SQL Server
Die besten Tipps für effektive Datenbankwartung
Paul S. Randal
Auf einen Blick:
- Verwalten von Daten- und Transaktionsprotokolldateien
- Beseitigen der Indexfragmentierung
- Gewährleisten korrekter, aktueller Statistiken
- Erkennen beschädigter Datenbankseiten
- Festlegen einer effektiven Sicherungsstrategie
Inhalt
Daten- und Protokolldateiverwaltung
Indexfragmentierung
Erkennen von Beschädigungen
Mehrmals pro Woche werde ich um Rat gefragt, wie eine Produktionsdatenbank effektiv gewartet werden kann. Manchmal kommen die Fragen von DBAs, die neue Lösungen implementieren und
bei der Feinabstimmung der Wartungsmethoden Hilfe benötigen, damit sie den Eigenschaften ihrer neuen Datenbanken entsprechen. Häufiger stammen die Fragen jedoch von Personen, die nicht von Berufs wegen DBAs sind, sich aber aus irgendeinem Grund um eine Datenbank kümmern und für sie verantwortlich sind. Ich bezeichne diese Rolle gerne als „unfreiwilliger DBA“. Schwerpunkt dieses Artikels ist eine Einführung in die bewährten Methoden der Datenbankwartung für alle unfreiwilligen DBAs.
Wie bei der Mehrzahl von Aufgaben und Verfahren in der IT-Welt gibt es keine einfache Standardlösung für die effektive Datenbankwartung, aber es gibt einige Hauptbereiche, die fast immer angesprochen werden müssen. Die wichtigsten fünf Bereiche sind für mich folgende (sie sind nicht nach Wichtigkeit sortiert):
- Daten- und Protokolldateiverwaltung
- Indexfragmentierung
- Statistiken
- Erkennen von Beschädigungen
- Sicherungen
Bei einer nicht (oder schlecht) gewarteten Datenbank können in einem oder mehreren dieser Bereiche Probleme entstehen, die schließlich zu schlechter Anwendungsleistung oder sogar Ausfallzeiten und Datenverlust führen können.
In diesem Artikel wird erläutert, warum diese Themen wichtig sind, und Sie erfahren, wie sie sich auf einfache Weise verringern lassen. Meine Erklärungen basieren auf SQL Server® 2005, aber es werden auch die Hauptunterschiede zu SQL Server 2000 sowie SQL Server 2008, dessen Veröffentlichung bevorsteht, beschrieben.
Daten- und Protokolldateiverwaltung
Der erste Bereich, dessen Überprüfung bei der Übernahme einer Datenbank immer empfehlenswert ist, betrifft Einstellungen im Zusammenhang mit der Daten- und (Transaktions-) Protokolldateiverwaltung. Insbesondere sollten Sie Folgendes sicherstellen:
- Die Daten- und Protokolldateien sind von einander getrennt und auch von allem anderen isoliert
- Automatische Vergrößerung ist richtig konfiguriert
- Sofortige Dateiinitialisierung ist konfiguriert
- Automatische Verkleinerung ist nicht aktiviert, und die Verkleinerung ist nicht Bestandteil eines Wartungsplans
Wenn Daten- und Protokolldateien (die im Idealfall sowieso auf separaten Volumes gespeichert sein sollten) ein Volume gemeinsam mit einer anderen Anwendung nutzen, die Dateien erstellt oder erweitert, besteht die Möglichkeit der Dateifragmentierung. In Datendateien kann übermäßige Dateifragmentierung zu Abfragen mit schlechter Leistung beitragen (v. a. bei Abfragen, die sehr große Datenmengen durchsuchen). In Protokolldateien kann dies weitaus größere Auswirkungen auf die Leistung haben, insbesondere wenn die automatische Vergrößerung die Dateigröße jedes Mal, wenn die Datei gebraucht wird, nur geringfügig erhöht.
Protokolldateien sind intern in Abschnitte unterteilt, die als virtuelle Protokolldateien (Virtual Log Files, VLFs) bezeichnet werden. Je stärker die Protokolldatei fragmentiert ist, desto mehr VLFs sind vorhanden (ich spreche hier absichtlich von nur einer Datei, da es nicht sinnvoll ist, mehrere Protokolldateien zu haben – es sollte nur eine pro Datenbank vorhanden sein). Wenn eine Protokolldatei mehr als etwa 200 VLFs hat, kann sich dies negativ auf protokollbezogene Vorgänge wie beispielsweise Protokolllesevorgänge (z. B. bei der Transaktionsreplikation/Rollback), Protokollsicherungen und sogar Trigger in SQL Server 2000 auswirken (das Implementieren von Triggern wurde in SQL Server 2005 zum Zeilenversionsverwaltungsframework anstelle des Transaktionsprotokolls geändert).
Die bewährte Methode hinsichtlich der Größenanpassung von Daten- und Protokolldateien besteht in ihrer Erstellung mit einer angemessenen Anfangsgröße. Bei Datendateien sollte die anfängliche Größe kurzfristig das Potenzial für das Hinzufügen zusätzlicher Daten zur Datenbank berücksichtigen. Wenn die anfängliche Größe der Daten beispielsweise 50 GB beträgt, aber bekannt ist, dass in den nächsten sechs Monaten zusätzlich 50 GB Daten hinzugefügt werden, ist es angebracht, die Datendatei von Anfang an mit einer Größe von 100 GB zu erstellen, statt sie mehrmals vergrößern zu müssen, bis sie diese Größe erreicht.
Bei Protokolldateien ist das Ganze leider ein wenig komplizierter, und es müssen beispielsweise folgende Faktoren berücksichtigt werden: die Transaktionsgröße (Transaktionen mit langer Laufzeit können erst nach ihrem Abschluss gelöscht werden) und die Häufigkeit der Protokollsicherung (da dadurch der inaktive Teil des Protokolls entfernt wird). Weitere Informationen finden Sie unter „8 Steps to Better Transaction Log Throughput“. Dabei handelt es sich um einen beliebten Blogbeitrag bei SQLskills.com, der von meiner Frau, Kimberly Tripp, geschrieben wird.
Nach ihrer Einrichtung sollten die Dateigrößen zu verschiedenen Zeiten überwacht und proaktiv manuell zu einer geeigneten Tageszeit vergrößert werden. Die automatische Vergrößerung sollte als Schutz für alle Fälle aktiviert bleiben, sodass Dateien bei Bedarf noch vergrößert werden können, falls ein ungewöhnliches Ereignis eintritt. Die Tatsache, dass die automatische Vergrößerung kleiner Mengen zur Dateifragmentierung führt, spricht dagegen, die Dateiverwaltung ganz der automatischen Vergrößerung zu überlassen. Zudem kann die automatische Vergrößerung ein zeitaufwändiger Prozess sein, der die Arbeit der Anwendung zu nicht vorhersehbaren Zeiten verzögert.
Die Größe für die automatische Vergrößerung sollte auf einen bestimmten Wert statt auf einen Prozentsatz eingestellt werden, um die beim Durchführen der automatischen Vergrößerung erforderliche Zeit sowie den benötigten Speicher zu begrenzen. Eine 100-GB-Datei könnte beispielsweise auf eine feststehende automatische Vergrößerung von 5 GB statt auf 10 Prozent eingestellt werden. Dies bedeutet, dass sie immer um 5 GB vergrößert wird, egal, wie groß die Datei schließlich ist, statt jedes Mal um eine immer größer werdende Menge (10 GB, 11 GB, 12 GB usw.) vergrößert zu werden, wenn die Datei wächst.
Wenn ein Transaktionsprotokoll (manuell oder automatisch) vergrößert wird, erfolgt die Initialisierung immer ab null. Datendateien haben dasselbe Standardverhalten in SQL Server 2000, aber seit SQL Server 2005 kann die sofortige Dateiinitialisierung aktiviert werden, die die Nullinitialisierung der Dateien überspringt, sodass die Vergrößerung und automatische Vergrößerung praktisch unmittelbar erfolgen. Entgegen der allgemeinen Auffassung ist dieses Feature in allen Editionen von SQL Server verfügbar. Um weitere Informationen zu erhalten, geben Sie „sofortige Dateiinitialisierung“ in den Index der Onlinedokumentation von SQL Server 2005 oder SQL Server 2008 ein.
Schließlich sollte darauf geachtet werden, dass die Verkleinerung keinesfalls aktiviert wird. Mithilfe der Verkleinerung kann die Größe einer Daten- oder Protokolldatei verringert werden, aber es ist ein sehr tiefgreifender Prozess, der viele Ressourcen beansprucht und sehr große Mengen an logischer Scanfragmentierung in Datendateien verursacht (weiter unten finden Sie weitere Informationen) und zu schlechter Leistung führt. Ich habe den SQL Server 2005-Eintrag in der Onlinedokumentation zum Thema Verkleinerung geändert, sodass er nun diesbezüglich eine Warnung enthält. Das manuelle Verkleinern einzelner Daten- und Protokolldateien ist jedoch unter bestimmten Umständen akzeptabel.
Die automatische Verkleinerung ist der größte Übeltäter, da sie alle 30 Minuten im Hintergrund startet und versucht, Datenbanken zu verkleinern, wenn die Option für die automatische Verkleinerung von Datenbanken auf „true“ gesetzt ist. Es ist ein ziemlich unvorhersehbarer Prozess, da er nur Datenbanken mit mehr als 25 Prozent freiem Speicherplatz verkleinert. Für die automatische Verkleinerung sind viele Ressourcen erforderlich, und sie verursacht eine Fragmentierung, die die Leistung senkt. Aus diesem Grund sollte davon abgesehen werden. Die automatische Verkleinerung sollte immer wie folgt ausgeschaltet werden:
ALTER DATABASE MyDatabase SET AUTO_SHRINK OFF;
Ein regelmäßiger Wartungsplan, der einen Befehl zum manuellen Verkleinern der Datenbank enthält, ist fast genauso schlecht. Wenn Sie feststellen, dass Ihre Datenbank fortwährend größer wird, nachdem sie gemäß Wartungsplan verkleinert wurde, ist dies darauf zurückzuführen, dass dieser Speicherplatz zum Ausführen der Datenbank erforderlich ist.
Es ist am besten, wenn die Datenbank auf eine stabile Zustandsgröße anwächst und grundsätzlich keine Verkleinerung durchgeführt wird. Weitere Informationen zu den Nachteilen der Verkleinerung sowie einige Kommentare zu den neuen Algorithmen in SQL Server 2005 finden Sie in meinem alten MSDN®-Blog unter blogs.msdn.com/sqlserverstorageengine/archive/tags/Shrink/default.aspx.
Indexfragmentierung
Neben der Fragmentierung auf Dateisystemebene und innerhalb der Protokolldatei ist es auch möglich, die Fragmentierung innerhalb der Datendateien durchzuführen, d. h. in den Strukturen, die die Tabellen- und Indexdaten speichern. Es gibt zwei grundlegende Arten der Fragmentierung, die innerhalb einer Datendatei stattfinden können:
- Fragmentierung innerhalb einzelner Daten- und Indexseiten (bisweilen als interne Fragmentierung bezeichnet)
- Fragmentierung innerhalb von Index- oder Tabellenstrukturen, die aus Seiten bestehen (bezeichnet als logische Scanfragmentierung und Blockscanfragmentierung)
Die interne Fragmentierung findet dort statt, wo viel leerer Speicherplatz auf einer Seite vorhanden ist. Wie in Abbildung 1 gezeigt, hat jede Seite in einer Datenbank eine Größe von 8 KB und einen 96-Byte-Seitenheader. Demzufolge kann eine Seite ungefähr 8096 Byte an Tabellen- oder Indexdaten speichern (bestimmte Tabellen- und Indexinterna für Daten- und Zeilenstrukturen sind in meinem Blog unter sqlskills.com/blogs/paul in der Kategorie „Inside The Storage Engine“ enthalten). Leerer Speicherplatz kann vorhanden sein, wenn jeder Tabellen- oder Indexdatensatz mehr als die Hälfte der Seitengröße einnimmt, da dann nur ein einziger Datensatz pro Seite gespeichert werden kann. Dies lässt sich nur sehr schwer oder gar nicht korrigieren, da dazu eine Tabellen- oder Indexschemaänderung erforderlich wäre, beispielsweise durch Ändern eines Indexschlüssels, sodass dieser keine zufälligen Einfügepunkte verursacht, wie dies bei einer GUID der Fall ist.
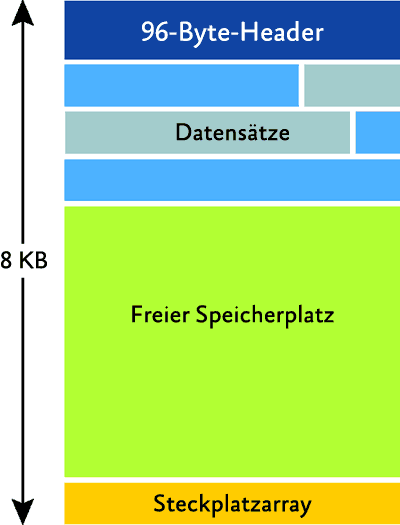
Abbildung 1 Die Struktur einer Datenbankseite (zum Vergrößern auf das Bild klicken)
Häufiger ist die interne Fragmentierung das Ergebnis von Datenänderungen wie beispielsweise Einfügungen, Aktualisierungen und Löschungen, die zu leerem Speicherplatz auf einer Seite führen können. Ein schlecht verwalteter Füllfaktor kann ebenfalls zur Fragmentierung beitragen. Die Onlinedokumentation enthält weitere Informationen dazu. In Abhängigkeit vom Tabellen-/Indexschema und den Eigenschaften der Anwendung kann dieser leere Speicherplatz nie wieder verwendet werden, nachdem er erstellt wurde, was zu ständig zunehmenden Mengen an unbrauchbarem Speicherplatz in der Datenbank führen kann.
Angenommen, Sie hätten eine Tabelle mit 100 Millionen Zeilen mit einer durchschnittlichen Datensatzgröße von 400 Byte. Im Laufe der Zeit hat jede Seite aufgrund des Datenänderungsmusters der Anwendung durchschnittlich 2800 Byte freien Speicherplatz. Der für die Tabelle erforderliche Gesamtspeicherplatz beträgt etwa 59 GB, der wie folgt berechnet wird: 8096-2800 / 400 = 13 Datensätze pro 8 KB-Seite. Anschließend wird 100 Millionen durch 13 geteilt, um die Anzahl der Seiten zu erhalten. Wenn der Speicherplatz nicht verschwendet würde, würden 20 Datensätze auf jede Seite passen, was den gesamten erforderlichen Speicherplatz auf 38 GB verringern würde. Das wäre eine große Einsparung!
Verschwendeter Speicherplatz auf Daten-/Indexseiten kann daher zu einem höheren Bedarf an Seiten führen, die dieselbe Datenmenge enthalten. Dies erfordert nicht nur mehr Festplattenspeicher, sondern bedeutet auch, dass eine Abfrage mehr E/As ausgeben muss, um dieselbe Datenmenge zu lesen. Alle diese zusätzlichen Seiten nehmen mehr Platz im Datencache und damit mehr Serverspeicher ein.
Die logische Scanfragmentierung wird durch einen als Seitenteilung bezeichneten Vorgang verursacht. Dazu kommt es, wenn ein Datensatz (gemäß der Indexschlüsseldefinition) auf einer bestimmten Indexseite eingefügt werden muss, aber auf der Seite nicht genug freier Speicherplatz vorhanden ist, um die eingefügten Daten aufzunehmen. Die Seite wird halbiert, und ungefähr 50 Prozent der Datensätze werden auf eine neu zugeordnete Seite verschoben. Diese neue Seite hängt normalerweise nicht physisch mit der alten Seite zusammen und wird daher als fragmentierte Seite bezeichnet. Die Blockscanfragmentierung ist vom Konzept her ähnlich. Die Fragmentierung innerhalb der Tabellen-/Indexstrukturen wirkt sich auf die Fähigkeit von SQL Server aus, effiziente Scans durchzuführen, sei es in einer gesamten Tabelle bzw. einem Index oder begrenzt durch eine WHERE-Abfrageklausel (z. B. SELECT * FROM MyTable WHERE Column1 > 100 AND Column1 < 4000).
Abbildung 2 zeigt neu erstellte Indexseiten mit 100 Prozent Füllfaktor und ohne Fragmentierung. Die Seiten sind voll, und die physische Reihenfolge der Seiten entspricht der logischen Reihenfolge. Abbildung 3 zeigt die Fragmentierung, die nach zufälligen Einfügungen/Aktualisierungen/Löschungen eintreten kann.
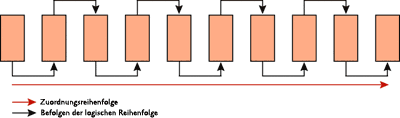
Abbildung 2 Neu erstellte Indexseiten ohne Fragmentierung; die Seiten sind 100 % voll (zum Vergrößern auf das Bild klicken)
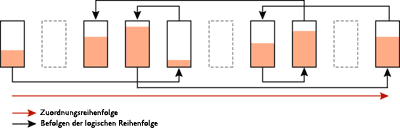
Abbildung 3 Indexseiten, die nach zufälligen Einfügungen, Aktualisierungen und Löschungen interne und logische Scanfragmentierung aufweisen (zum Vergrößern auf das Bild klicken)
Die Fragmentierung kann bisweilen verhindert werden, indem das Tabellen-/Indexschema verändert wird, aber wie oben bereits erwähnt, kann dies sehr schwierig oder unmöglich sein. Wenn das Verhindern keine Option ist, gibt es Möglichkeiten zum Entfernen der Fragmentierung, nachdem sie eingetreten ist, insbesondere beim Neuerstellen oder Neuorganisieren eines Index.
Beim Neuerstellen eines Index muss eine neue Kopie des Index – schön komprimiert und so zusammenhängend wie möglich – erstellt und der alte, fragmentierte Index gelöscht werden. Da SQL Server eine neue Kopie des Index erstellt, bevor der alte Index entfernt wird, ist freier Speicherplatz in den Datendateien erforderlich, der ungefähr der Größe des Index entspricht. In SQL Server 2000 war das Neuerstellen eines Index immer ein Offlinevorgang. In SQL Server 2005 Enterprise Edition kann das Neuerstellen des Index mit einigen Einschränkungen jedoch online erfolgen. Für die Neuorganisation andererseits wird ein direkter Algorithmus zum Komprimieren und Defragmentieren des Index verwendet. Zum Ausführen sind nur 8 KB zusätzlicher Speicherplatz erforderlich, und die Ausführung erfolgt immer online. Tatsächlich habe ich in SQL Server 2000 den Code für die Indexneuorganisation speziell als platzsparende Onlinealternative zum Neuerstellen eines Index geschrieben.
Die zu untersuchenden Befehle in SQL Server 2005 sind ALTER INDEX … REBUILD zum Neuerstellen von Indizes und ALTER INDEX … REORGANIZE, um sie neu zu organisieren. Diese Syntax ersetzt die SQL Server 2000-Befehle DBCC DBREINDEX bzw. DBCC INDEXDEFRAG.
Es gibt viele Kompromisse zwischen diesen Methoden, wie beispielsweise die Menge der generierten Transaktionsprotokollierung, die Menge des freien Speicherplatzes in der gewünschten Datenbank sowie die Frage, ob der Prozess ohne Arbeitsverlust unterbrochen werden kann. Ein Whitepaper, das diese Kompromisse erörtert und weitere Informationen enthält, finden Sie unter microsoft.com/technet/prodtechnol/sql/2000/maintain/ss2kidbp.mspx. Das Whitepaper basiert auf SQL Server 2000, aber die Konzepte lassen sich gut auf höhere Versionen übertragen.
Manche Administratoren entscheiden sich dafür, alle Indizes jede Nacht oder jede Woche (beispielsweise mithilfe einer Wartungsplanoption) neu zu erstellen oder neu zu organisieren, statt herauszufinden, welche Indizes fragmentiert sind und ob das Entfernen der Fragmentierung von Vorteil ist. Obwohl dies eine gute Lösung für einen unfreiwilligen DBA sein kann, der einfach mit geringem Aufwand etwas erreichen möchte, kann es bei größeren Datenbanken oder Systemen, für die Ressourcen eine große Rolle spielen, eine schlechte Wahl sein.
Ein ausgereifterer Ansatz besteht in der Verwendung der DMV sys.dm_db_index_physical_stats (oder DBCC SHOWCONTIG in SQL Server 2000), um regelmäßig zu bestimmen, welche Indizes fragmentiert sind, und dann zu entscheiden, ob und wie sie behandelt werden sollten. Im Whitepaper wird auch die Verwendung dieser zielgerichteteren Möglichkeiten erörtert. Zudem finden Sie weiteren Beispielcode für diese Filterung in Beispiel D des Onlinedokumentationseintrags für DMV sys.dm_db_index_physical_stats in SQL Server 2005 (msdn.microsoft.com/library/ms188917) oder Beispiel E im Onlinedokumentationseintrag für DBCC SHOWCONTIG in SQL Server 2000 und höher (unter msdn.microsoft.com/library/aa258803).
Unabhängig von der von Ihnen verwendeten Methode ist es äußerst ratsam, die Fragmentierung regelmäßig zu untersuchen und zu optimieren.
Der Abfrageprozessor ist der Teil von SQL Server, der entscheidet, wie eine Abfrage ausgeführt werden sollte, insbesondere welche Tabellen und Indizes verwendet und welche Vorgänge an ihnen durchgeführt werden sollten, um die Ergebnisse zu erhalten. Dies wird als Abfrageplan bezeichnet. Einige der wichtigsten Eingaben für diesen Entscheidungsfindungsprozess sind Statistiken, die die Verteilung der Datenwerte für Spalten innerhalb einer Tabelle oder eines Index beschreiben. Offensichtlich müssen Statistiken korrekt und aktuell sein, um für den Abfrageprozessor nützlich zu sein. Andernfalls könnten Abfragepläne mit schlechter Leistung ausgewählt werden.
Statistiken werden durch das Lesen der Tabellen-/Indexdaten und Bestimmen der Datenverteilung für die relevanten Spalten generiert. Statistiken können durch Scannen aller Datenwerte für eine bestimmte Spalte (vollständiger Scan) erstellt werden, aber sie können auch auf einem vom Benutzer angegebenen Prozentsatz der Daten (Stichprobenscan) basieren. Wenn die Verteilung der Werte in einer Spalte ziemlich gleichmäßig ist, sollte ein Stichprobenscan ausreichen. Auf diese Weise kann das Erstellen und Aktualisieren der Statistiken schneller als bei einem vollständigen Scan erfolgen.
Beachten Sie, dass Statistiken automatisch erstellt und verwaltet werden können, indem die Datenbankoptionen AUTO_CREATE_STATISTICS und AUTO_UPDATE_STATISTICS aktiviert werden, wie in Abbildung 4 dargestellt. Diese sind standardmäßig aktiviert, aber wenn Sie eine Datenbank gerade erst übernommen haben, sollten Sie dies sicherheitshalber überprüfen. Manchmal können Statistiken veraltet sein. In diesem Fall ist das manuelle Aktualisieren mithilfe des Vorgangs UPDATE STATISTICS bei besonderen Statistiksätzen möglich. Alternativ kann die gespeicherte Prozedur „sp_updatestats“ verwendet werden, die alle veralteten Statistiken aktualisiert (in SQL Server 2000 aktualisiert sp_updatestats alle Statistiken unabhängig vom Alter).
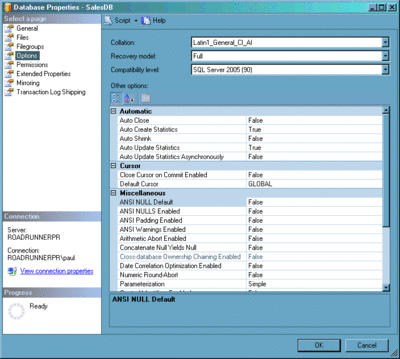
Abbildung 4 Ändern von Datenbankeinstellungen mithilfe von SQL Server Management Studio (zum Vergrößern auf das Bild klicken)
Wenn Sie Statistiken als Teil Ihres regelmäßigen Wartungsplans aktualisieren möchten, gibt es einen Haken, den Sie kennen sollten. Sowohl bei UPDATE STATISTICS als auch bei sp_updatestats wird (gegebenenfalls) standardmäßig die vorher angegebene Stichprobenstufe verwendet, und dabei kann es sich um weniger als einen vollständigen Scan handeln. Indexneuerstellungen aktualisieren Statistiken automatisch mit einem vollständigen Scan. Wenn Statistiken manuell nach einer Indexneuerstellung aktualisiert werden, besteht die Möglichkeit, dass die Statistiken nicht ganz korrekt sind! Dies kann geschehen, wenn ein Stichprobenscan aus der manuellen Aktualisierung den von der Indexneuerstellung generierten vollständigen Scan überschreibt. Andererseits werden Statistiken durch die Neuorganisation eines Index überhaupt nicht aktualisiert.
Auch hier gilt, dass viele Administratoren einen Wartungsplan haben, der alle Statistiken zu irgendeinem Zeitpunkt vor oder nach dem Neuerstellen aller Indizes aktualisiert, sodass sie schließlich unwissentlich weniger genaue Statistiken haben. Wenn Sie entscheiden, alle Indizes gelegentlich neu zu erstellen, bezieht dies auch die Statistiken mit ein. Wenn Sie sich für den komplexeren Weg der Defragmentierung entscheiden, sollte dies auch bei der Statistikwartung geschehen. Ich schlage Folgendes vor:
- Analysieren Sie Indizes, und legen Sie fest, welche Indizes behandelt werden sollen und wie die Defragmentierung erfolgen soll.
- Für alle Indizes, die nicht neu erstellt wurden, werden die Statistiken aktualisiert.
- Aktualisieren Sie die Statistiken für alle nicht indizierten Spalten.
Weitere Informationen zu Statistiken finden Sie im Whitepaper „Vom Abfrageoptimierer in Microsoft® SQL Server 2005 verwendete Statistiken“ (microsoft.com/technet/prodtechnol/sql/2005/qrystats.mspx).
Erkennen von Beschädigungen
Die leistungsbezogene Wartung wurde erörtert. Nun geht es um ein anderes Thema, nämlich das Erkennen und Begrenzen von Beschädigungen.
Es ist sehr unwahrscheinlich, dass die Datenbank, die Sie verwalten, völlig nutzlose Informationen enthält, die niemanden interessieren. Wie kann also dafür gesorgt werden, dass die Daten weiterhin vor Beschädigungen sicher sind und im Notfall wiederhergestellt werden können? Die Einzelheiten einer vollständigen Strategie für Notfallwiederherstellung und hohe Verfügbarkeit würden den Rahmen dieses Artikels sprengen, aber es gibt einige einfache Dinge, die Sie tun können.
Die überwältigende Mehrheit von Beschädigungen wird durch „Hardware“ verursacht. Warum ich das Wort in Anführungszeichen gesetzt habe? Hardware ist in diesem Fall eine Kurzbezeichnung für „etwas im E/A-Subsystem unterhalb von SQL Server“. Das E/A-Subsystem besteht aus Elementen wie beispielsweise dem Betriebssystem, den Dateisystemtreibern, Gerätetreibern, RAID-Controllern, Kabeln, Netzwerken und den eigentlichen Laufwerken. Dies sind viele Stellen, an denen Probleme auftreten können (was auch geschieht).
Zu einem der häufigsten Probleme kommt es bei einem Netzausfall, wenn ein Laufwerk gerade damit beschäftigt ist, eine Datenbankseite zu schreiben. Wenn das Laufwerk den Schreibvorgang nicht abschließen kann, bevor die Stromzufuhr unterbrochen wird (oder Schreibvorgänge zwischengespeichert werden und keine ausreichende Notfallenergieversorgung vorhanden ist, um den Cache des Laufwerks zu leeren), könnte das Ergebnis ein unvollständiges Seitenabbild auf dem Datenträger sein. Dies kann geschehen, da sich eine 8-KB-Datenbankseite aus 16 zusammenhängenden 512-Byte-Datenträgersektoren zusammensetzt. Ein unvollständiger Schreibvorgang könnte einige der Sektoren der neuen Seite geschrieben, aber einige Sektoren des vorherigen Seitenabbilds unverändert gelassen haben. Diese Situation wird als zerrissene Seite bezeichnet. Wie können Sie feststellen, ob dies geschehen ist?
SQL Server verfügt über eine Methode zum Erkennen dieser Situation. Dazu werden einige Bits von jedem Sektor der Seite gespeichert, und an ihrer Stelle wird ein bestimmtes Muster geschrieben (dies geschieht kurz bevor die Seite auf den Datenträger geschrieben wird). Wenn das Muster beim Wiedereinlesen der Seite nicht das gleiche ist, weiß SQL Server, dass die Seite „zerrissen“ war und gibt einen Fehler aus.
In SQL Server 2005 und höher steht eine umfassendere Methode mit der Bezeichnung „Seitenprüfsummen“ zur Verfügung, die Beschädigungen auf einer Seite erkennen kann. Dies beinhaltet das Schreiben einer ganzseitigen Prüfsumme auf der Seite, bevor sie geschrieben wird, und das Testen der Seite, wenn sie wieder eingelesen wird, genau wie dies beim Erkennen zerrissener Seiten der Fall ist. Nach dem Aktivieren der Seitenprüfsummen muss eine Seite in den Pufferpool eingelesen, geändert und dann wieder auf den Datenträger geschrieben werden, bevor sie durch eine Seitenprüfsumme geschützt wird.
Daher ist es eine bewährte Methode, Seitenprüfsummen ab SQL Server 2005 zu aktivieren und die Erkennung zerrissener Seiten in SQL Server 2000 zu aktivieren. Verwenden Sie zum Aktivieren von Seitenprüfsummen folgenden Befehl:
ALTER DATABASE MyDatabase SET PAGE_VERIFY CHECKSUM;
Zum Aktivieren der Erkennung zerrissener Seiten in SQL Server 2000 dient folgender Befehl:
ALTER DATABASE MyDatabase SET TORN_PAGE_DETECTION ON;
Mithilfe dieser Methoden können Sie erkennen, wenn eine Seite eine Beschädigung enthält, aber nur, wenn die Seite gelesen wird. Wie kann auf einfache Weise erzwungen werden, dass alle zugeordneten Seiten gelesen werden? Die beste Methode dafür (und für die Suche nach anderen Arten von Beschädigungen) ist der Befehl DBCC CHECKDB. Unabhängig von den angegebenen Optionen liest dieser Befehl immer alle Seiten in der Datenbank, sodass alle Seitenprüfsummen oder die Erkennung zerrissener Seiten überprüft werden. Sie sollten auch Warnungen einrichten, damit Sie wissen, wann Benutzern beim Ausführen von Abfragen Beschädigungsproblemen begegnen. Mithilfe einer Warnung für Fehler des Schweregrads 24 (Abbildung 5) können Sie über alle oben beschriebenen Probleme benachrichtigt werden.
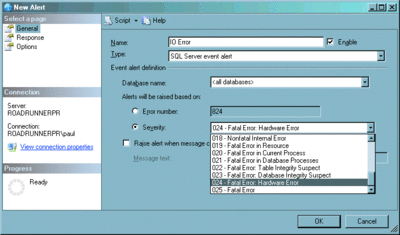
Abbildung 5 Einrichten einer Warnung für alle Fehler des Schweregrads 24 (zum Vergrößern auf das Bild klicken)
Eine weitere bewährte Methode besteht darin, bei Datenbanken regelmäßig DBCC CHECKDB zum Überprüfen ihrer Integrität auszuführen. Es gibt viele Variationen dieses Befehls sowie Fragen dazu, wie oft er ausgeführt werden sollte. Leider gibt es zu diesem Thema kein Whitepaper. Da DBCC CHECKDB jedoch das Hauptstück des Codes war, den ich für SQL Server 2005 geschrieben habe, habe ich diesbezüglich ausführliche Blogbeiträge verfasst. Die Kategorie „CHECKDB From Every Angle“ meines Blogs (sqlskills.com/blogs/paul) enthält viele ausführliche Artikel zur Konsistenzüberprüfung sowie bewährte Methoden und Anleitungen. Für unfreiwillige DBAs lautet die Faustregel, dass ein DBCC CHECKDB so oft wie eine vollständige Datenbanksicherung ausgeführt werden sollte (mehr dazu unten). Ich empfehle das Ausführen des folgenden Befehls:
DBCC CHECKDB ('MyDatabase') WITH NO_INFOMSGS,
ALL_ERRORMSGS;
Wenn dieser Befehl zu einer Ausgabe führt, hat DBCC einige Beschädigungen in der Datenbank gefunden. Jetzt stellt sich die Frage, was getan werden sollte, wenn DBCC CHECKDB Beschädigungen findet. Hier kommen Sicherungen ins Spiel.
Wenn es zu einer Beschädigung kommt oder ein anderer Notfall eintritt, besteht die wirksamste Wiederherstellungsmöglichkeit in der Wiederherstellung der Datenbank aus Sicherungen. Dies setzt natürlich voraus, dass Sicherungen vorhanden sind und dass sie selbst unbeschädigt sind. Häufig wird gefragt, wie eine stark beschädigte Datenbank wiederhergestellt werden kann, obwohl keine Sicherung vorhanden ist. Die einfache Antwort lautet, dass dies nicht möglich ist. Es wird immer zu einem gewissen Datenverlust kommen, der bei Ihrer Geschäftslogik und der relationalen Datenintegrität schweren Schaden anrichtet.
Dies ist also ein guter Grund für regelmäßig durchgeführte Sicherungen. Die Feinheiten beim Verwenden von Sicherungen und Wiederherstellung gehen weit über den Rahmen dieses Artikels hinaus, aber ich möchte eine kurze Einführung in das Einrichten einer Sicherungsstrategie geben.
Erstens sollten Sie regelmäßig vollständige Datenbanksicherungen durchführen. So verfügen Sie über eine Version zu einem bestimmten Zeitpunkt, die später wiederhergestellt werden kann. Sie können eine vollständige Datenbanksicherung mithilfe des Befehles BACKUP DATABASE durchführen. In der Onlinedokumentation finden Sie Beispiele. Als zusätzlichen Schutz können Sie die OPTION WITH CHECKSUM verwenden, die (gegebenenfalls) die Seitenprüfsummen der Seiten prüft, die gelesen werden, und eine Prüfsumme für die gesamte Sicherung berechnet. Dies sollte so häufig geschehen, dass nur eine begrenzte Menge an Daten oder Arbeiten in Ihrem Unternehmen verloren gehen kann. Wenn Sie beispielsweise einmal pro Tag eine vollständige Datenbanksicherung durchführen, können Sie in einem Notfall die Daten eines ganzen Tags verlieren. Wenn Sie nur vollständige Datenbanksicherungen verwenden, sollten Sie das Wiederherstellungsmodell SIMPLE verwenden (normalerweise als Wiederherstellungsmodus bezeichnet), um Schwierigkeiten hinsichtlich der Verwaltung des Transaktionsprotokollwachstums zu vermeiden.
Zweitens sollten Sicherungen immer ein paar Tage lang aufbewahrt werden, falls eine Sicherung beschädigt wird. Eine Sicherung, die einige Tage alt ist, ist immer besser als gar keine Sicherung. Sie sollten die Integrität Ihrer Sicherungen immer mithilfe des Befehls RESTORE WITH VERIFYONLY prüfen (weitere Informationen dazu finden Sie in der Onlinedokumentation). Wenn Sie beim Herstellen der Sicherung die Option WITH CHECKSUM verwendet haben, wird beim Ausführen des Überprüfungsbefehls geprüft, ob die Sicherungsprüfsumme noch gültig ist. Zudem werden alle Seitenprüfsummen der Seiten innerhalb der Sicherung erneut geprüft.
Drittens könnte es angebracht sein, differenzielle Datenbanksicherungen zu untersuchen, wenn eine tägliche, vollständige Datenbanksicherung es Ihnen nicht ermöglicht, den für Ihr Unternehmen tragbaren maximalen Daten-/Arbeitsverlust zu erreichen. Eine differenzielle Datenbanksicherung basiert auf einer vollständigen Datenbanksicherung und enthält einen Datensatz aller Änderungen seit der letzten vollständigen Sicherung (ein häufiger Irrtum ist, dass differenzielle Sicherungen inkrementell wären – sie sind es nicht). Eine Beispielstrategie könnte darin bestehen, eine täglichem, vollständige Datenbanksicherung mit einer differenziellen Datenbanksicherung alle vier Stunden durchzuführen. Eine differenzielle Sicherung bietet eine einzelne, zusätzliche Wiederherstellungsoption zu einem bestimmten Zeitpunkt. Wenn Sie nur vollständige Datenbank- und differenzielle Datenbankensicherungen verwenden, sollten Sie immer noch das Wiederherstellungsmodell SIMPLE verwenden.
Die ultimative Lösung bei der Wiederherstellbarkeit besteht in der Verwendung von Protokollsicherungen. Diese stehen nur in den Wiederherstellungsmodellen FULL (oder BULK_LOGGED) zur Verfügung und bieten die Sicherung aller Protokolldatensätze, die seit der vorherigen Protokollsicherung generiert wurden. Das Verwalten eines Satzes von Protokollsicherungen mit periodischen, vollständigen Datenbanksicherungen (und möglicherweise differenziellen Datenbanksicherungen) bietet eine unbegrenzte Zahl von Zeitpunkten, für die eine Wiederherstellung durchgeführt werden kann, einschließlich der minutengenauen Wiederherstellung. Der Kompromiss besteht dabei darin, dass das Transaktionsprotokoll weiter wächst, bis es durch eine Protokollsicherung „befreit“ wird. Eine mögliche Strategie wäre hier eine tägliche, vollständige Datenbanksicherung, eine differenzielle Datenbanksicherung alle vier Stunden sowie eine Protokollsicherung jede halbe Stunde.
Das Festlegen und Einrichten einer Sicherungsstrategie kann kompliziert sein. Zumindest sollten Sie eine regelmäßige, vollständige Datenbanksicherung durchführen, um sicherzustellen, dass mindestens ein Zeitpunkt vorhanden ist, für den eine Wiederherstellung durchgeführt werden kann.
Wie Sie sehen, gibt es einige Aufgaben, die unbedingt durchgeführt werden müssen, um sicherzustellen, dass Ihre Datenbank einwandfrei und verfügbar bleibt. Hier ist meine endgültige Checkliste für einen unfreiwilligen DBA, der eine Datenbank übernimmt:
- Entfernen Sie übermäßige Transaktionsprotokolldateifragmentierung.
- Stellen Sie die automatische Vergrößerung richtig ein.
- Schalten Sie geplante Verkleinerungsvorgänge aus.
- Schalten Sie die sofortige Dateiinitialisierung ein.
- Sorgen Sie dafür, dass Indexfragmentierung durch einen regelmäßigen Prozess erkannt und entfernt wird.
- Schalten Sie AUTO_CREATE_STATISTICS und AUTO_UPDATE_STATISTICS ein, und sorgen Sie dafür, dass Statistiken durch einen regelmäßigen Prozess aktualisiert werden.
- Schalten Sie Seitenprüfsummen (oder zumindest das Erkennen zerrissener Seiten in SQL Server 2000) ein.
- Es sollte ein regelmäßiger Prozess zum Ausführen von DBCC CHECKDB vorhanden sein.
- Es sollte ein regelmäßiger Prozess für vollständige Datenbanksicherungen sowie differenzielle Sicherungen und Protokollsicherungen für die Wiederherstellung für einen bestimmten Zeitpunkt vorhanden sein.
Ich habe in diesem Artikel T-SQL-Befehle angegeben, aber auch mit Management Studio kann viel getan werden. Ich hoffe, dies waren einige nützliche Hinweise für die effektive Datenbankwartung. Wenn Sie Feedback oder Fragen haben, schreiben Sie mir unter paul@sqlskills.com.
Paul S. Randal ist der leitende Direktor von SQLskills.com und ein SQL Server-MVP. Paul Randal war von 1999 bis 2007 im SQL Server-Speichermodulteam von Microsoft tätig. Er ist Experte für Notfallwiederherstellung, hohe Verfügbarkeit und Datenbankwartung. Sein Blog befindet sich unter SQLskills.com/blogs/paul.
© 2008 Microsoft Corporation und CMP Media, LLC. Alle Rechte vorbehalten. Die nicht genehmigte teilweise oder vollständige Vervielfältigung ist nicht zulässig.