TripPin Teil 6 - Schema
Dieser mehrteilige Lehrgang behandelt die Erstellung einer neuen Datenquellenerweiterung für Power Query. Der Lehrgang sollte nacheinander durchgeführt werden - jede Lektion baut auf dem in den vorangegangenen Lektionen erstellten Connector auf und fügt dem Connector schrittweise neue Funktionen hinzu.
In dieser Lektion lernen Sie Folgendes:
- Definieren Sie ein festes Schema für eine REST-API
- Datentypen für Spalten dynamisch festlegen
- Erzwingen Sie eine Tabellenstruktur, um Transformationsfehler aufgrund fehlender Spalten zu vermeiden
- Spalten aus der Ergebnismenge ausblenden
Einer der großen Vorteile eines OData-Dienstes gegenüber einer Standard-REST-API ist seine $metadata-Definition. Das Dokument $metadata beschreibt die in diesem Dienst gefundenen Daten, einschließlich des Schemas für alle Entitäten (Tabellen) und Felder (Spalten). Die Funktion OData.Feed verwendet diese Schemadefinition, um automatisch Datentypinformationen festzulegen. Anstatt alle Text- und Zahlenfelder zu erhalten (wie bei Json.Document), erhalten die Endbenutzer Datumsangaben, ganze Zahlen, Zeitangaben usw., was die Benutzerfreundlichkeit insgesamt verbessert.
Viele REST-APIs verfügen nicht über eine Möglichkeit, ihr Schema programmatisch zu bestimmen. In diesen Fällen müssen Sie Schemadefinitionen in Ihren Connector aufnehmen. In dieser Lektion werden Sie ein einfaches, fest kodiertes Schema für jede Ihrer Tabellen definieren und das Schema für die Daten, die Sie aus dem Dienst lesen, erzwingen.
Hinweis
Der hier beschriebene Ansatz sollte für viele REST-Dienste funktionieren. Zukünftige Lektionen werden auf diesem Ansatz aufbauen, indem sie rekursiv Schemata für strukturierte Spalten (Datensatz, Liste, Tabelle) erzwingen und Beispielimplementierungen bereitstellen, die programmatisch eine Schematabelle aus CSDL- oder JSON Schema Dokumenten erzeugen können.
Insgesamt hat das Erzwingen eines Schemas für die von Ihrem Connector zurückgegebenen Daten mehrere Vorteile, z. B.:
- Einstellung der richtigen Datentypen
- Entfernen von Spalten, die den Endbenutzern nicht angezeigt werden müssen (z. B. interne IDs oder Statusinformationen)
- Sicherstellen, dass jede Seite der Daten die gleiche Form hat, indem alle Spalten hinzugefügt werden, die in einer Antwort fehlen könnten (eine übliche Methode für REST-APIs, um anzuzeigen, dass ein Feld null sein sollte)
Anzeigen des vorhandenen Schemas mit Table.Schema
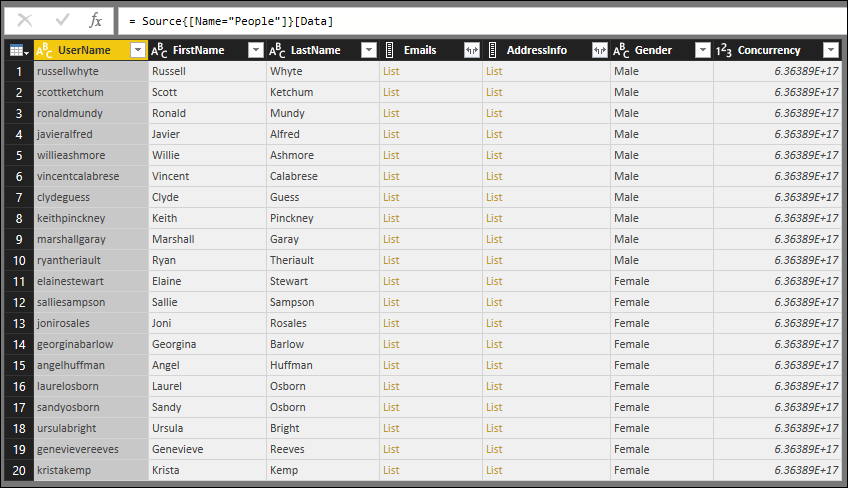
Der in der vorangegangenen Lektion erstellte Connector zeigt drei Tabellen des TripPin-Dienstes an:Airlines, Airports und People. Führen Sie die folgende Abfrage aus, um die Tabelle Airlines anzuzeigen:
let
source = TripPin.Contents(),
data = source{[Name="Airlines"]}[Data]
in
data
In den Ergebnissen sehen Sie vier Spalten, die zurückgegeben werden:
- @odata.id
- @odata.editLink
- AirlineCode
- Name
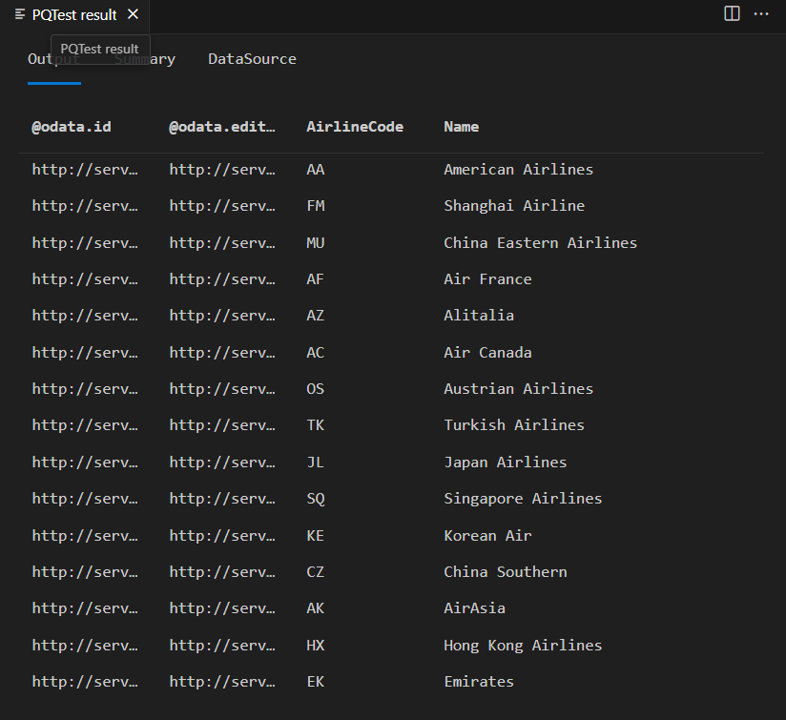
Die Spalten "@odata.*" sind Teil des OData-Protokolls und nichts, was Sie den Endbenutzern Ihres Connectors zeigen wollen oder müssen. AirlineCode und Name sind die beiden Spalten, die Sie beibehalten sollten. Wenn Sie sich das Schema der Tabelle ansehen (mit der praktischen Funktion Table.Schema ), können Sie sehen, dass alle Spalten der Tabelle den Datentyp Any.Typehaben.
let
source = TripPin.Contents(),
data = source{[Name="Airlines"]}[Data]
in
Table.Schema(data)
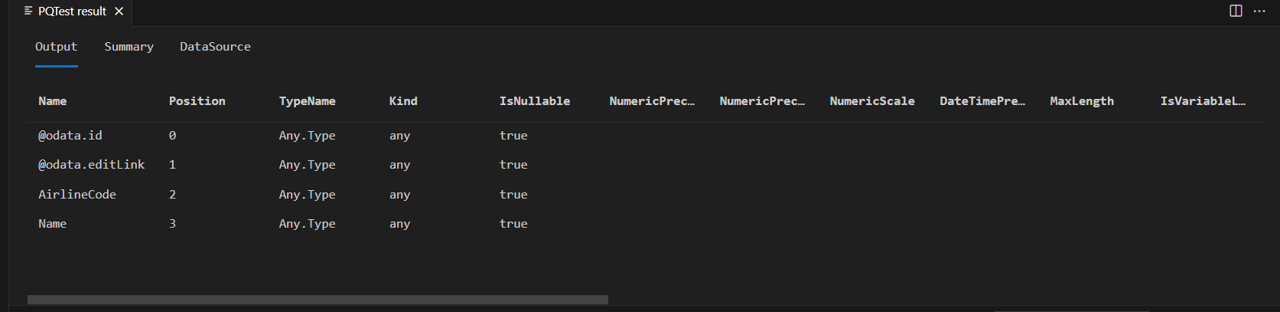
Table.Schema gibt viele Metadaten über die Spalten in einer Tabelle zurück, einschließlich Namen, Positionen, Typinformationen und viele erweiterte Eigenschaften, wie Precision, Scale und MaxLength.
In künftigen Lektionen werden Entwurfsmuster für die Einstellung dieser erweiterten Eigenschaften vorgestellt, aber im Moment müssen Sie sich nur um den zugeschriebenen Typ (TypeName), den primitiven Typ (Kind) und die Frage kümmern, ob der Spaltenwert null sein könnte (IsNullable).
Definieren einer einfachen Schematabelle
Ihre Schematabelle wird aus zwei Spalten bestehen:
| Spalte | Details |
|---|---|
| Name | Der Name der Spalte. Dieser muss mit dem Namen in den vom Dienst zurückgegebenen Ergebnissen übereinstimmen. |
| type | Der M-Datentyp, den Sie einstellen werden. Die kann ein primitiver Typ (text, number, datetime usw.) oder ein zugeschriebener Typ (Int64.Type, Currency.Type usw.) sein. |
Die fest kodierte Schematabelle für die Tabelle Airlines setzt ihre Spalten AirlineCode und Name auf textund sieht wie folgt aus:
Airlines = #table({"Name", "Type"}, {
{"AirlineCode", type text},
{"Name", type text}
});
Die Tabelle Airports hat vier Felder, die Sie beibehalten wollen (darunter eines vom Typ record):
Airports = #table({"Name", "Type"}, {
{"IcaoCode", type text},
{"Name", type text},
{"IataCode", type text},
{"Location", type record}
});
Schließlich hat die Tabelle People sieben Felder, einschließlich Listen (Emails, AddressInfo), einer Nullable-Spalte (Gender) und einer Spalte mit einem zugeschriebenen Typ (Concurrency).
People = #table({"Name", "Type"}, {
{"UserName", type text},
{"FirstName", type text},
{"LastName", type text},
{"Emails", type list},
{"AddressInfo", type list},
{"Gender", type nullable text},
{"Concurrency", Int64.Type}
})
Die Hilfsfunktion SchemaTransformTable
Die unten beschriebene Hilfsfunktion SchemaTransformTable wird verwendet, um Schemata für Ihre Daten zu erzwingen. Hierfür werden die folgenden Parameter verwendet:
| Parameter | Typ | Beschreibung |
|---|---|---|
| table | table | Die Datentabelle, für die Sie Ihr Schema erzwingen wollen. |
| Schema | table | Die Schematabelle, aus der die Spalteninformationen gelesen werden sollen, mit dem folgenden Typ: type table [Name = text, Type = type]. |
| enforceSchema | Zahl | (optional) Eine Aufzählung, die das Verhalten der Funktion steuert. Der Standardwert ( EnforceSchema.Strict = 1) stellt sicher, dass die Ausgabetabelle mit der angegebenen Schematabelle übereinstimmt, indem alle fehlenden Spalten hinzugefügt und zusätzliche Spalten entfernt werden. Die Option EnforceSchema.IgnoreExtraColumns = 2 kann verwendet werden, um zusätzliche Spalten im Ergebnis zu erhalten. Wenn EnforceSchema.IgnoreMissingColumns = 3 verwendet wird, werden sowohl fehlende als auch zusätzliche Spalten ignoriert. |
Die Logik für diese Funktion sieht in etwa so aus:
- Stellen Sie fest, ob in der Quelltabelle Spalten fehlen.
- Stellen Sie fest, ob es zusätzliche Spalten gibt.
- Strukturierte Spalten (vom Typ
list,recordundtable) und Spalten, die auftype anygesetzt sind, werden ignoriert. - Verwenden Sie Table.TransformColumnTypes, um jeden Spaltentyp festzulegen.
- Spalten in der Reihenfolge neu anordnen, in der sie in der Schematabelle erscheinen.
- Setzen Sie den Typ in der Tabelle selbst mit Value.ReplaceType.
Hinweis
Der letzte Schritt zum Festlegen des Tabellentyps macht es überflüssig, dass die Power Query-Benutzeroberfläche bei der Anzeige der Ergebnisse im Abfrage-Editor Typinformationen ableitet. Dies beseitigt das Problem der doppelten Anfrage, das Sie am Ende des vorherigen Tutorialsgesehen haben.
Der folgende Hilfscode kann kopiert und in Ihre Erweiterung eingefügt werden:
EnforceSchema.Strict = 1; // Add any missing columns, remove extra columns, set table type
EnforceSchema.IgnoreExtraColumns = 2; // Add missing columns, do not remove extra columns
EnforceSchema.IgnoreMissingColumns = 3; // Do not add or remove columns
SchemaTransformTable = (table as table, schema as table, optional enforceSchema as number) as table =>
let
// Default to EnforceSchema.Strict
_enforceSchema = if (enforceSchema <> null) then enforceSchema else EnforceSchema.Strict,
// Applies type transforms to a given table
EnforceTypes = (table as table, schema as table) as table =>
let
map = (t) => if Type.Is(t, type list) or Type.Is(t, type record) or t = type any then null else t,
mapped = Table.TransformColumns(schema, {"Type", map}),
omitted = Table.SelectRows(mapped, each [Type] <> null),
existingColumns = Table.ColumnNames(table),
removeMissing = Table.SelectRows(omitted, each List.Contains(existingColumns, [Name])),
primativeTransforms = Table.ToRows(removeMissing),
changedPrimatives = Table.TransformColumnTypes(table, primativeTransforms)
in
changedPrimatives,
// Returns the table type for a given schema
SchemaToTableType = (schema as table) as type =>
let
toList = List.Transform(schema[Type], (t) => [Type=t, Optional=false]),
toRecord = Record.FromList(toList, schema[Name]),
toType = Type.ForRecord(toRecord, false)
in
type table (toType),
// Determine if we have extra/missing columns.
// The enforceSchema parameter determines what we do about them.
schemaNames = schema[Name],
foundNames = Table.ColumnNames(table),
addNames = List.RemoveItems(schemaNames, foundNames),
extraNames = List.RemoveItems(foundNames, schemaNames),
tmp = Text.NewGuid(),
added = Table.AddColumn(table, tmp, each []),
expanded = Table.ExpandRecordColumn(added, tmp, addNames),
result = if List.IsEmpty(addNames) then table else expanded,
fullList =
if (_enforceSchema = EnforceSchema.Strict) then
schemaNames
else if (_enforceSchema = EnforceSchema.IgnoreMissingColumns) then
foundNames
else
schemaNames & extraNames,
// Select the final list of columns.
// These will be ordered according to the schema table.
reordered = Table.SelectColumns(result, fullList, MissingField.Ignore),
enforcedTypes = EnforceTypes(reordered, schema),
withType = if (_enforceSchema = EnforceSchema.Strict) then Value.ReplaceType(enforcedTypes, SchemaToTableType(schema)) else enforcedTypes
in
withType;
Aktualisieren des TripPin-Connectors
Sie nehmen nun die folgenden Änderungen an Ihrem Connector vor, um den neuen Schemaerzwingungscode zu nutzen.
- Definieren Sie eine Master-Schema-Tabelle (
SchemaTable), die alle Ihre Schemadefinitionen enthält. - Aktualisieren Sie
TripPin.Feed,GetPageundGetAllPagesByNextLink, um einenschema-Parameter zu akzeptieren. - Setzen Sie Ihr Schema in
GetPagedurch. - Aktualisieren Sie Ihren Code für die Navigationstabellen, um jede Tabelle mit einem Aufruf einer neuen Funktion (
GetEntity) zu umschließen - so können Sie die Tabellendefinitionen in Zukunft flexibler bearbeiten.
Stammschema-Tabelle
Sie fassen nun Ihre Schemadefinitionen in einer einzigen Tabelle zusammen und fügen eine Hilfsfunktion (GetSchemaForEntity) hinzu, mit der Sie die Definition anhand eines Entitätsnamens nachschlagen können (zum Beispiel GetSchemaForEntity("Airlines")).
SchemaTable = #table({"Entity", "SchemaTable"}, {
{"Airlines", #table({"Name", "Type"}, {
{"AirlineCode", type text},
{"Name", type text}
})},
{"Airports", #table({"Name", "Type"}, {
{"IcaoCode", type text},
{"Name", type text},
{"IataCode", type text},
{"Location", type record}
})},
{"People", #table({"Name", "Type"}, {
{"UserName", type text},
{"FirstName", type text},
{"LastName", type text},
{"Emails", type list},
{"AddressInfo", type list},
{"Gender", type nullable text},
{"Concurrency", Int64.Type}
})}
});
GetSchemaForEntity = (entity as text) as table => try SchemaTable{[Entity=entity]}[SchemaTable] otherwise error "Couldn't find entity: '" & entity &"'";
Hinzufügen von Schemaunterstützung zu Datenfunktionen
Sie werden nun einen optionalen Parameter schema zu den Funktionen TripPin.Feed, GetPage und GetAllPagesByNextLink hinzufügen.
Auf diese Weise können Sie das Schema (bei Bedarf) an die Auslagerungsfunktionen weitergeben, wo es auf die Ergebnisse angewendet wird, die Sie vom Dienst zurückerhalten.
TripPin.Feed = (url as text, optional schema as table) as table => ...
GetPage = (url as text, optional schema as table) as table => ...
GetAllPagesByNextLink = (url as text, optional schema as table) as table => ...
Sie werden auch alle Aufrufe dieser Funktionen aktualisieren, um sicherzustellen, dass Sie das Schema korrekt weitergeben.
Durchsetzung des Schemas
Die eigentliche Durchsetzung des Schemas erfolgt in Ihrer GetPage-Funktion.
GetPage = (url as text, optional schema as table) as table =>
let
response = Web.Contents(url, [ Headers = DefaultRequestHeaders ]),
body = Json.Document(response),
nextLink = GetNextLink(body),
data = Table.FromRecords(body[value]),
// enforce the schema
withSchema = if (schema <> null) then SchemaTransformTable(data, schema) else data
in
withSchema meta [NextLink = nextLink];
Hinweis
Diese GetPage Implementierung verwendet Table.FromRecords, um die Liste der Datensätze in der JSON-Antwort in eine Tabelle zu konvertieren.
Ein großer Nachteil bei der Verwendung von Table.FromRecords ist, dass davon ausgegangen wird, dass alle Datensätze in der Liste den gleichen Satz von Feldern haben.
Dies funktioniert für den TripPin-Dienst, da die OData-Datensätze garantiert dieselben Felder enthalten, aber dies ist möglicherweise nicht bei allen REST-APIs der Fall.
Eine robustere Implementierung würde eine Kombination aus Table.FromList und Table.ExpandRecordColumnverwenden.
In späteren Tutorials wird die Implementierung dahingehend geändert, dass die Spaltenliste aus der Schematabelle abgerufen wird, um sicherzustellen, dass bei der Übersetzung von JSON nach M keine Spalten verloren gehen oder fehlen.
Hinzufügen der Funktion GetEntity
Die Funktion GetEntity wird Ihren Aufruf von TripPin.Feed umschließen.
Es wird eine Schemadefinition auf der Grundlage des Entitätsnamens nachschlagen und die vollständige Anfrage-URL erstellen.
GetEntity = (url as text, entity as text) as table =>
let
fullUrl = Uri.Combine(url, entity),
schemaTable = GetSchemaForEntity(entity),
result = TripPin.Feed(fullUrl, schemaTable)
in
result;
Sie aktualisieren dann Ihre TripPinNavTable Funktion, um GetEntityaufzurufen, anstatt alle Aufrufe inline zu machen.
Der Hauptvorteil besteht darin, dass Sie Ihren Code für die Entitätserstellung weiter ändern können, ohne die Logik der Navigationstabelle berühren zu müssen.
TripPinNavTable = (url as text) as table =>
let
entitiesAsTable = Table.FromList(RootEntities, Splitter.SplitByNothing()),
rename = Table.RenameColumns(entitiesAsTable, {{"Column1", "Name"}}),
// Add Data as a calculated column
withData = Table.AddColumn(rename, "Data", each GetEntity(url, [Name]), type table),
// Add ItemKind and ItemName as fixed text values
withItemKind = Table.AddColumn(withData, "ItemKind", each "Table", type text),
withItemName = Table.AddColumn(withItemKind, "ItemName", each "Table", type text),
// Indicate that the node should not be expandable
withIsLeaf = Table.AddColumn(withItemName, "IsLeaf", each true, type logical),
// Generate the nav table
navTable = Table.ToNavigationTable(withIsLeaf, {"Name"}, "Name", "Data", "ItemKind", "ItemName", "IsLeaf")
in
navTable;
Zusammenfügen des Gesamtbilds
Sobald alle Codeänderungen vorgenommen wurden, kompilieren Sie die Testabfrage, die Table.Schema für die Tabelle Airlines aufruft, und führen Sie sie erneut aus.
let
source = TripPin.Contents(),
data = source{[Name="Airlines"]}[Data]
in
Table.Schema(data)
Sie sehen nun, dass Ihre Tabelle Airlines nur die beiden Spalten hat, die Sie in ihrem Schema definiert haben:
Wenn Sie denselben Code mit der Tabelle "Personen" ausführen...
let
source = TripPin.Contents(),
data = source{[Name="People"]}[Data]
in
Table.Schema(data)
Sie werden sehen, dass die von Ihnen verwendete Art der Zuschreibung (Int64.Type) ebenfalls korrekt eingestellt wurde.
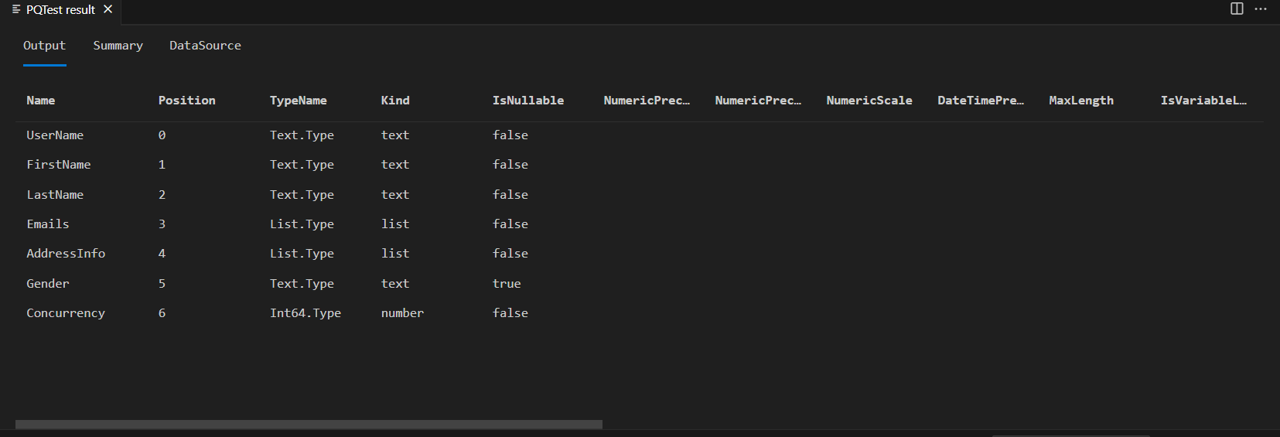
Wichtig ist, dass diese Implementierung von SchemaTransformTable die Typen der Spalten list und record nicht ändert, aber die Spalten Emails und AddressInfo sind weiterhin als listtypisiert. Das liegt daran, dass Json.Document JSON-Arrays korrekt auf M-Listen und JSON-Objekte auf M-Datensätze abbildet. Wenn Sie die Listen- oder Datensatzspalte in Power Query erweitern, werden Sie feststellen, dass alle erweiterten Spalten vom Typ any sind. Zukünftige Tutorials werden die Implementierung verbessern, um Typinformationen für verschachtelte komplexe Typen rekursiv zu setzen.
Zusammenfassung
Dieses Tutorial bietet eine Beispielimplementierung für die Durchsetzung eines Schemas für JSON-Daten, die von einem REST-Dienst zurückgegeben werden. Während in diesem Beispiel ein einfaches, fest kodiertes Schematabellenformat verwendet wird, könnte der Ansatz erweitert werden, indem eine Schematabellendefinition dynamisch aus einer anderen Quelle erstellt wird, z. B. aus einer JSON-Schemadatei oder einem von der Datenquelle bereitgestellten Metadatendienst/Endpunkt.
Neben der Änderung von Spaltentypen (und -werten) setzt Ihr Code auch die richtigen Typinformationen für die Tabelle selbst. Das Festlegen dieser Typinformationen wirkt sich positiv auf die Leistung aus, wenn sie innerhalb von Power Query ausgeführt werden, da die Benutzererfahrung immer versucht, Typinformationen abzuleiten, um dem Endbenutzer die richtigen UI-Warteschlangen anzuzeigen, und die Ableitungsaufrufe schließlich zusätzliche Aufrufe an die zugrunde liegenden Daten-APIs auslösen können.
Wenn Sie die Tabelle "Personen" mit dem TripPin-Connector aus der vorigen Lektionanzeigen, werden Sie feststellen, dass alle Spalten ein "type any"-Symbol haben (auch die Spalten, die Listen enthalten):
Wenn Sie dieselbe Abfrage mit dem TripPin-Connector aus dieser Lektion ausführen, werden Sie feststellen, dass die Typinformationen korrekt angezeigt werden.