Objekterkennung mithilfe von Fast R-CNN
Inhaltsverzeichnis
- Zusammenfassung
- Einrichtung
- Ausführen des Toy-Beispiels
- Trainieren von Pascal VOC-Daten
- Trainieren Sie CNTK Fast R-CNN auf Ihren eigenen Daten
- Technische Details
- Algorithmusdetails
Zusammenfassung


In diesem Lernprogramm wird beschrieben, wie Sie fast R-CNN in der CNTK Python-API verwenden. SchnelleS R-CNN mit BrainScript und cnkt.exe wird hier beschrieben.
Die obigen Beispiele sind Beispiele für Bilder und Objektanmerkungen für den Lebensmitteldatensatz (links) und den Pascal VOC-Dataset (rechts), der in diesem Lernprogramm verwendet wird.
Fast R-CNN ist ein Objekterkennungsalgorithmus, der 2015 von Ross Girshick vorgeschlagen wird. Das Papier wird an ICCV 2015 angenommen und archiviert unter https://arxiv.org/abs/1504.08083. Fast R-CNN baut auf früheren Arbeiten auf, um Objektvorschläge mithilfe von tiefen konvolutionalen Netzwerken effizient zu klassifizieren. Im Vergleich zu früheren Arbeiten verwendet Fast R-CNN eine Region von Interessenpooling-Schema , mit der die Berechnungen aus den konvolutionalen Ebenen wiederverwendet werden können.
Einrichten
Um den Code in diesem Beispiel auszuführen, benötigen Sie eine CNTK Python-Umgebung (siehe hier , um Hilfe zur Einrichtung zu erhalten). Installieren Sie die folgenden zusätzlichen Pakete in Ihrer cntk Python-Umgebung
pip install opencv-python easydict pyyaml dlib
Vorkompilierte Binärdateien für begrenzungsfeldregression und nicht maximale Unterdrückung
Der Ordner Examples\Image\Detection\utils\cython_modules enthält vorab kompilierte Binärdateien, die für die Ausführung von Fast R-CNN erforderlich sind. Die derzeit im Repository enthaltenen Versionen sind Python 3.5 für Windows und Python 3.5, 3.6 für Linux, alle 64 Bit. Wenn Sie eine andere Version benötigen, können Sie sie kompilieren, wenn Sie die schritte ausführen, die unter
- Linux: https://github.com/rbgirshick/py-faster-rcnn
- Windows: https://github.com/MrGF/py-faster-rcnn-windows
Kopieren Sie die generierten cython_bbox und cpu_nms (und/oder gpu_nms) Binärdateien von $FRCN_ROOT/lib/utils zu $CNTK_ROOT/Examples/Image/Detection/utils/cython_modules.
Beispieldaten und Basismodell
Wir verwenden ein vortrainiertes AlexNet-Modell als Basis für fast-R-CNN-Schulungen (für VGG oder andere Basismodelle siehe Verwenden eines anderen Basismodells). Sowohl das Beispiel-Dataset als auch das vorab trainierte AlexNet-Modell können heruntergeladen werden, indem sie den folgenden Python-Befehl aus dem FastRCNN-Ordner ausführen:
python install_data_and_model.py
- Erfahren Sie, wie Sie ein anderes Basismodell verwenden
- Erfahren Sie, wie Sie Fast R-CNN auf Pascal VOC-Daten ausführen
- Erfahren Sie, wie Sie fast R-CNN auf eigenen Daten ausführen.
Ausführen des Toy-Beispiels
So trainieren und bewerten Sie fast R-CNN-Ausführung
python run_fast_rcnn.py
Die Ergebnisse für Schulungen mit 2000 ROIs auf Lebensmittelgeschäften mit AlexNet als Basismodell sollten wie folgt aussehen:
AP for gerkin = 1.0000
AP for butter = 1.0000
AP for joghurt = 1.0000
AP for eggBox = 1.0000
AP for mustard = 1.0000
AP for champagne = 1.0000
AP for orange = 1.0000
AP for water = 0.5000
AP for avocado = 1.0000
AP for tomato = 1.0000
AP for pepper = 1.0000
AP for tabasco = 1.0000
AP for onion = 1.0000
AP for milk = 1.0000
AP for ketchup = 0.6667
AP for orangeJuice = 1.0000
Mean AP = 0.9479
So visualisieren Sie die vorhergesagten Begrenzungsfelder und Beschriftungen auf den Bildern, die aus dem FastRCNN Ordner geöffnet FastRCNN_config.py sind, und legen Sie fest
__C.VISUALIZE_RESULTS = True
Die Bilder werden im FastRCNN/Output/Grocery/ Ordner gespeichert, wenn Sie ausführen python run_fast_rcnn.py.
Zug auf Pascal VOC
Um die Pascal-Daten herunterzuladen und die Anmerkungsdateien für Pascal im CNTK-Format zu erstellen, führen Sie die folgenden Skripts aus:
python Examples/Image/DataSets/Pascal/install_pascalvoc.py
python Examples/Image/DataSets/Pascal/mappings/create_mappings.py
Ändern der dataset_cfg In-Methode get_configuration() in run_fast_rcnn.py
from utils.configs.Pascal_config import cfg as dataset_cfg
Jetzt legen Sie fest, dass Sie die Pascal VOC 2007-Daten verwenden python run_fast_rcnn.py. Achten Sie darauf, dass die Schulung eine Weile dauern kann.
Trainieren Ihrer eigenen Daten
Vorbereiten eines benutzerdefinierten Datasets
Option #1: Visual Object Tagging Tool (empfohlen)
Das Visual Object Tagging Tool (VOTT) ist ein plattformübergreifendes Anmerkungstool zum Kennzeichnen von Video- und Bildressourcen.

VOTT bietet die folgenden Features:
- Computergestütztes Tagging und Nachverfolgen von Objekten in Videos mithilfe des Camshift-Tracking-Algorithmus.
- Exportieren von Tags und Ressourcen in das CNTK Fast-RCNN-Format zur Schulung eines Objekterkennungsmodells.
- Ausführen und Überprüfen eines trainierten CNTK-Objekterkennungsmodells auf neuen Videos, um stärkere Modelle zu generieren.
So wird's mit VOTT kommentiert:
- Herunterladen der neuesten Version
- Folgen Sie der Readme , um einen Taggingauftrag auszuführen.
- Nach dem Markieren von Exporttags in das Datasetverzeichnis
Option #2: Verwenden von Anmerkungsskripts
Um ein CNTK Fast R-CNN-Modell auf Ihrem eigenen Datensatz zu trainieren, stellen wir zwei Skripts bereit, um rechteckige Regionen in Bildern zu kommentieren und diesen Regionen Bezeichnungen zuzuweisen.
Die Skripts speichern die Anmerkungen im richtigen Format, wie erforderlich durch den ersten Schritt der Ausführung von Fast R-CNN (A1_GenerateInputROIs.py).
Speichern Sie zuerst Ihre Bilder in der folgenden Ordnerstruktur
<your_image_folder>/negative- Bilder, die für Schulungen verwendet werden, die keine Objekte enthalten<your_image_folder>/positive- Bilder, die für Schulungen verwendet werden, die Objekte enthalten<your_image_folder>/testImages- Bilder, die zum Testen verwendet werden, die Objekte enthalten
Für die negativen Bilder müssen Sie keine Anmerkungen erstellen. Verwenden Sie für die anderen beiden Ordner die bereitgestellten Skripts:
- Führen Sie die Ausführung
C1_DrawBboxesOnImages.pyaus, um begrenzungsgebundene Felder auf den Bildern zu zeichnen.- Im Skriptsatz
imgDir = <your_image_folder>(/positiveoder/testImages) vor dem Ausführen. - Fügen Sie Anmerkungen mithilfe des Mauszeigers hinzu. Sobald alle Objekte in einem Bild kommentiert wurden, schreibt die TASTE "n" die bboxes.txt-Datei, und fahren Sie dann mit dem nächsten Bild fort, "u" rückgängig (d. h. entfernt) das letzte Rechteck, und "q" beendet das Anmerkungstool.
- Im Skriptsatz
- Führen Sie die Ausführung
C2_AssignLabelsToBboxes.pyaus, um den Begrenzungsfeldern Bezeichnungen zuzuweisen.- Im Skriptsatz
imgDir = <your_image_folder>(/positiveoder/testImages) vor dem Ausführen... - ... und passen Sie die Klassen im Skript an, um Ihre Objektkategorien widerzuspiegeln, z. B
classes = ("dog", "cat", "octopus"). . - Das Skript lädt diese manuell kommentierten Rechtecke für jedes Bild, zeigt sie eins nacheinander an, und fordert den Benutzer auf, die Objektklasse bereitzustellen, indem er links neben dem Fenster auf die entsprechende Schaltfläche klickt. Grund-Wahrheitsanmerkungen, die entweder als "nicht entschieden" oder "ausgeschlossen" gekennzeichnet sind, werden vollständig von der weiteren Verarbeitung ausgeschlossen.
- Im Skriptsatz
Trainieren des benutzerdefinierten Datasets
Führen Sie nach dem Speichern Ihrer Bilder in der beschriebenen Ordnerstruktur aus, und kommentieren Sie sie bitte
python Examples/Image/Detection/utils/annotations/annotations_helper.py
nachdem Sie den Ordner in diesem Skript in Ihren Datenordner geändert haben. Erstellen Sie schließlich einen MyDataSet_config.py in dem Ordner, der utils\configs den vorhandenen Beispielen folgt:
__C.CNTK.DATASET == "YourDataSet":
__C.CNTK.MAP_FILE_PATH = "../../DataSets/YourDataSet"
__C.CNTK.CLASS_MAP_FILE = "class_map.txt"
__C.CNTK.TRAIN_MAP_FILE = "train_img_file.txt"
__C.CNTK.TEST_MAP_FILE = "test_img_file.txt"
__C.CNTK.TRAIN_ROI_FILE = "train_roi_file.txt"
__C.CNTK.TEST_ROI_FILE = "test_roi_file.txt"
__C.CNTK.NUM_TRAIN_IMAGES = 500
__C.CNTK.NUM_TEST_IMAGES = 200
__C.CNTK.PROPOSAL_LAYER_SCALES = [8, 16, 32]
Beachten Sie, dass __C.CNTK.PROPOSAL_LAYER_SCALES nicht für Fast R-CNN verwendet wird, nur für schnellere R-CNN.
So trainieren und bewerten Sie Fast R-CNN für Ihre Daten ändern sich dataset_cfg in der get_configuration() Methode von run_fast_rcnn.py
from utils.configs.MyDataSet_config import cfg as dataset_cfg
und ausführen python run_fast_rcnn.py.
Technische Details
Der Fast R-CNN-Algorithmus wird im Abschnitt " Algorithmusdetails " zusammen mit einer allgemeinen Übersicht über die Implementierung in der CNTK Python-API erläutert. Dieser Abschnitt konzentriert sich auf die Konfiguration von Fast R-CNN und die Verwendung verschiedener Basismodelle.
Parameter
Die Parameter werden in drei Teile gruppiert:
- Detektorparameter (siehe
FastRCNN/FastRCNN_config.py) - Parameter des Datasets (siehe Beispiel
utils/configs/Grocery_config.py) - Basismodellparameter (siehe Beispiel
utils/configs/AlexNet_config.py)
Die drei Teile werden geladen und in der get_configuration() Methode zusammengeführt.run_fast_rcnn.py In diesem Abschnitt werden die Detektorparameter behandelt. Hier werden Die Parameter des Datasets beschrieben, basismodellparameter hier. Im Folgenden durchlaufen wir die wichtigsten Parameter in FastRCNN_config.py. Alle Parameter werden auch in der Datei kommentiert. Die Konfiguration verwendet das EasyDict Paket, das einfachen Zugriff auf geschachtelte Wörterbücher ermöglicht.
# Number of regions of interest [ROIs] proposals
__C.NUM_ROI_PROPOSALS = 200 # use 2000 or more for good results
# the minimum IoU (overlap) of a proposal to qualify for training regression targets
__C.BBOX_THRESH = 0.5
# Maximum number of ground truth annotations per image
__C.INPUT_ROIS_PER_IMAGE = 50
__C.IMAGE_WIDTH = 850
__C.IMAGE_HEIGHT = 850
# Use horizontally-flipped images during training?
__C.TRAIN.USE_FLIPPED = True
# If set to 'True' conv layers weights from the base model will be trained, too
__C.TRAIN_CONV_LAYERS = True
Die ROI-Vorschläge werden in der ersten Epoche in der ersten Epoche mithilfe der selektiven Suchimplementierung aus dem dlib Paket berechnet. Die Anzahl der generierten Vorschläge wird vom __C.NUM_ROI_PROPOSALS Parameter gesteuert. Es wird empfohlen, rund 2000 Vorschläge zu verwenden. Der Regressionskopf wird nur auf diesen ROIs trainiert, die eine Überschneidung (IoU) mit einem Boden wahrheitsfeld von mindestens __C.BBOX_THRESHhaben.
__C.INPUT_ROIS_PER_IMAGE Gibt die maximale Anzahl der Grund-Wahrheitsanmerkungen pro Bild an. CNTK muss derzeit eine maximale Zahl festlegen. Wenn weniger Anmerkungen vorhanden sind, werden sie intern gepolstert. __C.IMAGE_WIDTH und __C.IMAGE_HEIGHT sind die Dimensionen, die verwendet werden, um die Größe zu ändern und die Eingabebilder zu paden.
__C.TRAIN.USE_FLIPPED = True wird die Schulungsdaten erweitern, indem alle Bilder jeder anderen Epoche gedreht werden, d. h. die erste Epoche hat alle regulären Bilder, die zweite hat alle Bilder gedreht und so weiter. __C.TRAIN_CONV_LAYERS bestimmt, ob die konvolutionalen Ebenen, von eingaben zur Konvolutional feature map, trainiert oder behoben werden. Das Beheben der Konvschichtgewichte bedeutet, dass die Gewichte aus dem Basismodell genommen und nicht während des Trainings geändert werden. (Sie können auch angeben, wie viele Konvebenen Sie trainieren möchten, siehe Abschnitt Verwenden eines anderen Basismodells).
# NMS threshold used to discard overlapping predicted bounding boxes
__C.RESULTS_NMS_THRESHOLD = 0.5
# If set to True the following two parameters need to point to the corresponding files that contain the proposals:
# __C.DATA.TRAIN_PRECOMPUTED_PROPOSALS_FILE
# __C.DATA.TEST_PRECOMPUTED_PROPOSALS_FILE
__C.USE_PRECOMPUTED_PROPOSALS = False
__C.RESULTS_NMS_THRESHOLD ist der NMS-Schwellenwert, der zum Verwerfen von überlappenden Feldern in der Auswertung verwendet wird. Ein niedrigerer Schwellenwert führt zu weniger Entfernungen und somit mehr vorhergesagten Begrenzungsfeldern in der endgültigen Ausgabe. Wenn Sie den Leser festlegen __C.USE_PRECOMPUTED_PROPOSALS = True , werden vorab komputierte ROIs aus Textdateien gelesen. Dies wird beispielsweise für Schulungen in Pascal VOC-Daten verwendet. Die Dateinamen __C.DATA.TRAIN_PRECOMPUTED_PROPOSALS_FILE und __C.DATA.TEST_PRECOMPUTED_PROPOSALS_FILE werden in Examples/Image/Detection/utils/configs/Pascal_config.py.
# The basic segmentation is performed kvals.size() times. The k parameter is set (from, to, step_size)
__C.roi_ss_kvals = (10, 500, 5)
# When doing the basic segmentations prior to any box merging, all
# rectangles that have an area < min_size are discarded. Therefore, all outputs and
# subsequent merged rectangles are built out of rectangles that contain at
# least min_size pixels. Note that setting min_size to a smaller value than
# you might otherwise be interested in using can be useful since it allows a
# larger number of possible merged boxes to be created
__C.roi_ss_min_size = 9
# There are max_merging_iterations rounds of neighboring blob merging.
# Therefore, this parameter has some effect on the number of output rectangles
# you get, with larger values of the parameter giving more output rectangles.
# Hint: set __C.CNTK.DEBUG_OUTPUT=True to see the number of ROIs from selective search
__C.roi_ss_mm_iterations = 30
# image size used for ROI generation
__C.roi_ss_img_size = 200
Die obigen Parameter konfigurieren die selektive Suche von dlib. Details finden Sie auf der dlib-Homepage. Die folgenden zusätzlichen Parameter werden verwendet, um generierte ROIs w.r.t. mindestens und maximale Seitenlänge, Bereich und Seitenverhältnis zu filtern.
# minimum relative width/height of an ROI
__C.roi_min_side_rel = 0.01
# maximum relative width/height of an ROI
__C.roi_max_side_rel = 1.0
# minimum relative area of an ROI
__C.roi_min_area_rel = 0.0001
# maximum relative area of an ROI
__C.roi_max_area_rel = 0.9
# maximum aspect ratio of an ROI vertically and horizontally
__C.roi_max_aspect_ratio = 4.0
# aspect ratios of ROIs for uniform grid ROIs
__C.roi_grid_aspect_ratios = [1.0, 2.0, 0.5]
Wenn selektive Suche mehr ROIs zurückgibt, als angefordert werden, werden sie zufällig abgefragt. Wenn weniger ROIs zusätzliche ROIs in einem regulären Raster mithilfe des angegebenen __C.roi_grid_aspect_ratiosRasters generiert werden.
Verwenden eines anderen Basismodells
Um ein anderes Basismodell zu verwenden, müssen Sie eine andere Modellkonfiguration in der get_configuration() Methode run_fast_rcnn.pyauswählen. Zwei Modelle werden sofort unterstützt:
# for VGG16 base model use: from utils.configs.VGG16_config import cfg as network_cfg
# for AlexNet base model use: from utils.configs.AlexNet_config import cfg as network_cfg
Um das VGG16-Modell herunterzuladen, verwenden Sie bitte das Downloadskript in <cntkroot>/PretrainedModels:
python download_model.py VGG16_ImageNet_Caffe
Wenn Sie ein anderes Basismodell verwenden möchten, müssen Sie z. B. die Konfigurationsdatei utils/configs/VGG16_config.py kopieren und entsprechend Ihrem Basismodell ändern:
# model config
__C.MODEL.BASE_MODEL = "VGG16"
__C.MODEL.BASE_MODEL_FILE = "VGG16_ImageNet_Caffe.model"
__C.MODEL.IMG_PAD_COLOR = [103, 116, 123]
__C.MODEL.FEATURE_NODE_NAME = "data"
__C.MODEL.LAST_CONV_NODE_NAME = "relu5_3"
__C.MODEL.START_TRAIN_CONV_NODE_NAME = "pool2" # __C.MODEL.FEATURE_NODE_NAME
__C.MODEL.POOL_NODE_NAME = "pool5"
__C.MODEL.LAST_HIDDEN_NODE_NAME = "drop7"
__C.MODEL.FEATURE_STRIDE = 16
__C.MODEL.RPN_NUM_CHANNELS = 512
__C.MODEL.ROI_DIM = 7
Um die Knotennamen Ihres Basismodells zu untersuchen, können Sie die plot() Methode verwenden cntk.logging.graph. Bitte beachten Sie, dass ResNet-Modelle derzeit nicht unterstützt werden, da die Roipooling in CNTK noch nicht unterstützt wird.
Algorithmusdetails
SchnelleS R-CNN
R-CNNs für die Objekterkennung wurden 2014 von Ross Girshick et al. vorgestellt und wurden gezeigt, dass frühere state-of-the-art-Ansätze auf einem der wichtigsten Objekterkennungsprobleme im Feld ausstehen: Pascal VOC. Seitdem wurden zwei Nachverfolgungspapiere veröffentlicht, die erhebliche Geschwindigkeitsverbesserungen enthalten: Fast R-CNN und Faster R-CNN.
Die Grundidee von R-CNN besteht darin, ein tiefes neurales Netzwerk zu nehmen, das ursprünglich für die Bildklassifizierung mit Millionen von annotierten Bildern trainiert wurde und ihn zum Zweck der Objekterkennung ändert. Die Grundidee aus dem ersten R-CNN-Papier wird in der nachstehenden Abbildung (aus dem Papier) dargestellt: (1) In einem ersten Schritt werden in einem ersten Schritt eine große Anzahl von Bereichsvorschlägen generiert. (3) Diese Regionsvorschläge oder Regionen von Interessen (ROIs) werden dann unabhängig vom Netzwerk gesendet, das einen Vektor von z. B. 4096 Gleitkommawerten für jeden ROI ausgibt. Schließlich wird (4) ein Klassifizierer gelernt, der die 4096-Float-ROI-Darstellung als Eingabe verwendet und eine Bezeichnung und Vertrauen für jeden ROI ausgibt.

Während dieser Ansatz in Bezug auf Genauigkeit gut funktioniert, ist es sehr kostspielig, zu berechnen, da das neurale Netzwerk für jeden ROI ausgewertet werden muss. Schnelle R-CNN adressiert diesen Nachteil, indem nur die meisten Netzwerkebenen ausgewertet werden (um spezifisch zu sein: die Konvolutionsebenen) eine einzelne Zeit pro Bild. Laut den Autoren führt dies zu einer Geschwindigkeit von 213 Mal während der Tests und einer 9x Geschwindigkeit während der Schulung ohne Genauigkeitsverlust. Dies wird durch Die Verwendung einer ROI-Pooling-Ebene erreicht, die den ROI auf die konvolutionale Featurezuordnung angibt und die maximale Poolung ausführt, um die gewünschte Ausgabegröße zu generieren, die die folgende Ebene erwartet.
Im in diesem Lernprogramm verwendeten AlexNet-Beispiel wird die ROI-Pooling-Ebene zwischen der letzten konvolutionalen Ebene und der ersten vollständig verbundenen Ebene platziert. Im unten dargestellten CNTK-Python-API-Code wird durch Klonen von zwei Teilen des Netzwerksconv_layers, der und der .fc_layers Das Eingabebild wird dann zuerst normalisiert, durch die Ebene, die roipooling Ebene und schließlich die Vorhersage- und fc_layers Regressionsköpfe hinzugefügt, conv_layersdie die Klassenbezeichnung und die Regressionskoeffizienten pro Kandidaten-ROI vorhersagen.
def create_fast_rcnn_model(features, roi_proposals, label_targets, bbox_targets, bbox_inside_weights, cfg):
# Load the pre-trained classification net and clone layers
base_model = load_model(cfg['BASE_MODEL_PATH'])
conv_layers = clone_conv_layers(base_model, cfg)
fc_layers = clone_model(base_model, [cfg["MODEL"].POOL_NODE_NAME], [cfg["MODEL"].LAST_HIDDEN_NODE_NAME], clone_method=CloneMethod.clone)
# Normalization and conv layers
feat_norm = features - Constant([[[v]] for v in cfg["MODEL"].IMG_PAD_COLOR])
conv_out = conv_layers(feat_norm)
# Fast RCNN and losses
cls_score, bbox_pred = create_fast_rcnn_predictor(conv_out, roi_proposals, fc_layers, cfg)
detection_losses = create_detection_losses(...)
pred_error = classification_error(cls_score, label_targets, axis=1)
return detection_losses, pred_error
def create_fast_rcnn_predictor(conv_out, rois, fc_layers, cfg):
# RCNN
roi_out = roipooling(conv_out, rois, cntk.MAX_POOLING, (6, 6), spatial_scale=1/16.0)
fc_out = fc_layers(roi_out)
# prediction head
cls_score = plus(times(fc_out, W_pred), b_pred, name='cls_score')
# regression head
bbox_pred = plus(times(fc_out, W_regr), b_regr, name='bbox_regr')
return cls_score, bbox_pred
Die ursprüngliche Caffe-Implementierung, die in den R-CNN-Dokumenten verwendet wird, finden Sie unter GitHub: RCNN, Fast R-CNN und Faster R-CNN.
SVM vs NN-Schulung
Patrick Buehler bietet Anweisungen zum Trainieren eines SVM auf der CNTK Fast R-CNN-Ausgabe (mit den 4096-Features aus der letzten vollständig verbundenen Ebene) sowie eine Diskussion über Pros und Cons hier.
Selektive Suche
Selektive Suche ist eine Methode zum Suchen eines großen Satz möglicher Objektspeicherorte in einem Bild, unabhängig von der Klasse des tatsächlichen Objekts. Es funktioniert durch Gruppieren von Bildpixeln in Segmente, und führen Sie dann hierarchische Clustering aus, um Segmente aus demselben Objekt in Objektvorschläge zu kombinieren.



Um die erkannten ROIs aus der selektiven Suche zu ergänzen, fügen wir ROIs hinzu, die das Bild bei verschiedenen Skalierungen und Seitenverhältnissen einheitlich abdecken. Das Bild links zeigt eine Beispielausgabe der selektiven Suche, bei der jeder mögliche Objektspeicherort durch ein grünes Rechteck visualisiert wird. ROIs, die zu klein sind, zu groß usw. werden verworfen (Mitte) und schließlich ROIs, die das Bild einheitlich abdecken (rechts). Diese Rechtecks werden dann als Regions-of-Interests (ROIs) in der R-CNN-Pipeline verwendet.
Das Ziel der ROI-Generation besteht darin, eine kleine Gruppe von ROIs zu finden, die jedoch so viele Objekte im Bild wie möglich abdecken. Diese Berechnung muss ausreichend schnell sein, während gleichzeitig Objektstandorte in unterschiedlichen Skalierungen und Seitenverhältnissen gefunden werden. Die selektive Suche wurde gezeigt, dass diese Aufgabe gut ausgeführt wird, und zwar mit guter Genauigkeit, um Die Handelsabschläge zu beschleunigen.
NMS (Nicht maximale Unterdrückung)
Objekterkennungsmethoden geben häufig mehrere Erkennungen aus, die dasselbe Objekt in einem Bild vollständig oder teilweise abdecken.
Diese ROIs müssen zusammengeführt werden, um Objekte zu zählen und ihre genauen Speicherorte im Bild abzurufen.
Dies wird traditionell mithilfe einer Technik namens "Non Maximum Suppression" (NMS) durchgeführt. Die von uns verwendete NMS-Version (und die auch in den R-CNN-Publikationen verwendet wurde) führt keine ROIs zusammen, sondern versucht stattdessen zu identifizieren, welche ROIs die tatsächlichen Speicherorte eines Objekts abdecken und alle anderen ROIs verwerfen. Dies wird durch die iterative Auswahl des ROI mit höchster Vertrauenswürdigkeit implementiert und alle anderen ROIs entfernt, die diesen ROI erheblich überlappen und für dieselbe Klasse klassifiziert werden. Der Schwellenwert für die Überschneidung kann in PARAMETERS.py (Details) festgelegt werden.
Erkennungsergebnisse vor (links) und nach (rechts) Nicht maximale Unterdrückung:


mAP (mitteldurchschnittliche Genauigkeit)
Sobald er trainiert wurde, kann die Qualität des Modells mithilfe verschiedener Kriterien gemessen werden, z. B. Genauigkeit, Rückruf, Genauigkeit, Bereichskurve usw. Eine allgemeine Metrik, die für die Pascal VOC-Objekterkennungs-Herausforderung verwendet wird, besteht darin, die Durchschnittliche Genauigkeit (AP) für jede Klasse zu messen. Die folgende Beschreibung der Durchschnittliche Genauigkeit wird von Everingham et al. genommen. Die mittlere Mittelwertgenauigkeit (mAP) wird berechnet, indem der Durchschnitt über die APs aller Klassen genommen wird.
Für eine bestimmte Aufgabe und Klasse wird die Genauigkeits-/Rückrufkurve aus der rangierten Ausgabe einer Methode berechnet. Der Rückruf wird als Anteil aller positiven Beispiele definiert, die über einer bestimmten Rangfolge bewertet wurden. Genauigkeit ist der Anteil aller Beispiele oberhalb dieser Rangfolge, die aus der positiven Klasse stammen. Die AP fasst die Form der Genauigkeits-/Rückrufkurve zusammen und wird als mittlere Genauigkeit bei einer Reihe von elf gleich leer gestellten Rückrufstufen definiert [0,0.1, . . . ,1]:
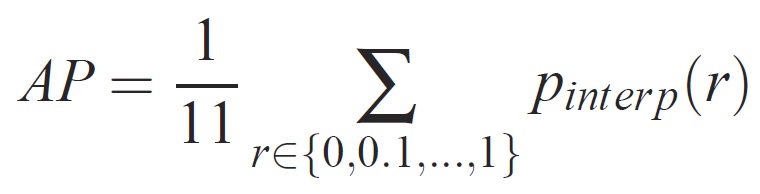
Die Genauigkeit auf jeder Rückrufstufe r wird interpoliert, indem die maximale Genauigkeit für eine Methode verwendet wird, für die der entsprechende Rückruf r überschreitet:
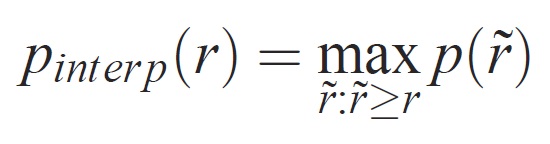
wobei p( ̃r) die gemessene Genauigkeit bei Rückruf ̃r ist. Die Absicht, die Genauigkeits-/Rückrufkurve auf diese Weise zu interpolieren, besteht darin, die Auswirkungen der "Wiggles" in der Genauigkeits-/Rückrufkurve zu verringern, die durch kleine Variationen in der Bewertung von Beispielen verursacht wird. Es sollte darauf hingewiesen werden, dass eine Methode eine hohe Bewertung erhalten soll, eine Methode auf allen Rückrufebenen präzise sein muss – dies bestraft Methoden, die nur eine Teilmenge von Beispielen mit hoher Genauigkeit abrufen (z. B. Seitenansichten von Autos).