Datenqualität für gespiegelte Microsoft Fabric-Datenbanken
Als Datenreplikationslösung ist die Spiegelung in Fabric eine kostengünstige Lösung mit geringer Latenz, um Daten aus verschiedenen Systemen auf einer einzigen Analyseplattform zusammenzuführen. Sie können Ihren vorhandenen Datenbestand kontinuierlich direkt in OneLake von Fabric replizieren, einschließlich Daten aus Azure SQL Database, Azure Cosmos DB und Snowflake.
Durch die Spiegelung in Fabric können Benutzer ein End-to-End-Produkt nutzen, das Ihre Analyseanforderungen vereinfachen soll. Die Spiegelung wurde für Offenheit und Zusammenarbeit zwischen Microsoft und Technologielösungen entwickelt, die das Open-Source-Delta Lake-Tabellenformat lesen können. Die Spiegelung ist eine kostengünstige Lösung mit geringer Latenz, mit der Sie ein Replikat Ihrer Daten in OneLake erstellen können, das für alle Ihre analytischen Anforderungen verwendet werden kann. Weitere Informationen zur Fabric-Spiegelung finden Sie in der Fabric-Dokumentation.
Konfigurieren der Datenqualität für eine gespiegelte Fabric-Datenbank
Aktivieren Sie die Spiegelung in Ihrem Fabric-Mandanten. Power BI-Administratoren können die Spiegelung für die gesamte organization oder für bestimmte Sicherheitsgruppen mithilfe der Einstellung im Power BI-Verwaltungsportal aktivieren oder deaktivieren. Die Spiegelung wird aktiviert, indem eine sichere Verbindung mit Ihrer operativen Datenquelle hergestellt wird. Sie wählen aus, ob eine gesamte Datenbank oder einzelne Tabellen repliziert werden sollen. Durch die Spiegelung werden Ihre Daten automatisch synchronisiert. Nach der Einrichtung werden die Daten kontinuierlich in OneLake repliziert, um die Analyse zu nutzen.
Vergewissern Sie sich nach aktivierter Spiegelung und initiierter Replikation, dass die Spiegelungsreplikation erfolgreich abgeschlossen wurde.
Öffnen Sie den SQL-Analyseendpunkt.
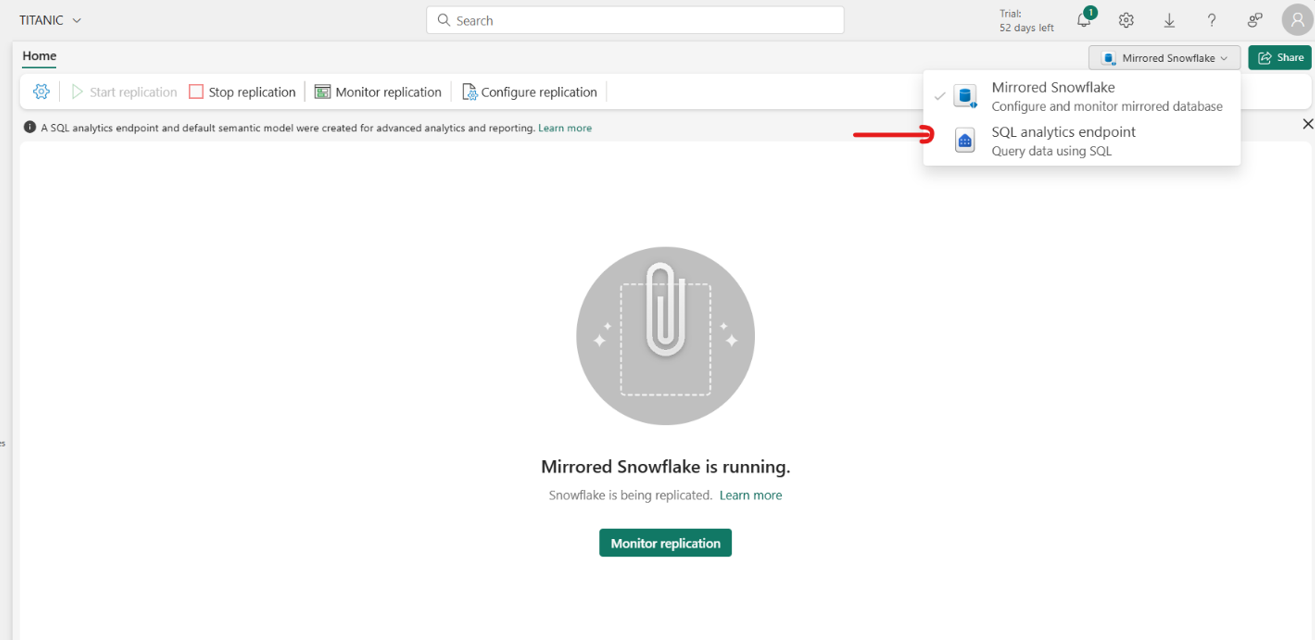
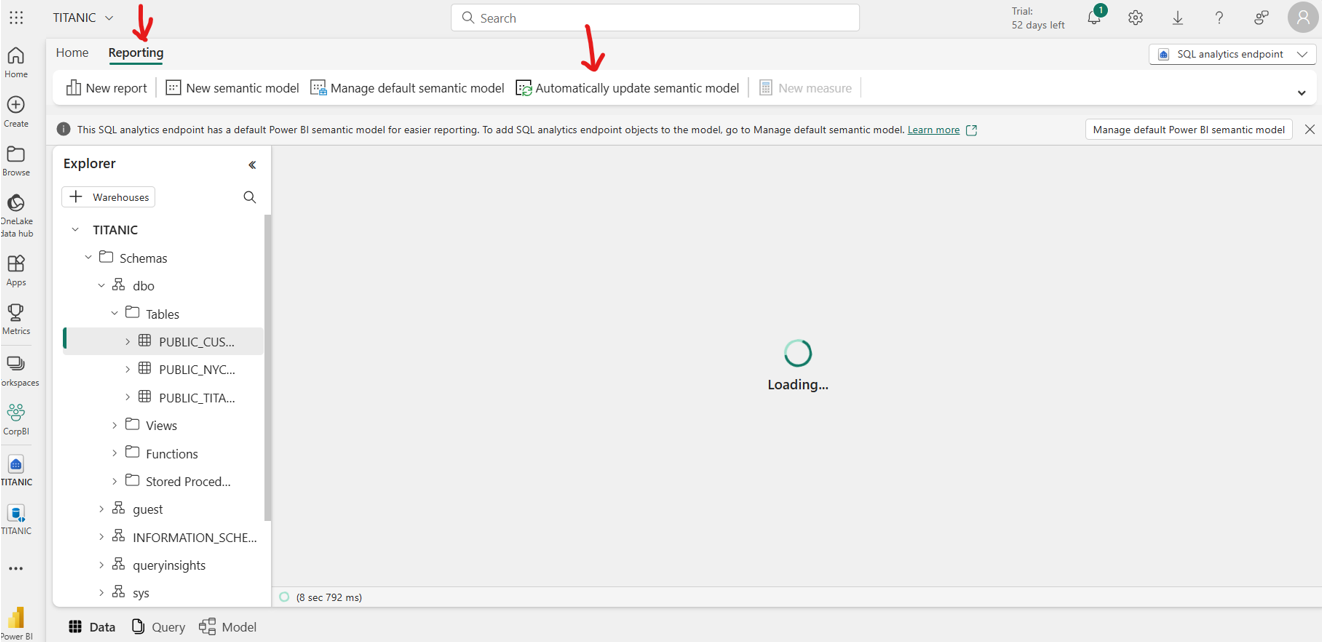
Wechseln Sie auf dieser Seite zur Registerkarte Berichterstellung, und wählen Sie Semantikmodell automatisch aktualisieren aus.
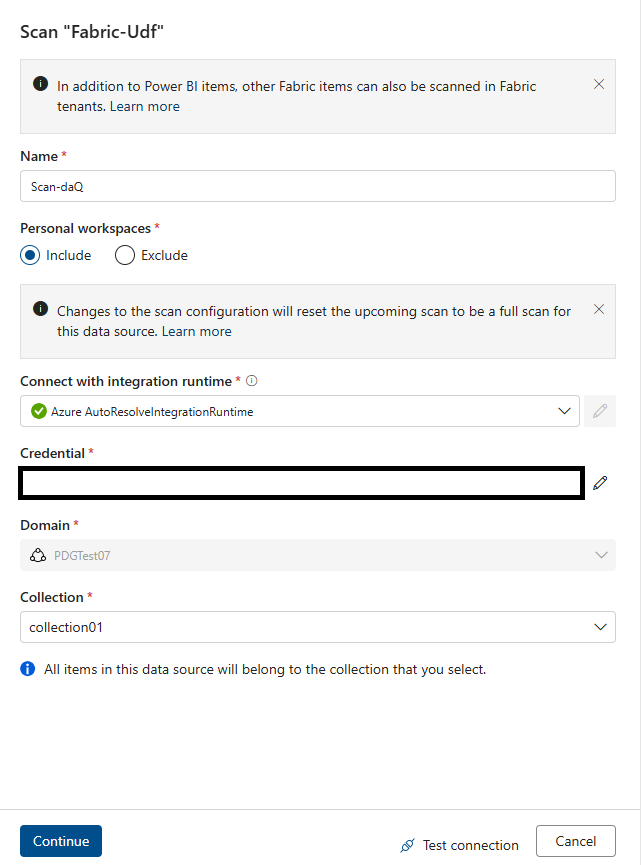
Wechseln Sie zur Seite Microsoft Purview Data Map, und überprüfen Sie die Datenquelle. Verwenden Sie die Dienstprinzipalauthentifizierung.
Ordnen Sie nach Abschluss der Überprüfung die neuen Datenassets einem Datenprodukt für die Zusammenstellung und Datenqualitätsbewertung zu.
Öffnen Sie die Microsoft Purview Data Quality Lösung, und führen Sie wie gewohnt einen Datenqualitätsscan oder ein Profil für Ihre Daten aus.


Wichtig
- Verwenden Sie Dienstprinzipale für Datenzuordnungsscans und eine verwaltete Identität für Datenqualitätsüberprüfungen.
- Wenn Ihre gespiegelten Datenbanktabellen in Fabric Lakehouse nicht verfügbar sind, wenden Sie sich an den Fabric-Support.
- Die Data Quality-Überprüfung wird nur für das Lakehouse-Delta-, Iceberg- und Parquet-Dateiformat unterstützt.
- Es gibt eine Abhängigkeit vom Fabric-Team, um Verknüpfungselemente von nativen Elementen in den Unterartikeln des OneLake SDK für Lakehouse zu unterscheiden. Vorerst werden alle Verknüpfungselemente (Tabellen und Dateien) beim Scannen als native Elemente betrachtet.