Konfigurationsverwaltung in HDInsight auf AKS mit Apache Spark-Cluster™
Wichtig
Azure HDInsight auf AKS wurde am 31. Januar 2025 eingestellt. Erfahren Sie mehr über durch diese Ankündigung.
Sie müssen Ihre Workloads zu Microsoft Fabric oder ein gleichwertiges Azure-Produkt migrieren, um eine abrupte Beendigung Ihrer Workloads zu vermeiden.
Wichtig
Dieses Feature befindet sich derzeit in der Vorschau. Die zusätzlichen Nutzungsbedingungen für Microsoft Azure Previews weitere rechtliche Bestimmungen enthalten, die für Azure-Features gelten, die in der Betaversion, in der Vorschau oder auf andere Weise noch nicht in die allgemeine Verfügbarkeit veröffentlicht werden. Informationen zu dieser spezifischen Vorschau finden Sie unter Azure HDInsight auf AKS Vorschauinformationen. Für Fragen oder Funktionsvorschläge stellen Sie bitte eine Anfrage auf AskHDInsight mit den Details, dabei können Sie uns für weitere Updates über Azure HDInsight Communityfolgen.
Azure HDInsight auf AKS ist ein verwalteter cloudbasierter Dienst für Big Data Analytics, der Organisationen bei der Verarbeitung großer Datenmengen hilft. In diesem Lernprogramm wird gezeigt, wie Sie die Konfigurationsverwaltung in Azure HDInsight auf AKS mit Apache Spark-Cluster™ verwenden.
Die Konfigurationsverwaltung wird verwendet, um dem Apache Spark-Cluster bestimmte Konfigurationen hinzuzufügen.
Wenn der Benutzer eine Konfiguration im Verwaltungsportal aktualisiert, wird der entsprechende Dienst auf rollierende Weise neu gestartet.
Schritte zum Aktualisieren von Konfigurationen
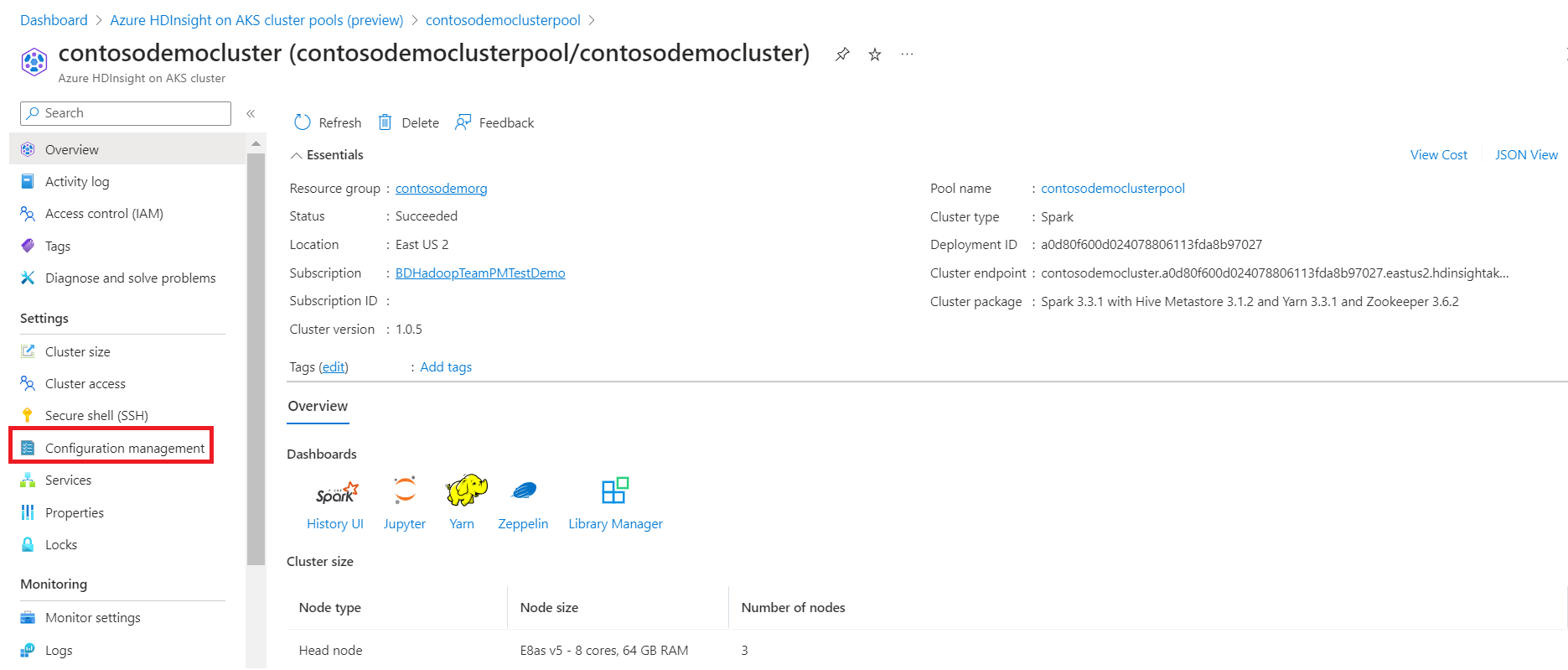
Klicken Sie im Clusterpool auf den Clusternamen, und navigieren Sie zur Seite "Clusterübersicht".
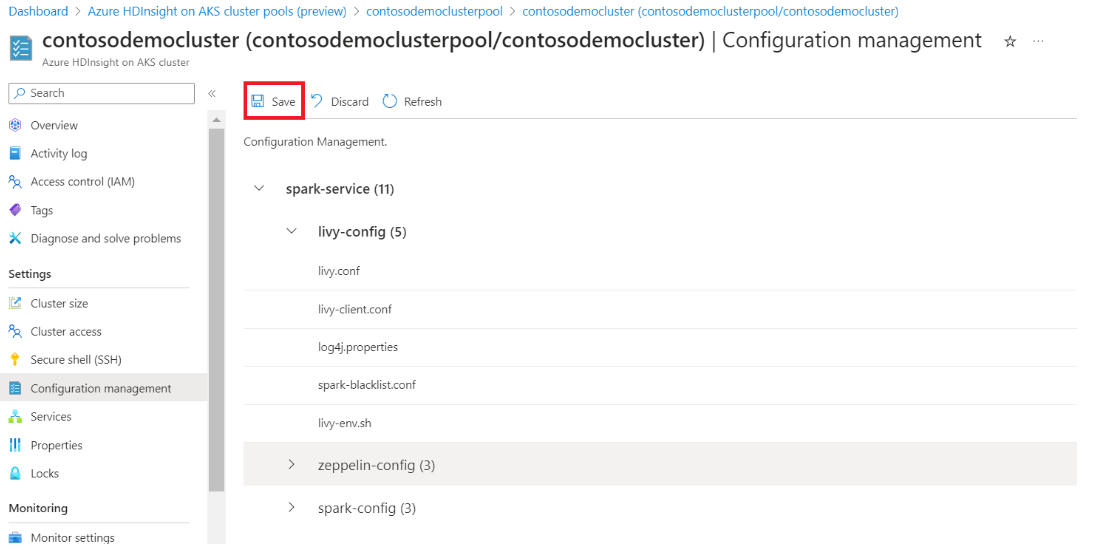
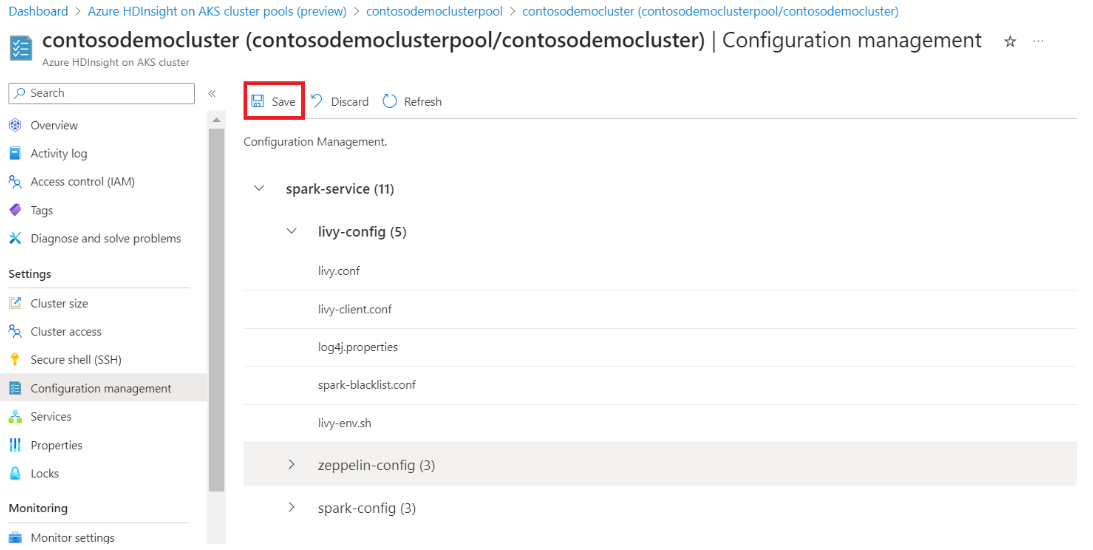
Klicken Sie im linken Bereich auf die Registerkarte "Konfigurationsverwaltung".
Dieser Schritt führt Sie zu den Spark-Konfigurationen, die bereitgestellt werden.
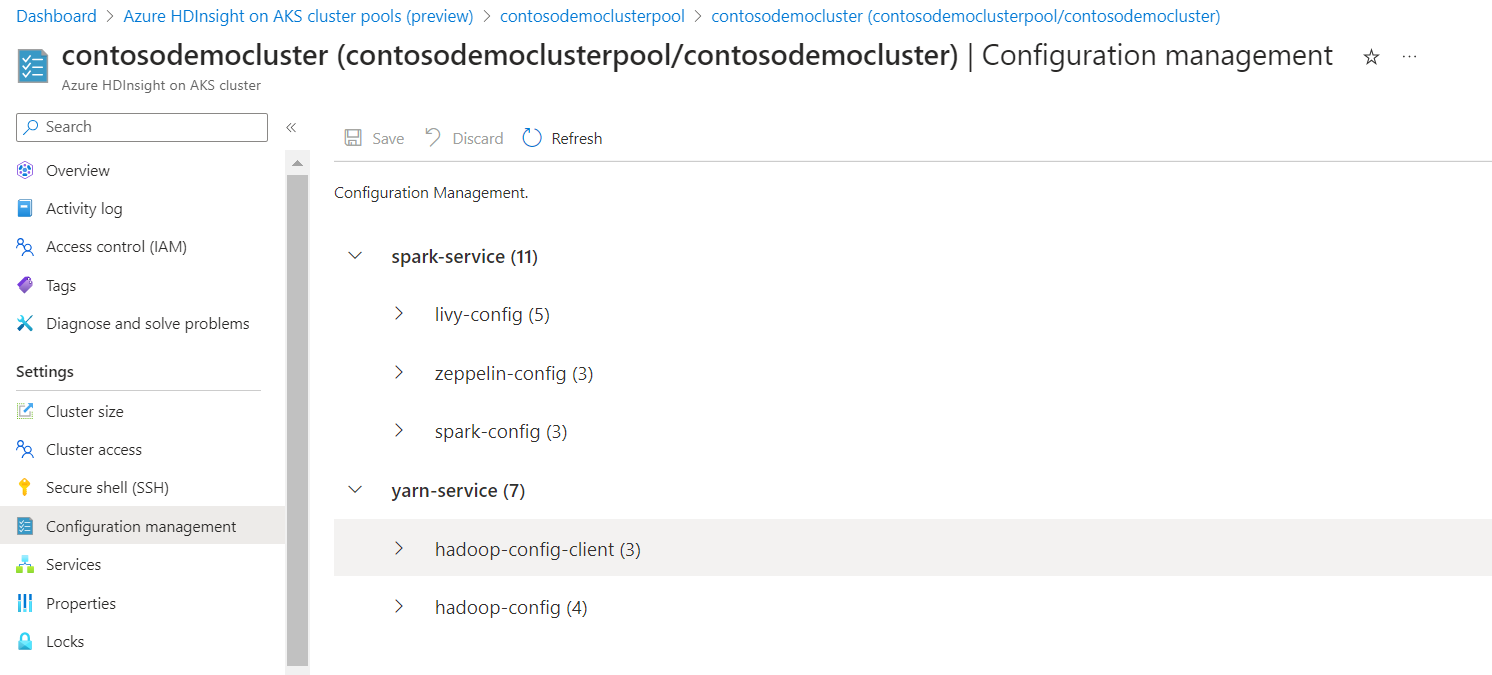
Klicken Sie auf die Konfiguration Tabs, die geändert werden müssen.
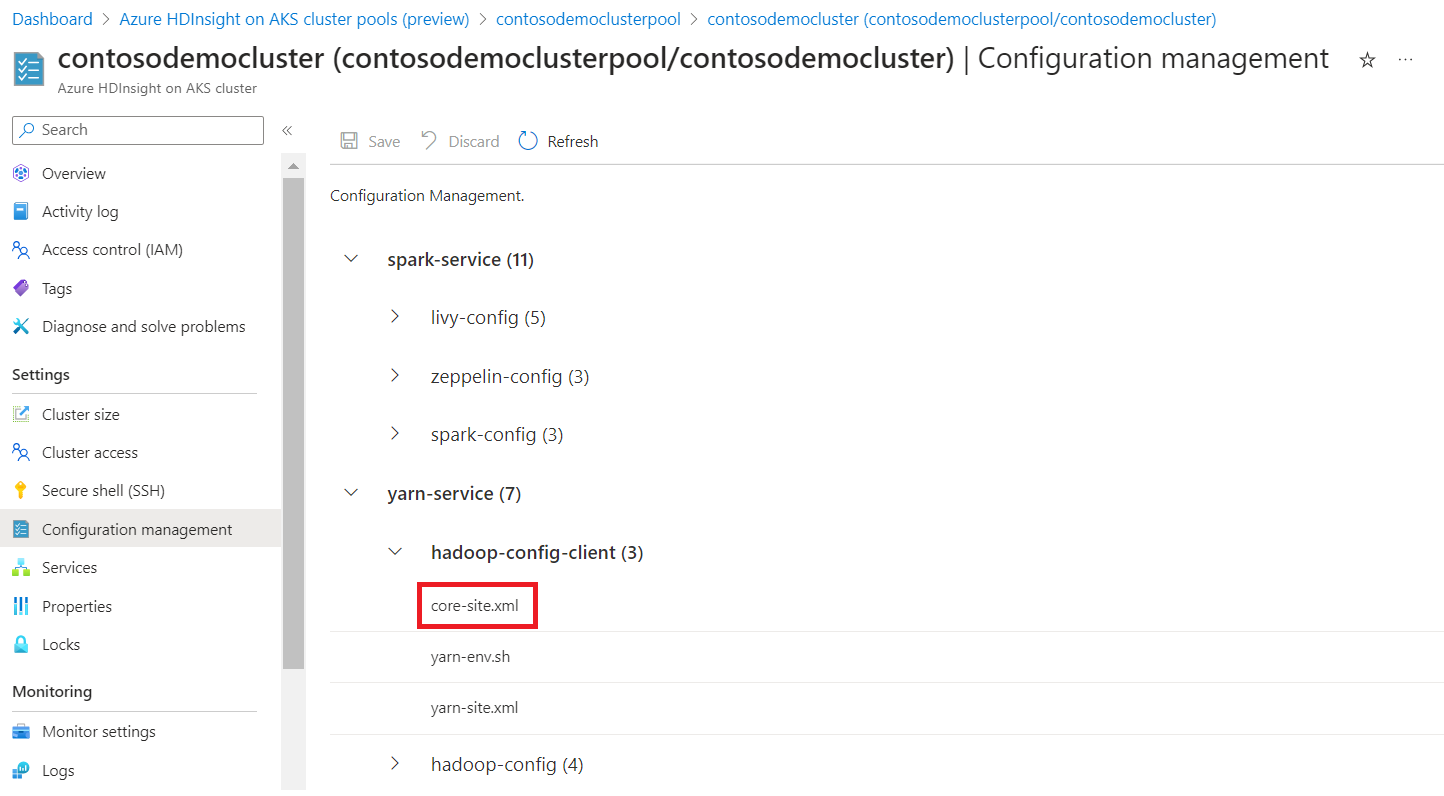
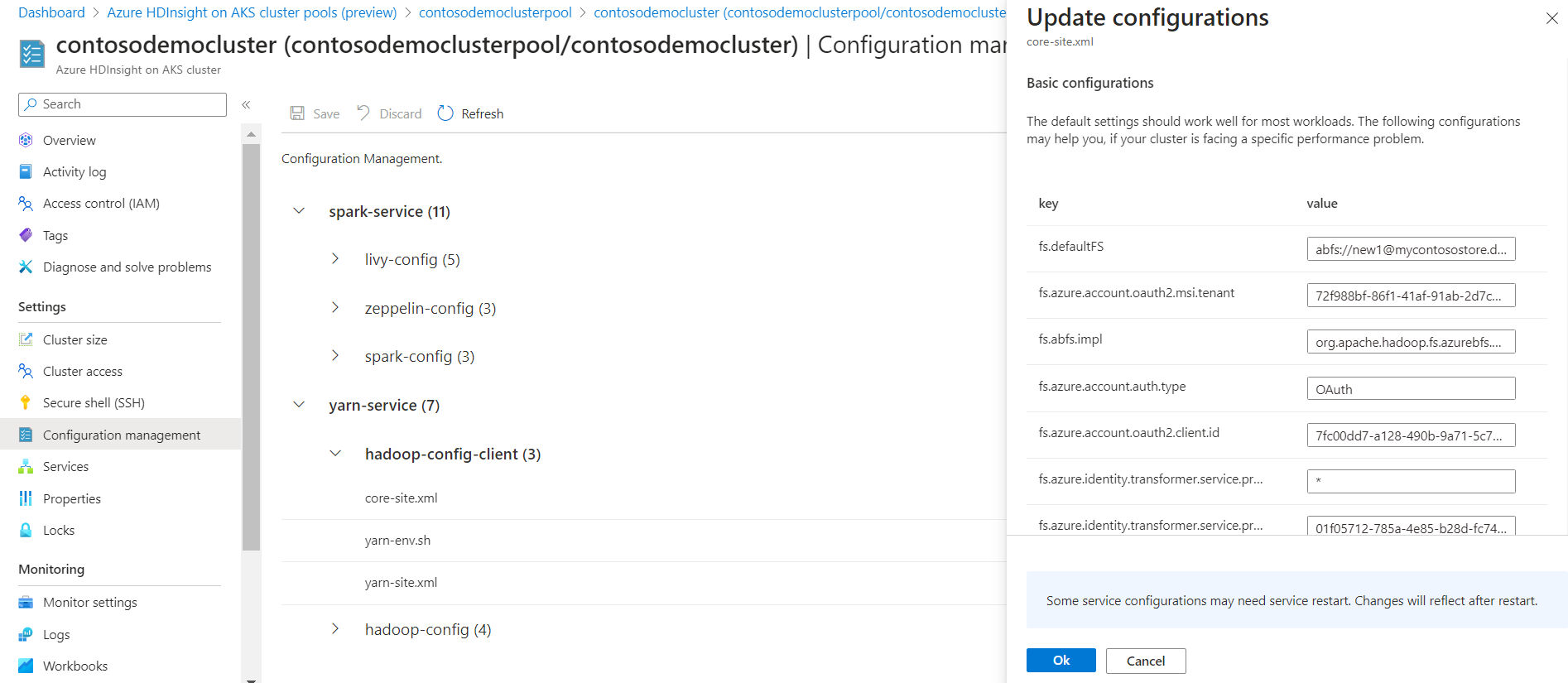
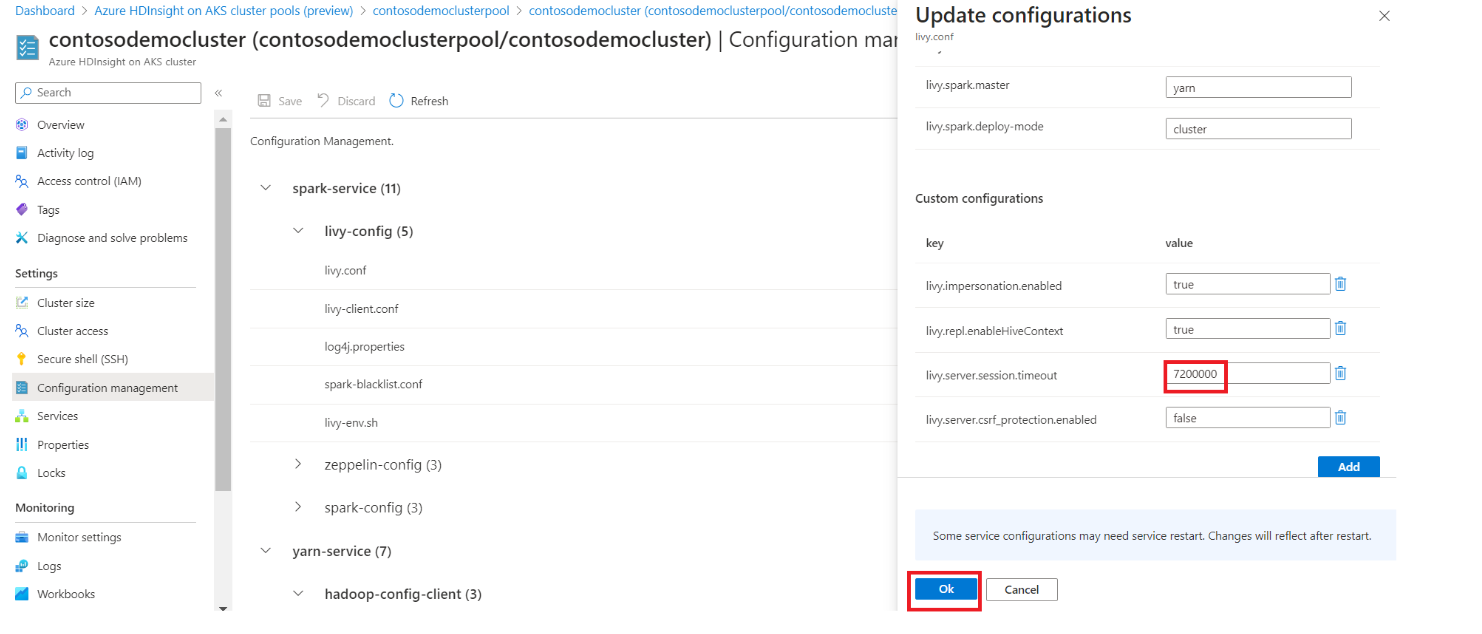
Um eine konfiguration zu ändern, ersetzen Sie die angegebenen Werte im Textfeld durch die gewünschten Werte, klicken Sie auf OK, und klicken Sie dann auf Speichern.
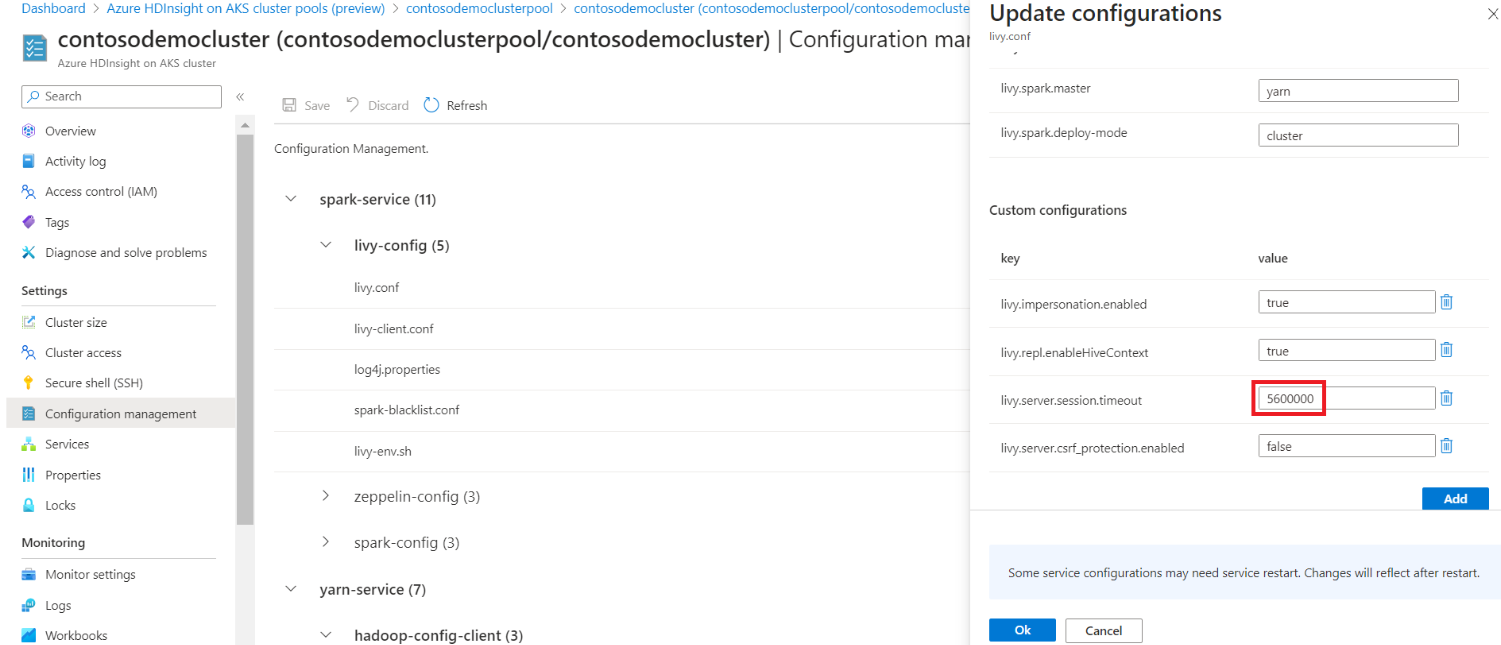
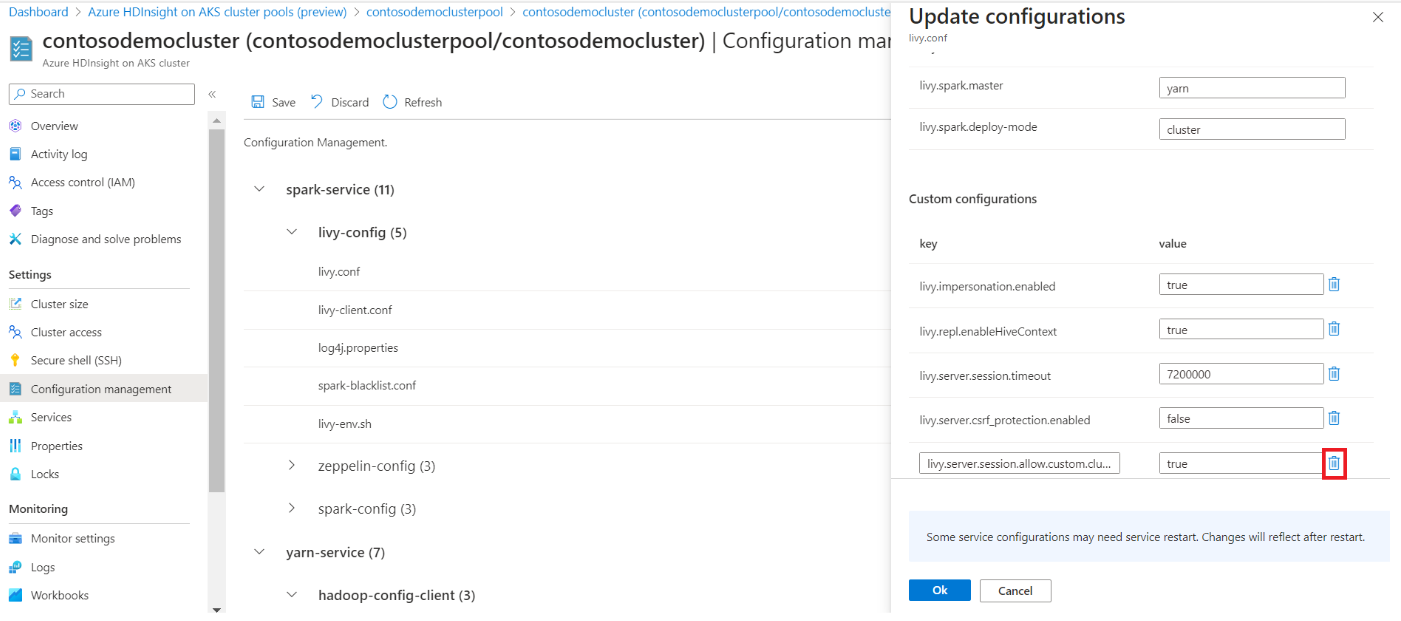
Wenn Sie einen neuen Parameter hinzufügen möchten, der standardmäßig nicht bereitgestellt wird, klicken Sie unten rechts auf "Hinzufügen".
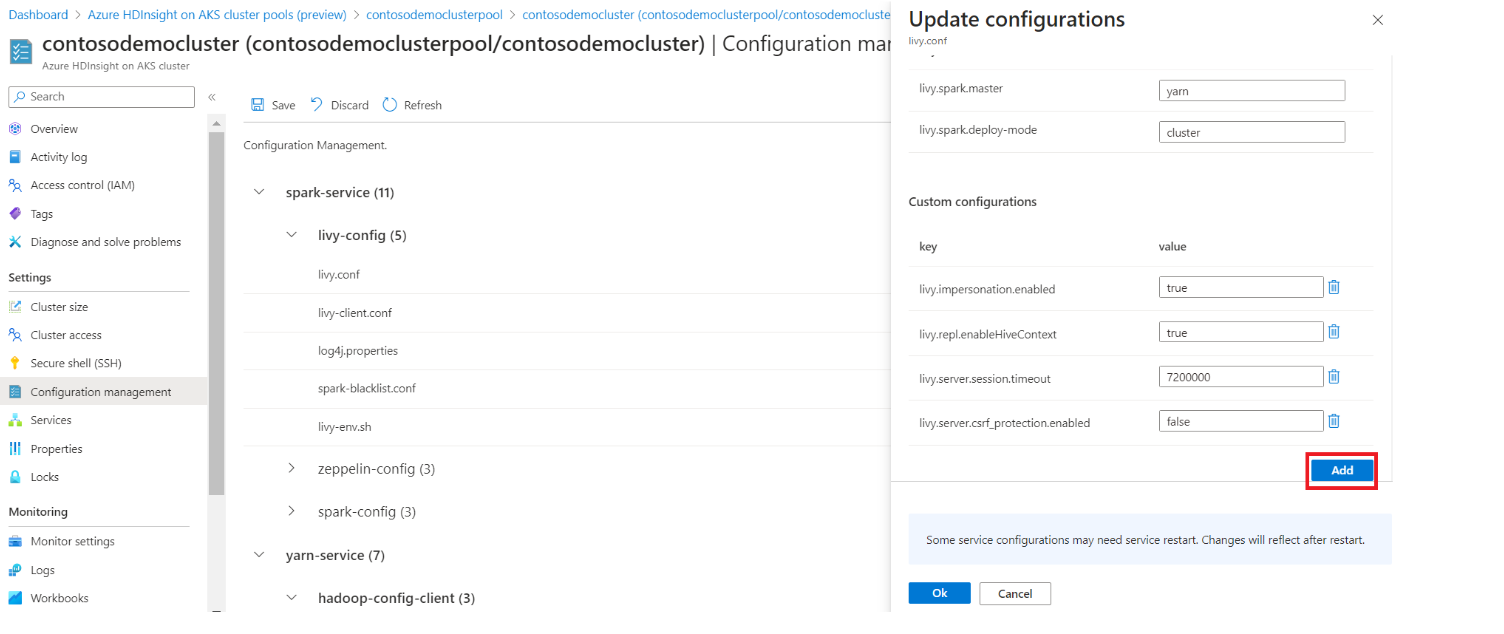
Fügen Sie die gewünschte Konfiguration hinzu, und klicken Sie auf "OK", und klicken Sie dann auf "Speichern".
Die Konfigurationen werden aktualisiert, und der Cluster wird neu gestartet.
Klicken Sie zum Löschen der Konfigurationen auf das Löschsymbol neben dem Textfeld.
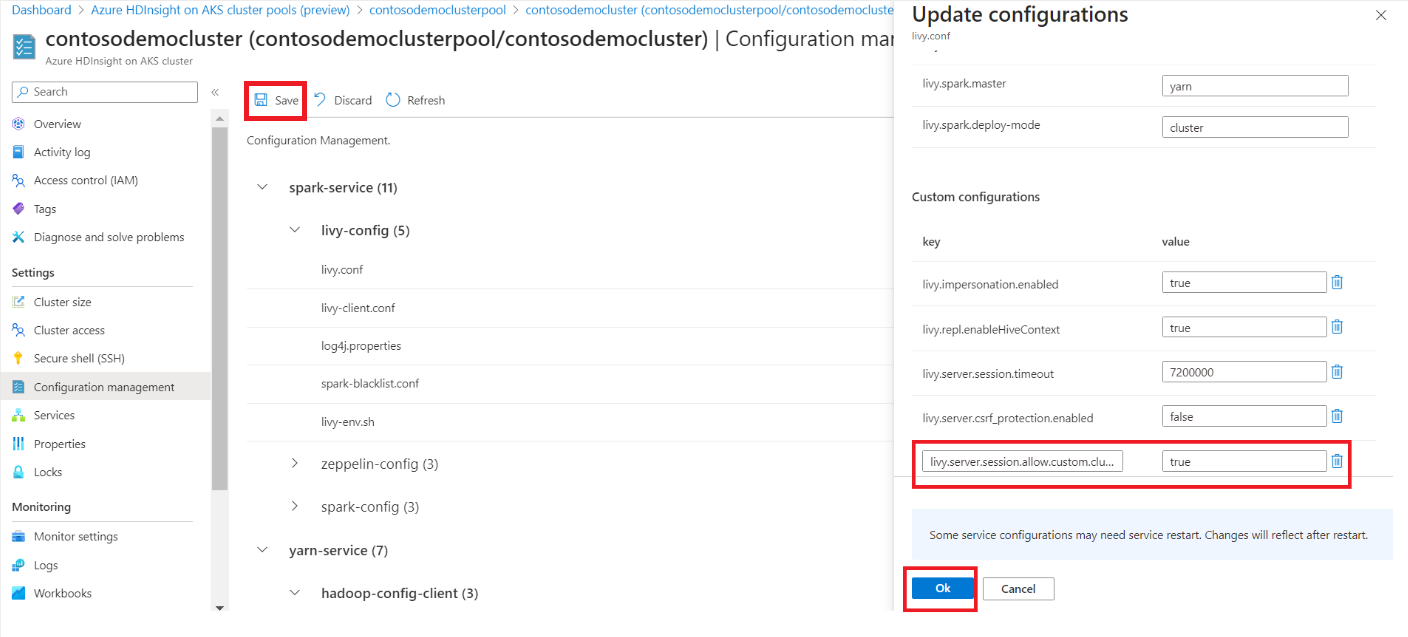
Klicken Sie auf "OK", und klicken Sie dann auf "Speichern".
Anmerkung
Wenn Sie Speichern auswählen, werden die Cluster neu gestartet. Es ist ratsam, keine aktiven Aufträge zu haben, während Konfigurationsänderungen vorgenommen werden, da sich der Neustart des Clusters auf die aktiven Aufträge auswirken kann.











Referenz
- Apache, Apache Spark, Spark und zugeordnete Open Source-Projektnamen sind Marken der Apache Software Foundation (ASF).