Überprüfen der Datenqualitätsbewertungen von Datenressourcen
Nachdem Sie Datenqualitätsregeln erstellt und eine Data Quality-Überprüfung ausgeführt haben, erhalten Ihre Datenressourcen eine Datenqualitätsbewertung basierend auf den Ergebnissen Ihrer Regeln. In diesem Artikel wird beschrieben, wie Bewertungen berechnet werden, um Ihnen ein tieferes Verständnis ihrer Datenqualitätsergebnisse zu vermitteln, und Sie bei der Entwicklung von Aktionselementen zur Verbesserung der Integrität Ihrer Daten unterstützen.
Grundlegendes zu Datenqualitätsbewertungen
Das Ziel von Data Quality-Regeln besteht darin, eine Beschreibung des Zustands der Daten bereitzustellen. Es zeigt insbesondere, wie weit die Daten von dem idealen Zustand entfernt sind, der durch die Regeln beschrieben wird. Jede Regel erzeugt bei der Ausführung eine Bewertung, die beschreibt, wie nah sich die Daten am gewünschten Zustand befinden. Die meisten Regeln sind sehr einfach; Sie dividieren die Gesamtzahl der Zeilen, die die Bewertung bestanden haben, durch die Gesamtzahl der Zeilen, die zum Ergebnis gelangen.
Die Formel, mit der die Datenqualitätsbewertung für eine Regel anhand von Daten in einer Spalte berechnet wird, lautet:
[(total number of passed records)/(passed records + failed records + miscast records + empty records + ignored records)]
- Zähler = Anzahl der übergebenen Datensätze
- Nenner = Gesamtzahl der Datensätze (Anzahl der übergebenen Datensätze + Anzahl fehlerhafter Datensätze + Anzahl falsch umgewandelter Datensätze + Anzahl leerer + Anzahl ignorierter Datensätze)
- Passed : Anzahl der Datensätze, die eine angewendete Regel bestanden haben
- Unschätzbar – die spalten, die zum Auswerten dieser Regel erforderlich sind, sind nicht auswertbar.
- Fehler: Anzahl der Datensätze, bei denen eine angewendete Regel fehlgeschlagen ist
- Miscast: Der Datentyp der Ressource und der Typ, den der Kunde als nicht übereinstimmend aufgelistet hat. Es kann nicht in den ausgedrückten Typ konvertiert werden.
- Leer: NULL- oder leere Datensätze
- Ignoriert: Zeilen haben nicht an der Regelauswertung teilgenommen. Kunden können Zeilen ausdrücken, die ignoriert werden sollen. Wie alle Zeilen ignorieren, die E-Mail = "n/a" haben oder Alle Zeilen ignorieren, bei denen departmentCode = 'test' oder 'internal'
Microsoft Purview Data Quality gibt dann einen Eindruck für den Status jeder Spalte, indem eine Spaltenbewertung generiert wird. Diese Bewertung ist der Durchschnitt aller Bewertungen der Regeln für diese Spalte.

Nachdem die Spaltenbewertungen berechnet wurden, lautet die Formel, die zum Berechnen der durchschnittlichen prozentualen Datenqualitätsbewertung für Datenprodukte und Governancedomänen verwendet wird:
[(Percentage 1 + Percentage 2) / (Sample size 1 + Sample size 2)] x 100
(Die Bewertung wird mit 100 multipliziert, um die Lesbarkeit der Bewertungen zu verbessern.)
Beispielberechnung
Angenommen, es gibt eine Spalte, in der die Regel "Leere/leere Felder" nicht definiert ist. Dies bedeutet, dass NULL-Werte für diese Spalte zulässig sind. Daher filtern bestimmte Regeln wie die Regel für eindeutige Werte in diesem Fall NULL-Werte heraus.
Beispiel: Wenn das Medienobjekt 10.000 Zeilen in einer Tabelle enthält, aber 3.000 null sind und 500 nicht eindeutig sind, lautet die Bewertung: ((10000 - 3000 - 500)/(10000 - 3000) )* 100 = 93
Die NULL-Zeilen werden ignoriert, wenn die Daten ausgewertet und eine Bewertung ermittelt wird.
Bestimmte Regelbewertungen
Für benutzerdefinierte Regeln gibt es eine ähnliche Funktion wie für die Regel für eindeutige Werte, aber in diesem Fall ist der Filter nicht auf NULL-Werte, sondern auf den Filterausdruck festgelegt.
Einige Regeln, z. B. die Aktualitätsregel, sind entweder erfolgreich oder schlagen fehl. Ihre Bewertungen sind also entweder 0 oder 100. Außerdem wird die Aktualitätsregel auf der Ebene der Datenressource und nicht auf der Spaltenebene angewendet.
Regeldetails und Verlauf
Sie können die Details und den Verlauf der Regelbewertungen anzeigen, indem Sie eine Regel auswählen. Wenn Sie einen bestimmten Regelnamen auswählen und zur Registerkarte " Regelverlauf " navigieren, wird der Trend der verschiedenen Überprüfungsausführungen für die jeweilige Regel angezeigt.
Regeldetails enthalten Informationen zur Anzahl von Zeilen, die für die verschiedenen Ausführungen für die jeweilige Regel übergeben, fehlgeschlagen und ignoriert wurden. Bei Regeln, die sich im Entwurfszustand (OFF-Zustand) befinden, tragen ihre Bewertungen nicht zur globalen Bewertung bei. Regeln im Entwurfszustand werden bei Qualitätsüberprüfungen überhaupt nicht ausgeführt und weisen daher keine Bewertungen auf.
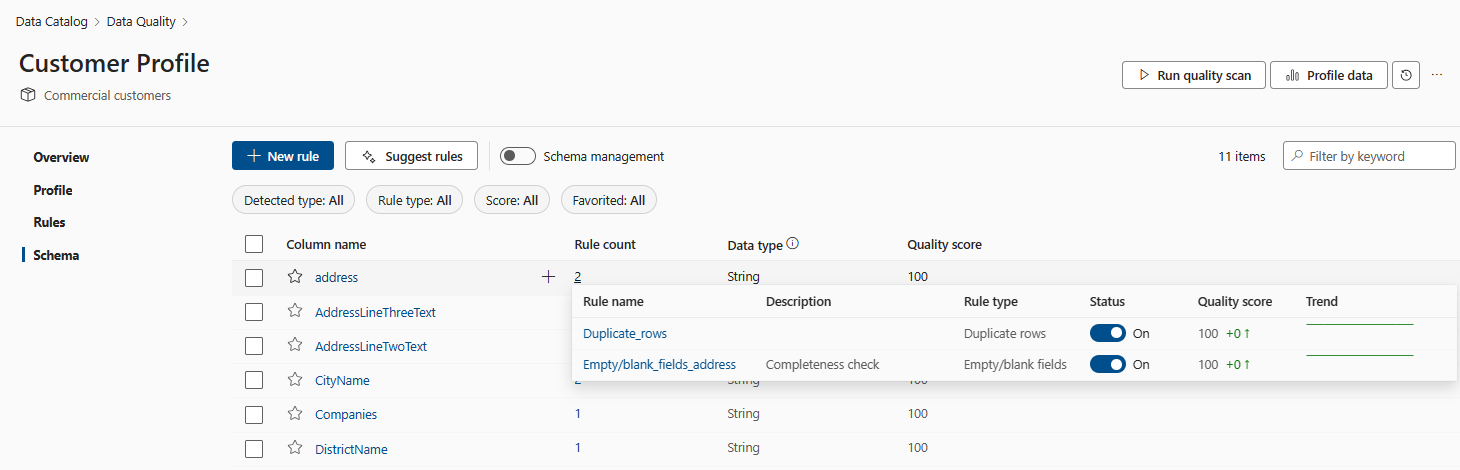
Spalten und Regeln haben eine m:n-Beziehung, dieselbe Regel kann auf viele Spalten angewendet werden, und viele Regeln können auf dieselbe Spalte angewendet werden. Sie können das Trendmuster jeder Regel anzeigen, indem Sie die Trendlinie im Bereich Schema anzeigen.
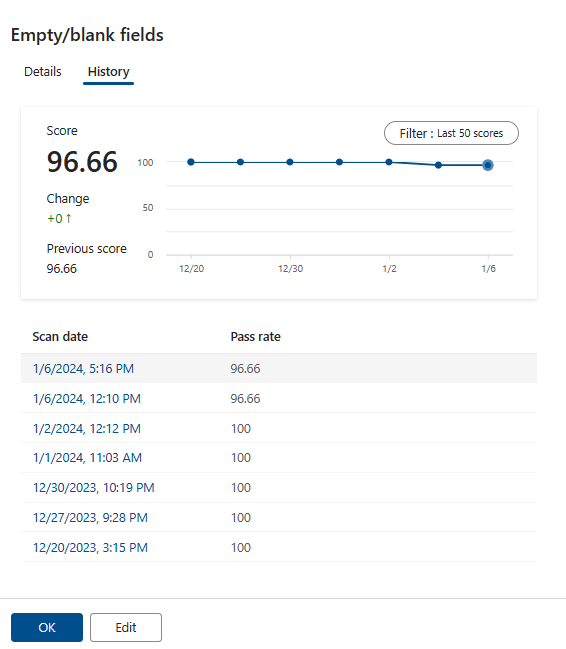
Trends zur Datenqualitätsbewertung auf Ressourcenebene sind für die letzten 50 Ausführungen verfügbar. Dieser Qualitätsbewertungstrend hilft Data Quality Stewards bei der Überwachung von Datenqualitätstrends und -schwankungen von Monat zu Monat. Die Datenqualität kann auch Warnungen für jede Datenqualitätsüberprüfung auslösen, wenn die Qualitätsbewertung den Schwellenwert oder die Geschäftserwartungen nicht erfüllt.
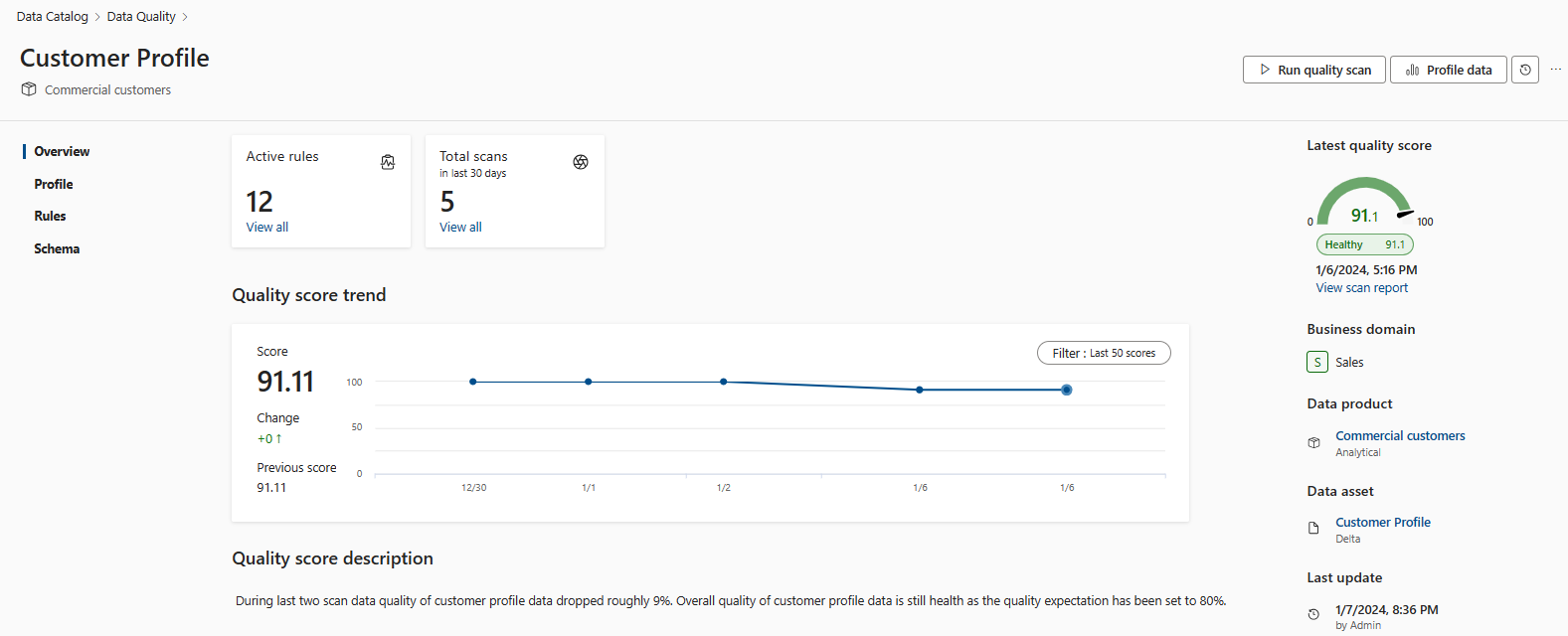
Die Globale Bewertung ist der Durchschnitt aller produktionsregel, die für die Ressource definiert sind. Die globale Bewertung auf Ressourcenebene wird auch auf die Datenprodukt- und Governancedomänenebene hochgerollt. Die Globale Bewertung soll die offizielle Definition des Zustands der Datenressource, des Datenprodukts und der Governancedomäne im Kontext der Datenqualität sein.
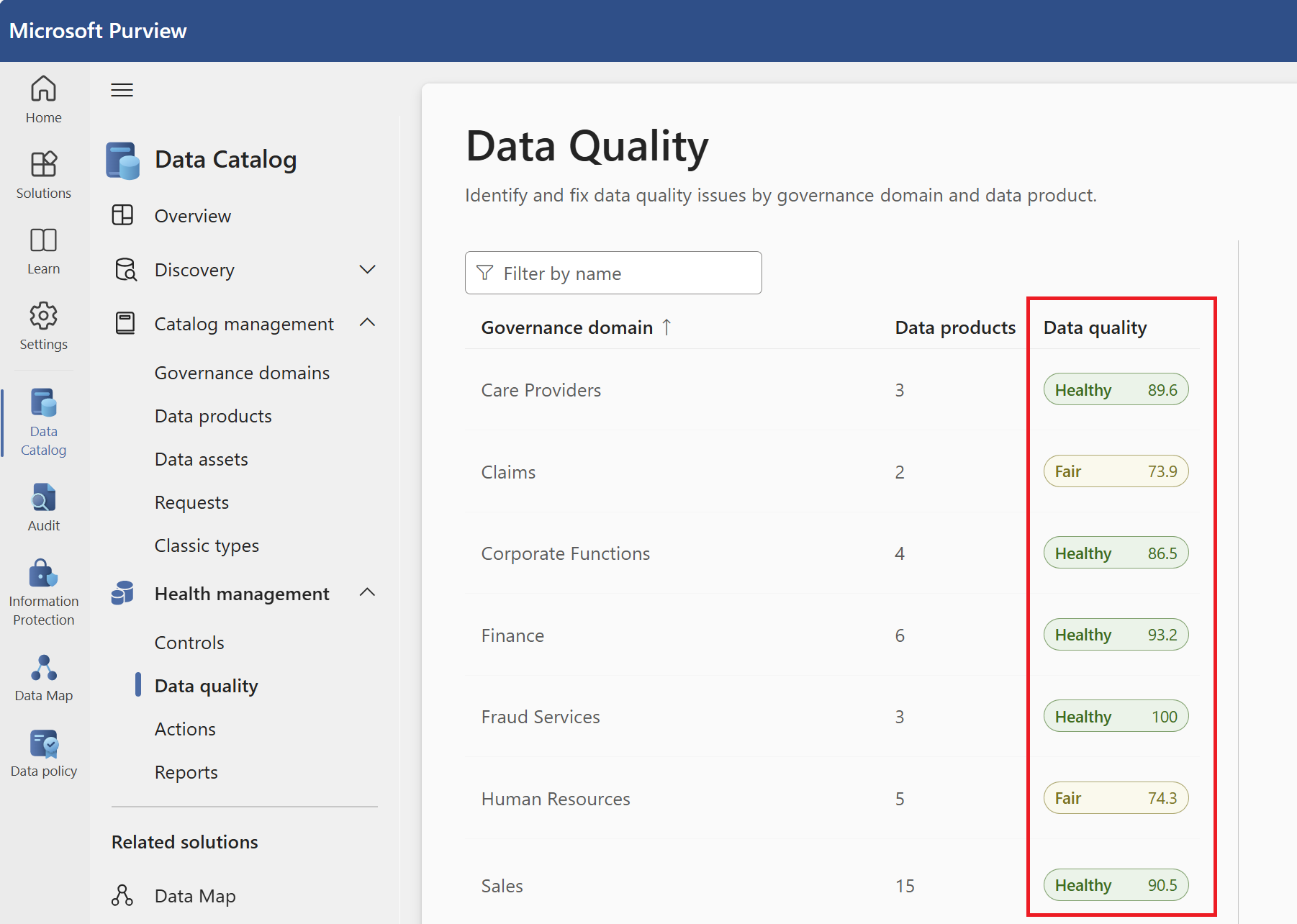
Für die Data Quality-Dimension wird ein Zusammenfassungsbericht erstellt. Dieser Bericht enthält eine Datenqualitätsbewertung für jede Data Quality-Dimension. Die globale Bewertung für die Governancedomäne wird ebenfalls in diesem Bericht veröffentlicht. Sie können die Qualitätsbewertung für jede Governancedomäne, jedes Datenprodukt und jede Datenressource in diesem Power BI-Bericht durchsuchen.



Hinweis
- Datenqualitätsdimensionen sind anerkannte Begriffe, die von Datenexperten verwendet werden, um ein Merkmal von Daten zu beschreiben, die anhand definierter Standards gemessen oder bewertet werden können, um das Qualitätsniveau der Daten zu quantifizieren, die zum Führen eines Unternehmens verwendet werden.
- Die Datenqualitätsbewertung für ein Medienobjekt ist der arithmetische Durchschnitt der Bewertungen der Regeln, die auf die zugehörigen Spalten angewendet werden.
- Die Datenqualitätsbewertung für ein Datenprodukt ist der arithmetische Durchschnitt der Datenqualitätsbewertungen der Datenressourcen, die diesem Datenprodukt zugeordnet sind.
- Die Datenqualitätsbewertung für eine Governancedomäne ist der arithmetische Durchschnitt der Datenqualitätsbewertungen der Datenprodukte, die dieser Domäne zugeordnet sind.