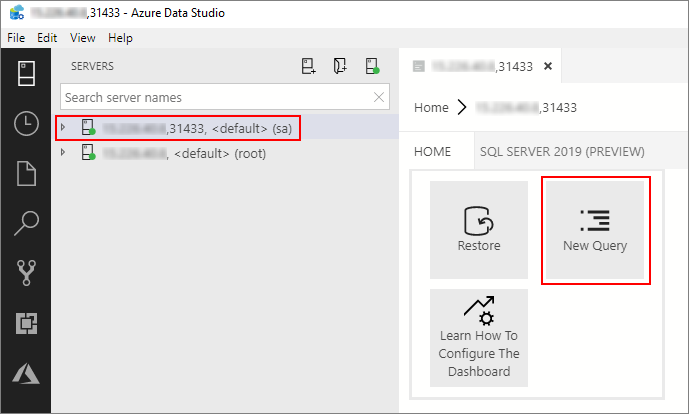
Führen Sie den folgenden Transact-SQL-Befehl aus, um den Kontext in der Masterinstanz in die Sales-Datenbank zu ändern.
USE Sales GOErstellen Sie eine externe Datenquelle für den Datenpool, wenn diese nicht bereits vorhanden ist.
IF NOT EXISTS(SELECT * FROM sys.external_data_sources WHERE name = 'SqlDataPool') CREATE EXTERNAL DATA SOURCE SqlDataPool WITH (LOCATION = 'sqldatapool://controller-svc/default');Erstellen Sie eine externe Tabelle namens web_clickstream_clicks_data_pool im Datenpool.
IF NOT EXISTS(SELECT * FROM sys.external_tables WHERE name = 'web_clickstream_clicks_data_pool') CREATE EXTERNAL TABLE [web_clickstream_clicks_data_pool] ("wcs_user_sk" BIGINT , "i_category_id" BIGINT , "clicks" BIGINT) WITH ( DATA_SOURCE = SqlDataPool, DISTRIBUTION = ROUND_ROBIN );
Die Erstellung einer externen Datenpooltabelle ist ein blockierender Vorgang. Sie können erst dann wieder Aktionen durchführen, wenn die angegebene Tabelle auf allen Back-End-Knoten des Datenpools erstellt wurde. Wenn während des Erstellens ein Fehler auftritt, wird dem Aufrufer eine Fehlermeldung zurückgegeben.
Laden der Daten
In den folgenden Schritten werden die Webclickstream-Beispieldaten aus der externen Tabelle, die in den vorherigen Schritten erstellt wurde, in den Datenpool eingelesen.
Verwenden Sie eine
INSERT INTO-Anweisung, um die Ergebnisse der Abfrage in den Datenpool (die externe Tabelle web_clickstream_clicks_data_pool) einzufügen.INSERT INTO web_clickstream_clicks_data_pool SELECT wcs_user_sk, i_category_id, COUNT_BIG(*) as clicks FROM sales.dbo.web_clickstreams_hdfs INNER JOIN sales.dbo.item it ON (wcs_item_sk = i_item_sk AND wcs_user_sk IS NOT NULL) GROUP BY wcs_user_sk, i_category_id HAVING COUNT_BIG(*) > 100;Überprüfen Sie die eingefügten Daten mit zwei SELECT-Abfragen.
SELECT count(*) FROM [dbo].[web_clickstream_clicks_data_pool] SELECT TOP 10 * FROM [dbo].[web_clickstream_clicks_data_pool]
Abfragen der Daten
Verknüpfen Sie die gespeicherten Ergebnisse der Abfrage im Datenpool mit lokalen Daten in der Sales-Tabelle.
SELECT TOP (100)
w.wcs_user_sk,
SUM( CASE WHEN i.i_category = 'Books' THEN 1 ELSE 0 END) AS book_category_clicks,
SUM( CASE WHEN w.i_category_id = 1 THEN 1 ELSE 0 END) AS [Home & Kitchen],
SUM( CASE WHEN w.i_category_id = 2 THEN 1 ELSE 0 END) AS [Music],
SUM( CASE WHEN w.i_category_id = 3 THEN 1 ELSE 0 END) AS [Books],
SUM( CASE WHEN w.i_category_id = 4 THEN 1 ELSE 0 END) AS [Clothing & Accessories],
SUM( CASE WHEN w.i_category_id = 5 THEN 1 ELSE 0 END) AS [Electronics],
SUM( CASE WHEN w.i_category_id = 6 THEN 1 ELSE 0 END) AS [Tools & Home Improvement],
SUM( CASE WHEN w.i_category_id = 7 THEN 1 ELSE 0 END) AS [Toys & Games],
SUM( CASE WHEN w.i_category_id = 8 THEN 1 ELSE 0 END) AS [Movies & TV],
SUM( CASE WHEN w.i_category_id = 9 THEN 1 ELSE 0 END) AS [Sports & Outdoors]
FROM [dbo].[web_clickstream_clicks_data_pool] as w
INNER JOIN (SELECT DISTINCT i_category_id, i_category FROM item) as i
ON i.i_category_id = w.i_category_id
GROUP BY w.wcs_user_sk;
Bereinigung
Verwenden Sie den folgenden Befehl, um die in diesem Tutorial erstellten Datenbankobjekte zu entfernen.
DROP EXTERNAL TABLE [dbo].[web_clickstream_clicks_data_pool];
Nächste Schritte
Erfahren Sie, wie Sie Daten über Spark-Aufträgen in den Datenpool einlesen: