Verwenden von Apache Kafka® auf HDInsight gemeinsam mit Apache Flink® auf HDInsight in AKS
Wichtig
Azure HDInsight auf AKS wurde am 31. Januar 2025 eingestellt. Erfahren Sie mehr über in dieser Ankündigung.
Sie müssen Ihre Workloads zu Microsoft Fabric oder ein gleichwertiges Azure-Produkt migrieren, um eine abrupte Beendigung Ihrer Workloads zu vermeiden.
Wichtig
Dieses Feature befindet sich derzeit in der Vorschau. Die zusätzlichen Nutzungsbedingungen für Microsoft Azure Previews weitere rechtliche Bestimmungen enthalten, die für Azure-Features gelten, die in der Betaversion, in der Vorschau oder auf andere Weise noch nicht in die allgemeine Verfügbarkeit veröffentlicht werden. Informationen zu dieser spezifischen Vorschau finden Sie unter Azure HDInsight auf AKS-Vorschauinformationen. Für Fragen oder Funktionsvorschläge senden Sie bitte eine Anfrage mit den Details an AskHDInsight und folgen Sie uns für weitere Updates zur Azure HDInsight Community.
Ein bekannter Anwendungsfall für Apache Flink ist Stream Analytics. Die beliebte Wahl vieler Benutzer, die Datenströme zu verwenden, die mit Apache Kafka aufgenommen werden. Typische Installationen von Flink und Kafka beginnen mit Ereignisströmen, die an Kafka gesendet werden und von Flink-Aufträgen genutzt werden können.
In diesem Beispiel wird HDInsight auf AKS-Clustern verwendet, die Flink 1.17.0 ausführen, um Streamingdaten zu verarbeiten, die das Kafka-Thema verarbeiten und produzieren.
Anmerkung
FlinkKafkaConsumer ist veraltet und wird mit Flink 1.17 entfernt, verwenden Sie stattdessen KafkaSource. FlinkKafkaProducer ist veraltet und wird mit Flink 1.15 entfernt, verwenden Sie stattdessen KafkaSink.
Voraussetzungen
Sowohl Kafka als auch Flink müssen sich im gleichen VNet befinden, oder es sollte vnet-peering zwischen den beiden Clustern vorhanden sein.
Erstellen eines Kafka-Clusters im selben VNet. Sie können Kafka 3.2 oder 2.4 auf HDInsight basierend auf Ihrer aktuellen Nutzung auswählen.
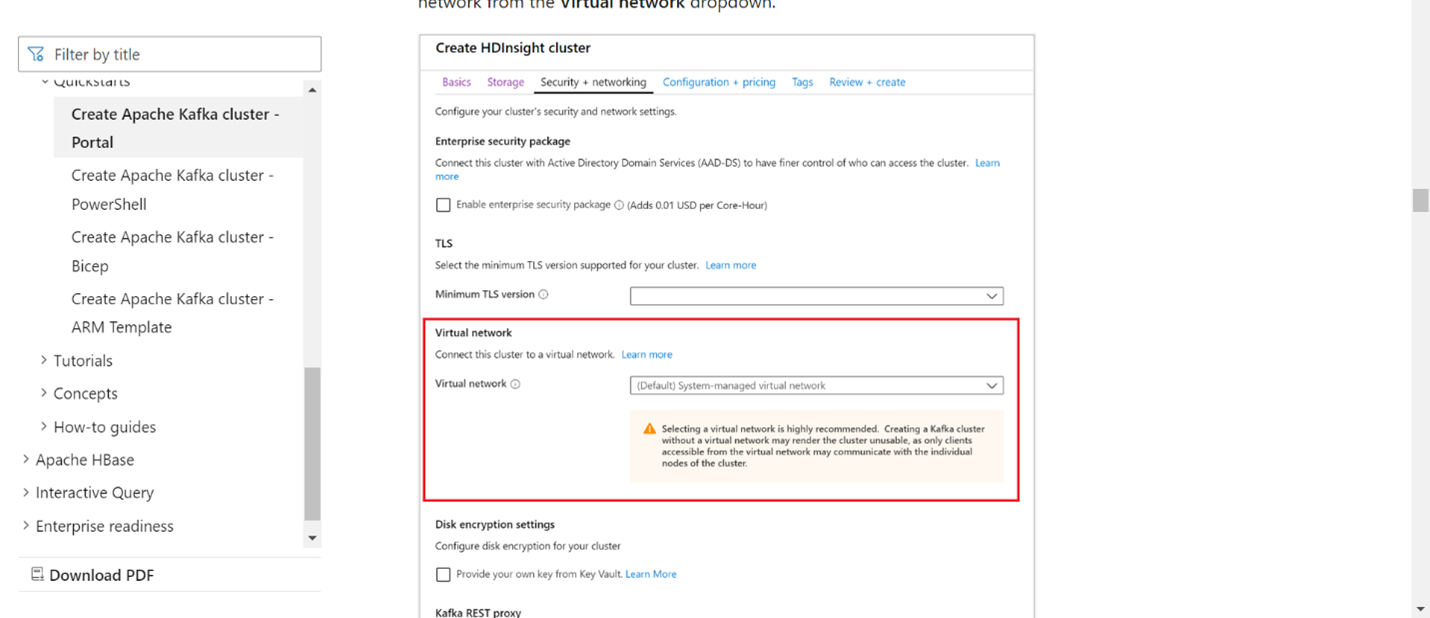
Fügen Sie die VNet-Details im Abschnitt "Virtuelles Netzwerk" hinzu.
Erstellen Sie ein HDInsight im AKS-Clusterpool mit demselben VNet.
Erstellen Sie einen Flink-Cluster zum erstellten Clusterpool.

Apache Kafka Connector
Flink bietet einen Apache Kafka Connector zum Lesen von Daten aus und Schreiben von Daten in Kafka-Topics mit Garantien für genau einmalige Lieferung.
Maven-Abhängigkeit
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-connector-kafka</artifactId>
<version>1.17.0</version>
</dependency>
Gebäude Kafka Sink
Kafka Sink stellt eine Generatorklasse bereit, um eine Instanz eines KafkaSink zu erstellen. Wir verwenden das gleiche Verfahren, um unser Sink zu konstruieren, und verwenden es zusammen mit dem auf HDInsight auf AKS laufenden Flink-Cluster.
SinKafkaToKafka.java
import org.apache.flink.api.common.eventtime.WatermarkStrategy;
import org.apache.flink.api.common.functions.MapFunction;
import org.apache.flink.api.common.serialization.SimpleStringSchema;
import org.apache.flink.connector.base.DeliveryGuarantee;
import org.apache.flink.connector.kafka.sink.KafkaRecordSerializationSchema;
import org.apache.flink.connector.kafka.sink.KafkaSink;
import org.apache.flink.connector.kafka.source.KafkaSource;
import org.apache.flink.connector.kafka.source.enumerator.initializer.OffsetsInitializer;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
public class SinKafkaToKafka {
public static void main(String[] args) throws Exception {
// 1. get stream execution environment
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
// 2. read kafka message as stream input, update your broker IPs below
String brokers = "X.X.X.X:9092,X.X.X.X:9092,X.X.X.X:9092";
KafkaSource<String> source = KafkaSource.<String>builder()
.setBootstrapServers(brokers)
.setTopics("clicks")
.setGroupId("my-group")
.setStartingOffsets(OffsetsInitializer.earliest())
.setValueOnlyDeserializer(new SimpleStringSchema())
.build();
DataStream<String> stream = env.fromSource(source, WatermarkStrategy.noWatermarks(), "Kafka Source");
// 3. transformation:
// https://www.taobao.com,1000 --->
// Event{user: "Tim",url: "https://www.taobao.com",timestamp: 1970-01-01 00:00:01.0}
SingleOutputStreamOperator<String> result = stream.map(new MapFunction<String, String>() {
@Override
public String map(String value) throws Exception {
String[] fields = value.split(",");
return new Event(fields[0].trim(), fields[1].trim(), Long.valueOf(fields[2].trim())).toString();
}
});
// 4. sink click into another kafka events topic
KafkaSink<String> sink = KafkaSink.<String>builder()
.setBootstrapServers(brokers)
.setProperty("transaction.timeout.ms","900000")
.setRecordSerializer(KafkaRecordSerializationSchema.builder()
.setTopic("events")
.setValueSerializationSchema(new SimpleStringSchema())
.build())
.setDeliveryGuarantee(DeliveryGuarantee.EXACTLY_ONCE)
.build();
result.sinkTo(sink);
// 5. execute the stream
env.execute("kafka Sink to other topic");
}
}
Ein Java-Programm namens Event.java schreiben
import java.sql.Timestamp;
public class Event {
public String user;
public String url;
public Long timestamp;
public Event() {
}
public Event(String user,String url,Long timestamp) {
this.user = user;
this.url = url;
this.timestamp = timestamp;
}
@Override
public String toString(){
return "Event{" +
"user: \"" + user + "\"" +
",url: \"" + url + "\"" +
",timestamp: " + new Timestamp(timestamp) +
"}";
}
}
Packen Sie die JAR-Datei und reichen Sie den Job bei Flink ein
Laden Sie auf Webssh die Jar-Datei hoch und übermitteln Sie die Jar-Datei.

Auf der Benutzeroberfläche des Flink-Dashboards

Produzieren Sie das Thema - Klick auf Kafka

Verarbeitung des Themas - Veranstaltungen zu Kafka

Referenz
- Apache Kafka Connector
- Apache, Apache Kafka, Kafka, Apache Flink, Flink und zugehörige Open Source-Projektnamen sind Marken der Apache Software Foundation (ASF).