Mit Big Data-Cluster für SQL Server bereitgestellte Ressourcen
Gilt für: ![]() SQL Server 2019 (15.x)
SQL Server 2019 (15.x)
Wichtig
Das Microsoft SQL Server 2019-Big Data-Cluster-Add-On wird eingestellt. Der Support für SQL Server 2019-Big Data-Clusters endet am 28. Februar 2025. Alle vorhandenen Benutzer*innen von SQL Server 2019 mit Software Assurance werden auf der Plattform vollständig unterstützt, und die Software wird bis zu diesem Zeitpunkt weiterhin über kumulative SQL Server-Updates verwaltet. Weitere Informationen finden Sie im Ankündigungsblogbeitrag und unter Big Data-Optionen auf der Microsoft SQL Server-Plattform.
In diesem Artikel werden die Ressourcen beschrieben, die von einem Big Data-Cluster für SQL Server bereitgestellt werden.
Mit einem Big Data-Cluster werden Pods auf dem Bereitstellungsprofil basierend bereitgestellt. Weitere Informationen finden Sie unter Standardkonfigurationen.
In diesem Artikel werden die Pods beschrieben, die mit dem Profil aks-dev-test-ha bereitgestellt werden. Zudem erhalten Sie Informationen über einen Spark-Pool. Führen Sie eine Abfrage für Kubernetes durch, um die in Ihrem Cluster bereitgestellten Pods anzuzeigen. Im folgenden Beispiel wird eine Liste von Pods unter einem bestimmten Namespace zurückgegeben.
kubectl get pods -n <namespace>
Ersetzen Sie <namespace> durch den Namen des Big Data-Clusters.
Weitere Informationen finden Sie unter Vorgehensweise: Bereitstellen von Big Data-Cluster für SQL Server auf Kubernetes.
Das folgende Diagramm zeigt die in einem Big Data-Cluster bereitgestellten Komponenten an:
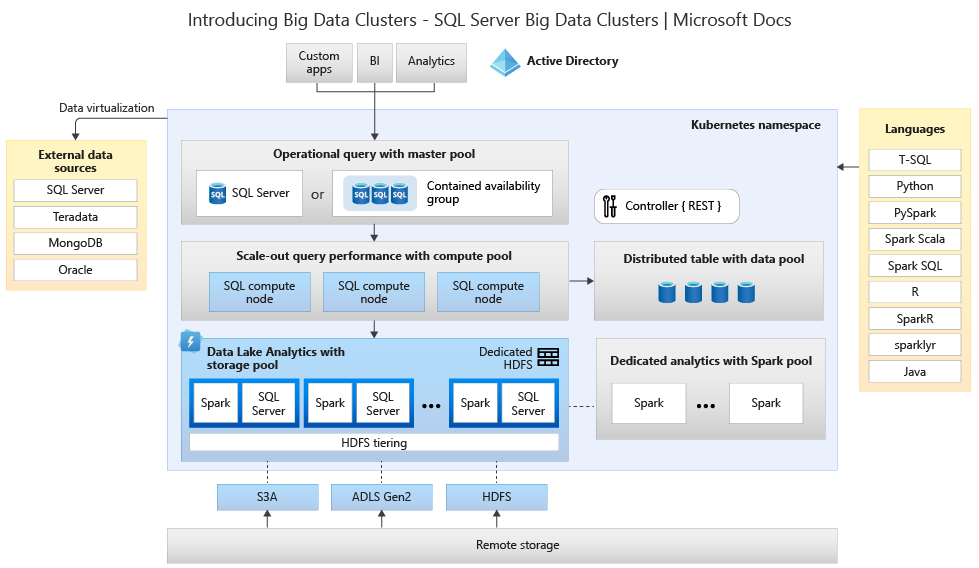
Weitere Informationen zur Architektur finden Sie unter Einführung in Big Data-Cluster für SQL Server.
Bereitgestellte Pods
In der folgenden Tabelle sind die in einem Big Data-Cluster bereitgestellten Pods aufgeführt.
| Name | Bereich |
|---|---|
control-<nnnn> |
Steuerung |
controldb-<#> |
Steuerung |
controlwd-<nnnn> |
Steuerung |
logsdb-<#> |
Steuerung |
logsui-<nnnn> |
Steuerung |
metricsdb-<#> |
Steuerung |
metricsdc-<nnnn> |
Steuerung |
metricsui-<nnnn> |
Steuerung |
mgmtproxy-<nnnn> |
Steuerung |
zookeeper-<#> |
Steuerung |
dns-<nnnn> |
Steuerung |
master-<#n> |
Masterinstanz |
operator-<nnnn> |
Masterinstanz |
compute-<#n>-<#m> |
Computepool |
data-<#>-<#> |
Datenpool |
storage-<#>-<#> |
Speicherpool |
nmnode-<#>-<#> |
Speicherpool |
sparkhead-<#> |
Speicherpool |
appproxy-<#m> |
Anwendungspool |
gateway-<#> |
Gatewaydienst |
Nicht alle Pods sind in jedem Big Data-Cluster enthalten. Bereitstellungen mit Hochverfügbarkeit oder Active Directory-Integrationen beinhalten spezifische Pods.
Spezifische Pods für Hochverfügbarkeit:
operator-<nnnn>zookeeper-<#>
Spezifische Pods für Active Directory:
dns-<nnnn>
In den folgenden Abschnitten werden die Pods beschrieben und die Container in jedem Pod aufgelistet.
Control
Steuerungspods stellen den Steuerungsdienst bereit.
| Podname | Anzahl | Kubernetes-Controllertyp | Container |
|---|---|---|---|
control-# |
1 | ReplicaSet | - controller- security-support- fluentbit |
controldb |
1 | StatefulSet | - mssql-server- fluentbit |
controlwd |
1 | ReplicaSet | - controlwatchdog |
logsdb-# |
1 | StatefulSet | - elasticsearch |
logsui |
1 | ReplicaSet | - kibana |
metricsdb-# |
1 | StatefulSet | - influxdb |
metricsdc |
1 pro Kubernetes-Knoten | DaemonSet | - telegraf |
metricsui-nnnn |
1 | ReplicaSet | - grafana |
mgmtproxy-nnnn |
1 | ReplicaSet | - service-proxy- fluentbit |
dns-nnnn |
0 oder 1 für die Azure Active Directory-Integration | ReplicaSet | - dns- fluentbit |
Master-Instanz
Bei master-<#n> handelt es sich um die SQL Server-Masterinstanz.
- Verwaltet den Datenpool über DDL
- Bearbeitet Daten im Daten Pool über DML
- Lagert die analytische Abfrageausführung in den Datenpool aus
| Podname | Anzahl | Kubernetes-Controllertyp | Container |
|---|---|---|---|
master-<#n> |
Mindestens 1 für Hochverfügbarkeit | StatefulSet | - mssql-server- fluentbit- collectd- mssql-ha-supervisor * |
operator* |
0 oder 1 für Hochverfügbarkeit | ReplicaSet | - mssql-ha-operator |
* Nur für Bereitstellungen mit Hochverfügbarkeit. Der Operator implementiert und registriert die benutzerdefinierte Ressourcendefinition für SQL Server und die Verfügbarkeitsgruppenressourcen. Wenn der Operator bereitgestellt wird, registriert er sich selbst als Listener für Benachrichtigungen über SQL Server-Ressourcen, die im Kubernetes-Cluster bereitgestellt werden. mssql-ha-supervisor unterstützt die Verfügbarkeitsgruppe.
Jeder master-Pod enthält eine Instanz von SQL Server. Eine Bereitstellung mit Hochverfügbarkeit umfasst 3 Pods. Jeder Pod enthält eine SQL Server-Instanz mit Datenbanken in einer SQL Server-Always On-Verfügbarkeitsgruppe.
Schließen Sie je nach Arbeitsauslastung zum Zeitpunkt der Bereitstellung zusätzliche Pods ein.
Computepool
Der Computepool stellt eine SQL Server-Instanz für die Berechnung bereit.
| Podname | Anzahl | Kubernetes-Controllertyp | Container |
|---|---|---|---|
compute-<#n>-<#m> |
Mindestens einer | StatefulSet | - mssql-server- fluentbit- collectd |
#nidentifiziert den Computepool.#midentifiziert die Instanz-ID innerhalb des Pools.
Die SQL Server-Instanzen des Computepools sind zustandslos. Sie benötigen lediglich Speicher für tempdb.
Schließen Sie je nach Arbeitsauslastung zum Zeitpunkt der Bereitstellung zusätzliche Pods ein.
Datenpool
Der Datenpool bietet SQL Server-Instanzen für die Speicherung und das Computing.
| Podname | Anzahl | Kubernetes-Controllertyp | Container |
|---|---|---|---|
data-<#n>-<#m> |
0 oder mehr | StatefulSet | - mssql-server - fluentbit- collectd |
#nidentifiziert den Datenpool.#midentifiziert die Instanz-ID innerhalb des Pools.
Schließen Sie je nach Arbeitsauslastung zum Zeitpunkt der Bereitstellung zusätzliche Pods ein.
Speicherpool
Der Speicherpool ermöglicht die Datenerfassung über Spark, den Speicher in HDFS, den Datenzugriff über HDFS und SQL Server-Endpunkte.
| Podname | Anzahl | Kubernetes-Controllertyp | Container |
|---|---|---|---|
storage-0-# |
Mindestens einer Schließen Sie je nach Arbeitsauslastung zum Zeitpunkt der Bereitstellung zusätzliche Pods ein. | StatefulSet | - hadoop- mssql-server- fluentbit |
nmnode-0-# |
Mindestens 1 für Hochverfügbarkeit | StatefulSet | - hadoop- fluentbit |
sparkehead-# |
Mindestens 1 für Hochverfügbarkeit | StatefulSet | - hadoop-yarn-jobhistory- hadoop-livy-sparkhistory- hadoop-hivemetastore-- fluentbit |
zookeeper |
0 oder 3 für Hochverfügbarkeit | StatefulSet | - zookeeper- fluentbit |
Anwendungspool
Der Anwendungspool ist in einigen der Testkonfigurationsprofile enthalten. Der Anwendungspool hostet Anwendungsdienstproxys, die Sie definieren, wenn Sie Ihre Anwendungen für Big Data-Cluster bereitstellen.
appproxy ist eine Web-API, die sich vor den Anwendungen des Anwendungspools befindet. Sie authentifiziert Benutzer und leitet die Anforderungen dann an die Anwendungen weiter.
| Podname | Kubernetes-Controllertyp | Container |
|---|---|---|
appproxy |
ReplicaSet | - app-service-proxy- fluentbit |
Weitere Informationen finden Sie unter Einführung in die Anwendungsbereitstellung in einem Big Data-Cluster.
Schließen Sie je nach Arbeitsauslastung zum Zeitpunkt der Bereitstellung zusätzliche Pods ein.
Gatewaydienst
Der Gatewaydienst stellt das Knox-Gateway zu Spark, HDFS, Yarn, zur Yarn-Benutzeroberfläche und zur Spark-Benutzeroberfläche bereit.
| Podname | Kubernetes-Controllertyp | Container |
|---|---|---|
gateway-<#> |
StatefulSet | - knox- fluentbit |
Es wird nur ein Gateway unterstützt.
Referenzen zu Open-Source-Containern
Informationen zu bestimmten Open-Source-Projekten und -Versionen finden Sie unter Referenz zu Open-Source-Software.
Nächste Schritte
Weitere Informationen zu Big Data-Cluster für SQL Server finden Sie in den folgenden Ressourcen: