Automatische Skalierung von HDInsight auf AKS-Clustern
Wichtig
Azure HDInsight auf AKS wurde am 31. Januar 2025 eingestellt. Erfahren Sie mehr zu in dieser Ankündigung.
Sie müssen Ihre Workloads zu Microsoft Fabric oder ein gleichwertiges Azure-Produkt migrieren, um eine abrupte Beendigung Ihrer Workloads zu vermeiden.
Wichtig
Dieses Feature befindet sich derzeit in der Vorschau. Die zusätzlichen Nutzungsbedingungen für Microsoft Azure Previews weitere rechtliche Bestimmungen enthalten, die für Azure-Features gelten, die in der Betaversion, in der Vorschau oder auf andere Weise noch nicht in die allgemeine Verfügbarkeit veröffentlicht werden. Informationen zu dieser spezifischen Vorschau finden Sie unter Azure HDInsight auf AKS-Vorschauinformationen. Für Fragen oder Featurevorschläge sende bitte eine Anfrage an AskHDInsight und gib die Details an. Folge uns für weitere Updates zur Azure HDInsight Community.
Die Größe eines Clusters, um die Auftragsleistung zu erfüllen und Kosten im Voraus zu verwalten, ist immer schwierig und schwer zu bestimmen! Einer der lukrativen Vorteile des Baus von Data Lake House über die Cloud ist seine Flexibilität, was bedeutet, dass autoskalierte Funktion verwendet wird, um die Nutzung der zur Hand stehenden Ressourcen zu maximieren. Die automatische Skalierung mit Kubernetes ist ein Schlüssel zur Schaffung eines kostenoptimierten Ökosystems. Bei unterschiedlichen Nutzungsmustern in jedem Unternehmen können Sich im Laufe der Zeit Abweichungen in Clusterlasten ergeben, die dazu führen könnten, dass Cluster nicht bereitgestellt werden (schlechte Leistung) oder überprovisioniert (unnötige Kosten aufgrund leerer Ressourcen).
Die Autoskalierungsfunktion, die in HDInsight auf AKS angeboten wird, kann die Anzahl der Workerknoten in Ihrem Cluster automatisch erhöhen oder verringern. Die automatische Skalierung verwendet die Clustermetriken und die Skalierungsrichtlinie, die von den Kunden verwendet wird.
Dieses Feature eignet sich gut für geschäftskritische Workloads, die möglicherweise
- Variable oder unvorhersehbare Datenverkehrsmuster und benötigen Dienstgütevereinbarungen (SLAs) mit hoher Leistungsfähigkeit und Skalierbarkeit oder
- Vordefinierter Zeitplan für die erforderlichen Arbeitsknoten, die zur erfolgreichen Ausführung der Aufträge auf dem Cluster zur Verfügung stehen.
Die automatische Skalierung mit HDInsight auf AKS-Clustern macht die Cluster kosteneffizient und elastisch auf Azure.
Mit der automatischen Skalierung können Kunden Cluster verkleineren, ohne arbeitslasten zu beeinträchtigen. Es ist mit erweiterten Funktionen wie sanfter Außerbetriebnahme und Kühlperiode ausgestattet. Mit diesen Funktionen können Benutzer fundierte Entscheidungen zum Hinzufügen und Entfernen von Knoten basierend auf der aktuellen Auslastung des Clusters treffen.
Funktionsweise
Dieses Feature funktioniert, indem die Anzahl der Knoten innerhalb vordefinierter Grenzwerte basierend auf Clustermetriken oder einem definierten Zeitplan für Hochskalierungs- und Herunterskalierungsvorgänge angepasst wird. Es gibt zwei Arten von Bedingungen zum Auslösen von Autoskalenereignissen: schwellenwertbasierte Trigger für verschiedene Clusterleistungsmetriken (als load-based scaling bezeichnet) und zeitbasierte Trigger (als zeitplanbasierte Skalierung bezeichnet).
Die lastbasierte Skalierung ändert die Anzahl der Knoten in Ihrem Cluster innerhalb eines festgelegten Bereichs, um eine optimale CPU-Auslastung sicherzustellen und die Betriebskosten zu minimieren.
Die zeitplanbasierte Skalierung ändert die Anzahl der Knoten in Ihrem Cluster gemäß einem Zeitplan für Hoch- und Herunterskalierungsvorgänge.
Anmerkung
Die automatische Skalierung unterstützt keine Änderung des SKU-Typs eines vorhandenen Clusters.
Clusterkompatibilität
In der folgenden Tabelle werden die Clustertypen beschrieben, die mit der Funktion "Automatische Skalierung" kompatibel sind, und die verfügbaren oder geplanten Clustertypen.
| Arbeitsbelastung | Lastbasiert | Zeitplanbasiert |
|---|---|---|
| Flink | Geplant | Ja |
| Trino | Ja** | Ja** |
| Funke | Ja** | Ja** |
Die reibungslose Außerbetriebnahme ist konfigurierbar.
Skalierungsmethoden
zeitplanbasierte Skalierung:
Wenn Ihre Aufträge für feste Zeitpläne und eine vorhersehbare Dauer oder für eine geringe Nutzung während bestimmter Tageszeiten ausgeführt werden sollen, z. B. Test- und Entwicklungsumgebungen außerhalb der Arbeitszeiten, Tagesendaufgaben.
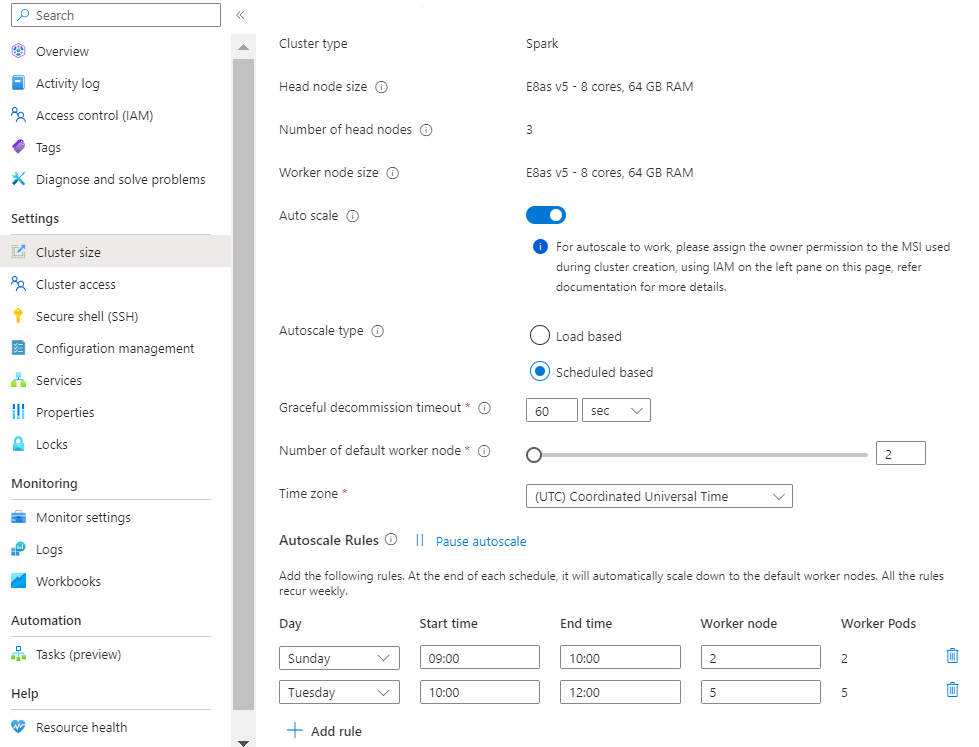
Lastabhängige Waage:
Wenn die Lastmuster während des Tages erheblich und unvorhersehbar schwanken, z. B. Bestelldatenverarbeitung mit zufälligen Schwankungen in Lastmustern basierend auf verschiedenen Faktoren.
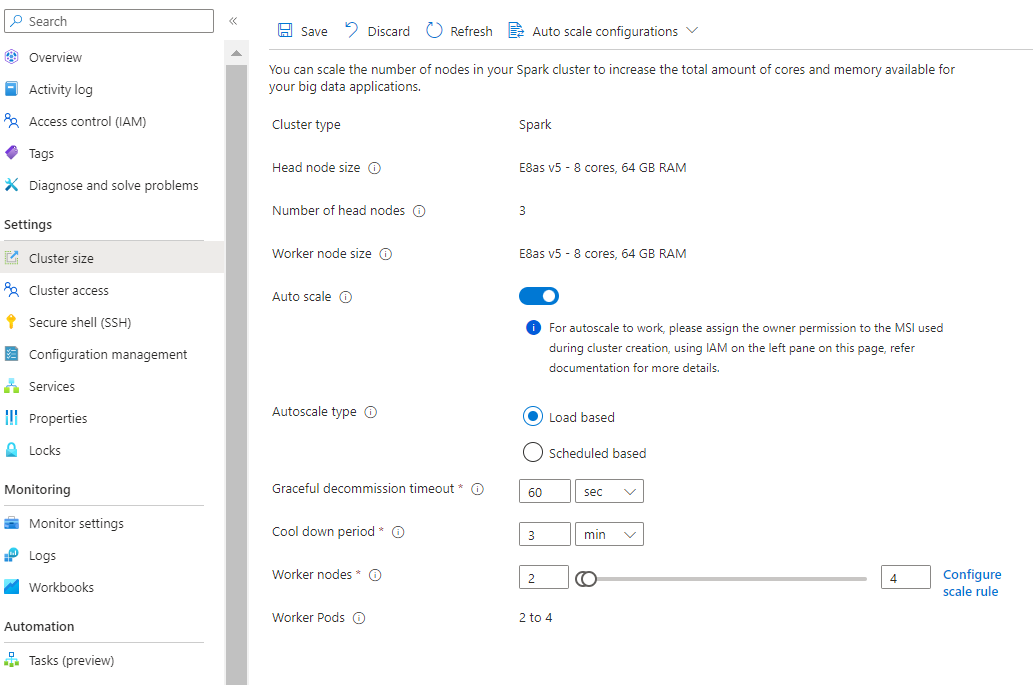
Mit der neuen Option "Skalierungsregel konfigurieren" können Sie jetzt die Skalierungsregeln anpassen.
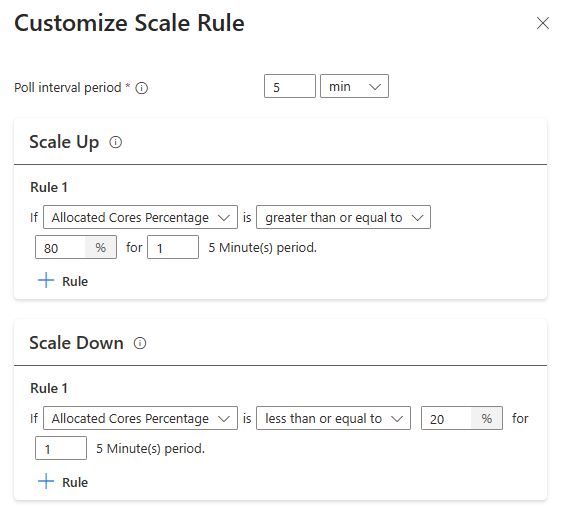
Trinkgeld
- Skalierungsregeln haben Vorrang, wenn eine oder mehrere Regeln ausgelöst werden. Selbst wenn nur eine der Regeln für das Hochskalieren darauf hinweist, dass das Cluster unterversorgt ist, wird versucht, das Cluster hochzuskalieren. Damit eine Skalierung nach unten erfolgt, darf keine Regel zur Skalierung nach oben ausgelöst werden.


Ladebasierte Skalierungsbedingungen
Wenn die folgenden Bedingungen erkannt werden, gibt die automatische Skalierung eine Skalierungsanforderung aus.
| Hochskalieren | Skalierung nach unten |
|---|---|
| Zugewiesene Kerne sind größer als 80% bei einem Abrufintervall von 5 Minuten (bei einer Prüfperiode von 1 Minute) | Zugewiesene Kerne sind kleiner oder gleich 20% für ein 5-minütiges Abfrageintervall (1-minütiger Prüfzeitraum) |
Bei der Skalierung stellt die Auto-Skalierung eine Skalierungsanforderung, um die erforderliche Anzahl von Knoten hinzuzufügen. Die Skalierung basiert darauf, wie viele neue Arbeitsknoten benötigt werden, um die aktuellen CPU- und Arbeitsspeicheranforderungen zu erfüllen. Dieser Wert ist auf die maximale Anzahl festgelegter Arbeitsknoten begrenzt.
Beim Herunterskalieren stellt die Automatische Skalierung eine Anfrage zum Entfernen einiger Knoten. Die Skalierungsüberlegungen umfassen die Anzahl der Pods pro Knoten, die aktuellen CPU- und Arbeitsspeicheranforderungen und Arbeitsknoten, die Kandidaten für die Entfernung basierend auf der aktuellen Auftragsausführung sind. Der Scale down-Vorgang setzt die Knoten zuerst außer Betrieb und entfernt sie dann aus dem Cluster.
Wichtig
Die Auto-Scale-Regel-Engine löscht vorausschauend alte Ereignisse alle 30 Minuten, um den Systemspeicher zu optimieren. Daher gibt es im Skalierungsregelintervall eine Obergrenze von 30 Minuten. Um die konsistente und zuverlässige Auslösung von Skalierungsaktionen sicherzustellen, ist es zwingend erforderlich, das Skalierungsregelintervall auf einen Wert festzulegen, der kleiner als der Grenzwert ist. Durch Einhaltung dieser Richtlinie können Sie einen reibungslosen und effizienten Skalierungsprozess garantieren und gleichzeitig Systemressourcen effektiv verwalten.
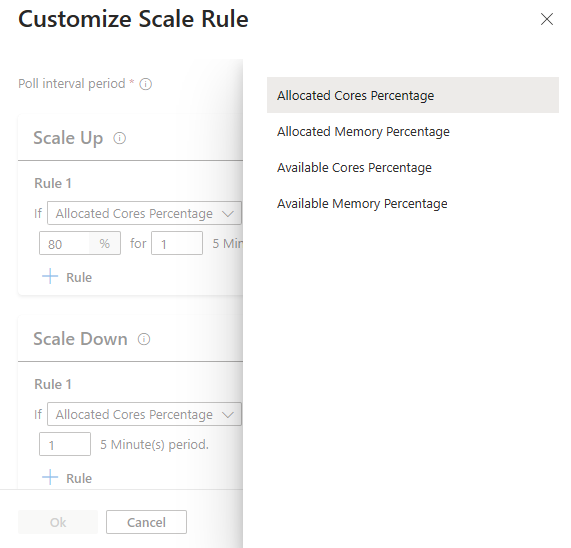
Clustermetriken
Die automatische Skalierung überwacht kontinuierlich den Cluster und sammelt die folgenden Metriken für die lastbasierte Autoskalierung:
Clustermetriken für Skalierungszwecke verfügbar
| Metrik | Beschreibung |
|---|---|
| Prozentsatz der verfügbaren Kerne | Die Gesamtzahl der im Cluster verfügbaren Kerne im Vergleich zur Gesamtzahl der Kerne im Cluster. |
| Verfügbarer Arbeitsspeicherprozentsatz | Der im Cluster verfügbare Gesamtspeicher (in MB) im Vergleich zur Gesamtmenge des Arbeitsspeichers im Cluster. |
| Zugewiesener Kernanteil | Die Gesamtzahl der im Cluster zugewiesenen Kerne im Vergleich zur Gesamtanzahl der Kerne im Cluster. |
| Zugewiesener Arbeitsspeicherprozentsatz | Die Menge des im Cluster zugeordneten Arbeitsspeichers im Vergleich zur Gesamtmenge des Arbeitsspeichers im Cluster. |
Standardmäßig werden die obigen Metriken alle 300 Sekundenüberprüft, es kann auch konfiguriert werden, wenn Sie das Abfrageintervall mit der Option "Autoskalen anpassen" anpassen. Die automatische Skalierung trifft Entscheidungen zur Skalierung nach oben oder unten basierend auf diesen Metriken.
Anmerkung
Standardmäßig verwendet die automatische Skalierung standardmäßig den Standardressourcenrechner für YARN für Apache Spark. Lastbasierte Skalierung ist für Apache Spark Clusters verfügbar.
Sanfte Stilllegung
Unternehmen benötigen Möglichkeiten, petabyte-Skalierung mit automatischer Skalierung zu erreichen und Ressourcen ordnungsgemäß außer Betrieb zu setzen, wenn sie nicht mehr benötigt werden. In einem solchen Szenario erweist sich die Funktion für die Außerbetriebnahme als hilfreich.
Die elegante Außerbetriebnahme ermöglicht den Abschluss von Aufträgen, selbst wenn die automatische Skalierung die Außerbetriebnahme der Arbeitsknoten ausgelöst hat. Mit diesem Feature können Knoten weiterhin bereitgestellt werden, bis Aufträge abgeschlossen sind.
Trino: Mitarbeiter haben standardmäßig "Graceful Decommission" aktiviert. Der Koordinator ermöglicht dem zu beendenden Worker, seine Aufgaben für eine festgelegte Zeitspanne abzuschließen, bevor er aus dem Cluster entfernt wird. Sie können das Timeout entweder mithilfe des nativen Trino-Parameters
shutdown.grace-periododer auf der Azure-Portaldienstkonfigurationsseite konfigurieren.Apache Spark: Das Herunterskalieren kann alle laufenden Aufträge im Cluster beeinträchtigen/beenden. Wenn Sie die Einstellungen für Graceful Decommissioning im Azure-Portal aktivieren, umfasst dies Graceful Decommission von YARN-Knoten und stellt sicher, dass alle laufenden Arbeiten an einem Arbeitsknoten abgeschlossen sind, bevor der Knoten aus dem HDInsight im AKS-Cluster entfernt wird.
Abkühlzeit
Um fortlaufende Skalierungsvorgänge zu vermeiden, wartet das Autoscale-Modul auf ein konfigurierbares Intervall, bevor eine andere Reihe von Skalierungsvorgängen initiiert wird. Der Standardwert ist auf 180 Sekunden eingestellt.
Anmerkung
- In benutzerdefinierten Skalierungsregeln kann kein Regeltrigger über ein Triggerintervall von mehr als 30 Minuten verfügen. Nachdem ein Ereignis für die automatische Skalierung eintritt, ist die Wartezeit, bevor eine zusätzliche Skalierungsrichtlinie erzwungen wird.
- Der Abkühlzeitraum sollte größer als das Richtlinienintervall sein, sodass die Clustermetriken zurückgesetzt werden können.
Loslegen
Damit die automatische Skalierung funktioniert, müssen Sie den Besitzer oder Mitwirkenden Berechtigung für die MSI-Datei (während der Clustererstellung) auf Clusterebene zuweisen, indem Sie IM linken Bereich IAM verwenden.
Beziehen Sie sich auf die folgende Abbildung und die Schritte, um eine Rollenzuweisung hinzuzufügen.
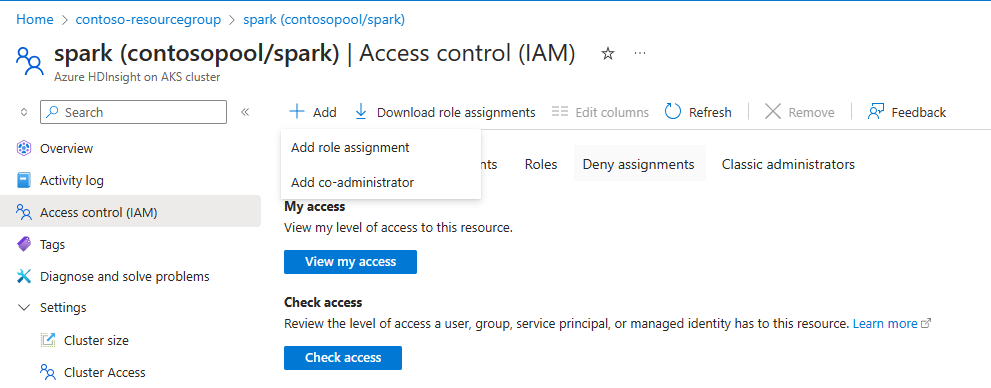
Wählen Sie Rollenzuweisunghinzufügen,
- Zuordnungstyp: Privilegierte Administratorrollen
- Rolle: Besitzer oder Mitwirkender
- Mitglieder: Wählen Sie "verwaltete Identität" aus, und wählen Sie die vom Benutzer zugewiesene verwaltete Identität aus, die während der Clustererstellungsphase angegeben wurde.
- Weisen Sie die Rolle zu.

Erstellen eines Clusters mit zeitplanbasierter automatischer Skalierung
Nachdem Ihr Clusterpool erstellt wurde, erstellen Sie einen neuen Cluster mit Ihrer gewünschten Arbeitsauslastung (im Clustertyp), und führen Sie die anderen Schritte im Rahmen des normalen Clustererstellungsprozesses aus.
Aktivieren Sie auf der Registerkarte KonfigurationUmschaltfläche automatische Skalierung.
Wählen Sie die auf dem Zeitplan basierende Option zum automatischen Skalieren aus.
Wählen Sie Ihre Zeitzone aus, und klicken Sie dann auf + Regel hinzufügen
Wählen Sie die Wochentage aus, auf die die neue Bedingung angewendet werden soll.
Bearbeiten Sie die Zeit, zu der die Bedingung wirksam werden soll, und die Anzahl der Knoten, auf die der Cluster skaliert werden soll.
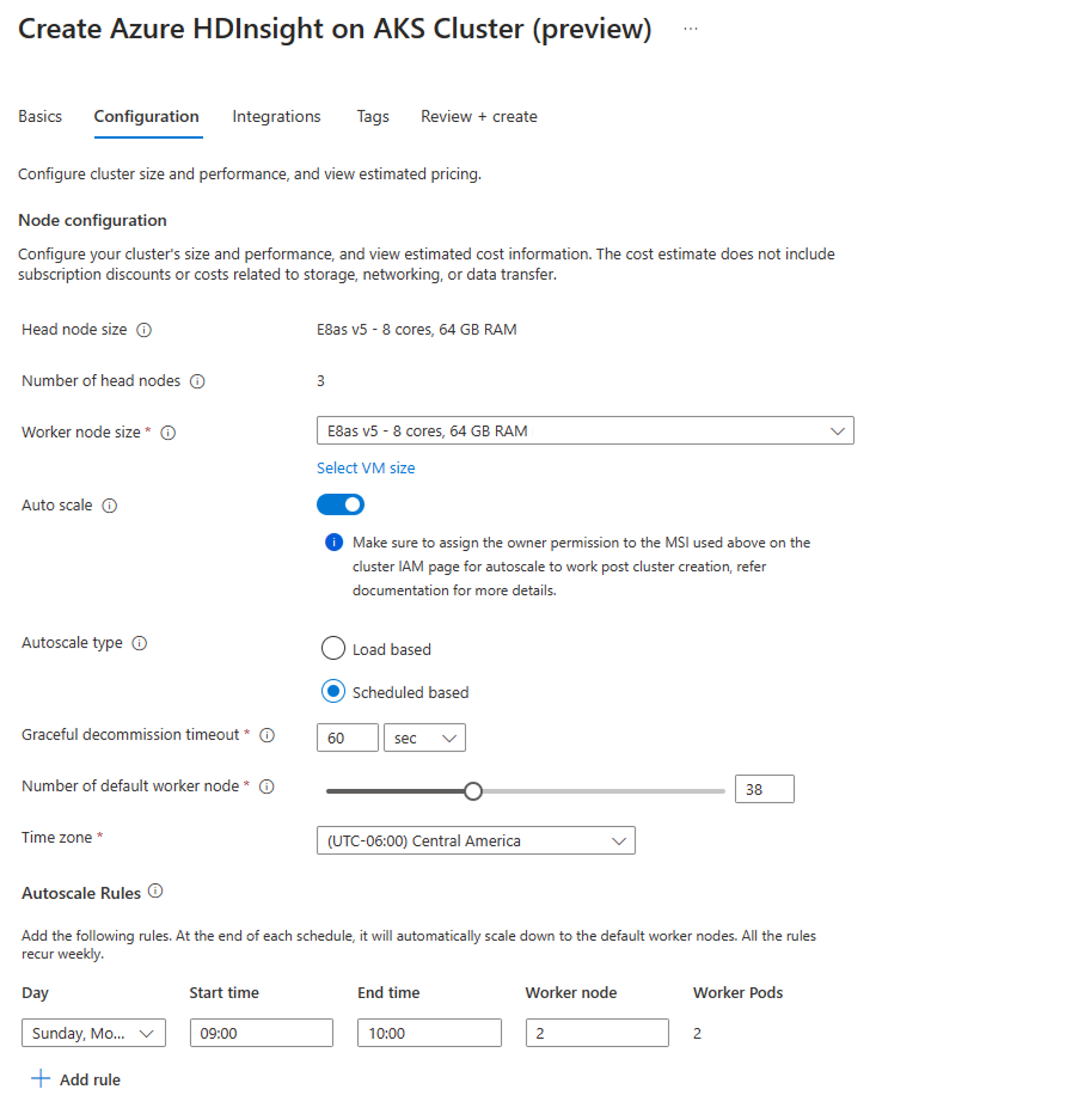
Anmerkung
- Der Benutzer sollte über die Rolle "Besitzer" oder "Mitwirkender" im Cluster-MSI verfügen, damit die Automatische Skalierung funktioniert.
- Der Standardwert definiert die anfängliche Größe des Clusters, wenn er erstellt wird.
- Der Unterschied zwischen zwei Zeitplänen ist standardmäßig auf 30 Minuten festgelegt.
- Der Zeitwert folgt dem 24-Stunden-Format.
- Im Falle eines fortlaufenden Fensters von über 24 Stunden über Tage hinweg müssen Sie den Zeitplan für die automatische Skalierung über Tage hinweg festlegen, und die automatische Skalierung nimmt 23:59 als 00:00 (mit derselben Knotenanzahl) an, die sich über zwei Tage zwischen 22:00 und 23:59, 00:00 bis 02:00 bis 22:00 bis 02:00 erstreckt.
- Die Zeitpläne werden standardmäßig in koordinierter Weltzeit (UTC) festgelegt. Sie können jederzeit auf die Zeitzone aktualisieren, die Ihrer lokalen Zeitzone in der verfügbaren Dropdownliste entspricht. Wenn Sie sich in einer Zeitzone befinden, die Daylight Savings beobachtet, wird der Zeitplan nicht automatisch angepasst, Sie müssen die Zeitplanaktualisierungen entsprechend verwalten.

Erstellen eines Clusters mit lastbasierter automatischer Skalierung
Nachdem Ihr Clusterpool erstellt wurde, erstellen Sie einen neuen Cluster mit Ihrer gewünschten Arbeitsauslastung (im Clustertyp), und führen Sie die anderen Schritte im Rahmen des normalen Clustererstellungsprozesses aus.
Aktivieren Sie auf der Registerkarte Konfiguration die Umschaltfläche automatische Skalierung.
Wählen Sie Load based autoscale aus.
Basierend auf der Art der Workload haben Sie die Möglichkeit, ein reibungsloses Außerbetriebnahme-Zeitlimitund eine Abkühlzeit hinzuzufügen.
Wählen Sie die mindesten und maximalen Knoten aus, und konfigurieren Sie bei Bedarf die Skalierungsregeln, um die automatische Skalierung an Ihre Anforderungen anzupassen.
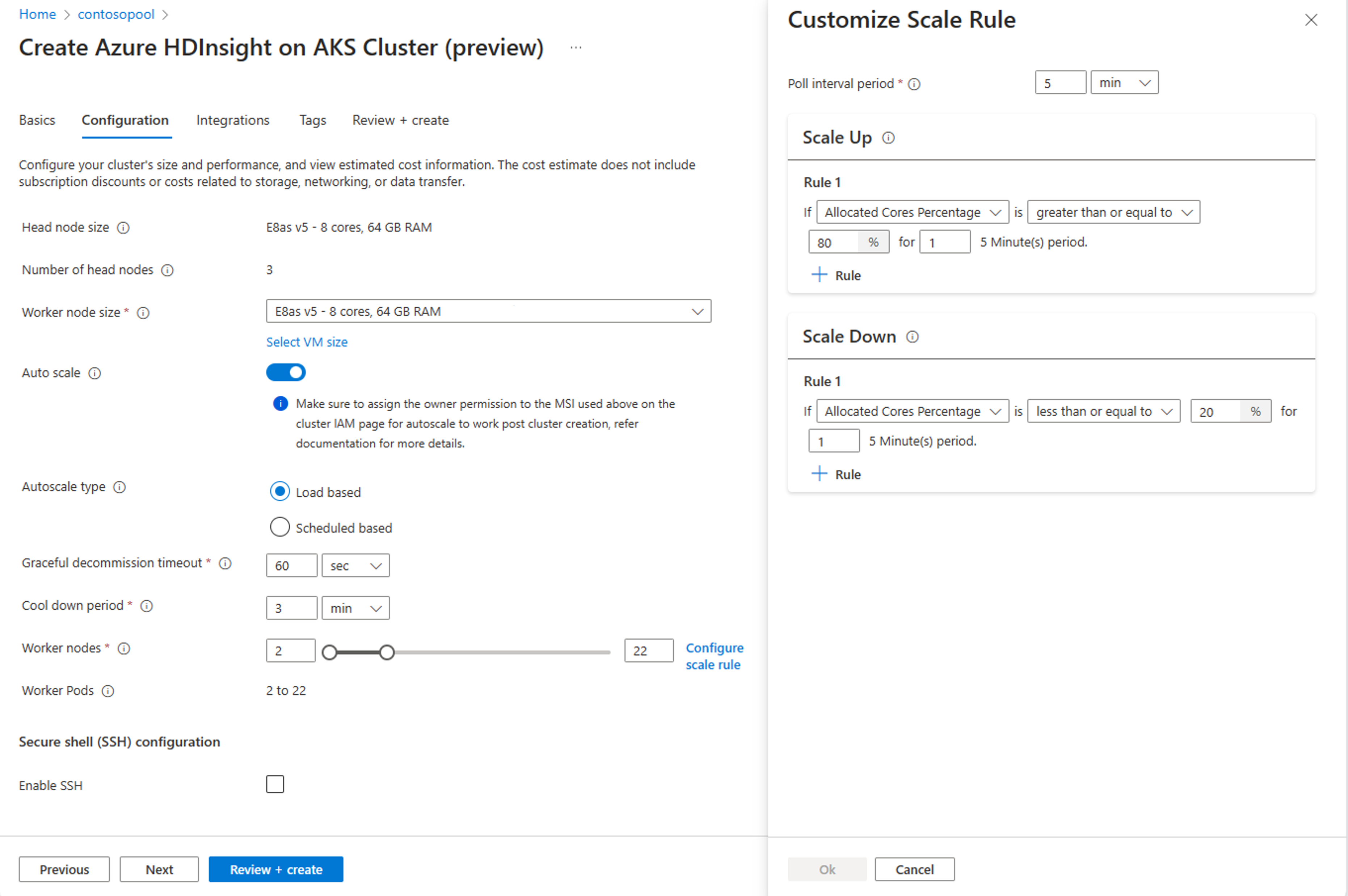
Trinkgeld
- Ihr Abonnement verfügt über ein Kapazitätskontingent für jede Region. Die Gesamtzahl der Kerne Ihrer Hauptknoten und die maximale Anzahl an Arbeitsknoten darf das Kapazitätskontingent nicht überschreiten. Dieses Kontingent ist jedoch eine weiche Grenze; Sie können jederzeit ein Supportticket erstellen, um es einfach zu erhöhen.
- Wenn Sie den Gesamten Kernkontingentgrenzwert überschreiten, erhalten Sie eine Fehlermeldung, die besagt,
The maximum node count you can select is {maxCount} due to the remaining quota in the selected subscription ({remaining} cores). - Skalierungsregeln haben Vorrang, wenn mindestens eine Regel ausgelöst wird. Selbst wenn nur eine der Regeln darauf hindeutet, dass das Cluster unterversorgt ist, wird das Cluster versuchen, sich zu vergrößern. Damit die Skalierung nach unten erfolgen kann, darf keine Regel für das Hochskalieren ausgelöst werden.
- In der öffentlichen Vorschau unterstützt HDInsight auf AKS bis zu 500 Knoten in einem Cluster.

Erstellen eines Clusters mit einer Ressourcen-Manager-Vorlage
Zeitplanbasierte automatische Skalierung
Sie können ein HDInsight auf einem AKS-Cluster mit zeitplanbasierter Autoskalierung mithilfe einer Azure Resource Manager-Vorlage erstellen, indem Sie dem Clusterprofile-Abschnitt -> "autoscaleProfile" eine Autoskalierung konfigurieren.
Der AutoScale-Knoten enthält eine Wiederholung mit einer Zeitzone und einem Zeitplan, der beschreibt, wann die Änderung stattfindet. Eine vollständige Resource Manager-Vorlage finden Sie im Beispiel-JSON
{
"autoscaleProfile": {
"enabled": true,
"autoscaleType": "ScheduleBased",
"gracefulDecommissionTimeout": 60,
"scheduleBasedConfig": {
"schedules": [
{
"days": [
"Monday",
"Tuesday",
"Wednesday"
],
"startTime": "09:00",
"endTime": "10:00",
"count": 2
},
{
"days": [
"Sunday",
"Saturday"
],
"startTime": "12:00",
"endTime": "22:00",
"count": 5
},
{
"days": [
"Monday",
"Tuesday",
"Wednesday",
"Thursday",
"Friday"
],
"startTime": "22:00",
"endTime": "23:59",
"count": 6
},
{
"days": [
"Monday",
"Tuesday",
"Wednesday",
"Thursday",
"Friday"
],
"startTime": "00:00",
"endTime": "05:00",
"count": 6
}
],
"timeZone": "UTC",
"defaultCount": 110
}
}
}
Tipp
- Sie müssen konfliktfreie Zeitpläne mithilfe von ARM-Bereitstellungen festlegen, um Fehlfunktionen bei Skalierungsvorgängen zu vermeiden.
lastbasierte automatische Skalierung
Sie können ein HDInsight auf einem AKS-Cluster mit ladebasierter Autoskalierung mithilfe einer Azure Resource Manager-Vorlage erstellen, indem Sie dem Clusterprofil im Abschnitt> "autoscaleProfile" eine Autoskalierung hinzufügen.
Der Knoten "AutoScale" enthält
- Ein Abrufintervall, Abkühlperiode,
- sanfte Außerbetriebnahme
- minimale und maximale Knoten,
- Standardschwellenregeln,
- Skalierungsmetriken, die beschreiben, wann die Änderung stattfindet.
Eine vollständige Ressourcen-Manager-Vorlage finden Sie im Beispiel-JSON wie folgt:
{
"autoscaleProfile": {
"enabled": true,
"autoscaleType": "LoadBased",
"gracefulDecommissionTimeout": 60,
"loadBasedConfig": {
"minNodes": 2,
"maxNodes": 157,
"pollInterval": 300,
"cooldownPeriod": 180,
"scalingRules": [
{
"actionType": "scaleup",
"comparisonRule": {
"threshold": 80,
"operator": " greaterThanOrEqual"
},
"evaluationCount": 1,
"scalingMetric": "allocatedCoresPercentage"
},
{
"actionType": "scaledown",
"comparisonRule": {
"threshold": 20,
"operator": " lessThanOrEqual"
},
"evaluationCount": 1,
"scalingMetric": "allocatedCoresPercentage"
}
]
}
}
}
Verwenden der REST-API
Um die automatische Skalierung für einen ausgeführten Cluster mithilfe der REST-API zu aktivieren oder zu deaktivieren, erstellen Sie eine PATCH-Anforderung an Ihren Endpunkt für die automatische Skalierung: https://management.azure.com/subscriptions/{{USER_SUB}}/resourceGroups/{{USER_RG}}/providers/Microsoft.HDInsight/clusterpools/{{CLUSTER_POOL_NAME}}/clusters/{{CLUSTER_NAME}}?api-version={{HILO_API_VERSION}}
- Verwenden Sie die entsprechenden Parameter in der Anforderungsnutzlast. Die JSON-Nutzlast kann verwendet werden, um die automatische Skalierung zu aktivieren.
- Verwenden Sie das Payload (autoscaleProfile: null) oder das Flag (enabled, false), um die automatische Skalierung zu deaktivieren.
- Siehe die im obigen Schritt erwähnten JSON-Beispiele als Referenz.
Automatische Skalierung für einen laufenden Cluster anhalten
Wir haben das Feature "Pause" in der automatischen Skalierung eingeführt. Jetzt können Sie mithilfe des Azure-Portals die automatische Skalierung auf einem ausgeführten Cluster anhalten. Das folgende Diagramm veranschaulicht, wie sie die automatische Skalierung für Pause und Fortsetzen auswählen.

Sie können den Vorgang fortsetzen, sobald Sie die Vorgänge für die automatische Skalierung fortsetzen möchten.

Trinkgeld
Wenn Sie mehrere Zeitpläne konfigurieren und die Automatische Skalierung anhalten, wird der nächste Zeitplan nicht ausgelöst. Die Knotenanzahl bleibt unverändert, auch wenn sich die Knoten in einem außerBetrieb genommenen Zustand befinden.
Automatische Skalierungskonfigurationen kopieren
Mithilfe des Azure-Portals können Sie jetzt die gleichen Autoskalenkonfigurationen für ein gleiches Cluster-Shape in Ihrem Clusterpool kopieren, sie können dieses Feature verwenden und dieselben Konfigurationen exportieren oder importieren.

Überwachen von Aktivitäten für die automatische Skalierung
Cluster-Status
Der im Azure-Portal aufgelistete Clusterstatus kann Ihnen helfen, Aktivitäten der automatischen Skalierung zu überwachen. Alle Clusterstatusmeldungen, die Möglicherweise angezeigt werden, werden in der Liste erläutert.
| Clusterstatus | Beschreibung |
|---|---|
| Erfolgreich | Der Cluster läuft normal. Alle vorherigen Aktivitäten der automatischen Skalierung wurden erfolgreich abgeschlossen. |
| Angenommen | Der Clustervorgang (z. B. Erweiterung) wird akzeptiert und wartet darauf, abgeschlossen zu werden. |
| Misslungen | Dies bedeutet, dass ein aktueller Vorgang aus irgendeinem Grund fehlgeschlagen ist, der Cluster ist möglicherweise nicht funktionsfähig. |
| Storniert | Der aktuelle Vorgang ist abgesagt. |
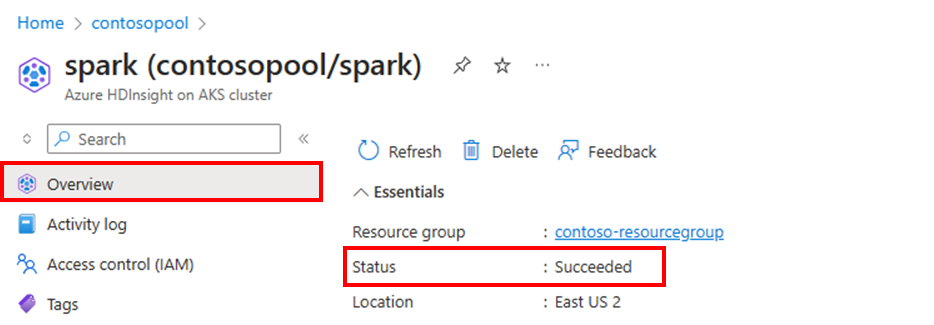
Um die aktuelle Anzahl von Knoten in Ihrem Cluster anzuzeigen, wechseln Sie auf der Seite Übersicht Ihres Clusters zum Clustergröße Diagramms.

Vorgangsverlauf
Sie können den Hoch- und Herunterskalierungsverlauf des Clusters als Teil der Clustermetriken anzeigen. Sie können auch alle Skalierungsaktionen über den letzten Tag, die Woche oder einen anderen Zeitraum auflisten.

Zusätzliche Ressourcen