Trainieren eines Vorhersagecodierungsmodells (Vorschau)
Tipp
eDiscovery (Vorschauversion) ist jetzt im neuen Microsoft Purview-Portal verfügbar. Weitere Informationen zur Verwendung der neuen eDiscovery-Benutzeroberfläche finden Sie unter Informationen zu eDiscovery (Vorschauversion).
Wichtig
Predictive Coding wurde zum 31. März 2024 eingestellt und ist in neuen eDiscovery-Fällen nicht verfügbar. Für vorhandene Fälle mit trainierten Vorhersagecodierungsmodellen können Sie weiterhin vorhandene Bewertungsfilter auf Prüfsätze anwenden. Sie können jedoch keine neuen Modelle erstellen oder trainieren.
Nachdem Sie ein Vorhersagecodierungsmodell in Microsoft Purview-eDiscovery (Premium) erstellt haben, besteht der nächste Schritt darin, die erste Trainingsrunde durchzuführen, um das Modell anhand der relevanten und nicht relevanten Inhalte in Ihrem Überprüfungssatz zu trainieren. Nachdem Sie die erste Trainingsrunde abgeschlossen haben, können Sie nachfolgende Trainingsrunden durchführen, um die Fähigkeit des Modells zur Vorhersage relevanter und nicht relevanter Inhalte zu verbessern.
Informationen zum Workflow für die Vorhersagecodierung finden Sie unter Informationen zur Vorhersagecodierung in eDiscovery (Premium).
Tipp
Wenn Sie kein E5-Kunde sind, verwenden Sie die 90-tägige Testversion von Microsoft Purview-Lösungen, um zu erfahren, wie zusätzliche Purview-Funktionen Ihre Organisation bei der Verwaltung von Datensicherheits- und Complianceanforderungen unterstützen können. Beginnen Sie jetzt im Microsoft Purview-Testversionshub. Erfahren Sie mehr über Anmelde- und Testbedingungen.
Vor dem Trainieren eines Modells
- Kennzeichnen Sie Elemente während einer Trainingsrunde basierend auf der Relevanz des Inhalts im Dokument als Relevant oder Nicht relevant . Stützen Sie ihre Entscheidung nicht auf die Werte in den Metadatenfeldern. Für E-Mail-Nachrichten oder Teams-Unterhaltungen sollten Sie ihre Bezeichnungsentscheidung beispielsweise nicht auf die Nachrichtenteilnehmer stützen.
Erstmaliges Trainieren eines Modells
Hinweis
Für eine begrenzte Zeit ist diese klassische eDiscovery-Erfahrung auch im neuen Microsoft Purview-Portal verfügbar. Aktivieren Sie die klassische eDiscovery-Benutzeroberfläche des Complianceportals in den Einstellungen für die eDiscovery-Benutzeroberfläche (Vorschau), um die klassische Benutzeroberfläche im neuen Microsoft Purview-Portal anzuzeigen.
Öffnen Sie im Microsoft Purview-Complianceportal einen eDiscovery (Premium)-Fall, und wählen Sie dann die Registerkarte Review sets (Prüfsätze) aus.
Öffnen Sie einen Überprüfungssatz, und wählen Sie dann Analytics>Predictive Coding (Vorschau) verwalten aus.
Wählen Sie auf der Seite Vorhersagecodierungsmodelle (Vorschau) das Modell aus, das Sie trainieren möchten.
Wählen Sie auf der Registerkarte Übersicht unter Runde 1 die Option Nächste Trainingsrunde starten aus.
Die Registerkarte Training wird angezeigt und enthält 50 Elemente, die Sie bezeichnen können.
Überprüfen Sie jedes Dokument, und wählen Sie dann am unteren Rand des Lesebereichs Relevant oder Nicht relevant aus, um es zu bezeichnen.
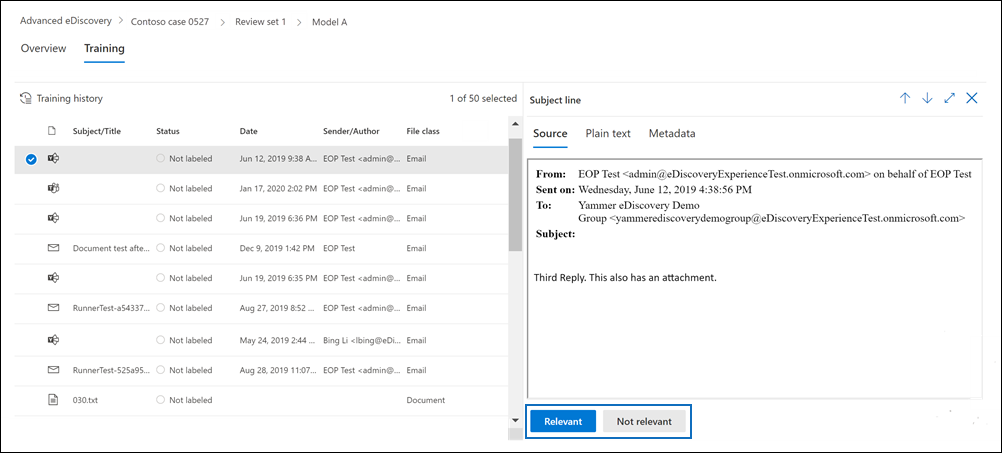
Nachdem Sie alle 50 Elemente beschriftet haben, wählen Sie Fertig stellen aus.
Es dauert einige Minuten, bis das System von Ihrer Bezeichnung "lernt" und das Modell aktualisiert. Wenn dieser Prozess abgeschlossen ist, wird auf der Seite Vorhersagecodierungsmodelle (Vorschau) eine status bereit für das Modell angezeigt.
Durchführen zusätzlicher Trainingsrunden
Nachdem Sie die erste Trainingsrunde durchgeführt haben, können Sie nachfolgende Trainingsrunden durchführen, indem Sie die Schritte im vorherigen Abschnitt ausführen. Der einzige Unterschied besteht darin, dass die Anzahl der Trainingsrunden auf der Registerkarte Übersicht des Modells aktualisiert wird. Nachdem Sie beispielsweise die erste Trainingsrunde durchgeführt haben, können Sie Nächste Trainingsrunde starten auswählen, um mit der zweiten Trainingsrunde zu beginnen. Und so weiter.
Jede Trainingsrunde (sowohl die in Bearbeitung als auch die abgeschlossenen) wird auf der Registerkarte Training für das Modell angezeigt. Wenn Sie eine Trainingsrunde auswählen, wird eine Flyoutseite mit Informationen und Metriken für die Runde angezeigt.
Was passiert, nachdem Sie eine Trainingsrunde durchgeführt haben
Nachdem Sie die erste Trainingsrunde durchgeführt haben, wird ein Auftrag gestartet, der die folgenden Aufgaben ausführt:
Basierend darauf, wie Sie die 40 Elemente im Trainingssatz bezeichnet haben, lernt das Modell aus Ihrer Bezeichnung und aktualisiert sich selbst, um genauer zu werden.
Das Modell verarbeitet dann jedes Element im gesamten Überprüfungssatz und weist eine Vorhersagebewertung zwischen 0 (nicht relevant) und 1 (relevant) zu.
Das Modell weist den 10 Elementen im Steuerelementsatz, die Sie während der Trainingsrunde bezeichnet haben, eine Vorhersagebewertung zu. Das Modell vergleicht die Vorhersagebewertung dieser 10 Elemente mit der tatsächlichen Bezeichnung, die Sie dem Element während der Trainingsrunde zugewiesen haben. Basierend auf diesem Vergleich identifiziert das Modell die folgende Klassifizierung (als Kontrollsatz-Konfusionsmatrix bezeichnet), um die Vorhersageleistung des Modells zu bewerten:
| Label | Das Modell sagt voraus, dass das Element relevant ist | Das Modell sagt voraus, dass das Element nicht relevant ist |
|---|---|---|
| Prüfer bezeichnet element als relevant | Wahr positiv | Falsch positiv |
| Prüfer bezeichnet Element als nicht relevant | Falsch negativ | Richtig negativ |
Basierend auf diesen Vergleichen leitet das Modell Werte für die F-Bewertung, Genauigkeit und Abrufmetriken sowie die Fehlerspanne für jede ab. Bewertungen für diese Modellleistungsmetriken werden auf einer Flyoutseite für die Trainingsrunde angezeigt. Eine Beschreibung dieser Metriken finden Sie unter Referenz zur Vorhersagecodierung.
- Schließlich bestimmt das Modell die nächsten 50 Elemente, die für die nächste Trainingsrunde verwendet werden. Dieses Mal kann das Modell 20 Elemente aus dem Steuerelementsatz und 30 neue Elemente aus dem Überprüfungssatz auswählen und sie als Trainingssatz für die nächste Runde festlegen. Die Stichprobenentnahme für die nächste Trainingsrunde wird nicht einheitlich entnommen. Das Modell optimiert die Stichprobenauswahl von Elementen aus dem Überprüfungssatz, um Elemente auszuwählen, bei denen die Vorhersage mehrdeutig ist, was bedeutet, dass die Vorhersagebewertung im Bereich von 0,5 liegt. Dieser Prozess wird als voreingenommene Auswahl bezeichnet.
Was geschieht, nachdem Sie nachfolgende Trainingsrunden durchgeführt haben?
Nachdem Sie nachfolgende Trainingsrunden (nach der ersten Trainingsrunde) durchgeführt haben, führt das Modell die folgenden Schritte aus:
- Das Modell wird basierend auf den Bezeichnungen aktualisiert, die Sie in dieser Trainingsrunde auf den Trainingssatz angewendet haben.
- Das System wertet die Vorhersagebewertung des Modells für die Elemente im Steuerelementsatz aus und überprüft, ob die Bewertung mit der Beschriftung von Elementen im Steuerelementsatz übereinstimmt. Die Auswertung erfolgt für alle bezeichneten Elemente aus dem Kontrollsatz für alle Trainingsrunden. Die Ergebnisse dieser Auswertung werden in die Dashboard auf der Registerkarte Übersicht für das Modell integriert.
- Das aktualisierte Modell verarbeitet jedes Element im Überprüfungssatz erneut und weist jedem Element eine aktualisierte Vorhersagebewertung zu.
Nächste Schritte
Nachdem Sie die erste Trainingsrunde durchgeführt haben, können Sie weitere Trainingsrunden durchführen oder den Vorhersagebewertungsfilter des Modells auf den Überprüfungssatz anwenden, um die Elemente anzuzeigen, die das Modell als relevant oder nicht relevant vorhergesagt hat. Weitere Informationen finden Sie unter Anwenden eines Vorhersagebewertungsfilters auf einen Überprüfungssatz.