Einführung in den Speicherpool in Big Data-Cluster für SQL Server
Gilt für: ![]() SQL Server 2019 (15.x)
SQL Server 2019 (15.x)
In diesem Artikel ist die Rolle beschrieben, die der SQL Server-Speicherpool in einem SQL Server-Big Data-Cluster spielt. In den folgenden Abschnitten sind die Architektur und die Funktionalität eines Speicherpools beschrieben.
Wichtig
Das Microsoft SQL Server 2019-Big Data-Cluster-Add-On wird eingestellt. Der Support für SQL Server 2019-Big Data-Clusters endet am 28. Februar 2025. Alle vorhandenen Benutzer*innen von SQL Server 2019 mit Software Assurance werden auf der Plattform vollständig unterstützt, und die Software wird bis zu diesem Zeitpunkt weiterhin über kumulative SQL Server-Updates verwaltet. Weitere Informationen finden Sie im Ankündigungsblogbeitrag und unter Big Data-Optionen auf der Microsoft SQL Server-Plattform.
Speicherpoolarchitektur
Der Speicherpool ist der lokale HDFS-Cluster (Hadoop) in einem SQL Server-Big Data-Cluster. Er bietet beständigen Speicher für unstrukturierte und semistrukturierte Daten. Datendateien, z. B. Parquet-Dateien oder durch Trennzeichen getrennte Textdateien, können im Speicherpool gespeichert werden. Für die beständige Speicherung wird jedem Pod im Pool ein persistentes Volume zugeordnet. Der Zugriff auf die Speicherpooldateien ist über PolyBase in SQL Server oder direkt mithilfe einer Apache Knox Gateway-Instanz möglich.
Ein klassisches HDFS-Setup besteht aus einer Gruppe von Standardhardwarecomputern mit zugeordnetem Speicher. Die Daten werden in Blöcken auf die Knoten verteilt, um Fehlertoleranz und die Verwendung von Parallelverarbeitung zu ermöglichen. Einer der Knoten im Cluster fungiert als Namensknoten und enthält die Metadateninformationen zu den Dateien in den Datenknoten.
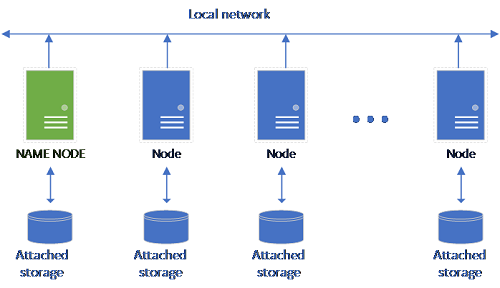
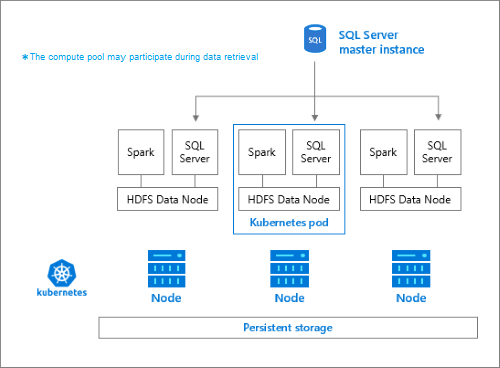
Der Speicherpool besteht aus Speicherknoten, die Mitglieder eines HDFS-Clusters sind. Er führt einen oder mehrere Kubernetes-Pods aus, wobei jeder dieser Pods die folgenden Container hostet:
- Einen Hadoop-Container, der mit einem persistenten Volume (Speicher) verknüpft ist. Alle Container dieses Typs bilden zusammen den Hadoop-Cluster. In diesem Hadoop-Container befindet sich ein YARN-Knotenverwaltungsprozess, der bedarfsgesteuerte Apache Spark-Workerprozesse erstellen kann. Der Spark-Hauptknoten hostet die Container für den Hive-Metastore, den Spark-Verlauf und den YARN-Auftragsverlauf.
- Eine SQL Server-Instanz zum Lesen von Daten aus dem HDFS mithilfe der OpenRowSet-Technologie
collectdzum Erfassen von Metrikdatenfluentbitzum Erfassen von Protokolldaten
Aufgaben
Speicherknoten werden für folgende Aufgaben verwendet:
- Datenerfassung über Apache Spark
- Datenspeicherung in HDFS (Parquet-Format und durch Trennzeichen getrenntes Textformat). Das HDFS bietet auch Datenbeständigkeit, da HDFS-Daten auf alle Speicherknoten in SQL Server BDC verteilt werden.
- Datenzugriff über HDFS und SQL Server-Endpunkte.
Datenzugriff (Accessing data)
Die Hauptmethoden für den Zugriff auf die Daten im Speicherpool sind die folgenden:
- Spark-Aufträge
- Verwendung von externen SQL Server-Tabellen, um das Abfragen der Daten mithilfe von PolyBase-Serverknoten und der SQL Server-Instanzen zu ermöglichen, die auf den HDFS-Knoten ausgeführt werden
Sie können auch Folgendes verwenden, um mit dem HDFS zu interagieren:
- Azure Data Studio.
- Azure Data CLI (
azdata). - kubectl zum Senden von Befehlen an den Hadoop-Container
- HDFS-HTTP-Gateway
Nächste Schritte
Weitere Informationen zu Big Data-Cluster für SQL Server finden Sie in den folgenden Ressourcen: