Migrieren von Batch KI zu Azure Machine Learning Service
Der Azure Batch KI-Dienst wird im März eingestellt. Die skalierbaren Trainings- und Bewertungsfunktionen von Batch KI sind jetzt im Azure Machine Learning Service verfügbar, der am 4. Dezember 2018 in die allgemeine Verfügbarkeit überging.
Der Azure Machine Learning Service umfasst neben vielen weiteren Funktionen für das maschinelle Lernen ein cloudbasiertes, verwaltetes Computeziel zum Trainieren, Bereitstellen und Bewerten von Machine Learning-Modellen. Dieses Computeziel heißt Azure Machine Learning Compute. Beginnen Sie noch heute mit der Migration und Nutzung. Sie können über die entsprechenden Python SDKs, die Befehlszeilenschnittstelle und das Azure-Portal mit dem Azure Machine Learning Service interagieren.
Wenn Sie von der Batch KI-Vorschauversion auf die allgemein verfügbare Version von Azure Machine Learning Service upgraden, stehen Ihnen benutzerfreundlichere Konzepte wie Estimatoren und Datenspeicher zur Verfügung. Darüber hinaus profitieren Sie von Azure-SLAs und Kundensupport für allgemein verfügbare Versionen.
Azure Machine Learning Service bietet zudem neue Funktionen wie automatisiertes maschinelles Lernen, Hyperparameteroptimierung und ML-Pipelines, die bei den meisten umfangreichen KI-Workloads hilfreich sind. Dank der Möglichkeit, ein trainiertes Modell ohne Wechsel zu einem separaten Dienst bereitzustellen, können Sie die Data Science-Schleife von der Datenaufbereitung (mit dem Datenaufbereitungs-SDK) bis hin zur Operationalisierung und Modellüberwachung abwickeln.
Starten der Migration
Um Unterbrechungen Ihrer Anwendungen zu vermeiden und von den neuesten Features zu profitieren, führen Sie vor dem 31. März 2019 folgende Schritte aus:
Erstellen Sie einen Azure Machine Learning Service-Arbeitsbereich, um loszulegen:
Installieren Sie das Azure Machine Learning SDK und das SDK für die Datenaufbereitung.
Richten Sie eine Instanz von Azure Machine Learning Compute für das Trainieren von Modellen ein.
Aktualisieren Sie Ihre Skripts, sodass diese Azure Machine Learning Compute verwenden. Die folgenden Abschnitte zeigen, wie allgemeiner für Batch KI verwendeter Code mit dem Code für Azure Machine Learning zusammenhängt.
Erstellen von Arbeitsbereichen
Das Konzept der Initialisierung eines Arbeitsbereichs mithilfe einer Datei vom Typ „configuration.json“ in Azure Batch KI ähnelt der Verwendung einer Konfigurationsdatei in Azure Machine Learning Service.
Vorgehensweise für Batch KI:
sys.path.append('../../..')
import utilities as utils
cfg = utils.config.Configuration('../../configuration.json')
client = utils.config.create_batchai_client(cfg)
utils.config.create_resource_group(cfg)
_ = client.workspaces.create(cfg.resource_group, cfg.workspace, cfg.location).result()
Vorgehensweise für Azure Machine Learning Service:
from azureml.core.workspace import Workspace
ws = Workspace.from_config()
print('Workspace name: ' + ws.name,
'Azure region: ' + ws.location,
'Subscription id: ' + ws.subscription_id,
'Resource group: ' + ws.resource_group, sep = '\n')
Sie können einen Arbeitsbereich auch direkt erstellen, indem Sie die Konfigurationsparameter angeben:
from azureml.core import Workspace
# Create the workspace using the specified parameters
ws = Workspace.create(name = workspace_name,
subscription_id = subscription_id,
resource_group = resource_group,
location = workspace_region,
create_resource_group = True,
exist_ok = True)
ws.get_details()
# write the details of the workspace to a configuration file to the notebook library
ws.write_config()
Weitere Informationen zur Klasse für den Azure Machine Learning-Arbeitsbereich finden Sie in der SDK-Referenzdokumentation.
Erstellen von Computeclustern
Azure Machine Learning unterstützt mehrere Computeziele. Einige davon werden durch den Dienst verwaltet, andere können an Ihren Arbeitsbereich angefügt werden (beispielsweise ein HDInsight-Cluster oder ein virtueller Remotecomputer). Weitere Informationen zu verschiedenen Computezielen finden Sie hier. Das Konzept der Erstellung eines Azure Batch KI-Computeclusters entspricht der Erstellung eines AmlCompute-Clusters in Azure Machine Learning Service. Bei der Amlcompute-Erstellung wird eine Computekonfiguration verwendet, was mit der Übergabe von Parametern in Azure Batch KI vergleichbar ist. Hinweis: Für den AmlCompute-Cluster ist die automatische Skalierung standardmäßig aktiviert. In Azure Batch KI ist sie standardmäßig deaktiviert.
Vorgehensweise für Batch KI:
nodes_count = 2
cluster_name = 'nc6'
parameters = models.ClusterCreateParameters(
vm_size='STANDARD_NC6',
scale_settings=models.ScaleSettings(
manual=models.ManualScaleSettings(target_node_count=nodes_count)
),
user_account_settings=models.UserAccountSettings(
admin_user_name=cfg.admin,
admin_user_password=cfg.admin_password or None,
admin_user_ssh_public_key=cfg.admin_ssh_key or None,
)
)
_ = client.clusters.create(cfg.resource_group, cfg.workspace, cluster_name, parameters).result()
Vorgehensweise für Azure Machine Learning Service:
from azureml.core.compute import ComputeTarget, AmlCompute
from azureml.core.compute_target import ComputeTargetException
# Choose a name for your CPU cluster
gpu_cluster_name = "nc6"
# Verify that cluster does not exist already
try:
gpu_cluster = ComputeTarget(workspace=ws, name=gpu_cluster_name)
print('Found existing cluster, use it.')
except ComputeTargetException:
compute_config = AmlCompute.provisioning_configuration(vm_size='STANDARD_NC6',
vm_priority='lowpriority',
min_nodes=1,
max_nodes=2,
idle_seconds_before_scaledown='300',
vnet_resourcegroup_name='<my-resource-group>',
vnet_name='<my-vnet-name>',
subnet_name='<my-subnet-name>')
gpu_cluster = ComputeTarget.create(ws, gpu_cluster_name, compute_config)
gpu_cluster.wait_for_completion(show_output=True)
Weitere Informationen zur AMLCompute-Klasse von AML finden Sie in der SDK-Referenzdokumentation. In der obigen Konfiguration sind nur die Angaben „vm_size“ und „max_nodes“ obligatorisch. Die übrigen Eigenschaften (etwa die VNETs) dienen lediglich zur erweiterten Clustereinrichtung.
Überwachen des Status Ihres Clusters
Dies ist in Azure Machine Learning Service einfacher, wie hier zu sehen:
Vorgehensweise für Batch KI:
cluster = client.clusters.get(cfg.resource_group, cfg.workspace, cluster_name)
utils.cluster.print_cluster_status(cluster)
Vorgehensweise für Azure Machine Learning Service:
gpu_cluster.get_status().serialize()
Abrufen eines Verweises auf ein Speicherkonto
Das Konzept eines Datenspeichers (etwa ein Blob) wird in Azure Machine Learning Service mithilfe des DataStore-Objekts vereinfacht. Standardmäßig erstellt Ihr Azure Machine Learning Service-Arbeitsbereich ein Speicherkonto. Im Rahmen der Arbeitsbereichserstellung können Sie jedoch auch Ihren eigenen Speicher anfügen.
Vorgehensweise für Batch KI:
azure_blob_container_name = 'batchaisample'
blob_service = BlockBlobService(cfg.storage_account_name, cfg.storage_account_key)
blob_service.create_container(azure_blob_container_name, fail_on_exist=False)
Vorgehensweise für Azure Machine Learning Service:
ds = ws.get_default_datastore()
print(ds.datastore_type, ds.account_name, ds.container_name)
Weitere Informationen zum Registrieren zusätzlicher Speicherkonten sowie zum Abrufen eines Verweises auf einen anderen registrierten Datenspeicher finden Sie in der Dokumentation für Azure Machine Learning Service.
Herunterladen und Hochladen von Daten
Bei beiden Diensten lassen sich die Daten mithilfe des obigen Datenspeicherverweises problemlos in das Speicherkonto hochladen. Für Azure Batch KI stellen wir auch das Trainingsskript als Teil der Dateifreigabe bereit. Sie werden jedoch sehen, wie Sie es im Fall von Azure Machine Learning Service als Teil Ihrer Auftragskonfiguration angeben können.
Vorgehensweise für Batch KI:
mnist_dataset_directory = 'mnist_dataset'
utils.dataset.download_and_upload_mnist_dataset_to_blob(
blob_service, azure_blob_container_name, mnist_dataset_directory)
script_directory = 'tensorflow_samples'
script_to_deploy = 'mnist_replica.py'
blob_service.create_blob_from_path(azure_blob_container_name,
script_directory + '/' + script_to_deploy,
script_to_deploy)
Vorgehensweise für Azure Machine Learning Service:
import os
import urllib
os.makedirs('./data', exist_ok=True)
download_url = 'https://s3.amazonaws.com/img-datasets/mnist.npz'
urllib.request.urlretrieve(download_url, filename='data/mnist.npz')
ds.upload(src_dir='data', target_path='mnist_dataset', overwrite=True, show_progress=True)
path_on_datastore = ' mnist_dataset/mnist.npz' ds_data = ds.path(path_on_datastore) print(ds_data)
Erstellen von Experimenten
Wie bereits erwähnt gleicht das Experimentkonzept von Azure Machine Learning Service dem Konzept in Azure Batch KI. Jedes Experiment kann einzelne Ausführungen umfassen, was mit Aufträgen in Azure Batch KI vergleichbar ist. In Azure Machine Learning Service ist außerdem eine Hierarchie mit übergeordneten und untergeordneten Ausführungen möglich.
Vorgehensweise für Batch KI:
experiment_name = 'tensorflow_experiment'
experiment = client.experiments.create(cfg.resource_group, cfg.workspace, experiment_name).result()
Vorgehensweise für Azure Machine Learning Service:
from azureml.core import Experiment
experiment_name = 'tensorflow_experiment'
experiment = Experiment(ws, name=experiment_name)
Übermitteln von Aufträgen
Nach der Experimenterstellung haben Sie mehrere Möglichkeiten, um eine Ausführung zu übermitteln. In diesem Beispiel möchten wir ein Deep Learning-Modell mit TensorFlow erstellen und dabei einen Azure Machine Learning Service-Estimator verwenden. Ein Estimator ist einfach eine Wrapperfunktion für die zugrunde liegende Ausführungskonfiguration und dient dazu, die Übermittlung von Ausführungen zu vereinfachen. Er wird derzeit nur für Pytorch und TensorFlow unterstützt. Das Datenspeicherkonzept vereinfacht zudem die Angabe der Einbindungspfade.
Vorgehensweise für Batch KI:
azure_file_share = 'afs'
azure_blob = 'bfs'
args_fmt = '--job_name={0} --num_gpus=1 --train_steps 10000 --checkpoint_dir=$AZ_BATCHAI_OUTPUT_MODEL --log_dir=$AZ_BATCHAI_OUTPUT_TENSORBOARD --data_dir=$AZ_BATCHAI_INPUT_DATASET --ps_hosts=$AZ_BATCHAI_PS_HOSTS --worker_hosts=$AZ_BATCHAI_WORKER_HOSTS --task_index=$AZ_BATCHAI_TASK_INDEX'
parameters = models.JobCreateParameters(
cluster=models.ResourceId(id=cluster.id),
node_count=2,
input_directories=[
models.InputDirectory(
id='SCRIPT',
path='$AZ_BATCHAI_JOB_MOUNT_ROOT/{0}/{1}'.format(azure_blob, script_directory)),
models.InputDirectory(
id='DATASET',
path='$AZ_BATCHAI_JOB_MOUNT_ROOT/{0}/{1}'.format(azure_blob, mnist_dataset_directory))],
std_out_err_path_prefix='$AZ_BATCHAI_JOB_MOUNT_ROOT/{0}'.format(azure_file_share),
output_directories=[
models.OutputDirectory(
id='MODEL',
path_prefix='$AZ_BATCHAI_JOB_MOUNT_ROOT/{0}'.format(azure_file_share),
path_suffix='Models'),
models.OutputDirectory(
id='TENSORBOARD',
path_prefix='$AZ_BATCHAI_JOB_MOUNT_ROOT/{0}'.format(azure_file_share),
path_suffix='Logs')
],
mount_volumes=models.MountVolumes(
azure_file_shares=[
models.AzureFileShareReference(
account_name=cfg.storage_account_name,
credentials=models.AzureStorageCredentialsInfo(
account_key=cfg.storage_account_key),
azure_file_url='https://{0}.file.core.windows.net/{1}'.format(
cfg.storage_account_name, azure_file_share_name),
relative_mount_path=azure_file_share)
],
azure_blob_file_systems=[
models.AzureBlobFileSystemReference(
account_name=cfg.storage_account_name,
credentials=models.AzureStorageCredentialsInfo(
account_key=cfg.storage_account_key),
container_name=azure_blob_container_name,
relative_mount_path=azure_blob)
]
),
container_settings=models.ContainerSettings(
image_source_registry=models.ImageSourceRegistry(image='tensorflow/tensorflow:1.8.0-gpu')),
tensor_flow_settings=models.TensorFlowSettings(
parameter_server_count=1,
worker_count=nodes_count,
python_script_file_path='$AZ_BATCHAI_INPUT_SCRIPT/'+ script_to_deploy,
master_command_line_args=args_fmt.format('worker'),
worker_command_line_args=args_fmt.format('worker'),
parameter_server_command_line_args=args_fmt.format('ps'),
)
)
In Azure Batch KI wird der eigentliche Auftrag im Rahmen der Erstellungsfunktion übermittelt.
job_name = datetime.utcnow().strftime('tf_%m_%d_%Y_%H%M%S')
job = client.jobs.create(cfg.resource_group, cfg.workspace, experiment_name, job_name, parameters).result()
print('Created Job {0} in Experiment {1}'.format(job.name, experiment.name))
Umfassende Informationen zu diesem Trainingscodeausschnitt (einschließlich der Datei „mnist_replica.py“, die weiter oben in die Dateifreigabe hochgeladen wurde) finden Sie im GitHub-Repository mit dem Azure Batch KI-Beispielnotebook.
Vorgehensweise für Azure Machine Learning Service:
from azureml.train.dnn import TensorFlow
script_params={
'--num_gpus': 1,
'--train_steps': 500,
'--input_data': ds_data.as_mount()
}
estimator = TensorFlow(source_directory=project_folder,
compute_target=gpu_cluster,
script_params=script_params,
entry_script='tf_mnist_replica.py',
node_count=2,
worker_count=2,
parameter_server_count=1,
distributed_backend='ps',
use_gpu=True)
Umfassende Informationen zu diesem Trainingscodeausschnitt (einschließlich der Datei „tf_mnist_replica.py“) finden Sie im GitHub-Repository mit dem Azure Machine Learning Service-Beispielnotebook. Der Datenspeicher selbst kann entweder in die einzelnen Knoten eingebunden werden, oder die Trainingsdaten können direkt auf den Knoten heruntergeladen werden. Ausführlichere Informationen zu Datenspeicherverweisen in Ihrem Estimator finden Sie in der Dokumentation für Azure Machine Learning Service.
Eine Ausführung in Azure Machine Learning Service wird mithilfe der Übermittlungsfunktion übermittelt.
run = experiment.submit(estimator)
print(run)
Eine weitere Möglichkeit zum Angeben von Parametern für Ihre Ausführung ist die Verwendung einer Ausführungskonfiguration. Dies ist insbesondere hilfreich, wenn Sie eine benutzerdefinierte Trainingsumgebung definieren möchten. Weitere Informationen finden Sie in diesem AmlCompute-Beispielnotebook.
Überwachen von Ausführungen
Nach der Übermittlung einer Ausführung können Sie entweder warten, bis sie abgeschlossen ist, oder sie in Azure Machine Learning Service mithilfe praktischer Jupyter-Widgets überwachen, die Sie direkt in Ihrem Code aufrufen können. Darüber hinaus können Sie auch den Kontext einer beliebigen vorherigen Ausführung abrufen, indem Sie die verschiedenen Experimente in einem Arbeitsbereich und die einzelnen Ausführungen innerhalb der einzelnen Experimente durchlaufen.
Vorgehensweise für Batch KI:
utils.job.wait_for_job_completion(client, cfg.resource_group, cfg.workspace,
experiment_name, job_name, cluster_name, 'stdouterr', 'stdout-wk-0.txt')
files = client.jobs.list_output_files(cfg.resource_group, cfg.workspace, experiment_name, job_name,
models.JobsListOutputFilesOptions(outputdirectoryid='stdouterr'))
for f in list(files):
print(f.name, f.download_url or 'directory')
Vorgehensweise für Azure Machine Learning Service:
run.wait_for_completion(show_output=True)
from azureml.widgets import RunDetails
RunDetails(run).show()
Hier sehen Sie eine Momentaufnahme, wie das Widget in Ihr Notizbuch geladen wird, um Ihre Protokolle in Echtzeit anzuzeigen: 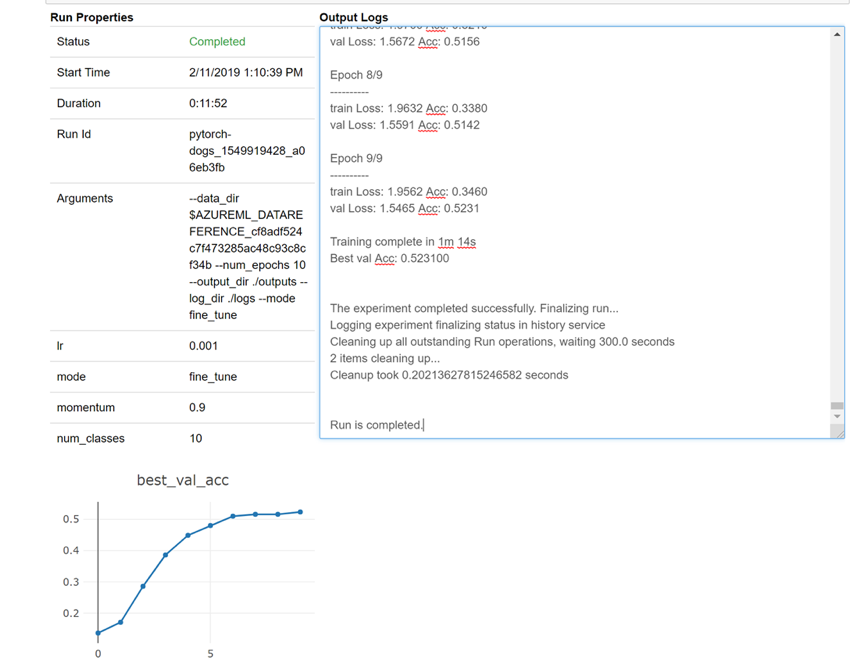
Bearbeiten von Clustern
Das Löschen eines Clusters ist ganz einfach. Mit Azure Machine Learning Service können Sie zudem einen Cluster über das Notebook aktualisieren, um ihn auf eine höhere Knotenanzahl zu skalieren, oder die Wartezeit erhöhen, nach der der Cluster im Leerlauf herunterskaliert wird. Die VM-Größe des Clusters kann dagegen nicht geändert werden, da hierzu letztendlich eine neue Bereitstellung am Back-End erforderlich wäre.
Vorgehensweise für Batch KI:
_ = client.clusters.delete(cfg.resource_group, cfg.workspace, cluster_name)
Vorgehensweise für Azure Machine Learning Service:
gpu_cluster.delete()
gpu_cluster.update(min_nodes=2, max_nodes=4, idle_seconds_before_scaledown=600)
Support
Batch KI wird am 31. März eingestellt und blockiert bereits die Registrierung neuer Abonnements beim Dienst, es sei denn, es wird zugelassen, indem eine Ausnahme über den Support ausgelöst wird. Sollten Sie Fragen oder Feedback in Verbindung mit der Migration zu Azure Machine Learning Service haben, wenden Sie sich an uns.
Azure Machine Learning Service ist ein allgemein verfügbarer Dienst. Er verfügt somit über eine verbindliche SLA und bietet eine Auswahl verschiedener Supportpläne.
Die Preise für die Verwendung der Azure-Infrastruktur über den Azure Batch KI-Dienst oder über den Azure Machine Learning-Dienst sollten nicht variieren, da wir in beiden Fällen nur den Preis für die zugrunde liegende Computeverarbeitung berechnen. Weitere Informationen finden Sie unter Azure-Preisrechner.
Die regionale Verfügbarkeit für die beiden Dienste können Sie im Azure-Portal anzeigen.
Nächste Schritte
Lesen Sie den Überblick über den Azure Machine Learning Service.
Konfigurieren Sie Computeziele zum Trainieren von Modellen mit dem Azure Machine Learning Service.
Lesen Sie die Azure-Roadmap, um mehr über Updates anderer Azure-Dienste zu erfahren.