Visualisieren und Interpretieren von Abfragediagnosen in Power BI
Einführung
Sobald Sie aufgezeichnet haben die Diagnosen, die Sie verwenden möchten, ist der nächste Schritt, dass Sie in der Lage sind, zu verstehen, was sie sagen.
Es ist hilfreich zu wissen, was die einzelnen Spalten im Abfragediagnoseschema bedeuten, was wir in diesem kurzen Lehrgang nicht wiederholen werden. Einen ausführlichen Bericht über die gibt es hier.
Im Allgemeinen ist es besser, bei der Erstellung von Visualisierungen die vollständige detaillierte Tabelle zu verwenden. Denn unabhängig davon, wie viele Zeilen es sind, geht es Ihnen wahrscheinlich um eine Art Darstellung der Zeit, die in den verschiedenen Ressourcen verbracht wurde, oder darum, wie die ursprüngliche Abfrage aussah.
Wie in unserem Artikel über die Aufzeichnung der Diagnosen erwähnt, arbeite ich mit den OData- und SQL-Ablaufverfolgungen für dieselbe Tabelle (oder fast dieselbe): die Tabelle Kunden von Northwind. Ich werde mich insbesondere auf häufige Anfragen unserer Kunden konzentrieren und auf eine der einfacher zu interpretierenden Gruppen von Spuren: die vollständige Aktualisierung des Datenmodells.
Erstellung der Visualisierungen
Wenn Sie Spuren durchgehen, gibt es viele Möglichkeiten, sie zu bewerten. In diesem Artikel werden wir uns auf eine zweigeteilte Visualisierung konzentrieren - eine, um die Details zu zeigen, die Sie interessieren, und die andere, um auf einfache Weise die zeitlichen Beiträge der verschiedenen Faktoren zu betrachten. Für die erste Visualisierung wird eine Tabelle verwendet. Sie können jedes beliebige Feld auswählen, aber die empfohlenen Felder sind für einen einfachen, umfassenden Überblick über die Vorgänge:
- Id
- Startzeit
- Abfrage
- Schritt
- Abfrage der Datenquelle
- Ausschließlich Dauer (%)
- Zeilenanzahl
- Kategorie
- Ist Benutzerabfrage
- Pfad
Für die zweite Visualisierung bietet sich die Verwendung eines gestapelten Säulendiagramms an. Für den Parameter „Axis“ können Sie „ID“ oder Step verwenden. Wenn wir uns das Refresh ansehen, weil es nichts mit den Schritten im Editor selbst zu tun hat, wollen wir uns wahrscheinlich nur 'Id' ansehen. Für den Parameter „Legend“ müssen Sie „Category“ oder „Operation“ wählen (abhängig von der gewünschten Granularität). Für „Value“ stellen Sie „Exclusive Duration“ ein (und stellen sicher, dass es sich nicht um % handelt, sodass Sie den Rohwert der Dauer erhalten). Legen Sie schließlich für die QuickInfo „Earliest Start Time“ fest.
Sobald Ihre Visualisierung erstellt ist, sortieren Sie bitte nach „Earliest Start Time“ absteigend, sodass Sie die Reihenfolge des Ablaufs sehen können.
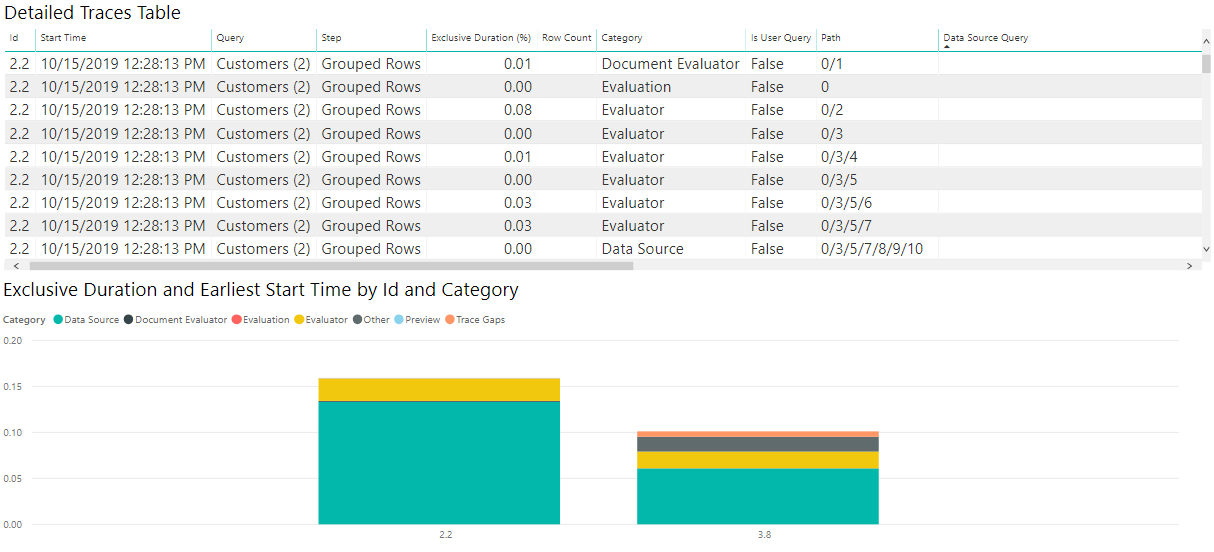
Auch wenn Ihre genauen Bedürfnisse unterschiedlich sein können, ist diese Kombination von Diagrammen ein guter Ausgangspunkt für die Betrachtung zahlreicher Diagnosedateien und für eine Reihe von Zwecken.
Interpretation der Visualisierungen
Wie bereits erwähnt, gibt es viele Fragen, die Sie mit der Abfragediagnose beantworten können, aber die beiden häufigsten sind die Frage nach dem Zeitaufwand und die Frage nach der an die Quelle gesendeten Abfrage.
Die Frage, wie die Zeit verbracht wird, ist einfach und wird bei den meisten Verbindern ähnlich lauten. Wie bereits an anderer Stelle erwähnt, ist bei der Abfragediagnose zu beachten, dass je nach Connector ganz unterschiedliche Funktionen zur Verfügung stehen. Zum Beispiel haben viele ODBC-basierte Connectors keine genaue Aufzeichnung darüber, welche Abfrage an das tatsächliche Back-End-System gesendet wird, da Power Query nur sieht, was es an den ODBC-Treiber sendet.
Wenn wir sehen wollen, wie die Zeit verbracht wird, können wir uns einfach die oben erstellten Visualisierungen ansehen.
Da die Zeitwerte für die Beispielabfragen, die wir hier verwenden, so klein sind, ist es besser, wenn wir die Spalte Exklusive Dauer im Power Query-Editor in „Sekunden“ konvertieren, wenn wir damit arbeiten wollen, wie Power BI die Zeit berichtet. Sobald wir diese Umrechnung vorgenommen haben, können wir unser Diagramm betrachten und einen guten Eindruck davon bekommen, wo die Zeit verbracht wird.
Für meine OData-Ergebnisse sehe ich in der Abbildung, dass der größte Teil der Zeit für das Abrufen der Daten aus der Quelle aufgewendet wurde - wenn ich in der Legende das Element „Datenquelle“ auswähle, werden mir alle verschiedenen Vorgänge angezeigt, die mit dem Senden einer Abfrage an die Datenquelle verbunden sind.
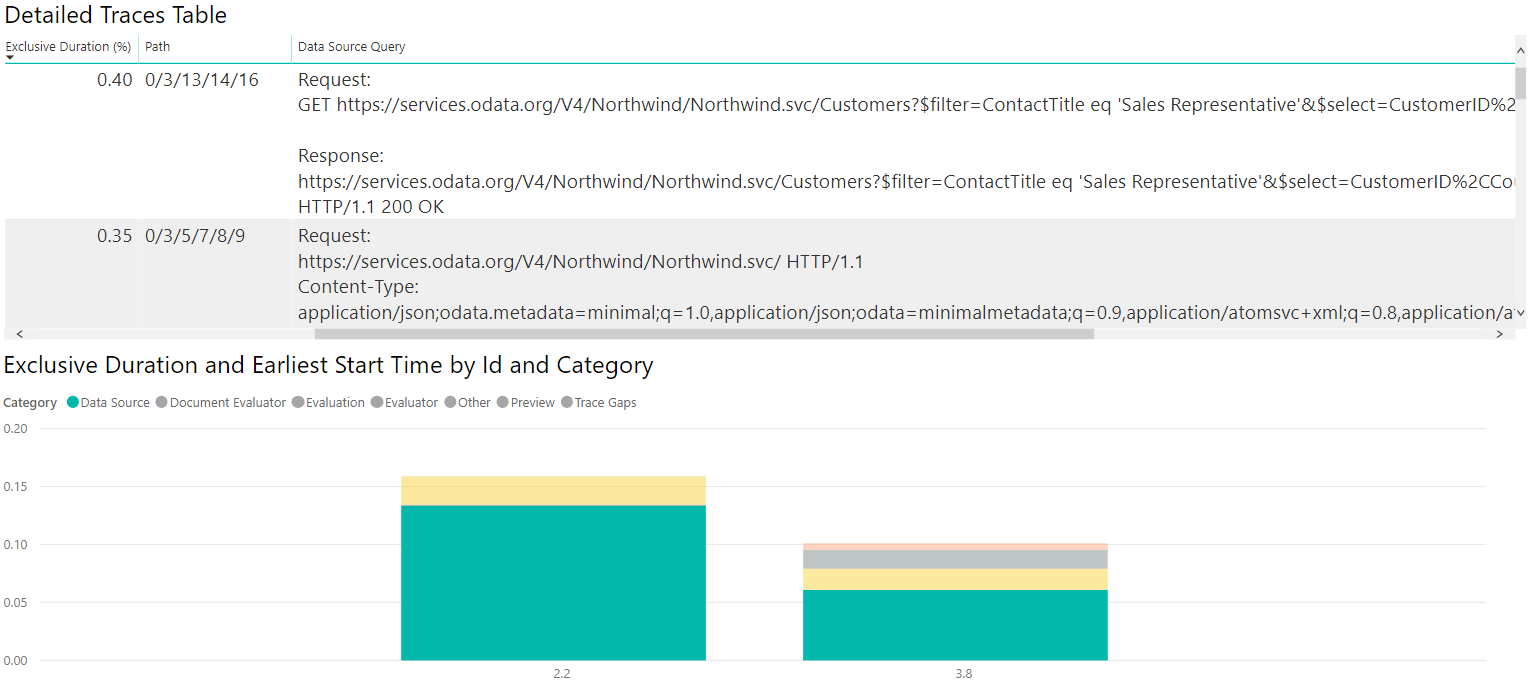
Wenn wir die gleichen Operationen durchführen und ähnliche Visualisierungen erstellen, aber mit den SQL-Spuren anstelle der ODATA-Spuren, können wir sehen, wie die beiden Datenquellen im Vergleich aussehen!
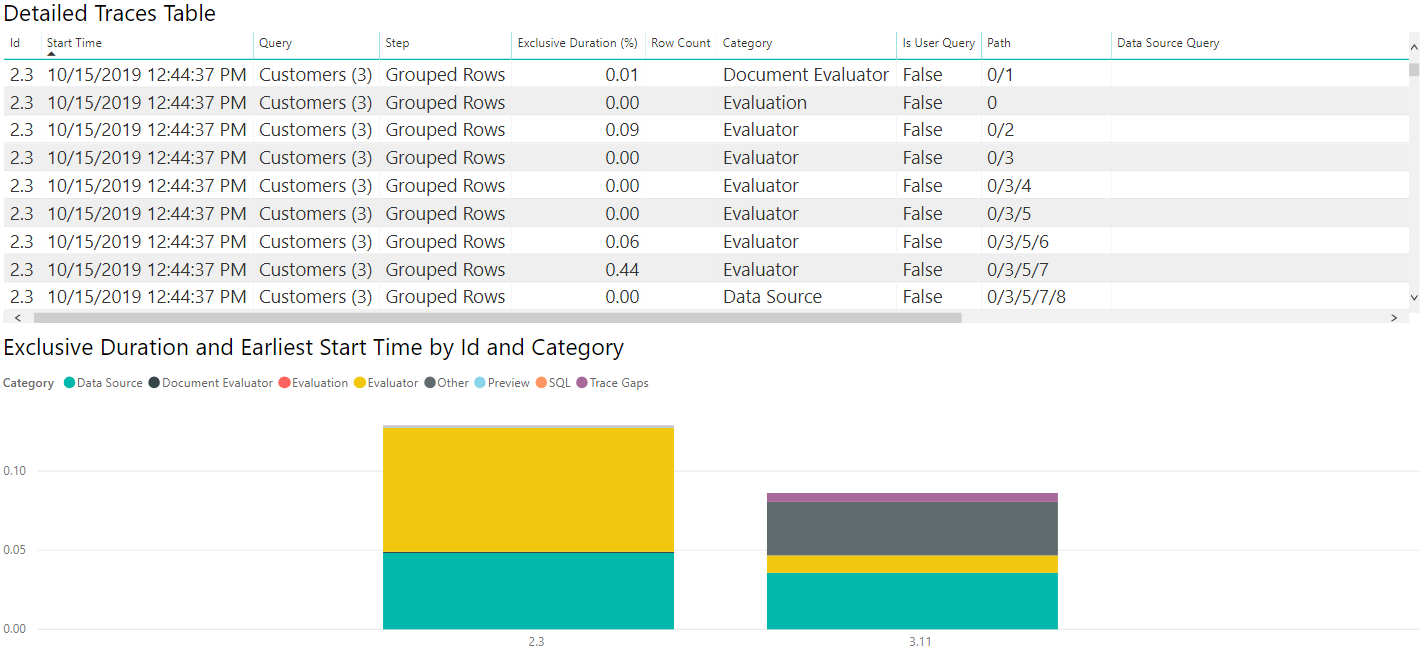
Wenn wir die Tabelle Datenquelle auswählen, können wir wie bei der ODATA-Diagnose sehen, dass die erste Auswertung (2.3 in diesem Bild) Metadatenabfragen ausgibt, während die zweite Auswertung tatsächlich die Daten abruft, die uns interessieren. Da wir in diesem Fall nur kleine Datenmengen abrufen, dauert der Datenabruf nur wenig Zeit (weniger als eine Zehntelsekunde für die gesamte zweite Auswertung und weniger als eine Zwanzigstelsekunde für den Datenabruf selbst), aber das wird nicht in allen Fällen zutreffen.
Wie oben können wir die Kategorie „Datenquelle“ in der Legende auswählen, um die ausgegebenen Abfragen zu sehen.
Einsicht in die Daten
Blick auf die Pfade
Wenn Sie sich dies ansehen, können Sie feststellen, dass die verbrauchte Zeit seltsam ist - zum Beispiel bei der OData-Abfrage, dass es eine Datenquellenabfrage mit dem folgenden Wert gibt:
Request:
https://services.odata.org/V4/Northwind/Northwind.svc/Customers?$filter=ContactTitle%20eq%20%27Sales%20Representative%27&$select=CustomerID%2CCountry HTTP/1.1
Content-Type: application/json;odata.metadata=minimal;q=1.0,application/json;odata=minimalmetadata;q=0.9,application/atomsvc+xml;q=0.8,application/atom+xml;q=0.8,application/xml;q=0.7,text/plain;q=0.7
<Content placeholder>
Response:
Content-Type: application/json;odata.metadata=minimal;q=1.0,application/json;odata=minimalmetadata;q=0.9,application/atomsvc+xml;q=0.8,application/atom+xml;q=0.8,application/xml;q=0.7,text/plain;q=0.7
Content-Length: 435
<Content placeholder>
Diese Datenquellenabfrage ist mit einem Vorgang verbunden, der nur, sagen wir, 1 % der Exklusivitätsdauer in Anspruch nimmt. In der Zwischenzeit gibt es einen ähnlichen Fall:
Request:
GET https://services.odata.org/V4/Northwind/Northwind.svc/Customers?$filter=ContactTitle eq 'Sales Representative'&$select=CustomerID%2CCountry HTTP/1.1
Response:
https://services.odata.org/V4/Northwind/Northwind.svc/Customers?$filter=ContactTitle eq 'Sales Representative'&$select=CustomerID%2CCountry
HTTP/1.1 200 OK
Diese Datenquellenabfrage ist mit einem Vorgang verbunden, der fast 75 % der Exklusivitätsdauer in Anspruch nimmt. Wenn Sie den Pfad aktivieren, werden Sie feststellen, dass der letztere eigentlich ein untergeordnetes Element des ersteren ist. Das bedeutet, dass die erste Abfrage im Grunde nur wenig Zeit in Anspruch genommen hat, während der eigentliche Datenabruf durch die „innere“ Abfrage verfolgt wurde.
Das sind extreme Werte, aber sie liegen im Rahmen dessen, was man sehen kann.