Konfigurieren von Kubernetes auf mehreren Computern für SQL Server-Big Data-Cluster-Bereitstellungen
Gilt für: ![]() SQL Server 2019 (15.x)
SQL Server 2019 (15.x)
Wichtig
Das Microsoft SQL Server 2019-Big Data-Cluster-Add-On wird eingestellt. Der Support für SQL Server 2019-Big Data-Clusters endet am 28. Februar 2025. Alle vorhandenen Benutzer*innen von SQL Server 2019 mit Software Assurance werden auf der Plattform vollständig unterstützt, und die Software wird bis zu diesem Zeitpunkt weiterhin über kumulative SQL Server-Updates verwaltet. Weitere Informationen finden Sie im Ankündigungsblogbeitrag und unter Big Data-Optionen auf der Microsoft SQL Server-Plattform.
Dieser Artikel enthält ein Beispiel für die Verwendung von kubeadm zum Konfigurieren von Kubernetes auf mehreren Computern für Big Data-Cluster für SQL Server-Bereitstellungen. In diesem Beispiel sind mehrere Ubuntu 16.04- oder 18.04 LTS-Computer (physisch oder virtuell) das Ziel. Für Bereitstellungen auf einer anderen Linux-Plattform müssen Sie einige der Befehle so ändern, dass Sie Ihrem System entsprechen.
Tipp
Beispielskripts zum Konfigurieren von Kubernetes finden Sie unter Erstellen eines Kubernetes-Clusters mit Kubeadm auf Ubuntu 20.04 LTS.
Ein Beispielskript, das eine kubeadm-Bereitstellung eines einzelnen Knotens auf einer VM automatisiert und dann eine Standardkonfiguration des Big Data-Clusters darauf bereitstellt, finden Sie unter Bereitstellen eines kubeadm-Clusters mit einem einzelnen Knoten.
Voraussetzungen
- Mindestens drei physische oder virtuelle Linux-Computer
- Empfohlene Konfiguration pro Computer:
- 8 CPUs
- 64GB Arbeitsspeicher
- 100GB Speicher
Wichtig
Stellen Sie vor der Bereitstellung eines Big Data Clusters sicher, dass die Uhren auf allen für die Bereitstellung verwendeten Kubernetes-Knoten synchronisiert werden. Der Big Data-Cluster verfügt über integrierte Integritätseigenschaften für verschiedene zeitempfindliche Dienste. Zudem können zeitliche Abweichungen zu einer falschen Statusangabe führen.
Vorbereiten der Computer
Auf jedem Computer müssen mehrere Voraussetzungen erfüllt sein. Führen Sie in einem Bash-Terminal auf jedem Computer die folgenden Befehle aus:
Fügen Sie den aktuellen Computer der
/etc/hosts-Datei hinzu:echo $(hostname -i) $(hostname) | sudo tee -a /etc/hostsDeaktivieren Sie den Austausch auf allen Geräten.
sudo sed -i "/ swap / s/^/#/" /etc/fstab sudo swapoff -aImportieren Sie die Schlüssel, und registrieren Sie das Repository für Kubernetes.
curl -s https://packages.cloud.google.com/apt/doc/apt-key.gpg | sudo sudo tee /etc/apt/trusted.gpg.d/apt-key.asc echo 'deb http://apt.kubernetes.io/ kubernetes-xenial main' | sudo tee -a /etc/apt/sources.list.d/kubernetes.listKonfigurieren Sie die Docker- und Kubernetes-Voraussetzungen auf dem Computer.
KUBE_DPKG_VERSION=1.15.0-00 #or your other target K8s version, which should be at least 1.13. sudo apt-get update && \ sudo apt-get install -y ebtables ethtool && \ sudo apt-get install -y docker.io && \ sudo apt-get install -y apt-transport-https && \ sudo apt-get install -y kubelet=$KUBE_DPKG_VERSION kubeadm=$KUBE_DPKG_VERSION kubectl=$KUBE_DPKG_VERSION && \ curl https://raw.githubusercontent.com/kubernetes/helm/master/scripts/get | bashLegen Sie
net.bridge.bridge-nf-call-iptables=1fest. Unter Ubuntu 18.04 aktivieren die folgenden Befehle zuerstbr_netfilter.. /etc/os-release if [ "$VERSION_CODENAME" == "bionic" ]; then sudo modprobe br_netfilter; fi sudo sysctl net.bridge.bridge-nf-call-iptables=1
Konfigurieren des Kubernetes-Masters
Nachdem Sie die vorherigen Befehle auf den einzelnen Computern ausgeführt haben, wählen Sie einen der Computer als Ihren Kubernetes-Master aus. Führen Sie dann die folgenden Befehle auf diesem Computer aus.
Erstellen Sie zunächst mit dem folgenden Befehl eine rbac.yaml-Datei in Ihrem aktuellen Verzeichnis.
cat <<EOF > rbac.yaml apiVersion: rbac.authorization.k8s.io/v1 kind: ClusterRoleBinding metadata: name: default-rbac subjects: - kind: ServiceAccount name: default namespace: default roleRef: kind: ClusterRole name: cluster-admin apiGroup: rbac.authorization.k8s.io EOFInitialisieren Sie den Kubernetes-Master auf diesem Computer. Im folgenden Beispielskript wird die Kubernetes-Version
1.15.0festgelegt. Welche Version Sie verwenden, hängt von Ihrem Kubernetes-Cluster ab.KUBE_VERSION=1.15.0 sudo kubeadm init --pod-network-cidr=10.244.0.0/16 --kubernetes-version=$KUBE_VERSIONDie erfolgreiche Initialisierung des Kubernetes-Masters sollte ausgegeben werden.
Beachten Sie den
kubeadm join-Befehl, den Sie auf den anderen Servern für den Beitritt zum Kubernetes-Cluster verwenden müssen. Kopieren Sie diesen zur späteren Verwendung.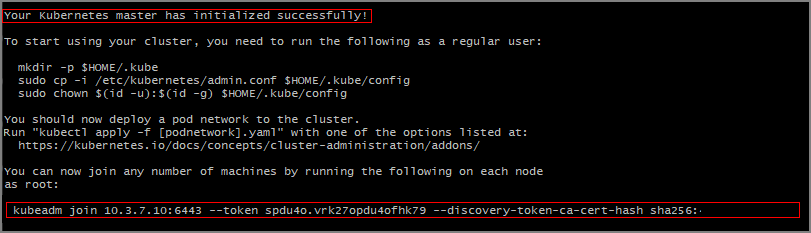
Richten Sie eine Kubernetes-Konfigurationsdatei für Ihr Basisverzeichnis ein.
mkdir -p $HOME/.kube sudo cp -i /etc/kubernetes/admin.conf $HOME/.kube/config sudo chown $(id -u):$(id -g) $HOME/.kube/configKonfigurieren Sie den Cluster und das Kubernetes-Dashboard.
kubectl apply -f https://raw.githubusercontent.com/coreos/flannel/master/Documentation/kube-flannel.yml helm init kubectl apply -f rbac.yaml kubectl apply -f https://raw.githubusercontent.com/kubernetes/dashboard/v1.10.1/src/deploy/recommended/kubernetes-dashboard.yaml kubectl create clusterrolebinding kubernetes-dashboard --clusterrole=cluster-admin --serviceaccount=kube-system:kubernetes-dashboard
Konfigurieren der Kubernetes-Agents
Die anderen Computer fungieren im Cluster als Kubernetes-Agents.
Führen Sie auf allen anderen Computern den Befehl kubeadm join aus, den Sie im vorherigen Abschnitt kopiert haben.

Anzeigen des Clusterstatus
Überprüfen Sie die Verbindung mit Ihrem Cluster mithilfe des Befehls kubectl get, um eine Liste der Clusterknoten zurückzugeben.
kubectl get nodes
Nächste Schritte
Mit den Schritten in diesem Artikel wurde ein Kubernetes-Cluster auf mehreren Ubuntu-Computern konfiguriert. Der nächste Schritt besteht darin, SQL Server 2019-Big Data-Cluster bereitzustellen. Anweisungen finden Sie im folgenden Artikel: