Planen und Optimieren der Datenbankkapazität für Microsoft HPC Pack
Die Windows HPC-Clusterverwaltungsfeatures in Microsoft HPC Pack basieren auf mehreren Microsoft SQL Server-Datenbanken zur Unterstützung von Verwaltungs-, Auftragsplanungs-, Diagnose-, Berichterstellungs- und Überwachungsfunktionen. Wenn Sie HPC Pack auf einem Server installieren, um einen Kopfknoten zu erstellen, installiert das Standardsetup die Express Edition von Microsoft SQL Server (wenn keine andere Edition von SQL Server erkannt wird) und erstellt die erforderlichen Datenbanken auf dem Kopfknoten. Die Express Edition hat keine zusätzlichen Lizenzgebühren und ist enthalten, um eine out-of-box-Erfahrung für Machbarkeits- oder Entwicklungscluster sowie für kleine Produktionscluster bereitzustellen. Je nach Größe, Durchsatz und Anforderungen Ihres Clusters können Sie eine andere Edition von SQL Server auf dem Kopfknoten installieren oder die Datenbanken auf Remoteservern installieren. Die Informationen in diesem Dokument sollen Ihnen dabei helfen, die Datenbankkonfiguration und zusätzliche Optimierungsoptionen zu ermitteln, die für Ihren Cluster geeignet sind.
In diesem Thema:
Anwendbare Versionen von Microsoft HPC Pack und Microsoft SQL Server
Grundlegende Optionen für die Datenbankeinrichtung in Microsoft HPC Pack
Auswählen der richtigen Edition von SQL Server für Ihren Cluster-
Anwendbare Versionen von Microsoft HPC Pack und Microsoft SQL Server
Die Anleitungen in diesem Thema gelten für die versionen von HPC Pack und SQL Server, die in der folgenden Tabelle aufgeführt sind.
| Version von Microsoft HPC Pack | Clusterdatenbanken | Unterstützte Versionen von Microsoft SQL Server | Hinweise |
| HPC Pack 2016 | - HPCManagement - HPCScheduler - HPCReporting - HPCDiagnostics - HPCMonitoring |
- SQL Server 2014 und höher - Azure SQL-Datenbank |
– Die SQL Server Express-Version beschränkt jede Datenbank auf 10 GB. |
| HPC Pack 2012 R2 und HPC Pack 2012 | - HPCManagement - HPCScheduler - HPCReporting - HPCDiagnostics - HPCMonitoring |
- SQL Server 2008 R2 und höher - Azure SQL-Datenbank |
– Die SQL Server Express-Version beschränkt jede Datenbank auf 10 GB. – Azure SQL-Datenbank wird nur für HPC Pack 2012 R2 Update 3 Build 4.5.5194 oder höher unterstützt |
Die grundlegenden Optionen für die Datenbankeinrichtung in Microsoft HPC Pack
Dieser Abschnitt enthält Hintergrundinformationen zu drei grundlegenden Optionen für die Datenbankeinrichtung mit HPC Pack. Anleitungen zum Auswählen einer geeigneten Option für Ihre Bereitstellung finden Sie unter Auswählen der richtigen Edition von SQL Server für Ihren Cluster in diesem Thema.
SQL Server Express auf dem Kopfknoten
Dies ist die out-of-box-Erfahrung. Dies wird in der Regel für Machbarkeits- oder Entwicklungscluster oder für kleine Produktionscluster verwendet. Wie in der Tabelle im vorherigen Abschnitt dargestellt, ermöglicht SQL Server 2016 Express, SQL Server 2014 Express oder SQL Server 2012 Express datenbankgrößen bis zu 10 GB. Die grundlegenden Schritte für dieses Setup sind wie folgt:
Installieren Sie HPC Pack auf einem Server, um einen Kopfknoten zu erstellen.
Optional können Sie im Installations-Assistenten Datenbank- und Protokolldateispeicherorte angeben (oder Standardeinstellungen akzeptieren).
SQL Server Express wird automatisch installiert, und die HPC-Datenbanken werden automatisch erstellt.
Stellen Sie Knoten bereit.
SQL Server Standard auf dem Kopfknoten
Dies ist eine grundlegende Konfiguration für mittelgroße Cluster. Sql Server Standard Edition (oder eine andere Full Edition, nicht Kompakt) ermöglicht größere Datenbanken und zusätzliche Verwaltungsfähigkeiten, um mehr Knoten und höheren Auftragsdurchsatz zu unterstützen. Die grundlegenden Schritte für dieses Setup sind wie folgt:
Installieren Sie eine Version der SQL Server Standard Edition, die von Ihrer Version von HPC Pack auf dem Server unterstützt wird, die als Kopfknoten fungiert.
Installieren Sie HPC Pack auf dem Server, um einen Kopfknoten zu erstellen.
Optional können Sie im Installations-Assistenten Datenbank- und Protokolldateispeicherorte angeben (oder Standardeinstellungen akzeptieren).
Die HPC-Datenbanken werden automatisch erstellt.
Optimieren Sie optional Datenbanken nach Bedarf mithilfe von SQL Server Management Studio.
Stellen Sie Knoten bereit.
Remotedatenbanken (SQL Server Standard oder SQL Server Express)
Die Installation einer oder mehrerer HPC-Datenbanken auf einem Remoteserver ist eine empfohlene Konfiguration für größere Cluster oder für Cluster, die für hohe Verfügbarkeit des Kopfknotens konfiguriert sind. Weitere Informationen finden Sie unter Bereitstellen eines HPC Pack-Clusters mit Schritt-für-Schritt-Anleitungen für Remotedatenbanken. Bei Knoten mit hoher Verfügbarkeit würden Sie in der Regel die Standard edition von SQL Server verwenden, um die hohe Verfügbarkeit der Datenbanken zu unterstützen (die sich von der hohen Verfügbarkeit der HPC-Verwaltungsdienste unterscheiden). Weitere Informationen finden Sie im Leitfaden für erste Schritte für HPC Pack 2016. Die grundlegenden Schritte für dieses Setup sind wie folgt:
Installieren Sie eine Version der SQL Server Standard Edition, die von Ihrer Version von HPC Pack auf einem Remoteserver unterstützt wird.
Erstellen Sie die HPC-Remotedatenbanken manuell, und optimieren Sie sie bei Bedarf mithilfe von SQL Server Management Studio.
Führen Sie weitere Konfigurationsschritte auf dem Remoteserver aus, auf dem SQL Server ausgeführt wird, wie dies für Ihre Version von HPC Pack erforderlich ist.
Installieren Sie HPC Pack auf einem Server, um einen Kopfknoten zu erstellen.
Geben Sie im Installations-Assistenten die Verbindungsinformationen für die Remotedatenbanken an.
Stellen Sie Knoten bereit.
Auswählen der richtigen Edition von SQL Server für Ihren Cluster
Die folgenden allgemeinen Richtlinien können Ihnen dabei helfen, zu bestimmen, welche Edition von SQL Server für Ihren Cluster verwendet werden soll. Die Knoten- und Auftragsdurchsatznummern sind nur als allgemeine Richtlinien gedacht, da die Leistung je nach der Hardware und Topologie variiert, die Sie für den Cluster auswählen, und der Workload, die Ihr Cluster unterstützt.
Erwägen Sie die Verwendung der Standard Edition (oder einer anderen Vollständigen Edition, nicht komprimieren) von SQL Server, wenn eine der folgenden Bedingungen zutrifft:
Der Cluster verfügt über viele Knoten. Informationen wie Knoteneigenschaften, Konfigurationen, Metriken und Leistungsverlauf werden in den Datenbanken gespeichert. Größere Cluster erfordern mehr Platz in den Datenbanken. Als allgemeine Richtlinie reicht die Express Edition für bis zu 64 Knoten mit SQL Server Express 2012 oder bis zu 128 Knoten mit einer höheren Version von SQL Server Express aus.
Der Cluster unterstützt eine sehr hohe Auftragsdurchsatzrate , z. B. mehr als 10.000 Vorgänge oder Teilvorgänge pro Tag. Jeder Auftrag, jede Aufgabe und jeder Teilvorgang enthält Einträge in der Datenbank, um Eigenschaften und Zuordnungsinformationen und Verlauf zu speichern. Der Standardaufbewahrungszeitraum für diese Daten beträgt 5 Tage. Sie können den Aufbewahrungszeitraum anpassen, um Ihre Kapazitätsanforderungen zu verringern. Weitere Informationen finden Sie unter HPC-Datenaufbewahrungseinstellungen in diesem Thema.
Der Cluster ist für hohe Verfügbarkeit des Kopfknotens konfiguriert, und Sie möchten auch hohe Verfügbarkeit für SQL Server konfigurieren.
Sie müssen Auftrags- und Aufgabendaten in der HPCScheduler-Datenbank für einen längeren Zeitraum speichern und den von Ihrer Version von SQL Server Express auferlegten Datenbankgrenzwert überschreiten.
Sie verwenden die HPCReporting-Datenbank stark und verwenden möglicherweise die Datenerweiterungsfeatures für benutzerdefinierte Berichte. Informationen zum Deaktivieren der Berichtserweiterung und zum Verringern der Größenanforderungen für die Berichtsdatenbank finden Sie unter HPC-Datenaufbewahrungseinstellungen in diesem Thema.
Sie benötigen die zusätzliche Zuverlässigkeit, Leistung und Flexibilität der SQL Server Management Studio-Tools (einschließlich Unterstützung für Wartungspläne). Sql Server Standard Edition bietet beispielsweise die folgenden Features (unter anderem), die für HPC-Clusteradministratoren hilfreich sein können:
Unbegrenzte Datenbankgröße
Unterstützung für Konfigurationen mit hoher Verfügbarkeit
Unbegrenzte RAM-Nutzung für die Datenbankzwischenspeicherung
Hinweis
SQL Server Management Studio ist nicht automatisch in der Express-Edition von SQL Server enthalten. Sie können sie separat herunterladen, wenn Sie einstellungen für Ihre HPC-Datenbanken ändern möchten.
Sie planen eine große Bereitstellung von Windows Azure-Knoten , z. B. mehrere hundert Windows Azure-Rolleninstanzen oder mehr. Weitere Informationen zu großen Windows Azure-Knotenbereitstellungen finden Sie unter Bewährte Methoden für große Bereitstellungen von Windows Azure-Knoten mit Microsoft HPC Pack.
Bewährte Methoden für Konfiguration und Optimierung
Dieser Abschnitt enthält einige Richtlinien und bewährte Methoden zur Leistungsoptimierung der HPC-Datenbanken. Beispielkonfigurationseinstellungen für einen größeren Cluster werden in der nachstehenden Liste beschrieben. Diese Einstellungen unterscheiden sich in einigen Fällen erheblich von denen, die standardmäßig von HPC Pack konfiguriert wurden. Weitere Informationen zu diesen Optionen werden in den folgenden Abschnitten bereitgestellt.
Konfigurieren Sie auf einem Server mit drei Platten (physische Datenträger):
Das Betriebssystem auf einer dedizierten Platte.
Die Clusterdatenbanken auf einer dedizierten Platte.
Die Clusterdatenbankprotokolldateien auf einem dedizierten Platter.
Konfigurieren Sie in SQL Server Management Studio Folgendes:
HPCManagement-Datenbank: Anfangsgröße 20 GB, Steigerungsrate von 100%
HPCManagement-Datenbankprotokolle: Anfangsgröße 2 GB
HPCScheduler-Datenbank: Anfangsgröße 30 GB, Zuwachsrate 0%
Hinweis
Wenn Sie in einem großen Cluster unerwartetes Herunterfahren des HPC-Auftragsplanungs aufgrund der HPCScheduler-Datenbank verhindern möchten, die sich ihren Größenbeschränkungen nähert, empfehlen wir, die Einstellungen für die automatische Vergrößerung für diese Datenbank nicht zu konfigurieren.
HPCScheduler-Datenbankprotokolle: Anfangsgröße 2 GB
HPCReporting-Datenbank: Anfangsgröße 30 GB, Steigerungsrate von 100%
HPCReporting-Datenbankprotokolle: Anfangsgröße 2 GB
HPCDiagnostics-Datenbank und -Protokolle: Standardeinstellungen verwenden
HPCMonitoring-Datenbank: 1 GB, Zuwachsrate 10%
HPCMonitoring-Datenbankprotokolle: Standardeinstellungen verwenden
Hinweis
Die HPCMonitoring-Datenbank ist ab HPC Pack 2012 konfiguriert.
Konfigurieren Sie für Datenbanken, die auf dem Kopfknoten gehostet werden, in SQL Server Management Studio den Speicher für die Datenbank so, dass er ungefähr eine Hälfte des physischen Speichers auf dem Knoten ist. Konfigurieren Sie beispielsweise für einen Kopfknoten mit 16 GB physischem Arbeitsspeicher die Datenbankgrößen von 8-10 GB.
Legen Sie für Datenbanken, die auf dem Kopfknoten gehostet werden, in SQL Server Management Studio das Parallelisierungsflagge auf 1 fest (0 ist die Standardeinstellung).
SQL Server-Wiederherstellungsmodell und Speicherplatzanforderungen
Standardmäßig ist in der SQL Server Standard Edition das SQL Server-Wiederherstellungsmodell für jede Datenbank auf Fullfestgelegt. Dieses Modell kann dazu führen, dass die Protokolldateien aufgrund der erforderlichen manuellen Wartung sehr groß werden. Um Speicherplatz freizufordern und die Speicherplatzanforderungen klein zu halten, können Sie das Wiederherstellungsmodell für jede Datenbank in Simpleändern. Das von Ihnen ausgewählte Wiederherstellungsmodell hängt von ihren Wiederherstellungsanforderungen ab. Wenn Sie das Full-Modell verwenden, stellen Sie sicher, dass Sie genügend Speicherplatz für die Protokolldateien planen und die regelmäßigen Wartungsanforderungen beachten. Weitere Informationen finden Sie unter Recovery Model Overview.
Hinweis
Wenn Sie das Full-Modell auswählen, da die HPC-Datenbanken logisch konsistent bleiben müssen, müssen Sie möglicherweise spezielle Verfahren implementieren, um die Wiederherstellbarkeit dieser Datenbanken sicherzustellen. Weitere Informationen finden Sie unter Wiederherstellung verwandter Datenbanken, die markierte Transaktionenenthalten.
Anfängliche Größenanpassung und automatische Vergrößerung für Datenbanken und Protokolldateien
Die automatische Vergrößerung bedeutet, dass die Größe einer Datenbank oder Protokolldatei automatisch um einen vordefinierten Prozentsatz erhöht (wie durch den Parameter für die automatische Vergrößerung definiert). Während des automatischen Vergrößerungsprozesses wird die Datenbank gesperrt. Dies wirkt sich auf Clustervorgänge und Leistung aus und kann zu Deadlocks und Timeouts für Vorgänge führen. Durch die Voranpassung Ihrer Datenbanken können Sie diese Leistungsprobleme vermeiden, und indem Sie einen größeren Prozentsatz der automatischen Vergrößerung konfigurieren, verringern Sie die Häufigkeit der automatischen Vergrößerungsvorgänge. Eine große Anfangsdatei, die mit einer Einstellung für die automatische Vergrößerung verbunden ist, die 100% nähert, kann jedoch einen erheblichen Zeitaufwand erfordern, um die Datenbank zu vergrößern. Es ist wichtig, die Leistung Ihres Datenträgersubsystems zu verstehen, um Werte zu ermitteln, die den Zugriff auf die Datenbank für einen längeren Zeitraum nicht blockieren.
Jede Datenbank verfügt über eine zugeordnete Protokolldatei. Sie können auch die anfängliche Größe und die Einstellungen für die automatische Vergrößerung der Protokolldateien optimieren.
Die Standardkonfigurationen für die Datenbanken und Protokolldateien (unabhängig von der SQL Server-Edition) werden in der folgenden Tabelle angezeigt:
| HPC-Datenbank und Protokoll | Anfangsgröße (MB) | Automatisches Wachsen |
|---|---|---|
| HPCManagement | Datenbank: 1024 Protokoll: 128 |
Datenbank: 50% Protokoll: 50% |
| HPCScheduler | Datenbank: 256 Protokoll: 64 |
Datenbank: 10% Protokoll: 10% |
| HPCReporting | Datenbank: 128 Protokoll: 64 |
Datenbank: 10% Protokoll: 10% |
| HPCDiagnostics | Datenbank: 256 Protokoll: 64 |
Datenbank: 10% Protokoll: 10% |
| HPCMonitoring Hinweis: Die HPCMonitoring-Datenbank ist ab HPC Pack 2012 konfiguriert. | Datenbank: 256 Protokoll: 138 |
Datenbank: 10% Protokoll: 10% |
In der folgenden Tabelle werden beispielsweise die Anfängliche Größe und die Einstellungen für die automatische Vergrößerung aufgelistet, die für einen Cluster mit mehreren hundert oder mehr Knoten geeignet sein können.
Hinweis
Die Anfangsgröße in dieser Tabelle wird in Gigabyte (GB) ausgedrückt, nicht megabyte (MB) wie in der vorherigen Tabelle.
| HPC-Datenbank und Protokoll | Anfangsgröße (GB) | Automatisches Wachsen |
|---|---|---|
| HPCManagement | Datenbank: 20 Protokoll: 2 |
Datenbank: 100% Protokoll: 10% |
| HPCScheduler | Datenbank: 30 Protokoll: 2 |
Datenbank: 0% Protokoll: 10% |
| HPCReporting | Datenbank: 30 Protokoll: 2 |
Datenbank: 100% Protokoll: 10% |
| HPCDiagnostics | Datenbank: Standard Protokoll: Standard |
Datenbank: Standard Protokoll: Standard |
| HPCMonitoring | Datenbank: 1 Protokoll: Standard |
Datenbank: Standard Protokoll: Standard |
Der folgende Bildschirmausschnitt veranschaulicht die HPC-Datenbanken im SQL Server Management Studio und das Dialogfeld "Datenbankeigenschaften", mit dem Sie die anfängliche Größe und die Einstellungen für die automatische Vergrößerung für die Datenbanken konfigurieren können.
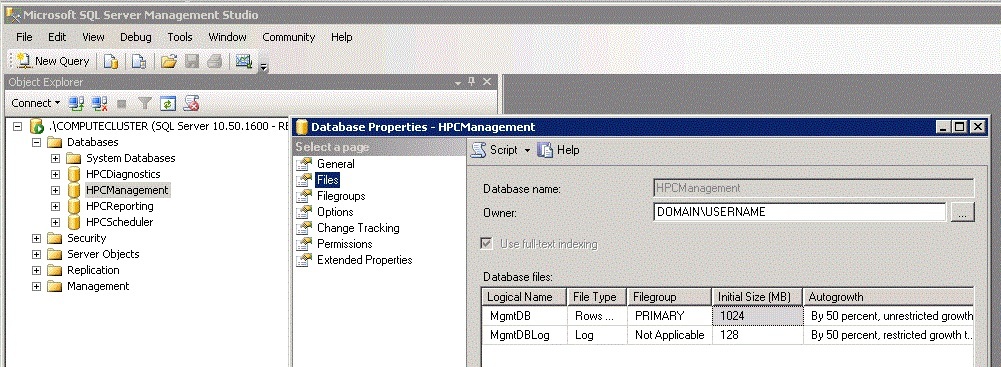
Speicherort der Datenbank- und Protokolldatei
Sie können die Leistung verbessern, indem Sie die Datenbanken auf einem separaten Datenträger (physischer Datenträger) als die Protokolldateien erstellen. Dies gilt für Datenbanken, die sich auf dem Kopfknoten und auf Remotedatenbanken befinden. Bei Datenbanken auf dem Kopfknoten können Sie die Speicherorte für Datenbank- und Protokolldateien während des Setups (im Installations-Assistenten) angeben. Platzieren Sie idealerweise die Systempartition, Daten und Protokolle auf separaten Platten.
Wenn die Berichterstellung stark verwendet wird, ziehen Sie in Betracht, die HPCReporting-Datenbank auf eine separate Platte zu verschieben.
Informationen zum Verschieben einer Datenbank finden Sie unter Verschieben einer Datenbank mithilfe von Trennen und Anfügen (Transact-SQL).
SQL Server-Instanzeinstellungen
Um die Speicher paging zu minimieren, stellen Sie sicher, dass Ihre SQL Server-Instanz über eine ausreichende Speicherzuweisung verfügt. Sie können den Speicher für Ihre SQL Server-Instanz über SQL Server Management Studio in den Servereigenschaften für die Instanz festlegen. Wenn sich Ihre Datenbanken beispielsweise auf einem Kopfknoten mit 16 GB Arbeitsspeicher befinden, sollten Sie 8-10 GB für SQL Server zuweisen.
Um den Kerninhalt des Kopfknotens zwischen SQL Server-Prozessen und HPC-Prozessen zu minimieren, legen Sie das Parallelisierungskennzeichnung für die SQL Server-Instanz auf 1 fest. Standardmäßig ist das Flag auf 0 festgelegt, was bedeutet, dass es keine Grenzen für die Anzahl der SQL-Kerne gibt. Durch Festlegen auf 1 beschränken Sie SQL Server-Prozesse auf 1 Kern.
HPC-Datenaufbewahrungseinstellungen
HPCManagement-Datenbank
Ab HPC Pack 2012 R2 Update 1 kann der Clusteradministrator die Anzahl von Tagen angeben, bevor der Dienst beginnt, Vorgangsprotokolldaten in der HPCManagement-Datenbank zu archivieren und die Anzahl der Tage, an denen die archivierten Vorgangsprotokolldaten aufbewahrt werden. Um beispielsweise das Vorgangsprotokollarchiv alle 7 Tage festzulegen und nach der Aufbewahrung für 180 Tage gelöscht zu werden, führen Sie HPC PowerShell als Administrator aus, und geben Sie das folgende Cmdlet ein:
Set-HpcClusterProperty –OperationArchive 7
Set-HpcClusterProperty –OperationRetention 180
HPCScheduler-Datenbank
Auftragseigenschaften, Zuordnungen und Verlauf werden in der HPCScheduler-Datenbank gespeichert. Standardmäßig werden Daten zu abgeschlossenen Aufträgen fünf Tage lang aufbewahrt. Der Aufbewahrungszeitraum für Auftragsdatensätze (TtlCompletedJobs) bestimmt, wie lange Daten für die folgenden Datensätze gespeichert werden sollen:
Daten zu abgeschlossenen Aufträgen (abgeschlossene, Fehlgeschlageneoder Abgebrochene) in der HPCScheduler-Datenbank.
SOA gemeinsame Daten, die in der Runtime$-Freigabe gespeichert sind.
Diagnosetestergebnisse und Daten in der HPCDiagnostics-Datenbank.
Nachrichten für abgeschlossene dauerhafte Sitzungen, die vom Brokerknoten mithilfe von MSMQ gespeichert werden.
Aufträge, die sich im Konfigurieren von Zustand befinden, werden nicht aus der Datenbank gelöscht. Die Aufträge müssen vom Auftragsbesitzer oder clusteradministrator (oder auf andere Weise abgeschlossen) abgebrochen werden und dann gemäß der Richtlinie für den Auftragsverlauf gelöscht werden.
Sie können diese Eigenschaft mithilfe des cmdlets Set-HpcClusterProperty konfigurieren. Um beispielsweise den Aufbewahrungszeitraum für Auftragsdatensätze auf drei Tage festzulegen, führen Sie HPC PowerShell als Administrator aus, und geben Sie das folgende Cmdlet ein:
Set-HpcClusterProperty –TtlCompletedJobs 3
Diese Eigenschaft kann auch im Auftragsverlauf Einstellungen des HPC-Auftragsplanungskonfigurationsdialogfelds konfiguriert werden.
HPCReporting-Datenbank
Historische Daten zum Cluster wie Clusterauslastung, Knotenverfügbarkeit und Auftragsstatistiken werden aggregiert und in der HPCReporting-Datenbank gespeichert. In der Datenbank werden auch Rohdaten zu Aufträgen gespeichert, die zur Unterstützung der benutzerdefinierten Berichterstellung verfügbar sind, wenn die Datenerweiterung aktiviert ist (standardmäßig aktiviert). Sie können beispielsweise benutzerdefinierte Laderückladungsberichte erstellen, die den von Ihrer Organisation verwendeten Lademethoden entsprechen. Informationen zur Verwendung der Rohdaten für benutzerdefinierte Berichte finden Sie in der Schritt-für-Schritt-Anleitung zur Berichterstellung.
In der folgenden Tabelle werden die Clustereigenschaften beschrieben, die die Datenerweiterung und Aufbewahrungszeiträume für die Rohdaten steuern. Diese Einstellungen wirken sich nicht auf die aggregierten Daten aus, die für die integrierten Berichte verwendet werden. Sie können die Werte der Eigenschaften mit dem Cmdlet Get-HPCClusterProperty anzeigen und die Werte mit dem Cmdlet Set-HpcClusterProperty festlegen. Um beispielsweise die Datenerweiterbarkeit zu deaktivieren, führen Sie HPC PowerShell als Administrator aus, und geben Sie das folgende Cmdlet ein:
Set-HpcClusterProperty –DataExtensibilityEnabled $false
| Eigenschaft | Beschreibung |
|---|---|
| DataExtensibilityEnabled- | Gibt an, ob der Cluster Informationen für benutzerdefinierte Berichte zu Aufträgen, Knoten und die Zuordnung von Aufträgen zu Knoten speichert. True gibt an, dass der Cluster Informationen für benutzerdefinierte Berichte zu Aufträgen, Knoten und die Zuordnung von Aufträgen zu Knoten speichert. False gibt an, dass der Cluster diese Informationen nicht speichert. Der Standardwert lautet "True". |
| DataExtensibilityTtl- | Gibt die Anzahl der Tage an, für die die HPCReporting-Datenbank alle Informationen zu Aufträgen und Knoten speichern soll, mit Ausnahme der Zuordnung von Aufträgen zu Knoten. Dieser Parameter weist den Standardwert 365 auf. |
| AllocationHistoryTtl | Gibt die Anzahl der Tage an, für die die HPCReporting-Datenbank Informationen über die Zuordnung von Aufträgen zu Knoten speichern soll. Dieser Parameter hat den Standardwert 5. |
| ReportingDBSize- | Enthält die aktuelle Größe der HPCReporting-Datenbank. Dieser Wert ist eine Zeichenfolge, die die Maßeinheiten für die Größe enthält. Dieser Parameter ist schreibgeschützt. Um diese Eigenschaft anzuzeigen, muss der Computer, auf dem HPC PowerShell ausgeführt wird, auf die HPCReporting-Datenbank zugreifen können. Weitere Informationen zum Aktivieren des Remotedatenbankzugriffs finden Sie unter Bereitstellen eines Clusters mit Schritt-für-Schritt-Anleitung für Remotedatenbanken. |
Wenn Sie die für die HPCReporting-Datenbank in Ihrem Cluster erforderliche Größe schätzen möchten, lesen Sie Schätzen der Größe der Berichtsdatenbank.
HPCDiagnostics-Datenbank
Informationen und Ergebnisse von Diagnosetestläufen werden in der HPCDiagnostics-Datenbank gespeichert. Der Aufbewahrungszeitraum für Auftragsdatensätze (TtlCompletedJobs) bestimmt, wie lange Daten zu abgeschlossenen Testläufen gespeichert werden sollen.
HPCMonitoring-Datenbank
Leistungsindikatorendaten, die vom HPC Monitoring Server Service und dem HPC Monitoring Client Service gesammelt und von Clusterknoten aggregiert werden, werden in der HPCMonitoring-Datenbank gespeichert.
Leistungsindikatordaten werden nach Minute, Stunde und Tag aggregiert. Der Datenaufbewahrungszeitraum für die Knotenleistungsindikatordaten wird durch die Clustereigenschaften in der folgenden Tabelle definiert. Sie können diese Eigenschaften mithilfe des Cmdlets Set-HpcClusterProperty konfigurieren.
| Eigenschaft | Beschreibung |
|---|---|
| MinuteCounterRetention | Gibt den Aufbewahrungszeitraum in Tagen für die Daten des Minutenleistungsindikators an. Der Standardwert ist 3 Tage. |
| HourCounterRetention | Gibt den Aufbewahrungszeitraum in Tagen für die Stundenleistungszählerdaten an. Der Standardwert ist 30 Tage. |
| DayCounterRetention | Gibt den Aufbewahrungszeitraum in Tagen für die Leistungsindikatordaten des Tages an. Der Standardwert ist 180 Tage. |
Sie können die für die HpcMonitoring-Datenbank benötigte Größe basierend auf der Anzahl der Knoten, der Anzahl der Leistungsindikatoren und dem Aufbewahrungszeitraum schätzen. Wenn Sie z. B. eine Standardeinstellung MinuteCounterRetention Zeitraum von 3 Tagen (4.320 Minuten) und 27 Leistungsindikatoren mit jedem Leistungswerteintrag verwenden, der ca. 40 Byte erfordert, erfordert jeder Knoten Folgendes:
4.320 x 27 x 40 = 4.665.600 Bytes oder ca. 5 MB.
Für einen Cluster mit 1000 Knoten wären ca. 5 GB Speicherplatz erforderlich.
Wartungsrichtlinien
Ein typischer SQL Server-Wartungsplan umfasst Folgendes:
Datenbanksicherung
Konsistenzprüfungen
Index-Defragmentierung
Sie können die Indexfragmentierung überwachen, indem Sie sql Server Management Studio und Defragmentindizes verwenden, wenn dies über einen Wartungsplan erforderlich ist.
Es wird in der Regel empfohlen, Ihre Indizes nach 250.000 Aufträgen oder einem Monat (je nachdem, welcher Wert kürzer ist) neu zu erstellen, wenn nicht häufiger. Wie oft Sie Konsistenzprüfungen und Sicherungen durchführen, hängt von Ihren Geschäftlichen Anforderungen ab. Es wird empfohlen, Wartung nur dann auszuführen, wenn es wenig zu keiner Benutzeraktivität gibt, vorzugsweise während einer geplanten Ausfallzeit (insbesondere für größere Cluster), da sich der Auftragsdurchsatz und die Benutzererfahrung erheblich auswirken können.
Informationen zu bewährten Methoden zur Datenbankwartung finden Sie unter Top-Tipps für effektive Datenbankwartung.
Hinweis
Wichtige Informationen zum Sichern und Wiederherstellen der HPC-Datenbanken finden Sie unter Sichern und Wiederherstellen in Windows HPC Server.