Mehrere GPUs und Computer
1. Einführung
CNTK unterstützt derzeit vier parallele SGD-Algorithmen:
Voraussetzungen
Um parallele Schulungen auszuführen, stellen Sie sicher, dass eine Implementierung der Message Passing Interface (MPI) installiert ist:
Installieren Sie unter Windows Version 7 (7.0.12437.6) von Microsoft MPI (MS-MPI), eine Microsoft-Implementierung des Standards "Nachrichtenübergabeschnittstelle" aus dieser Downloadseite, die einfach als "Version 7" im Seitentitel gekennzeichnet ist. Klicken Sie auf die Schaltfläche "Herunterladen", und wählen Sie dann die Laufzeit (
MSMpiSetup.exe) aus.Installieren Sie unter Linux OpenMPI, Version 1.10.x. Folgen Sie den Anweisungen hier , um sie selbst zu erstellen.
2. Konfigurieren der parallelen Schulung in CNTK in Python
Um Daten parallele SGD in Python zu verwenden, muss der Benutzer einen verteilten Lerner an den Trainer erstellen und übergeben:
from cntk import distributed
...
learner = cntk.learner.momentum_sgd(...) # create local learner
distributed_after = epoch_size # number of samples to warm start with
distributed_learner = distributed.data_parallel_distributed_learner(
learner = learner,
num_quantization_bits = 32, # non-quantized gradient accumulation
distributed_after = 0) # no warm start
...
minibatch_source = MinibatchSource(...)
...
trainer = Trainer(z, ce, pe, distributed_learner)
...
session = training_session(trainer=trainer, mb_source=minibatch_source, ...)
session.train()
...
distributed.Communicator.finalize() # must be called to finalize MPI in case of successful distributed training
Für benutzerdefinierte Schulungsschleifen (anstelle von training_session) müssen Benutzer die Methode übergeben num_data_partitions und partition_indexMinibatchSource.next_minibatch() verwenden, sodass verschiedene MPI-Knoten Daten aus verschiedenen Datenpartitionen lesen (nachdem distributed_after Beispiele gelesen wurden).
Bitte beachten Sie, dass nur dann aufgerufen werden sollte, Communicator.finalize() wenn die verteilte Schulung erfolgreich abgeschlossen wurde. Falls ein verteilter Worker fehlschlägt, sollte diese Methode nicht aufgerufen werden.
Ein voll funktionsfähiges Beispiel finden Sie im ConvNet-Beispiel.
3. Konfigurieren der parallelen Schulung in CNTK in BrainScript
Um parallele Schulungen in CNTK BrainScript zu aktivieren, ist es zunächst erforderlich, den folgenden Schalter entweder in der Konfigurationsdatei oder in der Befehlszeile zu aktivieren:
parallelTrain = true
Zweitens sollte der SGD Block in der Konfigurationsdatei einen Unterblock enthalten, der mit den folgenden Argumenten benannt ParallelTrain ist:
parallelizationMethod: (obligatorisch) legitime Werte sindDataParallelSGD,BlockMomentumSGDundModelAveragingSGD.Dadurch wird angegeben, welcher parallele Algorithmus verwendet werden soll.
distributedMBReading: (optional) akzeptiert boolesche Werte:trueoderfalse; Standardwert istfalseEs wird empfohlen, den verteilten Minibatch zu aktivieren, um die I/O-Kosten in jedem Mitarbeiter zu minimieren. Wenn Sie CNTK-Textformatleser, Image Reader oder Composite Data Reader verwenden, sollte distributedMBReading auf "true" festgelegt werden.
parallelizationStartEpoch: (optional) akzeptiert ganzzahligen Wert; Standard ist 1.Dies gibt an, ab welcher Epoche parallele Schulungsalgorithmen verwendet werden; bevor alle Arbeitnehmer dieselben Schulungen ausführen, aber nur ein Mitarbeiter darf das Modell speichern. Diese Option kann nützlich sein, wenn parallele Schulungen einige "Warmstartphase" erfordern.
syncPerfStats: (optional) akzeptiert ganzzahligen Wert; Standard ist 0.Dies gibt an, wie häufig die Leistungsstatistiken gedruckt werden. Diese Statistiken umfassen die Zeit für die Kommunikation und/oder berechnung in einem Synchronisierungszeitraum, die nützlich sein kann, um den Engpass paralleler Schulungsalgorithmen zu verstehen.
0 bedeutet, dass keine Statistiken gedruckt werden. Andere Werte geben an, wie oft die Statistiken gedruckt werden. Bedeutet beispielsweise,
syncPerfStats=5dass Statistiken nach jeder 5 Synchronisierung ausgedruckt werden.Ein Teilblock, der Details der einzelnen parallelen Schulungsalgorithmus angibt. Der Name des Unterblocks sollte gleich
parallelizationMethodsein. (obligatorisch)
Python bietet mehr Flexibilität und Verwendungen werden unten für verschiedene Parallelisierungsmethoden gezeigt.
4. Parallele Schulung mit CNTK
Parallelisierung in CNTK wird mit MPI implementiert.
4.1 Paralleltraining mit BrainScript
Angesichts einer der oben genannten Konfigurationen für parallele Schulungen von BrainScript können die folgenden Befehle verwendet werden, um einen parallelen MPI-Auftrag zu starten:
Parallele Schulung auf demselben Computer mit Linux:
mpiexec --npernode $num_workers $cntk configFile=$configParallele Schulung auf demselben Computer mit Windows:
mpiexec -n %num_workers% %cntk% configFile=%config%Parallele Schulung über mehrere Computerknoten mit Linux:
Schritt 1: Erstellen einer Hostdatei $hostfile mithilfe des bevorzugten Editors
# Comments are allowed after pound sign name_of_node1 slots=4 # we want 4 workers on node1 name_of_node2 slots=2 # we want 2 workers on node2
Dabei ist name_of_node(n) einfach ein DNS-Name oder eine IP-Adresse des Workerknotens.
Step 2: Execute your workload
```
mpiexec -hostfile $hostfile $cntk configFile=$config
```
Parallele Schulung über mehrere Computerknoten mit Windows:
mpiexec --hosts %num_nodes% %name_of_node1% %num_workers_on_node1% ... %cntk% configFile=%config%
wo $cntk sollte sich auf den Pfad der ausführbaren CNTK-Datei beziehen ($x ist die Art der Substituieren von Umgebungsvariablen, der Entsprechung %x% in der Windows-Shell).
4.2 Parallelschulung mit Python
Beispiele für verteilte Schulungen für CNTK v2 mit Python finden Sie hier:
Angesichts eines CNTK v2 Python-Skripts training.py können die folgenden Befehle verwendet werden, um einen parallelen MPI-Auftrag zu starten:
Parallele Schulung auf demselben Computer mit Linux:
mpiexec --npernode $num_workers python training.pyParallele Schulung auf demselben Computer mit Windows:
mpiexec -n %num_workers% python training.pyParallele Schulung über mehrere Computerknoten mit Linux:
Schritt 1: Erstellen einer Hostdatei $hostfile mithilfe des bevorzugten Editors
# Comments are allowed after pound sign name_of_node1 slots=4 # we want 4 workers on node1 name_of_node2 slots=2 # we want 2 workers on node2
Dabei ist name_of_node(n) einfach ein DNS-Name oder eine IP-Adresse des Workerknotens.
Step 2: Execute your workload
```
mpiexec -hostfile $hostfile python training.py
```
Parallele Schulung über mehrere Computerknoten mit Windows:
mpiexec --hosts %num_nodes% %name_of_node1% %num_workers_on_node1% ... python training.py
5 Data-Parallel Schulung mit 1-Bit-SGD
CNTK implementiert die 1-Bit-SGD-Technik [1]. Diese Technik ermöglicht es, jeden Minibatch über Arbeiter zu K verteilen. Die resultierenden Teilverläufe werden dann nach jedem Minibatch ausgetauscht und aggregiert. "1 Bit" bezieht sich auf eine Technik, die bei Microsoft entwickelt wurde, um die Menge der Daten zu verringern, die für jeden Farbverlaufswert auf ein einzelnes Bit ausgetauscht werden.
5.1 Der Algorithmus "1-Bit SGD"
Der direkte Austausch von Teilverläufen nach jedem Minibatch erfordert eine unerwendliche Kommunikationsbandbreite. Um dies zu beheben, quantisiert 1-Bit SGD jeden Farbverlaufswert aggressiv... bis zu einem einzelnen Bit (!) pro Wert. Praktisch bedeutet dies, dass große Farbverlaufswerte abgeschnitten werden, während kleine Werte künstlich aufgeblasen werden. Erstaunlicherweise schadet dies der Konvergenz nicht, wenn, und nur dann, wenn, ein Trick verwendet wird.
Der Trick besteht darin, dass der Algorithmus für jeden Minibatch die quantisierten Farbverläufe (die zwischen Arbeitern ausgetauscht werden) mit den ursprünglichen Farbverlaufswerten (die ausgetauscht werden sollen) vergleicht. Der Unterschied zwischen den beiden (der Quantisierungsfehler) wird berechnet und als Rest gespeichert. Dieser Rest wird dann dem nächsten Minibatch hinzugefügt.
Folglich wird jeder Farbverlaufswert trotz der aggressiven Quantisierung schließlich mit voller Genauigkeit ausgetauscht; nur zu einer Verzögerung. Experimente zeigen, dass dieses Modell, solange dieses Modell mit einem warmen Start kombiniert wird (ein Saatgutmodell, das auf einer kleinen Teilmenge der Schulungsdaten ohne Parallelisierung trainiert wurde), diese Technik hat gezeigt, dass keine oder sehr geringe Genauigkeitsverlust auftritt, während eine Geschwindigkeit nicht zu weit von linearer Geschwindigkeit ermöglicht wird (der grenzwertige Faktor ist, dass GPUs bei der Berechnung auf zu kleinen Teilbatches ineffizient werden).
Für maximale Effizienz sollte die Technik mit der automatischen Minibatchskalierung kombiniert werden, wo immer und dann der Trainer versucht, die Minibatchgröße zu erhöhen. Auswerten einer kleinen Teilmenge der bevorstehenden Datenzeit wählt der Trainer die größte Minibatchgröße aus, die keine Konvergenz beeinträchtigt. Hier kommt es praktisch, dass CNTK die Lernrate und die Dynamik-Hyperparameter auf eine minibatch-größe agnostische Weise angibt.
5.2 Verwenden von 1-Bit-SGD in BrainScript
1-Bit-SGD selbst hat keinen Anderen Parameter als die Aktivierung und nach welcher Epoche es beginnen soll. Darüber hinaus sollte die automatische Minibatchskalierung aktiviert sein. Diese werden konfiguriert, indem sie dem SGD-Block die folgenden Parameter hinzufügen:
SGD = [
...
ParallelTrain = [
DataParallelSGD = [
gradientBits = 1
]
parallelizationStartEpoch = 2 # warm start: don't use 1-bit SGD for first epoch
]
AutoAdjust = [
autoAdjustMinibatch = true # enable automatic growing of minibatch size
minibatchSizeTuningFrequency = 3 # try to enlarge after this many epochs
]
]
Beachten Sie, dass Data-Parallel SGD auch ohne 1-Bit-Quantisierung verwendet werden kann. In typischen Szenarien, insbesondere Szenarien, in denen jeder Modellparameter nur einmal wie für einen Feed-Forward DNN angewendet wird, ist dies aufgrund hoher Kommunikationsbandbreite nicht effizient.
Abschnitt 2.2.3 unten zeigt Ergebnisse von 1-Bit-SGD für eine Sprachaufgabe, verglichen mit der Block-Momentum SGD-Methode, die weiter beschrieben wird. Beide Methoden haben keine oder fast keinen Genauigkeitsverlust bei nahezu linearer Geschwindigkeit.
5.3 Verwenden von 1-Bit-SGD in Python
Um Daten parallele SGD in Python zu verwenden, muss der Benutzer optional mit 1-Bit-SGD einen verteilten Lerner erstellen und an den Trainer übergeben:
from cntk import distributed
...
learner = cntk.learner.momentum_sgd(...) # create local learner
distributed_after = epoch_size # number of samples to warm start with
distributed_learner = distributed.data_parallel_distributed_learner(
learner = learner,
num_quantization_bits = 1, # change to 32 for non-quantized gradient accumulation
distributed_after = distributed_after) # warm start: no parallelization is used for the first 'distributed_after' samples
...
minibatch_source = MinibatchSource(...)
...
trainer = Trainer(z, ce, pe, distributed_learner)
...
session = training_session(trainer=trainer, mb_source=minibatch_source, ...)
session.train()
...
distributed.Communicator.finalize() # must be called to finalize MPI in case of successful distributed training
Das Ändern von num_quantization_bits auf 32 während der Erstellung von distributed_learner macht die Verwendung nicht quantisierter Data-Parallel SGD. In diesem Fall ist kein Warmstart erforderlich.
6 Block-Momentum SGD
Block-Momentum SGD ist die Implementierung der "blockweise Modellaktualisierung und -filterung", oder BMUF, Algorithmus, short Block Momentum [2].
6.1 Der Block-Momentum SGD-Algorithmus
In der folgenden Abbildung wird das Verfahren im Block-Momentum Algorithmus zusammengefasst.

6.2 Konfigurieren von Block-Momentum SGD in BrainScript
Um Block-Momentum SGD zu verwenden, muss ein Unterblock im SGD Block mit den folgenden Optionen benannt BlockMomentumSGD werden:
syncPeriod. Dies ähnelt demsyncPeriodInModelAveragingSGD, in dem angegeben wird, wie häufig eine Modellsynchronisierung ausgeführt wird. Der Standardwert fürBlockMomentumSGD120.000.resetSGDMomentum. Dies bedeutet, dass nach jedem Synchronisierungspunkt der geglättete Farbverlauf, der in lokalen SGD verwendet wird, als 0 festgelegt wird. Der Standardwert dieser Variable ist true.useNesterovMomentum. Dies bedeutet, dass das Nesterov-Stil-Dynamikupdate auf blockebene angewendet wird. Weitere Informationen finden Sie unter [2]. Der Standardwert dieser Variable ist true.
Die Blockdynamik und die Blocklernrate werden in der Regel automatisch entsprechend der Anzahl der verwendeten Arbeitnehmer festgelegt, d.h.,
block_momentum = 1.0 - 1.0/num_of_workers
block_learning_rate = 1.0
Unsere Erfahrung gibt an, dass diese Einstellungen oft ähnliche Konvergenz wie der standard-SGD-Algorithmus bis zu 64 GPUs bieten, was das größte Experiment ist, das wir durchgeführt haben. Es ist auch möglich, die folgenden Parameter manuell mithilfe der folgenden Optionen anzugeben:
blockMomentumAsTimeConstantGibt die Zeitkonstante des Low-Pass-Filters in der Aktualisierung des Modells auf Blockebene an. Es wird wie folgt berechnet:blockMomentumAsTimeConstant = -syncPeriod / log(block_momentum) # or inversely block_momentum = exp(-syncPeriod/blockMomentumAsTimeConstant)blockLearningRateGibt die Blocklernrate an.
Im Folgenden finden Sie ein Beispiel für Block-Momentum SGD-Konfigurationsabschnitt:
learningRatesPerSample=0.0005
# 0.0005 is the optimal learning rate for single-GPU training.
# Use it for BlockMomentumSGD as well
ParallelTrain = [
parallelizationMethod = BlockMomentumSGD
distributedMBReading = true
syncPerfStats = 5
BlockMomentumSGD=[
syncPeriod = 120000
resetSGDMomentum = true
useNesterovMomentum = true
]
]
6.3 Verwenden von Block-Momentum SGD in BrainScript
1. Neuoptimierung von Lernparametern
Um einen ähnlichen Durchsatz pro Arbeiter zu erzielen, ist es notwendig, die Anzahl der Proben in einem Minibatch proportional zur Anzahl der Arbeitnehmer zu erhöhen. Dies kann durch Anpassen oder
nbruttsineachrecurrentiter,minibatchSizeje nachdem, ob die Randomisierung des Framemodus verwendet wird, erreicht werden.Es ist nicht erforderlich, die Lernrate anzupassen (im Gegensatz zu Model-Averaging SGD, siehe unten).
Es wird empfohlen, Block-Momentum SGD mit einem warm gestarteten Modell zu verwenden. Bei unseren Spracherkennungsaufgaben wird eine angemessene Konvergenz erzielt, wenn sie von Seedmodellen ab 24 Stunden (8,6 Millionen Stichproben) bis 120 Stunden (43,2 Millionen Stichproben)-Daten mit standard SGD trainiert wurde.
2. ASR-Experimente
Wir haben die Block-Momentum SGD und die Data-Parallel (1-Bit)-SGD-Algorithmen verwendet, um DNNs und LSTMs auf einer 2600-Stunden-Spracherkennungsaufgabe zu trainieren und die Genauigkeit der Worterkennung im Vergleich zu Geschwindigkeitsfaktoren zu vergleichen. Die folgenden Tabellen und Abbildungen zeigen die Ergebnisse (*).
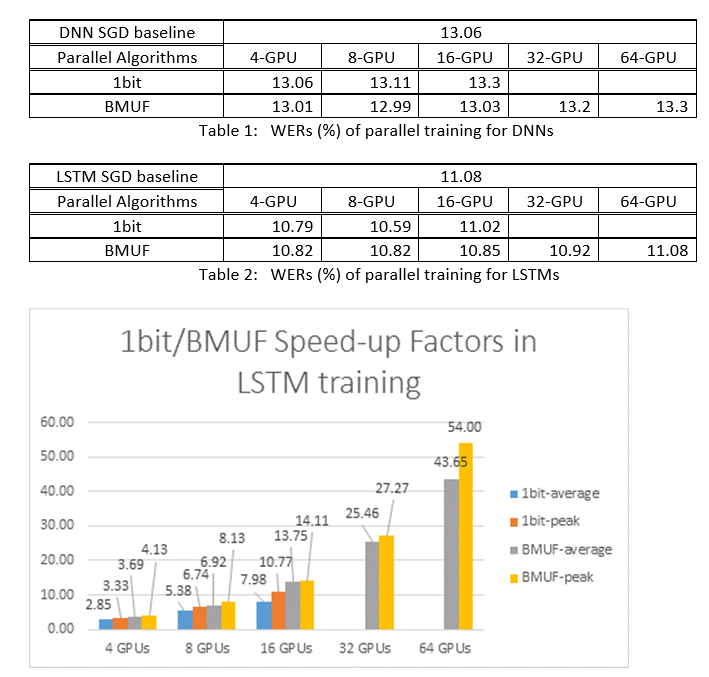
(*): Höchstgeschwindigkeitsfaktor: für 1-Bit-SGD, gemessen durch den maximalen Geschwindigkeits-Up-Faktor (verglichen mit SGD-Basisplan), der in einem Minibatch erreicht wurde; für Block-Dynamik gemessen durch die maximale Geschwindigkeit, die in einem Block erreicht wurde; Durchschnittliche Geschwindigkeitsfaktor: Die verstrichene Zeit in SGD-Basisplan dividiert durch die beobachtete verstrichene Zeit. Diese beiden Metriken werden aufgrund der Latenz in E/A eingeführt, die sich erheblich auf die durchschnittliche Geschwindigkeitsfaktormessung auswirken kann, insbesondere, wenn die Synchronisierung auf Minibatchebene ausgeführt wird. Gleichzeitig ist der maximale Geschwindigkeitsfaktor relativ robust.
3. Vorbehalte
Es wird empfohlen, auf "true" festzulegen
resetSGDMomentum. Andernfalls führt es häufig zu einer Abweichung des Trainingskriteriums. Rücksetzung der SGD-Dynamik auf 0, nachdem jede Modellsynchronisierung im Wesentlichen den Beitrag von den letzten Minibatches abschneidet. Daher wird empfohlen, keine große SGD-Dynamik zu verwenden. Beispielsweise beobachten wir für einesyncPeriodvon 120.000 einen signifikanten Genauigkeitsverlust, wenn die für SGD verwendete Dynamik 0,99 beträgt. Durch die Reduzierung der SGD-Dynamik auf 0,9, 0,5 oder sogar durch deaktivieren wird es insgesamt ähnliche Genauigkeiten, wie dies durch den standardmäßigen SGD-Algorithmus erreicht werden kann.Block-Momentum SGD verzögert und verteilt Modellupdates von einem Block über nachfolgende Blöcke hinweg. Daher ist es notwendig, sicherzustellen, dass Modellsynchronisierungen häufig genug in der Schulung ausgeführt werden. Eine Schnellüberprüfung besteht darin, die Verwendung zu verwenden
blockMomentumAsTimeConstant. Es wird empfohlen,Ndass die Anzahl der eindeutigen Schulungsbeispiele, die folgende Formel erfüllen sollte:N >= blockMomentumAsTimeConstant * num_of_workers ~= syncPeriod * num_of_workers^2
Die Annäherung stammt aus den folgenden Fakten: (1) Blockdynamik wird häufig als festgelegt; (1-1/num_of_workers) (2) log(1-1/num_of_workers)~=-num_of_workers.
6.4 Verwenden von Block-Momentum in Python
Um Block-Momentum in Python zu aktivieren, ähnlich wie die 1-Bit-SGD, muss der Benutzer einen blockimpuls verteilten Lerner an den Trainer erstellen und übergeben:
from cntk import distributed
...
learner = cntk.learner.momentum_sgd(...) # create local learner
distributed_learner = cntk.distributed.block_momentum_distributed_learner(learner, block_size=block_size)
...
minibatch_source = MinibatchSource(...)
...
trainer = Trainer(z, ce, pe, distributed_learner)
...
session = training_session(trainer=trainer, mb_source=minibatch_source, ...)
session.train()
...
distributed.Communicator.finalize() # must be called to finalize MPI in case of successful distributed training
Ein voll funktionsfähiges Beispiel finden Sie im ConvNet-Beispiel.
7 Model-Averaging SGD
Model-Averaging SGD ist eine Implementierung des Modellaveragingalgorithmus, der in [3,4] ohne verwendung des natürlichen Farbverlaufs detailliert beschrieben wird. Die Idee besteht darin, jedem Mitarbeiter eine Teilmenge von Daten zu ermöglichen, aber die Modellparameter von jedem Worker nach einem bestimmten Zeitraum zu ververwerten.
Model-Averaging SGD konvergiert im Allgemeinen langsamer und zu einem schlechteren Optimum, verglichen mit 1-Bit-SGD und Block-Momentum SGD, daher wird es nicht mehr empfohlen.
Um Model-Averaging SGD zu verwenden, muss ein Unterblock im SGD Block mit den folgenden Optionen benannt ModelAveragingSGD werden:
syncPeriodGibt die Anzahl der Beispiele an, die jeder Mitarbeiter verarbeiten muss, bevor ein Modellververarbeiter durchgeführt wird. Der Standardwert ist 40.000.
7.1 Verwenden von Model-Averaging SGD in BrainScript
Um Model-Averaging SGD maximal effektiv und effizient zu gestalten, müssen Benutzer einige Hyperparameter optimieren:
minibatchSizeodernbruttsineachrecurrentiterAngenommen,nMitarbeiter nehmen an der Model-Averaging SGD-Konfiguration teil, die aktuelle verteilte Leseimplementierung lädt1/n-th des Minibatchs in jeden Mitarbeiter. Um sicherzustellen, dass jeder Arbeiter den gleichen Durchsatz wie die Standard-SGD erzeugt, ist es notwendig, die Minibatchgrößen-gefaltet zu vergrößern. Bei Modellen, die mit der Randomisierung des Framemodus trainiert werden, kann dies durchminibatchSizedie Vergrößerung nachnZeiten erreicht werden. Für Modelle werden mithilfe von Sequenzmodus-Randomisierung, z. B. RNNs, trainiert, müssen einige Leser stattdessen um erhöhennbruttsineachrecurrentitern.learningRatesPerSample. Unsere Erfahrung weist darauf hin, dass es notwendig ist, um ähnliche Konvergenz wie die Standard-SGD zu erhalten, um dielearningRatesPerSamplenZeiten zu erhöhen. Eine Erläuterung finden Sie in [2]. Da die Lernrate erhöht wird, ist eine zusätzliche Pflege erforderlich, um sicherzustellen, dass sich die Schulung nicht unterscheidet - und dies ist in der Tat der Hauptvorsatz von Model-Averaging SGD. Sie können dieAutoAdjustEinstellungen verwenden, um das vorherige beste Modell neu zu laden, wenn ein Anstieg des Schulungskriteriums beobachtet wird.warmer Start. Es wird festgestellt, dass Model-Averaging SGD in der Regel besser konvergiert, wenn es aus einem Seedmodell gestartet wird, das vom standardmäßigen SGD-Algorithmus (ohne Parallelisierung) trainiert wird. Bei unseren Spracherkennungsaufgaben wird eine angemessene Konvergenz erzielt, wenn sie von Seedmodellen ab 24 Stunden (8,6 Millionen Stichproben) bis 120 Stunden (43,2 Millionen Stichproben)-Daten mit standard SGD trainiert wurde.
Im Folgenden sehen Sie ein Beispiel für den ModelAveragingSGD Konfigurationsabschnitt:
learningRatesPerSample = 0.002
# increase the learning rate by 4 times for 4-GPU training.
# learningRatesPerSample = 0.0005
# 0.0005 is the optimal learning rate for single-GPU training.
ParallelTrain = [
parallelizationMethod = ModelAveragingSGD
distributedMBReading = true
syncPerfStats = 20
ModelAveragingSGD = [
syncPeriod=40000
]
]
7.2 Verwenden von Model-Averaging SGD in Python
Diese Angaben sind nicht final.
8 Data-Parallel Schulung mit ParameterServer
Der Parameterserver ist ein häufig verwendetes Framework in verteiltem maschinellem Lernen [5][6][7]. Der wichtigste Vorteil ist die asynchrone parallele Schulung mit vielen Mitarbeitern. Er führt den Parameterserver als verteilten Modellspeicher ein. Anstatt allReduce-Grundtypen zum Synchronisieren von Parameterupdates zwischen Mitarbeitern direkt zu nutzen, bietet das Parameterserverframework Benutzern die Schnittstellen wie "Hinzufügen" und "Get", damit lokale Mitarbeiter globale Parameter vom Parameterserver aktualisieren und abrufen können. Auf diese Weise müssen lokale Mitarbeiter nicht während des Schulungsvorgangs warten, der viel Zeit spart, insbesondere, wenn die Anzahl der Mitarbeiter groß ist.
Da Parameterserver ein verteiltes Framework sind, das Modellparameter speichert, können Mitarbeiter diese Parameter, die sie während des Minibatchschulungsprozesses benötigen, nur abrufen, dies bietet sehr gute Flexibilität beim Entwerfen verteilter Schulungsmethode und verbessert auch die Effizienz beim Durchführen von Schulungen mit sparsamen Modellupdates. In dieser Version konzentrieren wir uns zuerst auf die asynchrone parallele Schulung, später geben wir mehr Einführung in die Nutzung des Parameterserverframeworks für effiziente Modellschulungen mit sparsamen Updates.
8.1 Verwendung von Data-Parallel ASGD
- Um Parameterserver für die asynchrone SGD (abbr. as ASGD) zu verwenden, sollten Sie CNTK mit Multiverso unterstützt erstellen, Multiverso ist ein allgemeines Parameterserverframework für verteilte machine Learning-Aufgaben, die vom Microsoft Research Asia-Team entwickelt wurden.
Clone Code: Klonen Sie den Code unter dem Stammordner von CNTK mithilfe von:
git submodule update --init Source/Multiverso
Linux: Erstellen Sie bitte mit--asgd=yesdem Konfigurationsprozess.Windows: Fügen Sie Ihre Systemumgebung hinzuCNTK_ENABLE_ASGD, und legen Sie den Wert auftrue
- warmer Start. In einigen Fällen ist es besser, die asynchrone Modellschulung aus einem Seedmodell zu starten (das von einem standardmäßigen SGD-Algorithmus trainiert wird). In manchem Sinne bringt asynchrone SGD mehr Lärm für die Schulung aufgrund der verzögerten Aktualisierungen von Asynchronismus zwischen Arbeitnehmern. Einige Modelle sind sehr empfindlich für solche Rauschen am Anfang, was zu einer Abweichung der Modellschulung führen kann. Unter diesen Umständen ist ein warmer Start erforderlich.
8.2 Konfigurieren von Data-Parallel ASGD in BrainScript
Um Data-Parallel ASGD in CNTK zu verwenden, ist es erforderlich, einen Teilblock DataParallelASGD im SGD-Block mit den folgenden Optionen zu verwenden.
-
syncPeriodPerWorkers. Es gibt die Anzahl der Beispiele an, die jeder Worker verarbeiten muss, bevor er mit den Parameterservern kommuniziert. Der Standardwert ist 256. Es wird als Größe von Minibatch empfohlen. Es ist offensichtlich, dass die häufige Synchronisierung zu erheblich hohen Kommunikationskosten führt. In unserem Test ist es nicht erforderlich, den Wert in den meisten Fällen auf 1 festzulegen.
-
usePipeline. Er gibt an, ob die Pipeline des Modellabrufs und die lokale Berechnung aktiviert wird. Wenn Sie die Pipeline aktivieren, wird der Gesamtdurchsatz der Schulung erheblich erhöht, da sie einige oder alle Kommunikationskosten ausblenden wird. Manchmal kann die Konvergenzrate jedoch verlangsamt werden, da mehr Verzögerung durch Hinzufügen von Pipeline eingeführt wird. Insgesamt wird die Uhrzeit in den meisten Fällen mit Pipeline gespeichert.
-
AdjustLearningRateAtBeginning. Nach dem kürzlich veröffentlichten Papier [5] ist das Training ASGD weniger stabil, und es muss viel kleinere Lernrate verwendet werden, um gelegentliche Explosionen des Trainingsverlusts zu vermeiden, daher wird der Lernprozess weniger effizient. Wir haben jedoch festgestellt, dass die Verwendung niedrigerer Lernrate für alle Aufgaben nicht erforderlich ist. Und für diese Aufgaben, die anfangs vertraulich sind, beginnen wir mit der Schulung mit kleiner Lernrate und vergrößern sie schrittweise in der Anfangsphase des Schulungsprozesses, bis sie die anfängliche Lernrate erreicht, die in normaler SGD verwendet wird. Auf diese Weise entspricht die endgültige Genauigkeit sgD mit der Geschwindigkeit von ASGD. Daher bieten wir diese Option für ASGD-Benutzer, diesen Trick zu nutzen. Es ist ein Unterblock in DataParallelASGD mit zwei Parametern: adjustCoefficient und adjustNBMiniBatch. Die Logik besteht darin, dass die Lernrate von adjustCoefficient von SGD anfänglichen Lernrate beginnt und durch anpassungCoefficient der SGD-anfänglichen Lernrate jeder anpassungNBMiniBatch Minibatch Minibatch mini-batches erhöht wird.
Im Folgenden sehen Sie ein Beispiel für den DataParallelASGD Konfigurationsabschnitt:
learningRatesPerSample = 0.0005
ParallelTrain = [
parallelizationMethod = DataParallelASGD
distributedMBReading = true
syncPerfStats = 20
DataParallelASGD = [
syncPeriodPerWorker=256
usePipeline = true
AdjustLearningRateAtBeginning = [
adjustCoefficient = 0.2
adjustNBMiniBatch = 1024
# Learning rate will be adjusted to original one after ((1 / adjustCoefficient) * adjustNBMiniBatch) samples
# which is 5120 in this case
]
]
]
8.3 Konfigurieren von Data-Parallel ASGD in Python
Diese Angaben sind nicht final.
8.4 Experimente
Die folgende Abbildung zeigt die Experimente zum Testen von ASGD mit CIFAR-10-Dataset. Das modell, das in diesem Experiment verwendet wird, ist ein 20-Layer ResNet. Der asynchrone Algorithmus reduziert die Kosten für das Warten auf alle Arbeitsknoten. ASGD ist in diesem Fall deutlich schneller als die synchronen Algorithmen wie MA und SSGD. *In den Experimenten synchronisieren alle Parallelmodi alle Parameter jeder Iteration (Minibatchupdate). Und für SSGD haben wir 32-Bit-Parameterupdates verwendet. Asynchroner Algorithmus erhält einen erheblichen Vorteil im Hinblick auf den Schulungsdurchsatz, der durch die Beispielverarbeitungsgeschwindigkeit gemessen wird, insbesondere, wenn die Arbeitsknotennummer bis zu 16 geht.
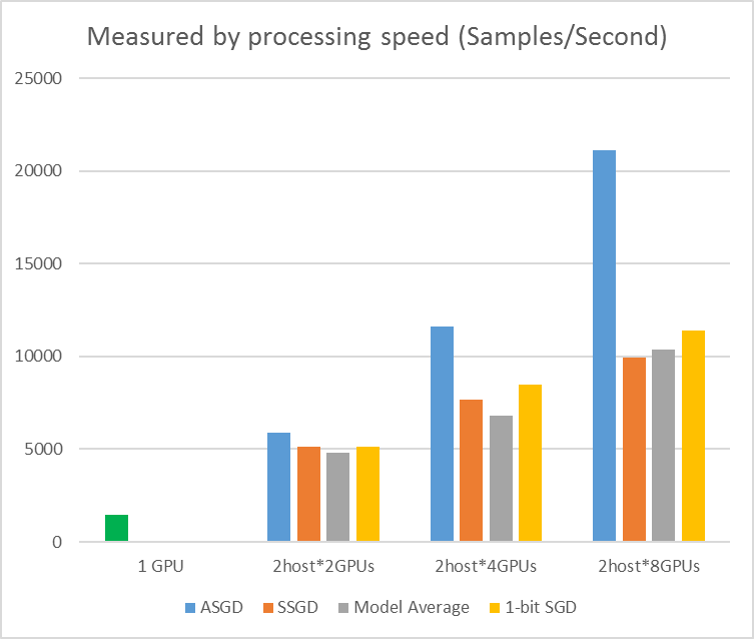 Abbildung 2.4 die Geschwindigkeit für verschiedene Schulungsmethoden
Abbildung 2.4 die Geschwindigkeit für verschiedene Schulungsmethoden
Referenzen
[1] F. Seide, Hao Fu, Jasha Droppo, Gang Li und Dong Yu, "1-Bit-Stochastische Farbverlaufsabstieg und seine Anwendung auf daten parallel verteilte Schulung von Sprach DNNs", in Proceedings of Interspeech, 2014.
[2] K. Chen und Q. Huo, "Skalierbare Schulung von Deep Learning Maschinen durch inkrementelle Blockschulung mit intrablock paralleler Optimierung und blockweiser Modellaktualisierungsfilterung", in Proceedings of ICASSP, 2016.
[3] M. Zinkevich, M. Weimer, L. Li und A. Smola, "Parallelisierte stochastische Farbverlaufsabstiege", in Proceedings of Advances in NIPS, 2010, Pp. 2595-2603.
[4] D. Povey, X. Zhang und S. Khudanpur, "Parallele Schulung von DNNs mit natürlichem Farbverlauf und Parameterverwertung", in Proceedings of the International Conference on Learning Representations, 2014.
[5] Chen J, Monga R, Bengio S, et al. Revisiting Distributed Synchron SGD. ICLR, 2016.
[6] Dean Jeffrey, Greg Corrado, Rajat Monga, Kai Chen, Matthieu Devin, Mark Mao, Andrew Senior et al. Große verteilte Deep-Netzwerke. In Fortschritten in neuralen Informationsverarbeitungssystemen, Pp. 1223-1231. 2012.
[7] Li Mu, Li Zhou, Zichao Yang, Aaron Li, Fei Xia, David G. Andersen und Alexander Smola. "Parameterserver für verteiltes maschinelles Lernen." In Big Learning NIPS Workshop, Vol. 6, p. 2. 2013.