Hinter den Kulissen der Data Privacy Firewall
Hinweis
Datenschutzebenen sind in Power Platform-Dataflows derzeit nicht verfügbar, aber das Produktteam arbeitet an dieser Funktionalität.
Wenn Sie Power Query schon länger verwenden, haben Sie das wahrscheinlich schon erlebt. Sie sind gerade dabei, eine Anfrage zu stellen, als Sie plötzlich eine Fehlermeldung erhalten, die sich auch durch noch so viel Online-Suche, noch so viele Änderungen an der Anfrage und noch so viel Tastaturkorrekturen nicht beheben lässt. Ein Fehler wie:
Formula.Firewall: Query 'Query1' (step 'Source') references other queries or steps, so it may not directly access a data source. Please rebuild this data combination.
Oder vielleicht:
Formula.Firewall: Query 'Query1' (step 'Source') is accessing data sources that have privacy levels which cannot be used together. Please rebuild this data combination.
Diese Formula.Firewall Fehler sind das Ergebnis der Data Privacy Firewall von Power Query (auch bekannt als Firewall), die manchmal den Anschein erweckt, als würde sie nur existieren, um Datenanalysten auf der ganzen Welt zu frustrieren. Ob Sie es glauben oder nicht, aber die Firewall erfüllt einen wichtigen Zweck. In diesem Artikel werden wir einen Blick unter die Haube werfen, um besser zu verstehen, wie es funktioniert. Mit einem besseren Verständnis werden Sie hoffentlich in der Lage sein, Firewall-Fehler in Zukunft besser zu diagnostizieren und zu beheben.
Was ist das?
Der Zweck der Data Privacy Firewall ist einfach: Sie soll verhindern, dass Power Query ungewollt Daten zwischen Quellen austauscht.
Warum wird dies benötigt? Sie könnten sicherlich ein M schreiben, das einen SQL-Wert an einen OData-Feed weitergibt. Dies wäre jedoch ein absichtliches Datenleck. Der Mashup-Autor würde (oder sollte zumindest) wissen, dass er dies tut. Warum dann der Schutz vor unbeabsichtigtem Datenabfluss?
Die Antwort? Falten.
Falten?
Folding ist ein Begriff, der sich auf die Konvertierung von Ausdrücken in M (z. B. Filter, Umbenennungen, Verknüpfungen usw.) in Operationen mit einer Rohdatenquelle (z. B. SQL, OData usw.) bezieht. Ein großer Teil der Leistungsfähigkeit von Power Query beruht auf der Tatsache, dass PQ die Operationen, die ein Benutzer über die Benutzeroberfläche ausführt, in komplexes SQL oder andere Backend-Datenquellsprachen umwandeln kann, ohne dass der Benutzer diese Sprachen beherrschen muss. Die Benutzer profitieren von den Leistungsvorteilen nativer Datenquellenoperationen und der Benutzerfreundlichkeit einer Benutzeroberfläche, über die alle Datenquellen mit einem gemeinsamen Befehlssatz transformiert werden können.
Als Teil der Faltung kann PQ manchmal feststellen, dass die effizienteste Art, ein bestimmtes Mashup auszuführen, darin besteht, Daten aus einer Quelle zu nehmen und sie an eine andere weiterzugeben. Wenn Sie z. B. eine kleine CSV-Datei mit einer großen SQL-Tabelle verknüpfen, möchten Sie wahrscheinlich nicht, dass PQ die CSV-Datei liest, die gesamte SQL-Tabelle liest und sie dann auf Ihrem lokalen Computer zusammenfügt. Sie möchten wahrscheinlich, dass PQ die CSV-Daten in eine SQL-Anweisung einbindet und die SQL-Datenbank auffordert, die Verknüpfung durchzuführen.
Auf diese Weise kann es zu ungewollten Datenlecks kommen.
Stellen Sie sich vor, Sie verbinden SQL-Daten, die Sozialversicherungsnummern von Mitarbeitern enthalten, mit den Ergebnissen eines externen OData-Feeds und stellen plötzlich fest, dass die Sozialversicherungsnummern aus SQL an den OData-Dienst gesendet werden. Schlechte Nachrichten, oder?
Dies ist die Art von Szenario, das die Firewall verhindern soll.
Wie funktioniert dies?
Die Firewall soll verhindern, dass Daten von einer Quelle ungewollt an eine andere Quelle gesendet werden. Das ist ganz einfach.
Wie erfüllt sie nun diese Aufgabe?
Dazu werden Ihre M Abfragen in so genannte Partitionen unterteilt und dann die folgende Regel angewandt:
- Eine Partition kann entweder auf kompatible Datenquellen zugreifen oder auf andere Partitionen verweisen, aber nicht beides.
Einfach und dennoch verwirrend. Was ist eine Partition? Was macht zwei Datenquellen „kompatibel“? Und warum sollte sich die Firewall darum kümmern, wenn eine Partition auf eine Datenquelle zugreifen und auf eine Partition verweisen möchte?
Schauen wir uns die oben genannte Regel Stück für Stück an.
Was ist eine Partition?
Auf der einfachsten Ebene ist eine Partition lediglich eine Sammlung von einem oder mehreren Abfrageschritten. Die granularste Partition, die möglich ist (zumindest in der derzeitigen Implementierung), ist ein einzelner Schritt. Die größten Partitionen können manchmal mehrere Abfragen umfassen. (Dazu später mehr.)
Wenn Sie mit Schritten nicht vertraut sind, können Sie diese rechts im Power Query Editor-Fenster nach Auswahl einer Abfrage im Bereich Angewandte Schritte anzeigen. In den Schritten wird alles festgehalten, was Sie getan haben, um Ihre Daten in ihre endgültige Form zu bringen.
Partitionen, die auf andere Partitionen verweisen
Wenn eine Abfrage mit eingeschalteter Firewall ausgewertet wird, unterteilt die Firewall die Abfrage und alle ihre Abhängigkeiten in Partitionen (d. h. Gruppen von Schritten). Immer wenn eine Partition auf etwas in einer anderen Partition verweist, ersetzt die Firewall den Verweis durch einen Aufruf einer speziellen Funktion namens Value.Firewall. Mit anderen Worten: Die Firewall lässt nicht zu, dass die Partitionen direkt aufeinander zugreifen können. Alle Verweise werden so geändert, dass sie durch die Firewall gehen. Betrachten Sie die Firewall als einen Torwächter. Eine Partition, die auf eine andere Partition verweist, muss die Erlaubnis der Firewall einholen, und die Firewall kontrolliert, ob die referenzierten Daten in der Partition zugelassen werden oder nicht.
Das mag alles ziemlich abstrakt erscheinen, also lassen Sie uns ein Beispiel betrachten.
Angenommen, Sie haben eine Abfrage mit dem Namen Employees, die einige Daten aus einer SQL-Datenbank abruft. Angenommen, Sie haben auch eine andere Abfrage (EmployeesReference), die einfach auf Employees verweist.
shared Employees = let
Source = Sql.Database(…),
EmployeesTable = …
in
EmployeesTable;
shared EmployeesReference = let
Source = Employees
in
Source;
Diese Abfragen werden in zwei Partitionen aufgeteilt: eine für die Abfrage Employees und eine für die Abfrage EmployeesReference (die auf die Partition Employees verweist). Bei der Auswertung mit eingeschalteter Firewall werden diese Abfragen wie folgt umgeschrieben:
shared Employees = let
Source = Sql.Database(…),
EmployeesTable = …
in
EmployeesTable;
shared EmployeesReference = let
Source = Value.Firewall("Section1/Employees")
in
Source;
Beachten Sie, dass der einfache Verweis auf die Abfrage „Employees“ durch einen Aufruf von Value.Firewall ersetzt wurde, dem der vollständige Name der Abfrage „Employees“ übergeben wird.
Wenn EmployeesReference ausgewertet wird, wird der Aufruf an Value.Firewall("Section1/Employees") von der Firewall abgefangen, die nun die Möglichkeit hat, zu kontrollieren, ob (und wie) die angeforderten Daten in die EmployeesReference-Partition fließen. Sie kann eine Reihe von Maßnahmen ergreifen: die Anfrage ablehnen, die angeforderten Daten zwischenspeichern (was ein weiteres Falten zu ihrer ursprünglichen Datenquelle verhindert) usw.
Auf diese Weise behält die Firewall die Kontrolle über die zwischen den Partitionen fließenden Daten.
Partitionen, die direkt auf Datenquellen zugreifen
Nehmen wir an, Sie definieren eine Abfrage Query1 mit einem Schritt (beachten Sie, dass diese einstufige Abfrage einer Firewall-Partition entspricht), und dass dieser einzelne Schritt auf zwei Datenquellen zugreift: eine SQL-Datenbanktabelle und eine CSV-Datei. Wie geht die Firewall damit um? Es gib ja keinen Partitionsverweis und somit keinen Aufruf an Value.Firewall, den sie abfangen könnte? Erinnern wir uns an die oben genannte Regel:
- Eine Partition kann entweder auf kompatible Datenquellen zugreifen oder auf andere Partitionen verweisen, aber nicht beides.
Damit Ihre Abfrage mit nur einer Partition, aber zwei Datenquellen ausgeführt werden kann, müssen die beiden Datenquellen „kompatibel“ sein. Mit anderen Worten, es muss erlaubt sein, dass Daten zwischen ihnen bidirektional ausgetauscht werden können. Dies bedeutet, dass die Datenschutzebenen beider Quellen öffentlich oder beide organisatorisch sein müssen, da es sich hierbei um die einzigen beiden Kombinationen handelt, die die Freigabe in beide Richtungen ermöglichen. Wenn beide Quellen als privat gekennzeichnet sind, oder wenn eine als öffentlich und eine als organisatorisch gekennzeichnet ist, oder wenn sie mit einer anderen Kombination von Datenschutzebenen gekennzeichnet sind, dann ist der bidirektional Austausch nicht erlaubt. Deswegen ist es nicht sicher, wenn sie beide in derselben Partition ausgewertet werden. Dies würde bedeuten, dass es zu einem unsicheren Datenverlust kommen könnte (aufgrund von Faltung), und die Firewall hätte keine Möglichkeit, dies zu verhindern.
Was passiert, wenn Sie versuchen, auf inkompatible Datenquellen in derselben Partition zuzugreifen?
Formula.Firewall: Query 'Query1' (step 'Source') is accessing data sources that have privacy levels which cannot be used together. Please rebuild this data combination.
Hoffentlich verstehen Sie jetzt eine der Fehlermeldungen, die am Anfang dieses Artikels aufgeführt sind, besser.
Beachten Sie, dass diese Kompatibilität Anforderung nur innerhalb einer bestimmten Partition gilt. Wenn eine Partition andere Partitionen referenziert, müssen die Datenquellen der referenzierten Partitionen nicht miteinander kompatibel sein. Dies liegt daran, dass die Firewall die Daten zwischenspeichern kann, wodurch ein weiteres Falten gegen die ursprüngliche Datenquelle verhindert wird. Die Daten werden in den Speicher geladen und so behandelt, als kämen sie aus dem Nichts.
Warum nicht beides?
Angenommen, Sie definieren eine Abfrage mit einem Schritt (der wiederum einer Partition entspricht), die auf zwei andere Abfragen (d. h. zwei andere Partitionen) zugreift. Was wäre, wenn Sie in demselben Schritt auch direkt auf eine SQL-Datenbank zugreifen wollten? Warum kann eine Partition nicht auf andere Partitionen verweisen und direkt auf kompatible Datenquellen zugreifen?
Wenn eine Partition auf eine andere Partition verweist, fungiert die Firewall als Gatekeeper für alle Daten, die in die Partition fließen, wie Sie bereits gesehen haben. Dazu muss sie in der Lage sein zu kontrollieren, welche Daten zugelassen werden. Wenn innerhalb der Partition auf Datenquellen zugegriffen wird und Daten von anderen Partitionen einfließen, verliert sie ihre Fähigkeit, als Gatekeeper zu fungieren, da die einfließenden Daten in eine der intern zugegriffenen Datenquellen gelangen könnten, ohne dass sie davon weiß. So verhindert die Firewall, dass eine Partition, die auf andere Partitionen zugreift, direkt auf Datenquellen zugreifen kann.
Was passiert also, wenn eine Partition versucht, auf andere Partitionen zu verweisen und auch direkt auf Datenquellen zuzugreifen?
Formula.Firewall: Query 'Query1' (step 'Source') references other queries or steps, so it may not directly access a data source. Please rebuild this data combination.
Jetzt verstehen Sie hoffentlich die andere Fehlermeldung, die am Anfang dieses Artikels aufgeführt ist, besser.
Partitionen im Detail
Wie Sie wahrscheinlich aus den obigen Informationen entnehmen können, ist die Art und Weise, wie Abfragen aufgeteilt werden, von großer Bedeutung. Wenn Sie einige Schritte haben, die auf andere Abfragen verweisen, und andere Schritte, die auf Datenquellen zugreifen, erkennen Sie nun hoffentlich, dass das Zeichnen der Partitionsgrenzen an bestimmten Stellen zu Firewall-Fehlern führt, während das Zeichnen an anderen Stellen die Ausführung Ihrer Abfrage problemlos ermöglicht.
Wie genau werden die Abfragen aufgeteilt?
Dieser Abschnitt ist wahrscheinlich der wichtigste, um zu verstehen, warum Sie Firewall-Fehler sehen, und um zu verstehen, wie man sie beheben kann (sofern möglich).
Hier eine kurze Zusammenfassung der Partitionierungslogik.
- Initiale Partitionierung
- Erzeugt eine Partition für jeden Schritt in jeder Abfrage
- Statische Phase
- Diese Phase hängt nicht von den Bewertungsergebnissen ab. Stattdessen kommt es darauf an, wie die Abfragen strukturiert sind.
- Parameter trimmen
- Trimmt parameterähnliche Partitionen, d. h. alle, die:
- Verweist nicht auf andere Partitionen
- Enthält keine Funktionsaufrufe
- Ist nicht zyklisch (d. h., er bezieht sich nicht auf sich selbst)
- Beachten Sie, dass das „Entfernen“ einer Partition sie in alle anderen Partitionen einbezieht, die auf sie verweisen.
- Das Trimmen von Parameterpartitionen ermöglicht es, dass Parameterreferenzen innerhalb von Funktionsaufrufen von Datenquellen (z. B.
Web.Contents(myUrl)) funktionieren, anstatt Fehler wie „Partition kann nicht auf Datenquellen und andere Schritte verweisen“ auszulösen.
- Trimmt parameterähnliche Partitionen, d. h. alle, die:
- Gruppierung (statisch)
- Partitionen werden in aufsteigender Reihenfolge der Abhängigkeit zusammengeführt. In den resultierenden zusammengeführten Partitionen ist Folgendes getrennt:
- Partitionen in verschiedenen Abfragen
- Partitionen, die nicht auf andere Partitionen verweisen (und somit auf eine Datenquelle zugreifen dürfen)
- Partitionen, die auf andere Partitionen verweisen (und somit nicht auf eine Datenquelle zugreifen dürfen)
- Partitionen werden in aufsteigender Reihenfolge der Abhängigkeit zusammengeführt. In den resultierenden zusammengeführten Partitionen ist Folgendes getrennt:
- Parameter trimmen
- Diese Phase hängt nicht von den Bewertungsergebnissen ab. Stattdessen kommt es darauf an, wie die Abfragen strukturiert sind.
- Dynamische Phase
- Diese Phase hängt von den Bewertungsergebnissen ab, einschließlich der Informationen über die Datenquellen, auf die die verschiedenen Partitionen zugreifen.
- Beschneiden
- Trimmt Partitionen, die alle folgenden Anforderungen erfüllen:
- Greift auf keine Datenquellen zu
- Verweist nicht auf Partitionen, die auf Datenquellen zugreifen
- Ist nicht zyklisch
- Trimmt Partitionen, die alle folgenden Anforderungen erfüllen:
- Gruppierung (dynamisch)
- Nachdem unnötige Partitionen entfernt wurden, sollten Sie versuchen, möglichst große Quellpartitionen zu erstellen. Dazu werden die Partitionen nach den gleichen Regeln zusammengeführt, die oben in der Phase der statischen Gruppierung beschrieben sind.
Was bedeutet das alles?
Gehen wir anhand eines Beispiels durch, um zu veranschaulichen, wie die oben dargestellte komplexe Logik funktioniert.
Hier ist ein Beispielszenario. Es handelt sich um eine relativ einfache Zusammenführung einer Textdatei (Contacts) mit einer SQL-Datenbank (Employees), wobei der SQL-Server ein Parameter ist (DbServer).
Die drei Abfragen
Hier ist der M-Code für die drei in diesem Beispiel verwendeten Abfragen.
shared DbServer = "MySqlServer" meta [IsParameterQuery=true, Type="Text", IsParameterQueryRequired=true];
shared Contacts = let
Source = Csv.Document(File.Contents("C:\contacts.txt"),[Delimiter=" ", Columns=15, Encoding=1252, QuoteStyle=QuoteStyle.None]),
#"Promoted Headers" = Table.PromoteHeaders(Source, [PromoteAllScalars=true]),
#"Changed Type" = Table.TransformColumnTypes(#"Promoted Headers",{{"ContactID", Int64.Type}, {"NameStyle", type logical}, {"Title", type text}, {"FirstName", type text}, {"MiddleName", type text}, {"LastName", type text}, {"Suffix", type text}, {"EmailAddress", type text}, {"EmailPromotion", Int64.Type}, {"Phone", type text}, {"PasswordHash", type text}, {"PasswordSalt", type text}, {"AdditionalContactInfo", type text}, {"rowguid", type text}, {"ModifiedDate", type datetime}})
in
#"Changed Type";
shared Employees = let
Source = Sql.Databases(DbServer),
AdventureWorks = Source{[Name="AdventureWorks"]}[Data],
HumanResources_Employee = AdventureWorks{[Schema="HumanResources",Item="Employee"]}[Data],
#"Removed Columns" = Table.RemoveColumns(HumanResources_Employee,{"HumanResources.Employee(EmployeeID)", "HumanResources.Employee(ManagerID)", "HumanResources.EmployeeAddress", "HumanResources.EmployeeDepartmentHistory", "HumanResources.EmployeePayHistory", "HumanResources.JobCandidate", "Person.Contact", "Purchasing.PurchaseOrderHeader", "Sales.SalesPerson"}),
#"Merged Queries" = Table.NestedJoin(#"Removed Columns",{"ContactID"},Contacts,{"ContactID"},"Contacts",JoinKind.LeftOuter),
#"Expanded Contacts" = Table.ExpandTableColumn(#"Merged Queries", "Contacts", {"EmailAddress"}, {"EmailAddress"})
in
#"Expanded Contacts";
Hier ist eine übergeordnete Ansicht, die die Abhängigkeiten zeigt.
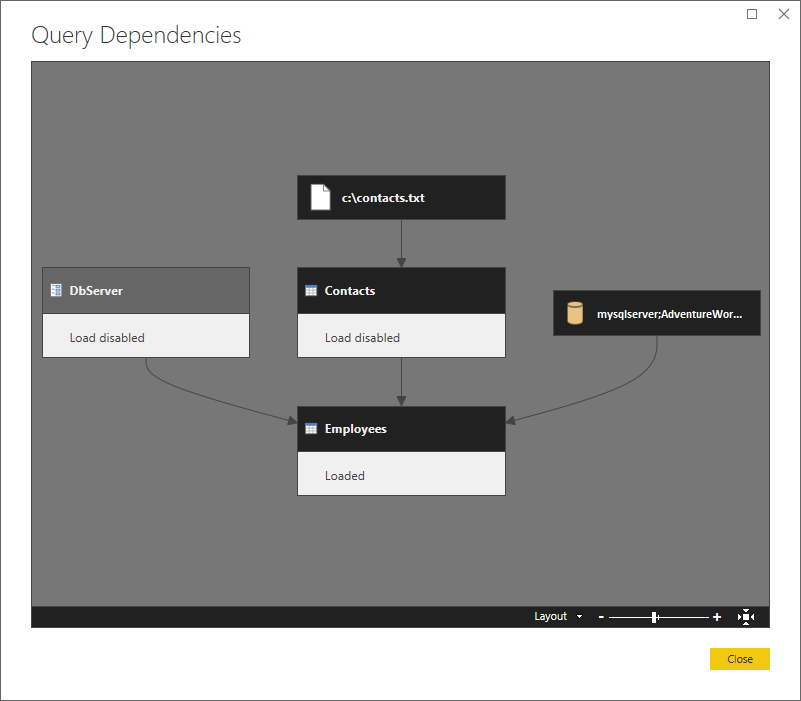
Partitionieren wir
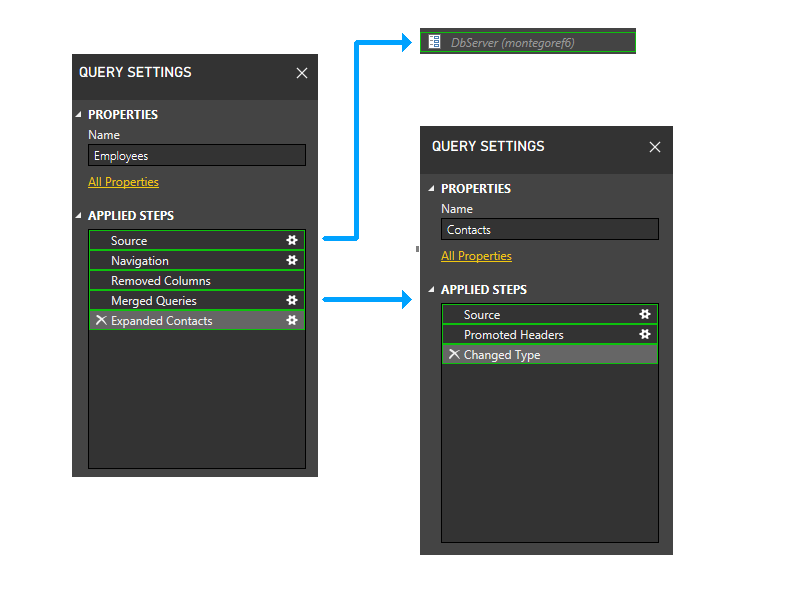
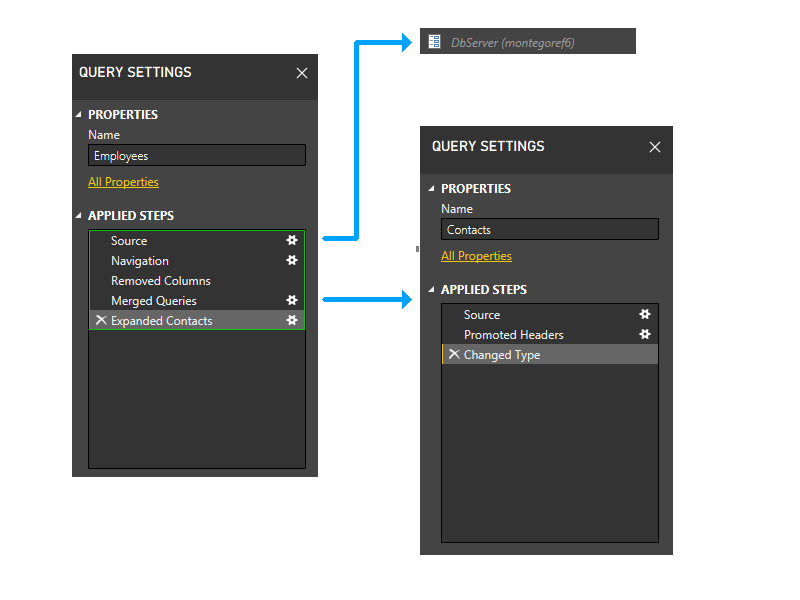
Lassen Sie uns ein wenig heranzoomen und Schritte in das Bild einfügen, um die Partitionierungslogik zu durchlaufen. Hier ist ein Diagramm der drei Abfragen, in dem die ursprünglichen Firewall-Partitionen grün dargestellt sind. Beachten Sie, dass jeder Schritt in seiner eigenen Partition beginnt.
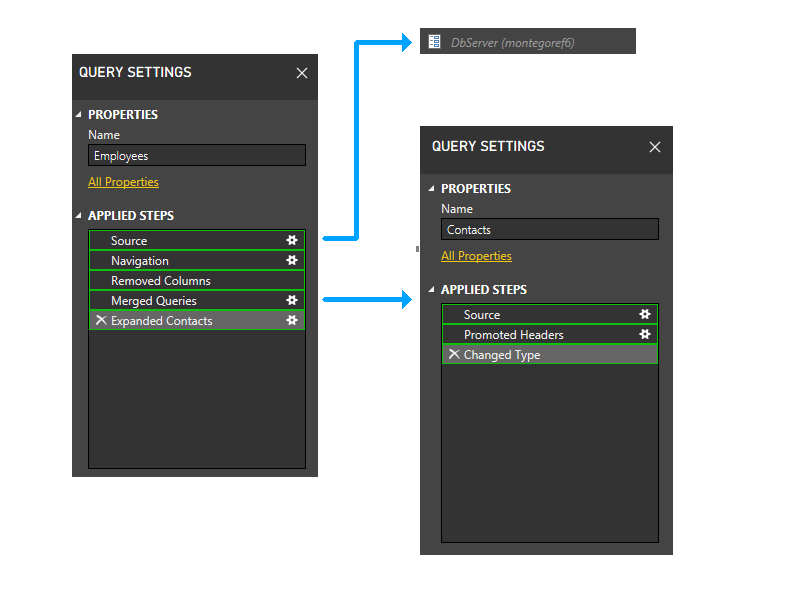
Als nächstes trimmen wir die Parameterpartitionen. Daher wird DbServer implizit in die Quellpartition aufgenommen.
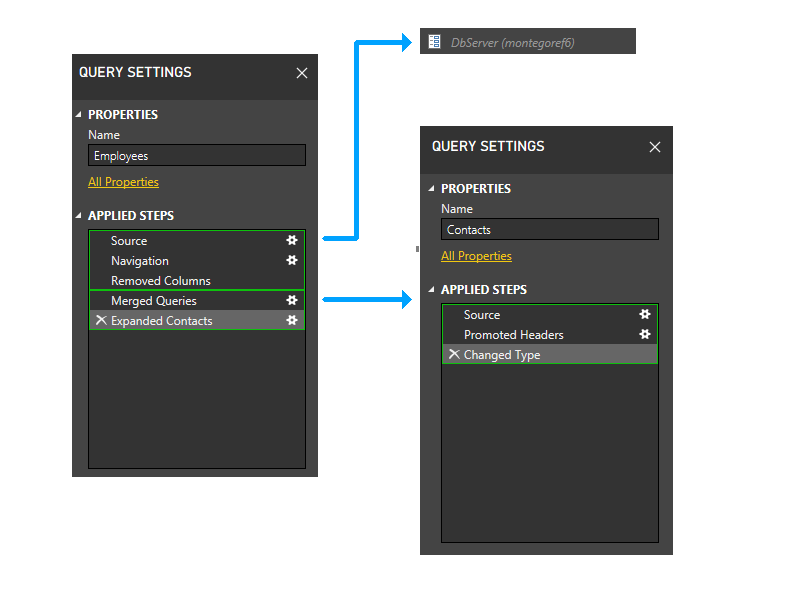
Jetzt führen wir die statische Gruppierung durch. Dadurch wird die Trennung zwischen Partitionen in separaten Abfragen beibehalten (beachten Sie z. B., dass die letzten beiden Schritte von Employees nicht mit den Schritten von Kontakte gruppiert werden), und zwischen Partitionen, die auf andere Partitionen verweisen (z. B. die letzten beiden Schritte von Employees), und solchen, die dies nicht tun (z. B. die ersten drei Schritte von Employees).
Jetzt treten wir in die dynamische Phase ein. In dieser Phase werden die oben genannten statischen Partitionen bewertet. Partitionen, die auf keine Datenquellen zugreifen, werden abgeschnitten. Die Partitionen werden dann gruppiert, um möglichst große Quellpartitionen zu schaffen. In diesem Beispielszenario greifen jedoch alle verbleibenden Partitionen auf Datenquellen zu, und es gibt keine weitere Gruppierung, die vorgenommen werden kann. Die Partitionen in unserem Beispiel werden also in dieser Phase nicht verändert.
Tun wir so, als ob
Zur Veranschaulichung sehen wir uns jedoch an, was passieren würde, wenn die Kontaktabfrage nicht aus einer Textdatei käme, sondern fest in M kodiert wäre (vielleicht über das Dialogfeld Enter Data ).
In diesem Fall würde die Contacts-Abfrage auf keine Datenquellen zugreifen. Sie würde also während des ersten Teils der dynamischen Phase beschnitten werden.
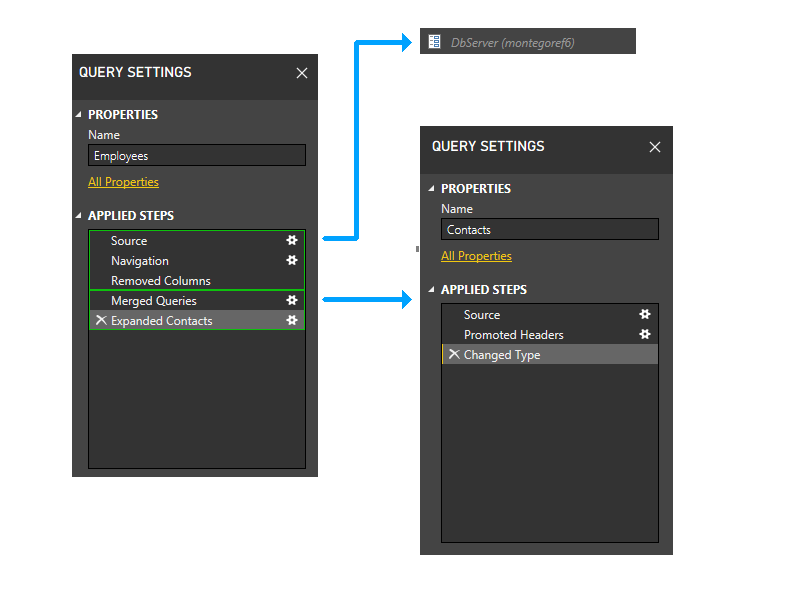
Wenn die Partition „Kontakte“ entfernt wird, verweisen die letzten beiden Schritte von „Employees“ nicht mehr auf andere Partitionen als diejenige, die die ersten drei Schritte von „Employees“ enthält. So würden die beiden Partitionen gruppiert werden.
Die resultierende Partition würde wie folgt aussehen.
Beispiel: Übergabe von Daten aus einer Datenquelle an eine andere
Okay, genug der abstrakten Erklärung. Schauen wir uns ein häufiges Szenario an, bei dem ein Firewall-Fehler auftreten kann, und die Schritte zur Behebung des Problems.
Stellen Sie sich vor, Sie möchten einen Firmennamen aus dem Northwind OData-Dienst abrufen und dann den Firmennamen für eine Bing-Suche verwenden.
Zunächst erstellen Sie eine Abfrage Unternehmen, um den Firmennamen abzurufen.
let
Source = OData.Feed("https://services.odata.org/V4/Northwind/Northwind.svc/", null, [Implementation="2.0"]),
Customers_table = Source{[Name="Customers",Signature="table"]}[Data],
CHOPS = Customers_table{[CustomerID="CHOPS"]}[CompanyName]
in
CHOPS
Als Nächstes erstellen Sie eine Suche Abfrage, die auf Unternehmen verweist und diese an Bing weitergibt.
let
Source = Text.FromBinary(Web.Contents("https://www.bing.com/search?q=" & Company))
in
Source
An diesem Punkt gibt es Probleme. Die Auswertung von Search führt zu einem Firewall-Fehler.
Formula.Firewall: Query 'Search' (step 'Source') references other queries or steps, so it may not directly access a data source. Please rebuild this data combination.
Das liegt daran, dass der Schritt „Quelle“ von Search auf eine Datenquelle (bing.com) und auch auf eine andere Abfrage/Partition (Company) verweist. Das verstößt gegen die oben genannte Regel („eine Partition kann entweder auf kompatible Datenquellen zugreifen oder auf andere Partitionen verweisen, aber nicht auf beides“).
Vorgehensweise Eine Möglichkeit besteht darin, die Firewall ganz zu deaktivieren (über die Option Datenschutz mit der Bezeichnung Die Datenschutzstufen ignorieren und möglicherweise die Leistung verbessern). Was aber, wenn Sie die Firewall aktiviert lassen wollen?
Um den Fehler zu beheben, ohne die Firewall zu deaktivieren, können Sie Unternehmen und Suche in einer einzigen Abfrage kombinieren, etwa so:
let
Source = OData.Feed("https://services.odata.org/V4/Northwind/Northwind.svc/", null, [Implementation="2.0"]),
Customers_table = Source{[Name="Customers",Signature="table"]}[Data],
CHOPS = Customers_table{[CustomerID="CHOPS"]}[CompanyName],
Search = Text.FromBinary(Web.Contents("https://www.bing.com/search?q=" & CHOPS))
in
Search
Alles findet jetzt innerhalb einer einzigen -Partition statt. Unter der Annahme, dass die Vertraulichkeitsstufen für die beiden Datenquellen kompatibel sind, sollte die Firewall nun zufrieden sein, und Sie erhalten keine Fehlermeldung mehr.
Das war's.
Es gäbe noch viel mehr zu diesem Thema zu sagen, aber dieser einführende Artikel ist schon lang genug. Wir hoffen, dass Sie dadurch die Firewall besser verstehen und Firewall-Fehler beheben können, wenn sie in Zukunft auftreten.