Syntaxreferenz für die FAST Query Language (FQL)
In diesem Artikel erfahren Sie mehr über den Aufbau komplexer Suchabfragen für Suche in SharePoint mit FQL (FAST Query Language). In dieser Referenz sind die Elemente einer FQL-Abfrage beschrieben, und es wird erläutert, wie Eigenschaftsspezifikationen, Tokenausdrücke und Operatoren in FQL-Abfragen verwendet werden.
Einführung in FQL und Unterausdrücke und Ausdrücke der Abfragesprache in SharePoint Server
FQL (FAST Query Language) ist eine leistungsstarke Abfragesprache, die es Entwicklern ermöglicht, genaue Suchvorgänge durchzuführen und den Suchbereich auf Werte zu begrenzen, die zu einer bestimmten verwalteten Eigenschaft oder einem Volltextindex gehören.
Ein Ausdruck der Abfragesprache kann geschachtelte Unterausdrücke enthalten, die Abfragebegriffe, Eigenschaftsspezifikationen und Operatoren enthalten, wie in Tabelle 1 beschrieben.
Tabelle 1. Teilausdrücke in Abfragesprachausdrücken
| Element | Beschreibung |
|---|---|
| Tokenausdrücke | Ein oder mehrere Abfragebegriffe, Phrasen oder numerische Werte, nach denen in einer Abfrage gesucht werden soll |
| Eigenschaftsspezifikation | Eine Eigenschaft oder ein Volltextindex, die bzw. der dem betroffenen Ausdruck zugeordnet werden soll |
| Operatoren | Schlüsselwörter, die boolesche Operationen (zum Beispiel AND, OR) oder andere Einschränkungen für Operanden angeben (zum Beispiel FILTER.) |
FQL-Abfrage - Beispiel
Im folgenden FQL-Abfragebeispiel wird nach den Begriffen "hello" und "world" in der verwalteten Eigenschaft body eines indizierten Elements gesucht:
body:string("hello world", mode="and")
Im Beispiel:
-
body:begrenzt den Bereich der Abfrage auf die verwaltete body-Eigenschaft innerhalb des Elements. -
"hello world"ist der Operand für den STRING -Operator, der die zu suchenden Begriffe angibt. -
mode="and"gibt an, dass der logische Abfrageoperator AND auf"hello world"angewendet wird.
Die Länge der FAST Query Language-Abfragen ist auf 2.048 Zeichen beschränkt.
Eigenschaftsspezifikation in FQL
Eine Eigenschaftsspezifikation begrenzt den Bereich des betroffenen Ausdrucks auf bestimmte Bereiche des indizierten Inhalts. Ein solcher Bereich kann durch einen Volltextindex oder eine verwaltete Eigenschaft angegeben werden.
Verwaltete Eigenschaften des Typs Text und YesNo werden als Nächstes ausgewertet. Alle übrigen verwalteten Eigenschaftstypen, einschließlich des Typs Datetime werden als numerische Werte ausgewertet.
Wenn Sie keine Eigenschaftsspezifikation für einen Ausdruck einfügen, versucht das Suchmodul den im Indexschema definierten standardmäßigen Volltextindex zuzuordnen.
Dem Namen der Eigenschaft muss stets ein Doppelpunkt vorangestellt werden (Operator In), und numerische Operatoren müssen immer eine Eigenschaftsspezifikation enthalten.
Eine Eigenschaftsspezifikation (der Operator In) kann auf die folgenden Abfrageeinheiten angewendet werden:
Einen einzelnen Begriff oder eine Phrase wie folgt:
author:shakespeare title:"to be or not to be"Einen Operator, zum Beispiel den Operator STRING, wie folgt:
title:string("to be or not to be")In diesem Fall gilt die Eigenschaftenspezifikation für den gesamten Operatorausdruck.
Beispiele
Jeder der folgenden Ausdrücke findet Elemente, die in der verwalteten title-Eigenschaft sowohl den Begriff "viel" als auch den Begriff "nichts" enthalten.
title:and(much, nothing)
and(title:much, title:nothing)
title:string("much nothing", mode="and")
Tokenausdrücke in FQL
Tokenausdrücke sind Wörter, Phrasen und numerische Werte, die mit dem Index abgeglichen werden.
Bei einem Tokenausdruck vom Typ Text kann es sich um ein einzelnes Wort oder eine in doppelte Anführungszeichen eingeschlossene Phrase handeln.
Ein numerischer Tokenausdruck kann ein einzelner Wert oder Wertebereichausdruck sein.
Platzhalterausdrücke
Mit einem Platzhalterausdruck wird ein einzelner Begriff oder eine Phrase angegeben, die ein Sternchen („*“) enthält. Durch die Angabe des Sternchens können auch null oder mehr Zeichen mit Ausnahme von Leerräumen gefunden werden. FQL unterstützt die Präfixsuche für individuelle verwaltete Texteigenschaften und Volltextindizes.
Beispiele für Platzhalterausdrücke
Nachfolgend finden Sie eine Liste gültiger Verwendungszwecke von Platzhalterausdrücken in FQL:
text*string("this examp*")
Numerische Ausdrücke
Jeder numerische Ausdruck muss eine Eigenschaftsspezifikation eines kompatiblen Indexschema-Datentyps enthalten. Tabelle 2 enthält die numerischen Datentypen, die in FQL verwendet werden können.
Tabelle 2. In FQL verwendbare numerische Datentypen
| FQL-Typ | Kompatible Indexschematypen | Beschreibung |
|---|---|---|
| Int | Integer | 64-Bit-Ganzzahl |
| Float | Double | 64-Bit-Gleitkommazahl mit doppelter Genauigkeit |
| Decimal | Decimal | 128-Bit-Dezimal |
| Datetime | Datetime | Ein Wert für Datum und Uhrzeit Aufgrund der Unterstützung von Datum/Uhrzeit in FQL können die gleichen numerischen Operationen an Datum-/Uhrzeitwerten ausgeführt werden wie an anderen numerischen Werten. |
Abfrageausdrücke für Datum und Uhrzeit
FQL stellt den datetime-Datentyp für Datum und Uhrzeit zur Verfügung.
Die folgenden ISO 8601-kompatiblen datetime-Formate werden in Abfragen unterstützt:
- JJJJ-MM-TT
- JJJJ-MM-TTThh:mm:ss
- YYYY-MM-DDThh:mm:ssZ
- YYYY-MM-DDThh:mm:ssfrZ
In diesen datetime-Formaten:
YYYY gibt eine vierziffrige Jahreszahl an.
Hinweis
Es werden nur vierziffrige Jahresangaben unterstützt.
MM gibt einen zweiziffrigen Monat an. Z. B. 01 = Januar.
DD gibt einen zweiziffrigen Tag des Monats an (01-31).
T gibt den Buchstaben „T" an.
hh gibt eine zweiziffrige Stundenangabe an (00-23).
mm gibt eine zweiziffrige Minutenangabe an (00-59).
ss gibt eine zweiziffrige Sekundenangabe an (00-59).
fr gibt einen optionalen Sekundenbruchteil an, ss; zwischen 1 und 7 Ziffern, die auf die folgen. nach den Sekunden. Beispiel: 2012-09-27T11:57:34.1234567.
Alle Datums-/Zeitwerte müssen gemäß der UTC (Coordinated Universal Time) angegeben werden, auch als GMT (Greenwich Mean Time) Zeitzone bekannt. Der UTC-Zeitzonenbezeichner (nachfolgendes "Z") ist optional.
Reservierte Wörter, Sonderzeichen und Escapezeichen
Die folgenden Wörter sind in FQL reserviert.
and, or, any, andnot, count, decimal, rank, near, onear, int, in32, int64, float, double, datetime, max, min, range, phrase, scope, filter, not, string, starts-with, ends-with, equals, words, xrank.
Wenn Sie diese Wörter als Begriffe in einem Abfrageausdruck ausdrücken möchten, müssen Sie sie in doppelte Anführungszeichen einschließen, wie in den folgenden Beispielen gezeigt:
or("any", "and", "xrank")string("any and xrank", mode="OR")phrase(this, is, a, "phrase")
Tipp
Reservierte Wörter und Zeichen unterliegen nicht der Groß-/Kleinschreibung. Es wird jedoch die Verwendung von Kleinbuchstaben empfohlen, um zukünftige Kompatibilität zu gewährleisten.
FQL erfordert nicht immer, dass Zeichenfolgen in doppelte Anführungszeichen eingeschlossen werden. Beispielsweise ist and(cat, dog) gültige FQL-Syntax, obwohl cat und dog nicht in doppelte Anführungszeichen eingeschlossen sind. Wir empfehlen jedoch, doppelte Anführungszeichen zu verwenden, um Konflikte mit reservierten Wörtern zu vermeiden.
Die Abfragebegriffe sind gemäß Ihren Gebietsschemaeinstellungen mit Token versehen. Beim Vorgang der Tokenisierung werden bestimmte Sonderzeichen entfernt. Da Sonderzeichen entfernt werden, stimmen die folgenden FQL-Ausdrücke überein.
and("[king]", "<queen>")
and("king", "queen")
Wenn eine Abfrage Begriffe aus der Benutzereingabe oder einer anderen Anwendung enthält, verwenden Sie den Operator string("<query terms>", mode="AND|OR|PHRASE"), um Konflikte mit reservierten Wörtern in der Abfragesprache zu vermeiden. Sie müssen auch mögliche doppelte Anführungszeichen aus der vom Benutzer angegebenen Abfrage entfernen.
FQL-Operatoren
FQL-Operatoren (FAST Query Language) sind Schlüsselwörter, die boolesche Operationen oder andere Einschränkungen für Operanden angeben. Die Syntax der FQL-Operatoren lautet wie folgt:
[property-spec:]operator(operand [,operand]* [, parameter="value"]*)
Inhalt der Syntax:
- property-spec ist eine optionale Eigenschaftsspezifikation gefolgt vom Operator "in".
- operator ist ein Schlüsselwort, das eine auszuführende Operation angibt.
- operand ist ein Begriffsausdruck oder ein anderer Operator.
- parameter ist der Name des Werts, der das Verhalten des Operators ändert.
- value ist der für den Parameternamen zu verwendende Wert.
Operatornamen, Parameternamen und Textwerte für Parameter unterliegen nicht der Groß-/Kleinschreibung. Leerzeichen sind im Textkörper des Operators zulässig, werden jedoch ignoriert, sofern sie nicht in doppelte Anführungszeichen eingeschlossen sind. Die Länge der FAST Query Language-Abfragen ist auf 2.048 Zeichen beschränkt.
Tabelle 3 enthält die Typen der von FQL unterstützten Operatoren.
Tabelle 3. Unterstützte FQL-Operatortypen
| Typ | Beschreibung | Operatoren |
|---|---|---|
| Zeichenfolge | Ermöglicht die Angabe von Abfrageoperationen in einer Begriffszeichenfolge. Dies ist der gängigste Operator für Textzeichenfolgen. | STRING |
| Boolescher Wert | Ermöglicht die Kombination von Begriffen und Unterausdrücken in einer Abfrage. | AND, OR, ANY, ANDNOT, NOT, COUNT, COUNT |
| Näherung | Hiermit können Sie angeben, wie nah die Abfragebegriffe in einer übereinstimmenden Textsequenz beieinander liegen. | NEAR, ONEAR, PHRASE, STARTS-WITH, ENDS-WITH, EQUALS |
| Numeric | Hiermit können Sie numerische Bedingungen in der Abfrage angeben. | RANGE , INT, FLOAT, DATETIME, DECIMAL |
| Relevanz | Hiermit können Sie die Relevanzbewertung einer Abfrage beeinflussen. | XRANK und FILTER |
Tabelle 4 enthält eine Liste der unterstützten Operatoren.
Tabelle 4. Unterstützte FQL-Operatoren
| Operator | Beschreibung | Typ |
|---|---|---|
| AND | Gibt nur Elemente zurück, die mit allen AND -Operanden übereinstimmen. | Boolescher Wert |
| ANDNOT | Gibt nur Elemente zurück, die mit dem ersten Operanden und nicht mit den nachfolgenden Operanden überstimmen. | Boolescher Wert |
| ANY | Ähnelt dem Operator OR, abgesehen davon, dass die dynamische Rangfolge (die Relevanzbewertung in der Ergebnismenge) weder von der Anzahl der übereinstimmenden Operanden noch vom Abstand zwischen den Begriffen im Element betroffen ist. | Boolescher Wert |
| COUNT | Ermöglicht Ihnen, anzugeben, wie oft ein Abfragebegriff in einem Element enthalten sein muss, damit er als Ergebnis zurückgegeben wird. Der Operand kann ein einzelner Abfragebegriff, eine Phrase oder ein Abfragebegriff mit Platzhalter sein. | Boolesch |
| DATETIME | Stellt die explizite Eingabe numerischer Werte zur Verfügung. Die explizite Typumwandlung ist optional und normalerweise nicht notwendig. Der Typ des Abfragebegriffs wird gemäß dem Typ der numerischen verwalteten Zieleigenschaft erkannt. | Numeric |
| DECIMAL | Stellt die explizite Eingabe numerischer Werte zur Verfügung. Die explizite Typumwandlung ist optional und normalerweise nicht notwendig. Der Typ des Abfragebegriffs wird gemäß dem Typ der numerischen verwalteten Zieleigenschaft erkannt. | Numeric |
| ENDS-WITH | Gibt an, dass ein Wort oder eine Phrase am Ende einer verwalteten Eigenschaft angezeigt werden muss. | Näherung |
| EQUALS | Gibt an, dass ein Wort, ein Phrasenbegriff oder eine Phrase eine genaue Tokenübereinstimmung mit der verwalteten Eigenschaft aufweisen muss. | Näherung |
| FILTER | Wird verwendet, um Metadaten oder andere strukturierte Daten abzufragen. | Relevanz |
| FLOAT | Stellt die explizite Eingabe numerischer Werte zur Verfügung. Die explizite Typumwandlung ist optional und normalerweise nicht notwendig. Der Typ des Abfragebegriffs wird gemäß dem Typ der numerischen verwalteten Zieleigenschaft erkannt. | Numeric |
| INT | Stellt die explizite Eingabe numerischer Werte zur Verfügung. Die explizite Typumwandlung ist optional und normalerweise nicht notwendig. Der Typ des Abfragebegriffs wird gemäß dem Typ der numerischen verwalteten Zieleigenschaft erkannt. | Numeric |
| NEAR | Beschränkt die Ergebnismenge auf Elemente, die N Begriffe innerhalb eines bestimmten Abstands voneinander aufweisen. |
Näherung |
| NOT | Gibt nur Elemente zurück, die den Operanden ausschließen. | Boolescher Wert |
| ONEAR | Die sortierte Variante von NEAR, die eine sortierte Zuordnung der Begriffe erfordert. Der ONEAR-Operator kann verwendet werden, um das Resultset auf Elemente zu beschränken, die N Ausdrücke innerhalb eines bestimmten Abstands von Rückgaben aufweisen, nur Elemente, die nicht mit dem Operanden übereinstimmen. Der Operand kann ein beliebiger gültiger FQL-Ausdruck sein. |
Näherung |
| OR | Gibt nur Elemente zurück, die mindestens einem der OR-Operanden entsprechen. Übereinstimmende Elemente werden in der dynamischen Rangfolge (Relevanzbewertung in der Ergebnismenge) weiter oben angegeben, wenn mehrere der OR-Operanden übereinstimmen. | Boolescher Wert |
| PHRASE | Gibt nur Elemente zurück, die einer genauen Tokenzeichenfolge entsprechen. | Näherung |
| RANGE | Ermöglicht mit Bereichen übereinstimmende Ausdrücke. Der Operator RANGE wird für numerische verwaltete Eigenschaften und verwaltete Eigenschaften für Datum/Uhrzeit verwendet. | Numerisch |
| STARTS-WITH | Gibt an, dass ein Wort oder eine Phrase am Anfang einer verwalteten Eigenschaft angezeigt werden muss. | Näherung |
| STRING | Definiert eine übereinstimmende boolesche Bedingung für eine Textzeichenfolge. | Zeichenfolge |
| XRANK | Ermöglicht es Ihnen, die dynamische Rangfolge von Elementen basierend auf bestimmten Begriffsvorkommen zu erhöhen, ohne zu ändern, welche Elemente mit der Abfrage übereinstimmen. Ein XRANK -Ausdruck enthält eine Komponente, die abgeglichen werden muss, und eine oder mehrere Komponenten, die nur für die dynamische Rangfolge relevant sind. | Relevanz |
Hinweis
In SharePoint wird der Operator RANK nicht mehr unterstützt und ist daher wirkungslos. Verwenden Sie stattdessen den Operator XRANK.
AND
Gibt nur Elemente zurück, die mit allen AND -Operanden übereinstimmen. Bei den Operanden kann es sich um einen einzelnen Begriff oder einen beliebigen gültigen FQL-Unterausdruck handeln.
Syntax
and(operand, operand [, operand]*)
Parameter
Nicht zutreffend
Beispiele
Der folgende Ausdruck gleicht Elemente ab, bei denen der Standard-Volltextindex den Begriff „Katze", „Hund" und „Fuchs" enthält.
and(cat, dog, fox)
ANDNOT
Gibt nur Elemente zurück, die mit dem ersten Operanden und nicht mit den nachfolgenden Operanden überstimmen. Bei den Operanden kann es sich um einen einzelnen Begriff oder einen beliebigen gültigen FQL-Unterausdruck handeln.
Syntax
andnot(operand, operand [,operand]*)
Parameter
Nicht zutreffend
Beispiele
Beispiel 1. Mit dem folgenden Ausdruck werden übereinstimmende Elemente gesucht, für die der standardmäßige Volltextindex "cat", aber nicht "dog" enthält.
andnot(cat, dog)
Beispiel 2. Mit dem folgenden Ausdruck werden übereinstimmende Elemente gesucht, für die der standardmäßige Volltextindex "dog", aber nicht "beagle" oder "chihuahua" enthält.
andnot(dog, beagle, chihuahua)
ANY
Hinweis
In SharePoint wird der ANY-Operator nicht mehr unterstützt. Verwenden Sie stattdessen den OR-Operator.
Vergleichbar mit dem OR-Operator, nur dass die dynamische Rangfolge (die Relevanzbewertung im Resultset) weder von der Zahl der übereinstimmenden Operanden noch vom Abstand zwischen den Suchausdrücken im Element beeinflusst wird. Bei den Operanden kann es sich um einen einzelnen Begriff oder einen beliebigen gültigen FQL-Unterausdruck handeln.
Die dynamische Rangkomponente für diesen Teil der Abfrage basiert auf dem am besten passenden Begriff im ANY-Ausdruck.
Hinweis
Der Unterschied zu OR bezieht sich nur auf die Rangfolge innerhalb der Ergebnismenge. Die Abfrage gleicht dieselbe Gesamtmenge von Elementen ab.
Syntax
any(operand, operand [,operand]*)
Parameter
Nicht zutreffend
Beispiele
Der folgende Ausdruck gleicht Elemente ab, bei denen der Standard-Volltextindex den Begriff „Katze" oder „Hund" enthält.
Wenn der Index sowohl „Katze" als auch „Hund" enthält, „Katze" aber als der bessere Treffer betrachtet wird, basiert die dynamische Rangfolge des Elements auf dem Begriff „Katze", und der Begriff „Hund" wird nicht berücksichtigt.
any(cat, dog)
COUNT
Gibt an, wie oft ein Abfragebegriff in einem Element enthalten sein muss, damit das Element als Ergebnis zurückgegeben wird. Der Operand kann ein einzelner Abfragebegriff, eine Phrase oder ein Abfragebegriff mit Platzhalter sein.
Syntax
property-spec:count(operand [,from=<numeric value>, to=<numeric value>])
Parameter
| Parameter | Wert | Beschreibung |
|---|---|---|
| From | <numeric_value> | Der Wert des Parameters from muss eine positive ganze Zahl sein, die angibt, wie oft eine Übereinstimmung des Operanden mindestens erzielt werden muss. Wenn der Parameter from nicht angegeben ist, ist kein unterer Grenzwert vorhanden. |
| to | <numeric_value> | Der Wert des Parameters to muss eine positive ganze Zahl sein, die angibt, wie oft eine Übereinstimmung des Operanden höchstens (nicht inklusive) erzielt werden muss. Beispielsweise gibt ein to-Wert von 11 an, dass 10 oder weniger Übereinstimmungen vorhanden sind. Wenn der Parameter to nicht angegeben ist, ist kein oberer Grenzwert vorhanden. |
Beispiele
Beispiel 1. Mit dem folgenden Ausdruck werden Übereinstimmungen mit mindestens 5 Instanzen des Worts "cat" gesucht.
count(cat, from=5)
Beispiel 2. Mit dem folgenden Ausdruck werden Übereinstimmungen mit mindestens 5 und maximal 9 Instanzen des Worts "cat" gesucht.
count(cat, from=5, to=10)
Beispiel 3. Das Wort kann entweder „Katze" oder „Hund" sein.
count(or(cat, dog), from=3)count(string("cat dog", mode="or"), from=3)
Die folgende Tabelle enthält Beispiele der Zeichenfolgenwerte der verwalteten Eigenschaft und gibt an, ob diese mit den beiden Ausdrücken in Beispiel 3 übereinstimmen.
| Übereinstimmung? | Text |
|---|---|
| Ja | Meine Katze mag meinen Hund, aber mein Hund hasst meine Katze. |
| Nein | Mein Vogel mag meinen Molch, aber mein Hund hasst meine Katze. |
DATETIME
Stellt die explizite Eingabe numerischer Datum/Uhrzeit-Werte zur Verfügung. Der Operand ist eine Datum/Uhrzeit-Zeichenfolge, die gemäß der unter Tokenausdrücke in FQL angegebenen Syntax formatiert ist.
Die explizite Typumwandlung ist optional und normalerweise nicht notwendig. Der Typ des Abfragebegriffs wird gemäß dem Typ der numerischen verwalteten Zieleigenschaft erkannt.
Syntax
datetime(<date/time string>)
Parameter
Nicht zutreffend
DECIMAL
Stellt die explizite Eingabe von Dezimalwerten zur Verfügung. Der Operand ist ein Dezimalwert gemäß der unter Tokenausdrücke in FQL angegebenen Syntax.
Die explizite Typumwandlung ist optional und normalerweise nicht notwendig. Der Typ des Abfragebegriffs wird gemäß dem Typ der numerischen verwalteten Zieleigenschaft erkannt.
Syntax
decimal(<decimal point value>)
Parameter
Nicht zutreffend
ENDS-WITH
Gibt an, dass ein Wort oder eine Phrase am Ende einer verwalteten Eigenschaft angezeigt werden muss (Begrenzungsabgleich).
Der Begrenzungsabgleich wird bei numerischen verwalteten Eigenschaften nicht unterstützt. Numerische verwaltete Eigenschaften unterliegen stets dem Abgleich von exakten Werten oder Wertebereichen.
Einige Anwendungen erfordern möglicherweise, dass Sie einen exakten Abgleich einer verwalteten Eigenschaft durchführen können. Dies kann beispielsweise eine verwaltete product name-Eigenschaft sein, bei der der vollständige Name eines Produkts eine Teilzeichenfolge eines anderen Produktnamens ist.
Syntax
ends-with(<term or phrase>)
Parameter
Nicht zutreffend
Beispiele
Mit dem folgenden Ausdruck werden übereinstimmende Elemente mit den Werten "Mr Adam Jones" und "Adam Jones" in der verwalteten Eigenschaft "author" gesucht. Elemente mit dem Wert "Adam Jones sr" stellen keine Übereinstimmung dar.
author:ends-with("adam jones")
Hinweise
Der Begrenzungsabgleich kann auf den gesamten Text der verwalteten Eigenschaft angewendet werden, oder auf einzelne Zeichenfolgen innerhalb einer verwalteten Eigenschaft, die eine Liste von Werten enthält (beispielsweise eine Liste mit Namen). In diesem Fall empfiehlt es sich, den genauen Inhalt jeder Zeichenfolge abzugleichen, und Abgleichsabfragen über Zeichenfolgengrenzen hinweg zu vermeiden.
Um Begrenzungsabgleichsabfragen durchzuführen, müssen Sie die relevante verwaltete Eigenschaft im Indexschema konfigurieren.
Wenn Sie das Begrenzungsabgleichsfeature für die verwaltete Eigenschaft aktivieren, können Sie Folgendes durchführen:
- Verwenden expliziter Begrenzungsabgleichsabfragen
- Verhindern, dass Phrasen über Zeichenfolgengrenzen hinweg abgeglichen werden. Für verwaltete Eigenschaften, die mehrere Zeichenfolgen enthalten, stellt dieses Feature sicher, dass eine Zeichenfolge vor oder nach einer Begrenzungsangabe keine Wörter abgleicht.
EQUALS
Gibt an, dass ein Wort oder eine Phrase eine genaue Tokenübereinstimmung mit der verwalteten Eigenschaft aufweisen muss.
Syntax
equals(<term or phrase>)
Parameter
Nicht zutreffend
Beispiele
Im folgenden Beispiel werden übereinstimmende Elemente mit den Werten "Adam Jones" in der verwalteten Eigenschaft "author" gesucht. Elemente mit den Werten "Adam Jones sr" oder "Mr Adam Jones" stellen keine Übereinstimmung dar.
author:equals("adam jones")
Hinweise
Siehe auch ENDS-WITH.
FILTER
Wird verwendet, um Metadaten oder andere strukturierte Daten abzufragen.
Die Verwendung des Operators FILTER impliziert Folgendes für die angegebene Abfrage:
Die Linguistik wird auf linguistics="OFF" festgelegt.
Die Rangfolge wird deaktiviert.
Es wird keine Hervorhebung der Abfrage in der hervorgehobenen Trefferzusammenfassung für den Abfrage-Ergebnistreffer verwendet.
Tipp: Wenn Sie den STRING-Operator in einem FILTER-Ausdruck verwenden, ist Linguistik standardmäßig deaktiviert. Sie können die Linguistikverarbeitung, die in jedem STRING-Ausdruck im FILTER durchgeführt wird, mit dem Operand
linguistics="ON"aktivieren.
Syntax
filter(<any valid FQL operator expression>)
Parameter
Nicht zutreffend
Beispiele
Der folgende Ausdruck gleicht Elemente mit einer verwalteten Title-Eigenschaft ab, die „Sonate" enthält, und einer verwalteten Doctype-Eigenschaft, die nur das Token „Audio" enthält. Für „Audio" wird kein linguistischer Abgleich durchgeführt. Da das Token FILTER zum Abgleich von „Audio" verwendet wird, wird dieser Text in der Zusammenfassung mit hervorgehobenen Treffern nicht hervorgehoben.
and(title:sonata, filter(doctype:equals("audio")))
Hinweise
Wenn Sie die Abfrage so einschränken müssen, dass wenigstens ein umfangreicher Satz von Ganzzahlen in einer numerischen Eigenschaft abgeglichen werden muss, können Sie dies auf zwei funktional äquivalente Arten ausdrücken:
and(string("hello world"), filter(property-spec:or(1, 20, 453, ... , 3473)))and(string("hello world"), filter(property-spec:int("1 20 453 ... 3473", mode="or")))
Im zweiten Beispiel wird der Operator INT mit einer Zeichenfolge verwendet, deren Gruppe numerischer Werte in doppelte Anführungszeichen eingeschlossen ist. Dadurch wird eine erheblich bessere Abfrageleistung erzielt, wenn eine umfangreiche Gruppe numerischer Werte gefiltert wird.
Wenn eine große Gruppe von Werten gefiltert werden muss, sollten Sie erwägen, anstelle von Zeichenfolgewerten numerische Werte zu verwenden, und Ihre Abfrage mit der optimierten Syntax ausdrücken.
FLOAT
Stellt die explizite Eingabe numerischer Gleitkommawerte zur Verfügung. Der Operand ist ein Gleitkommawert gemäß der unter Tokenausdrücke in FQL angegebenen Syntax.
Die explizite Typumwandlung ist optional und normalerweise nicht notwendig. Der Typ des Abfragebegriffs wird gemäß dem Typ der numerischen verwalteten Zieleigenschaft erkannt.
Syntax
float(<floating point value>)
Parameter
Nicht zutreffend
INT
Stellt die explizite Eingabe von ganzzahligen Werten zur Verfügung. Der Operand ist ein Ganzzahlwert gemäß der unter Tokenausdrücke in FQL angegebenen Syntax.
Die explizite Typumwandlung ist optional und normalerweise nicht notwendig. Der Typ des Abfragebegriffs wird gemäß dem Typ der numerischen verwalteten Zieleigenschaft erkannt.
Der Operator INT kann auch verwendet werden, um eine Gruppe von Ganzzahlwerten als Argumente für boolesche FQL-Operatoren auszudrücken. Dadurch wird ein leistungseffizientes Verfahren zur Verfügung gestellt, um eine Gruppe von Ganzzahlwerten in einer Abfrage anzugeben, da die Werte, die mit dem Operator INT übergeben werden, nicht mit der FQL-Abfrageanalyse analysiert werden, sondern direkt an die Komponente für den Abfrageabgleich übergeben werden.
Syntax
int(<integer value>)
int("value, value, ??? , value")
In der ersten Syntax wird eine einzelne ganze Zahl angegeben. Die zweite Syntax gibt eine kommagetrennte Liste von Ganzzahlwerten an, die in doppelte Anführungszeichen eingeschlossen sind.
Parameter
Nicht zutreffend
Beispiele
Wenn Sie die Abfrage so einschränken müssen, dass mindestens ein Wert aus einer großen Gruppe von Ganzzahlwerten in einer numerischen Eigenschaft gefunden wird, können Sie dies mit dem Operator INT ausdrücken:
and(string("hello world"), filter(id:int("1 20 49 124 453 985 3473", mode="or")))
NEAR
Beschränkt die Ergebnismenge auf Elemente, die N Begriffe innerhalb eines bestimmten Abstands voneinander aufweisen.
Die Reihenfolge der Abfragebegriffe ist für die Übereinstimmung nicht von Bedeutung, sondern nur der Abstand.
Mit den NEAR -Operatoren kann eine beliebige Anzahl von Begriffen kombiniert werden.
NEAR -Operanden können einzelne Begriffe, Phrasen oder boolesche Ausdrücke des Operators OR oder ANY sein. Platzhalter werden akzeptiert.
Wenn mehrere Operanden des Operators NEAR das gleiche indizierte Token abgleichen, werden sie als nah beieinander liegend betrachtet.
Syntax
near(arg, arg [, arg]* [, N=<numeric value>])
Parameter
| Parameter | Wert | Beschreibung |
|---|---|---|
| N | <numeric_value> | Gibt die maximale Anzahl von Wörtern an, die zwischen den Begriffen angezeigt werden darf (explizite Nähe). Wenn NEAR mehr als zwei Operanden enthält, wird die maximale Anzahl der zwischen den Begriffen zulässigen Wörter ( N) innerhalb des ganzen Ausdrucks gezählt. Standardwert: 4 |
Beispiele
Beispiel 1. Mit dem folgenden Ausdruck werden übereinstimmende Zeichenfolgen gesucht, die sowohl "cat" als auch "dog" enthalten und die durch maximal vier indizierte Token (Standard) getrennt sind.
near(cat, dog)
Beispiel 2. Mit dem folgenden Ausdruck werden übereinstimmende Zeichenfolgen gesucht, die "cat", "dog", "fox" und "wolf" enthalten und die durch maximal vier indizierte Token getrennt sind.
near(cat, dog, fox, wolf)
In der folgenden Tabelle finden Sie Beispiele für Zeichenfolgenwerte von verwalteten Eigenschaften und Angaben dazu, ob sie mit dem vorherigen Ausdruck in Beispiel 2 übereinstimmen.
| Übereinstimmung? | Text |
|---|---|
| Ja | Die Abbildung zeigt eine Katze, einen Hund, einen Fuchs und einen Wolf. |
| Ja (mit Wortstammerkennung) | Hunde, Füchse und Wölfe sind hundeartig, Katzen hingegen sind katzenartig. |
| Nein | Die Abbildung zeigt eine Katze mit einem Hund, einem Fuchs und einem Wolf. |
Der folgende Ausdruck gleicht alle Zeichenfolgen in der vorherigen Tabelle ab.
near(cat, dog, fox, wolf, N=5)
Hinweise
Überlegungen zum Abstand zwischen NEAR/ONEAR-Begriffen
N gibt die maximale Anzahl der Wörter an, die zwischen den Abfragebegriffen innerhalb des übereinstimmenden Segments des Elements angezeigt werden dürfen. Wenn NEAR oder ONEAR mehr als zwei Operanden enthält, wird die maximal zulässige Anzahl der Wörter zwischen den Abfragebegriffen ( N) innerhalb des Segments des Elements gezählt, das mit allen NEAR - oder ONEAR -Begriffen übereinstimmt.
NEAR oder ONEAR fungiert als Text mit Token. Dies bedeutet, dass Sonderzeichen wie Komma („ , “), Punkt („ . “), Doppelpunkt („ : “ ), oder Semikolon („ ; “ ) als Leerraum behandelt wird. Der Begriff „Abstand" bezieht sich auf Token innerhalb des indizierten Texts.
Wenn Sie ONEAR oder NEAR mit gleichen Operanden verwenden, funktioniert der Operator wie folgt:
near(a, a, n=x)
Diese Abfrage gibt immer true zurück, wenn mindestens eine Instanz des Buchstabens „ a"' im Kontext angezeigt wird. Dies bedeutet auch, dass NEAR nicht als COUNT-Operator verwendet werden kann. Weitere Informationen zum Zählen von Begriffsvorkommen finden Sie unter Operator COUNT.
Wenn NEAR auf Phrasen angewendet wird, werden ebenfalls sich überlappende Phrase im Text gefunden.
Wenn ein Token im übereinstimmenden Segment mehr als einen Operanden dem NEAR - oder dem ONEAR -Ausdruck zuordnet, kann die Abfrage die Elemente möglicherweise auch dann abgleichen, wenn die Anzahl der nicht übereinstimmenden Token innerhalb des übereinstimmenden Segments den Wert von N im Ausdruck des NEAR- oder des ONEAR-Operators überschreitet. Bei einer Überlappung kann es sich beispielsweise um sich überlappende Phrasen handeln. Wenn die Anzahl der Treffer bei Tokenüberlappungen O ist, gleicht die Abfrage Elemente ab, wenn nicht mehr als N+O nicht übereinstimmende Token innerhalb des übereinstimmenden Segments des Elements angezeigt werden.
NEAR or ONEAR with NOT
Der Operator NOT kann nicht innerhalb des Operators NEAR oder ONEAR verwendet werden. Die folgende FQL-Syntax ist nicht korrekt:
near(audi,not(bmw),n=2)
NOT
Gibt nur Elemente zurück, die dem Operanden nicht entsprechen. Der Operand kann ein beliebiger gültiger FQL-Ausdruck sein.
Syntax
not(operand)
Parameter
Nicht zutreffend
ONEAR
Die sortierte Variante von NEAR, die eine sortierte Zuordnung der Begriffe erfordert. The Operator ONEAR kann verwendet werden, um die Ergebnismenge auf Elemente mit N-Begriffen zu beschränken, die sich in einem bestimmten Abstand voneinander befinden.
Syntax
onear(arg, arg [, arg]* [, N=<numeric value>])
Parameter
| Parameter | Wert | Beschreibung |
|---|---|---|
| N | <numeric_value> | Gibt die maximale Anzahl von Wörtern an, die zwischen den Begriffen angezeigt werden darf (explizite Nähe). Wenn ONEAR mehr als zwei Operanden enthält, wird die maximale Anzahl der zwischen den Begriffen zulässigen Wörter ( N) innerhalb des ganzen Ausdrucks gezählt. Standardwert: 4 |
Beispiele
Beispiel 1. Mit dem folgenden Ausdruck werden Übereinstimmungen mit allen Instanzen der Wörter "cat", "dog", "fox" und "wolf" gesucht, die in dieser Reihenfolge angegeben sind und durch maximal vier indizierte Token getrennt sind.
onear(cat, dog, fox, wolf)
In der folgenden Tabelle finden Sie Beispiele für Zeichenfolgenwerte von verwalteten Eigenschaften und Angaben dazu, ob sie mit dem vorherigen Ausdruck übereinstimmen.
| Übereinstimmung? | Text |
|---|---|
| Ja | Die Abbildung zeigt eine Katze, einen Hund, einen Fuchs und einen Wolf. |
| Nein | Hunde, Füchse und Wölfe sind hundeartig, Katzen hingegen sind katzenartig. |
| Nein | Die Abbildung zeigt eine Katze mit einem Hund, einem Fuchs und einem Wolf. |
Beispiel 2. Der folgende Ausdruck stimmt (mit Wortstammerkennung) mit dem Text der zweiten Zeile der vorherigen Tabelle überein.
onear(dog, fox, wolf, cat, N=5)
Beispiel 3. Der folgende Ausdruck stimmt mit dem Text in der ersten und dritten Zeile der vorherigen Tabelle überein.
onear(cat, dog, fox, wolf, N=5)
Hinweise
Siehe auch NEAR.
OR
Gibt nur Elemente zurück, die mindestens einem der OR-Operanden entsprechen. Übereinstimmende Elemente werden in der dynamischen Rangfolge (Relevanzbewertung in der Ergebnismenge) weiter oben angegeben, wenn mehrere der OR -Operanden übereinstimmen. Bei den Operanden kann es sich um einen einzelnen Begriff oder einen beliebigen gültigen FQL-Unterausdruck handeln.
Syntax
or(operand, operand [,operand]*)
Parameter
Nicht zutreffend
Beispiele
Der folgende Ausdruck gleicht alle Elemente ab, bei denen der Standard-Volltextindex entweder „Katze" oder „Hund" enthält. Wenn der standardmäßige Volltextindex eines Elements sowohl "cat" als auch "dog" enthält, stimmt er überein und hat eine höhere dynamische Rangfolge, als wenn er nur eines der Token enthalten würde.
or(cat, dog)
PHRASE
Sucht nach einer exakten Tokenzeichenfolge.
Die PHRASE -Operanden können einzelne Begriffe sein. Platzhalter werden akzeptiert.
Syntax
phrase(term [, term]*)
Parameter
Nicht zutreffend
Hinweise
Siehe auch STRING.
RANGE
Der RANGE-Operator wird für numerische verwaltete Eigenschaften und verwaltete Eigenschaften vom Typ Datum/Uhrzeit verwendet. Dieser Operator ermöglicht Ausdrücke für die Bereichsübereinstimmung.
Syntax
range(start, stop [,from="GE"|"GT"] [,to="LE"|"LT"])
Parameter
| Parameter | Wert | Wert | Beschreibung |
|---|---|---|---|
| start | _<numeric_value>\ | <date/time_value>_ | Startwert für den Bereich. Verwenden Sie das reservierte Wort min, um anzugeben, dass der Bereich keine untere Grenze hat. |
| stop | _<numeric_value>\ | <date/time_value>_ | Endwert für den Bereich. Verwenden Sie das reservierte Wort max, um anzugeben, dass der Bereich keine obere Grenze hat. |
| Von | **GE\ | GT** | Optionaler Parameter, der das öffnende oder schließende Startintervall angibt. Gültige Werte:
|
| An | **LE\ | LT** | Optionaler Parameter, der das öffnende oder schließende Endintervall angibt. Gültige Werte:
|
Beispiele
Der folgende Ausdruck gleicht eine Beschreibungseigenschaft ab, die mit der Phrase „Große Errungenschaften" beginnt, die in Elementen mit einer Größe von mindestens 10.000 Byte angezeigt wird.
and(size:range(10000, max), description:starts-with("big accomplishments"))
STARTS-WITH
Gibt ein Wort oder eine Phrase an, die am Anfang einer verwalteten Eigenschaft angezeigt werden muss.
Syntax
starts-with(<term or phrase>)
Parameter
Nicht zutreffend
Beispiele
Mit dem folgenden Ausdruck werden übereinstimmende Elemente mit den Werten "Adam Jones sr" und "Adam Jones" in der verwalteten Eigenschaft author gesucht. Elemente mit dem Wert "Mr Adam Jones" stellen keine Übereinstimmung dar.
author:starts-with("adam jones")
Hinweise
Zusätzliche Hinweise zur Grenzübereinstimmung finden Sie unter ENDS-WITH.
STRING
Definiert eine boolesche Abgleichbedingung für eine Textzeichenfolge.
Der Operand ist eine Textzeichenfolge (ein oder mehrere Begriffe), die abgeglichen werden soll. Auf die Zeichenfolge folgt der Wert null, oder es folgen mehrere Parameter.
Der Parameter STRING kann auch als Typumwandlung verwendet werden. Die Abfrage string("24.5") beispielsweise behandelt den numerischen Wert „24.5" als Textzeichenfolge.
Syntax
string("<text string>"
[, mode=<mode>]
[, n=<near>]
[, weight=<n>]
[, linguistics=<on|off>]
[, wildcard=<on|off>])
Parameter
| Parameter | Wert | Beschreibung | ||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| mode | <mode> | Der Parameter mode gibt an, wie der Wert <text string> ausgewertet werden soll. Die folgende Liste enthält gültige Werte.
"PHRASE" - phrase(term [,term]*)
|
||||||||||||||
| n | <numeric_value> | Dieser Parameter gibt den maximalen Abstand eines Begriffs für mode= "NEAR" oder mode= "ONEAR" an. Die folgenden Ausdrücke sind gleichwertig: string("hello world", mode="NEAR", n=5)near(hello, world, n=5) Standard: 4 |
||||||||||||||
| weight | <numeric_value> | Dieser Parameter ist ein positiver numerischer Wert, der die Begriffsgewichtung für die dynamische Rangfolge angibt. Ein niedrigerer Wert gibt an, dass ein Begriff in der dynamischen Rangfolge weniger relevant ist. Ein höherer Wert gibt an, dass ein Begriff in der Rangfolge relevanter ist. Der Wert null für den gewichteten Parameter gibt an, dass ein Begriff für die dynamische Rangfolge nicht relevant ist. Der Parameter weight gilt für alle Begriffe im STRING-Ausdruck. TIPP: Der weight-Parameter ist nur für Volltextindex-Abfragen relevant. Standard: 100. | ||||||||||||||
| linguistics | on|off | Deaktiviert/Aktiviert alle Linguistik-Features für die Zeichenfolge (Lemmatisierung, Synonyme, Rechtschreibprüfung), wenn sie für die Abfrage aktiviert wurden. Mit diesem Parameter können Sie die linguistische Verarbeitung für einen bestimmten Begriff oder eine bestimmte Zeichenfolge ändern, während der Begriff oder die Zeichenfolge weiterhin für die Rangfolge relevant sein soll. Standard: "ON" | ||||||||||||||
| wildcard | on|off | Dieser Parameter steuert die Platzhaltererweiterung von Begriffen innerhalb der <Textzeichenfolge>. Diese Einstellung setzt alle Platzhaltereinstellungen in Abfrageparametern außer Kraft und ermöglicht die Aktivierung oder Deaktivierung von erweiterten Platzhalterzeichen für bestimmte Teile der Abfrage. Die folgenden Werte sind gültig:
|
Hinweis
In SharePoint gelten die Parameter minexpansion, maxexpansion und annotation_class für den Operator STRING als veraltet.
Beispiele
Beispiel 1. Da der Standardzeichenfolgenmodus „ PHRASE “ lautet, gibt jeder der folgenden Ausdrücke die gleichen Ergebnisse zurück.
"what light through yonder window breaks"string("what light through yonder window breaks")string("what light through yonder window breaks", mode="phrase")phrase(what, light, through, yonder, window, breaks)
Beispiel 2. Der folgende Zeichenfolgentokenausdruck und der Ausdruck mit dem AND-Operator geben dieselben Ergebnisse zurück.
string("cat dog fox", mode="and")and(cat, dog, fox)
Beispiel 3. Der folgende Zeichenfolgentokenausdruck und der Ausdruck mit dem OR-Operator geben dieselben Ergebnisse zurück.
string("coyote saguaro", mode="or")or(coyote, saguaro)
Beispiel 4. Der folgende Zeichenfolgentokenausdruck und der Ausdruck mit dem ANY-Operator geben dieselben Ergebnisse zurück.
string("coyote saguaro", mode="any")any(coyote, saguaro)
Beispiel 5. Der folgende Zeichenfolgentokenausdruck und der Ausdruck mit dem NEAR-Operator geben dieselben Ergebnisse zurück.
string("coyote saguaro", mode="near")near(coyote, saguaro)
Beispiel 6. Der folgende Zeichenfolgentokenausdruck und der Ausdruck mit dem NEAR-Operator geben dieselben Ergebnisse zurück.
string("cat dog fox wolf", mode="near", N=4)near(cat, dog, fox, wolf, N=4)
Beispiel 7. Der folgende Zeichenfolgentokenausdruck und der Ausdruck mit dem ONEAR-Operator geben dieselben Ergebnisse zurück.
string("cat dog fox wolf", mode="onear")onear(cat, dog, fox, wolf)
Beispiel 8. Mit dem folgenden Zeichenfolgentokenausdruck werden Übereinstimmungen für das Wort "nobler" mit deaktivierten linguistischen Features gesucht, weshalb für andere Wortformen (wie z. B. "ennobling") nicht mithilfe der Wortstammerkennung Übereinstimmungen gefunden werden.
string("nobler", linguistics="off")
Beispiel 9. Der Ausdruck erhöht jedoch die Position der Elemente, die den Begriff „Hund" enthalten, in der dynamischen Rangfolge stärker, als die von Elementen, die „Katze" enthalten.
or(string("cat", weight="200"), string("dog", weight="500"))
Hinweise
Relevanzgewichtung für die dynamische Rangfolge
Die Hauptauswirkung des Parameters weight betrifft OR -Abfragen. Er kann zudem eine gewisse Auswirkung auf AND -Abfragen haben. Der Algorithmus der dynamischen Rangfolge kann implizieren, dass verschiedene Begriffe eine unterschiedliche Relevanz in der Rangfolge haben, je nachdem, wo in dem Element die Begriffsübereinstimmung auftritt.
Dem Unterschied bei der Relevanz in der Rangfolge kann auch die Häufigkeit des Begriffs und die inverse Häufigkeit des Begriffs zugrunde liegen. Es folgt ein Beispiel:
- Abfrage:
and(string("a"), string("b", weight=200)) - Indexschema: Die verwaltete title -Eigenschaft hat eine höhere Gewichtung als die verwaltete body -Eigenschaft.
- Das Indexelement 1 enthält den Begriff „a" im Titel (title) und den Begriff „b" im Textkörper (body).
- Das Indexelement 2 enthält den Begriff „a" im Textkörper (body) und den Begriff „b" im Titel (title).
In diesem Beispiel erhält Element 2 die höchste Position in der Rangfolge, da die Elemente mit höherer Relevanz in der Rangfolge eine größere Verstärkung erhalten.
Tipp: Die relative Begriffsoptimierung (positiv oder negativ) wird auf die dynamische Rangfolgekomponente der Gesamtrangfolge angewendet. Die Rangberechnungen der Näheoptimierung (Abstand zwischen den Wörtern) werden nicht durch die Begriffsgewichtung beeinflusst. Die relative Gewichtung impliziert nicht immer, dass die Gesamtrangfolge für das Element entsprechend dem angegebenen Prozentsatz geändert wird. >Mit der folgenden Abfrage wird nach den Wörtern „peter“, „paul“ oder „mary“ gesucht, wobei „peter“ den doppelten Beitrag zur Rangfolge leistet wie die beiden anderen Wörter. >
or(peter, string("paul mary", mode="OR", weight=50))
Verarbeitung von Zeichenfolgen mit Sonderzeichen
Sonderzeichen wie Komma („,"), Semikolon („;"), Doppelpunkt („:"), Punkt („."), Minuszeichen („-"), Unterstrich („_"), oder Schrägstrich („/") werden innerhalb eines Zeichenfolgeausdrucks, der in doppelte Anführungszeichen eingeschlossen ist, als Leerzeichen behandelt. Dieses Verhalten steht im Zusammenhang mit dem Vorgang der Tokenisierung. Diese Zeichen schließen zudem eine implizite Phrasierung der Token ein, die durch diese Zeichen voneinander getrennt sind.
Die folgenden Abfrageausdrücke sind gleichwertig:
title:string("animals birds", mode="phrase")title:"animals/birds"title:string("animals/birds", mode="and")title:string("animals/birds", mode="or")
Die folgenden Abfrageausdrücke sind gleichwertig:
title:or(string("animals birds", mode="phrase"), string("animals insects", mode="phrase"))title:string("animals/birds animals/insects", mode="or")
Die folgenden Abfrageausdrücke sind gleichwertig:
body:string("help contoso com", mode="phrase")body:string("help@contoso.com")
Phrasenabgleich mit Token
Sie können mithilfe des STRING-Operators mit mode= "Ausdruck" oder dem PHRASE- Operator nach einer genauen Token-Zeichenfolge suchen.
Alle Ausdrucksvorgänge dieser Art setzen eine in Token übersetzte Übereinstimmung des Ausdrucks voraus. Dies bedeutet, dass Sonderzeichen wie Komma („ , "), Semikolon („ ; "), Doppelpunkt („ : "), Unterstrich („ _ "), Minuszeichen („ - ") oder Schrägstrich („ / ") als Leerzeichen behandelt werden. Dies bezieht sich auf den Tokenisierungsvorgang.
XRANK
Verstärkt den dynamischen Rang von Elementen basierend auf bestimmten Vorkommnissen von Begriffen im Vergleichsausdruck, ohne die Abfrage dahingehend zu verändern, welche Elemente mit der Abfrage übereinstimmen. Ein XRANK-Ausdruck besteht aus einer Komponente, die abgeglichen werden muss, dem Vergleichsausdruck und einer oder mehreren Komponenten, die nur in der dynamischen Rangfolge relevant sind, dem Rangausdruck. Es muss mindestens einer der Parameter angegeben werden, abgesehen von n, damit ein XRANK-Ausdruck gültig ist.
Match expressions kann ein beliebiger gültiger FQL-Ausdruck sein, einschließlich geschachtelter XRANK -Ausdrücke. Rank expressions kann ein beliebiger gültiger FQL-Ausdruck ohne XRANK-Ausdrücke sein. Wenn Ihre FQL-Abfragen über mehrere XRANK-Operatoren verfügen, wird der endgültige dynamische Rangfolgewert als Summe der Verstärkungen aller XRANK-Operatoren berechnet.
Hinweis
In SharePoint Server 2010 besaß der XRANK-Operator die beiden Parameter boost und boostall sowie die folgende Syntax: xrank(operand, rank-operand [, rank-operand]* [,boost=n] [,boostall=yes]). Diese Syntax und die dazugehörigen Parametern werden in SharePoint nicht mehr unterstützt. Wir empfehlen stattdessen, eine neue Syntax und neue Parameter zu verwenden.
Syntax
xrank(<match expression> [, <rank-expression>]*, rank-parameter[, rank-parameter]*)
Formel
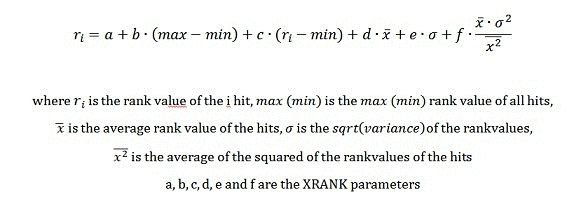
Parameter
| Parameter | Wert | Beschreibung |
|---|---|---|
| N | <integer_value> | Gibt die Anzahl der Ergebnisse für die Berechnung von Statistiken an. Dieser Parameter hat keine Auswirkungen auf die Anzahl der Ergebnisse, die durch die dynamische Rangfolge hinzu kommen; es handelt sich dabei lediglich um eine Methode zum Ausschließen irrelevanter Elemente aus den Berechnungen der Statistik. Standardwert: 0. Ein Nullwert trägt die Semantik aller Dokumente. |
| nb | <float_value> | Der Parameter nb verweist auf die normale Verstärkung. Dieser Parameter gibt den Faktor an, der mit dem Produkt der Abweichung und der Durchschnittsbewertung der Rangwerte der Ergebnisgruppe multipliziert wird. f in der XRANK-Formel. |
In der Regel ist die normale Verstärkung (nb) der einzige Parameter, der geändert wird. Dieser Parameter stellt das benötigte Steuerelement bereit, um ein bestimmtes Element höher oder niedriger zu stufen, ohne dabei die Standardabweichung zu berücksichtigen.
Erweiterte Parameter
Außerdem sind folgende erweiterte Parameter verfügbar. In der Regel werden sie jedoch nicht verwendet.
| Parameter | Wert | Beschreibung |
|---|---|---|
| cb | <float_value> | Der Parameter cb verweist auf die konstante Verstärkung. Standardwert: 0. a in der XRANK-Formel. |
| stdb | <float_value> | Der Parameter stdb verweist auf die Verstärkung der Standardabweichung. Standardwert: 0. e in der XRANK-Formel. |
| avgb | <float_value> | Der Parameter avgb verweist auf die durchschnittliche Verstärkung. Dieser Faktor wird mit dem Durchschnitt der Rangfolgewerte in der Ergebnismenge multipliziert. Standardwert: 0. d in der XRANK-Formel. |
| rb | <float_value> | Der Parameter rb verweist auf die Bereichsverstärkung. Dieser Faktor wird mit dem Bereich der Rangfolgewerte in der Ergebnisgruppe multipliziert. Standardwert: 0. b in der XRANK-Formel. |
| pb | <float_value> | Der Parameter pb verweist auf die Prozentwertverstärkung. Dieser Faktor wird im Vergleich zum Mindestwert des Korpus mit der Rangfolge des Elements multipliziert. Standardwert: 0. c in der XRANK-Formel. |
Beispiele
Beispiel 1. Der folgende Ausdruck gleicht Elemente ab, bei denen der Standard-Volltextindex den Begriff „Katze" oder „Hund" enthält. Der Ausdruck erhöht die dynamische Rangfolge der Elemente mit einer konstanten Verstärkung von 100 für Elemente, die zusätzlich den Begriff „Vollblutpferd" enthalten.
xrank(or(cat, dog), thoroughbred, cb=100)
Beispiel 2. Der folgende Ausdruck gleicht Elemente ab, bei denen der Standard-Volltextindex den Begriff „Katze" oder „Hund" enthält. Der Ausdruck erhöht die dynamische Rangfolge der Elemente mit einer normalen Verstärkung von 1,5 für Elemente, die zusätzlich den Begriff „Vollblutpferd" enthalten.
xrank(or(cat, dog), thoroughbred, nb=1.5)
Beispiel 3. Der folgende Ausdruck gleicht Elemente ab, bei denen der Standard-Volltextindex den Begriff „Katze" oder „Hund" enthält. Der Ausdruck erhöht die dynamische Rangfolge der Elemente mit einer konstanten Verstärkung von 100 und einer normalen Verstärkung von 1,5, für Elemente, die zusätzlich den Begriff „Vollblutpferd" enthalten.
xrank(or(cat, dog), thoroughbred, cb=100, nb=1.5)
Beispiel 4. Der folgende Ausdruck gleicht alle Elemente ab, die den Begriff „Tiere" enthalten und die dynamische Rangfolge wie folgt verstärken:
Die dynamische Rangfolge von Elementen, die den Begriff „Hunde" enthalten, werden um 100 Punkte verstärkt.
Die dynamische Rangfolge der Elemente, die den Begriff „Katzen" enthalten, werden um 200 Punkte verstärkt.
Die dynamische Rangfolge der Elemente, die die Begriffe „Hunde" und „Katzen" enthalten, werden um 300 Punkte verstärkt.
xrank(xrank(animals, dogs, cb=100), cats, cb=200)